Přehled
Tento článek pojednává o dvou různých dostupných přístupech k odstranění duplicitních řádků z tabulek SQL, což se často stává obtížné v průběhu času, protože data rostou, pokud to není provedeno včas.
Přítomnost duplicitních řádků je běžný problém, se kterým se čas od času potýkají vývojáři a testeři SQL, nicméně tyto duplicitní řádky spadají do řady různých kategorií, o kterých budeme diskutovat v tomto článku.
Tento článek se zaměřuje na konkrétní scénář, kdy data vložená do databázové tabulky vedou k zavedení duplicitních záznamů a poté se blíže podíváme na metody odstraňování duplikátů a nakonec je pomocí těchto metod odstraníme.
Příprava ukázkových dat
Než začneme prozkoumávat různé dostupné možnosti odstranění duplicit, vyplatí se v tomto bodě vytvořit vzorovou databázi, která nám pomůže porozumět situacím, kdy se duplicitní data dostanou do systému, a přístupům, které je třeba použít k jejich odstranění. .
Nastavení ukázkové databáze (UniversityV2)
Začněte vytvořením velmi jednoduché databáze, kterou tvoří pouze Student tabulka na začátku.
-- (1) Create UniversityV2 sample database
CREATE DATABASE UniversityV2;
GO
USE UniversityV2
CREATE TABLE [dbo].[Student] (
[StudentId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NULL,
[Course] VARCHAR (30) NULL,
[Marks] INT NULL,
[ExamDate] DATETIME2 (7) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ([StudentId] ASC)
);
Vyplnění tabulky studentů
Do tabulky Student přidáme pouze dva záznamy:
-- Adding two records to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Kontrola dat
Zobrazte tabulku, která v tuto chvíli obsahuje dva odlišné záznamy:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
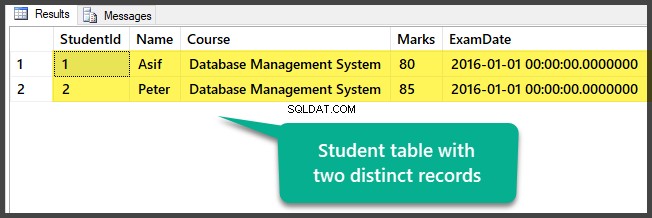
Úspěšně jste připravili ukázková data nastavením databáze s jednou tabulkou a dvěma odlišnými (různými) záznamy.
Nyní probereme některé potenciální scénáře, ve kterých byly duplikáty zavedeny a odstraněny, počínaje jednoduchými až mírně složitými situacemi.
Případ 01:Přidávání a odebírání duplikátů
Nyní zavedeme duplicitní řádky v tabulce Student.
Předpoklady
V tomto případě se říká, že tabulka obsahuje duplicitní záznamy, pokud je studentovo Jméno , Kurz , Značky a Datum zkoušky shodují se ve více záznamech, i když ID studenta je jiný.
Předpokládáme tedy, že žádní dva studenti nemohou mít stejné jméno, kurz, známky a datum zkoušky.
Přidání duplicitních dat pro Student Asif
Vložme schválně duplicitní záznam pro Student:Asif na Student tabulka takto:
-- Adding Student Asif duplicate record to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (3, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Zobrazení duplicitních dat studentů
Zobrazit Student tabulka pro zobrazení duplicitních záznamů:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
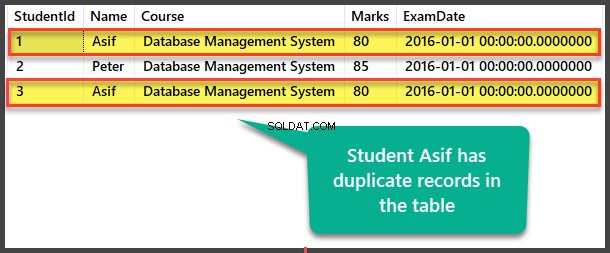
Hledání duplikátů metodou self-referencing
Co když jsou v této tabulce tisíce záznamů, pak zobrazení tabulky moc nepomůže.
V metodě samoodkazování vezmeme dva odkazy na stejnou tabulku a spojíme je pomocí mapování sloupec po sloupci s výjimkou ID, které je menší nebo větší než druhé.
Podívejme se na metodu samoodkazování, abychom našli duplikáty, která vypadá takto:
USE UniversityV2
-- Self-Referencing method to finding duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1,[dbo].[Student] S2
WHERE S1.StudentId<S2.StudentId AND
S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
Výstup výše uvedeného skriptu nám ukazuje pouze duplicitní záznamy:

Hledání duplikátů metodou self-referencing-2
Dalším způsobem, jak najít duplikáty pomocí vlastního odkazování, je použít INNER JOIN následovně:
-- Self-Referencing method 2 to find duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
INNER JOIN
[dbo].[Student] S2
ON S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
WHERE S1.StudentId<S2.StudentId

Odstranění duplikátů metodou vlastního odkazování
Duplikáty můžeme odstranit stejnou metodou, kterou jsme použili k nalezení duplikátů, s výjimkou použití DELETE v souladu s jeho syntaxí takto:
USE UniversityV2
-- Removing duplicates by using Self-Referencing method
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
Kontrola dat po odstranění duplikátů
Po odstranění duplikátů rychle zkontrolujme záznamy:
USE UniversityV2
-- View Student data after duplicates have been removed
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
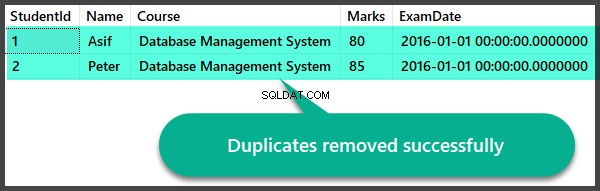
Vytváření duplikátů Zobrazení a odstranění duplicitních uložených procedur
Nyní, když víme, že naše skripty dokážou úspěšně najít a odstranit duplicitní řádky v SQL, je lepší je přeměnit na zobrazení a uloženou proceduru pro snadné použití:
USE UniversityV2;
GO
-- Creating view find duplicate students having same name, course, marks, exam date using Self-Referencing method
CREATE VIEW dbo.Duplicates
AS
SELECT
S1.[StudentId] AS S1_StudentId
,S2.StudentId AS S2_StudentID
,S1.Name AS S1_Name
,S2.Name AS S2_Name
,S1.Course AS S1_Course
,S2.Course AS S2_Course
,S1.ExamDate AS S1_ExamDate
,S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
,[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
GO
-- Creating stored procedure to removing duplicates by using Self-Referencing method
CREATE PROCEDURE UspRemoveDuplicates
AS
BEGIN
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
END
Přidání a zobrazení více duplicitních záznamů
Nyní přidejte další čtyři záznamy do Student tabulka a všechny záznamy jsou duplikáty takovým způsobem, že mají stejný název, kurz, známky a datum zkoušky:
--Adding multiple duplicates to Student table
INSERT INTO Student (Name,
Course,
Marks,
ExamDate)
VALUES ('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01');
-- Viewing Student table after multiple records have been added to Student table
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
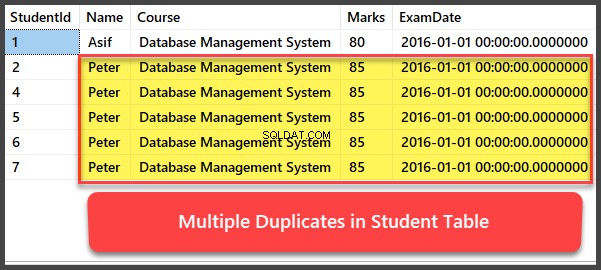
Odstranění duplicit pomocí procedury UspRemoveDuplicates
USE UniversityV2
-- Removing multiple duplicates
EXEC UspRemoveDuplicates
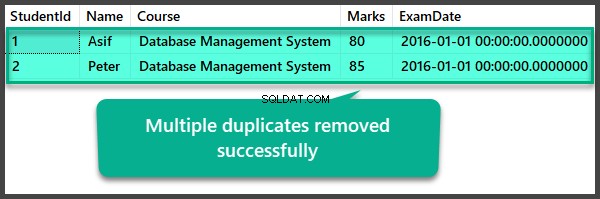
Kontrola dat po odstranění více duplikátů
USE UniversityV2
--View Student table after multiple duplicates removal
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Případ 02:Přidávání a odebírání duplikátů se stejnými ID
Dosud jsme identifikovali duplicitní záznamy s odlišnými ID, ale co když jsou ID stejná.
Představte si například scénář, ve kterém byla tabulka nedávno importována z textového nebo excelového souboru, který nemá primární klíč.
Předpoklady
V tomto případě se říká, že tabulka má duplicitní záznamy, pokud jsou všechny hodnoty sloupců naprosto stejné, včetně některého sloupce ID a chybí primární klíč, což usnadňuje zadávání duplicitních záznamů.
Vytvořit tabulku kurzů bez primárního klíče
Abychom reprodukovali scénář, ve kterém duplicitní záznamy při absenci primárního klíče spadají do tabulky, nejprve vytvořte nový kurz tabulky bez primárního klíče v databázi University2 takto:
USE UniversityV2
-- Creating Course table without primary key
CREATE TABLE [dbo].[Course] (
[CourseId] INT NOT NULL,
[Name] VARCHAR (30) NOT NULL,
[Detail] VARCHAR (200) NULL,
);
Vyplnění tabulky kurzů
-- Populating Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Tabular Data Modeling', N'This is about Tabular Data Modeling')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')
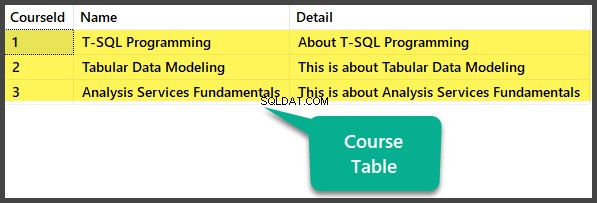
Kontrola dat
Zobrazit kurz tabulka:
USE UniversityV2
-- Viewing Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course
Přidání duplicitních dat do tabulky kurzů
Nyní vložte duplikáty do kurzu tabulka:
USE UniversityV2
-- Inserting duplicate records in Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
Zobrazit duplicitní data kurzu
Chcete-li zobrazit tabulku, vyberte všechny sloupce:
USE UniversityV2
-- Viewing duplicate data in Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course

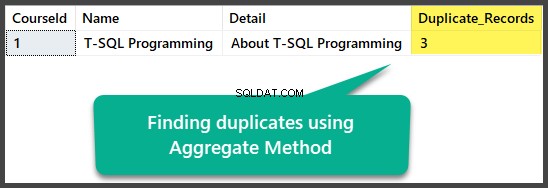
Hledání duplikátů agregační metodou
Přesné duplikáty můžeme najít pomocí agregační metody seskupením všech sloupců s celkovým počtem více než jednoho po výběru všech sloupců spolu s počítáním všech řádků pomocí funkce agregace count(*):
-- Finding duplicates using Aggregate method
SELECT <column1>,<column2>,<column3>…
,COUNT(*) AS Total_Records
FROM <Table>
GROUP BY <column1>,<column2>,<column3>…
HAVING COUNT(*)>1
To lze použít následovně:
USE UniversityV2
-- Finding duplicates using Aggregate method
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
Odstranění duplikátů agregační metodou
Odstraňme duplikáty pomocí Aggregate Method následovně:
USE UniversityV2
-- Removing duplicates using Aggregate method
-- (1) Finding duplicates and put them into a new table (CourseNew) as a single row
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records INTO CourseNew
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
-- (2) Rename Course (which contains duplicates) as Course_OLD
EXEC sys.sp_rename @objname = N'Course'
,@newname = N'Course_OLD'
-- (3) Rename CourseNew (which contains no duplicates) as Course
EXEC sys.sp_rename @objname = N'CourseNew'
,@newname = N'Course'
-- (4) Insert original distinct records into Course table from Course_OLD table
INSERT INTO Course (CourseId, Name, Detail)
SELECT
co.CourseId
,co.Name
,co.Detail
FROM Course_OLD co
WHERE co.CourseId <> (SELECT
c.CourseId
FROM Course c)
ORDER BY CO.CourseId
-- (4) Data check
SELECT
cn.CourseId
,cn.Name
,cn.Detail
FROM Course cn
-- Clean up
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
Kontrola dat
POUŽÍVEJTE UniversityV2
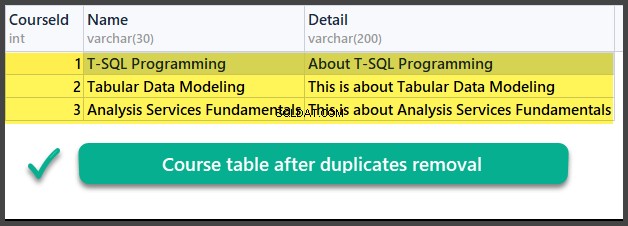
Úspěšně jsme se tedy naučili, jak odstranit duplikáty z databázové tabulky pomocí dvou různých metod založených na dvou různých scénářích.
Co dělat
Nyní můžete snadno identifikovat databázovou tabulku a zbavit ji duplicitní hodnoty.
1. Zkuste vytvořit UspRemoveDuplicatesByAggregate uložená procedura založená na metodě uvedené výše a odstranění duplikátů voláním uložené procedury
2. Zkuste upravit výše vytvořenou uloženou proceduru (UspRemoveDuplicatesByAggregates) a implementujte tipy pro vyčištění uvedené v tomto článku.
DROP TABLE CourseNew
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
3. Můžete si být jisti, že UspRemoveDuplicatesByAggregate uloženou proceduru lze provést tolikrát, kolikrát je to možné, dokonce i po odstranění duplikátů, aby se ukázalo, že procedura zůstává konzistentní?
4. Přečtěte si můj předchozí článek Jump to Start Test-Driven Database Development (TDDD) – Part 1 a zkuste vložit duplikáty do tabulek databáze SQLDevBlog, poté zkuste duplikáty odstranit pomocí obou metod uvedených v tomto tipu.
5. Zkuste prosím vytvořit jinou vzorovou databázi EmployeesSample s odkazem na můj předchozí článek Umění izolovat závislosti a data v testování databázových jednotek a vložte duplikáty do tabulek a zkuste je odstranit pomocí obou metod, které jste se naučili z tohoto tipu.
Užitečný nástroj:
dbForge Data Compare for SQL Server – výkonný nástroj pro porovnání SQL schopný pracovat s velkými daty.