Následuje výňatek z našeho whitepaperu „Jak navrhovat vysoce dostupná databázová prostředí s otevřeným zdrojovým kódem“, který si můžete zdarma stáhnout.
Pár slov o „vysoké dostupnosti“
V dnešní době je vysoká dostupnost nutností pro jakékoli seriózní nasazení. Dávno pryč jsou dny, kdy jste mohli naplánovat odstávku databáze na několik hodin kvůli provedení údržby. Pokud vaše služby nejsou dostupné, přicházíte o zákazníky a peníze. Vysoká dostupnost databázového prostředí má proto obvykle jednu z nejvyšších priorit.
To představuje značnou výzvu pro správce databází. Za prvé, jak poznáte, zda je vaše prostředí vysoce dostupné nebo ne? Jak byste to změřili? Jaké kroky musíte podniknout, abyste zlepšili dostupnost? Jak navrhnout své nastavení, aby bylo od začátku vysoce dostupné?
V ekosystému MySQL (a MariaDB) je k dispozici mnoho řešení HA, ale jak poznáme, kterým z nich můžeme důvěřovat? Některá řešení mohou fungovat za určitých specifických podmínek, ale při použití mimo tyto podmínky mohou způsobit větší potíže. Dokonce i základní funkce, jako je replikace MySQL, kterou lze konfigurovat mnoha způsoby, může způsobit značné škody – například cyklická replikace s více zapisovatelnými mastery. Přestože je snadné nastavit „multimaster setup“ pomocí replikace, může se velmi snadno rozbít a zanechat nám rozdílné datové sady na různých serverech. Pro databázi, která je často považována za jediný zdroj pravdy, může mít narušená integrita dat katastrofální následky.
V následujících kapitolách probereme požadavky na vysokou dostupnost v databázových
nastaveních a jak navrhnout systém od základů.
Měření vysoké dostupnosti
Co je to vysoká dostupnost? Abychom se mohli rozhodnout, zda je dané prostředí vysoce dostupné nebo ne, musíme mít na to nějaké metriky. Existuje mnoho způsobů, jak měřit vysokou dostupnost, my se zaměříme na některé z nejzákladnějších věcí.
Nejprve se však zamysleme, o čem celá tato vysoká dostupnost je? jaký je jeho účel? Jde o to, aby vaše prostředí sloužilo svému účelu. Účel lze definovat mnoha způsoby, ale obvykle se bude jednat o poskytování nějaké služby. Ve světě databází to obvykle trochu souvisí s daty. Může to být poskytování dat vaší interní aplikaci. Může to být ukládání dat a jejich zjišťování analytickými procesy. Může to být uložení některých dat pro vaše uživatele a jejich poskytnutí na požádání. Jakmile máme jasno o účelu, můžeme stanovit faktory úspěchu. To nám pomůže definovat, co v našem konkrétním případě znamená vysoká dostupnost.
SLA
Smlouva o úrovni služeb (SLA). Je také zcela běžné definovat SLA pro interní služby. Co je SLA? Je to definice úrovně služeb, kterou plánujete poskytovat svým zákazníkům. Je to pro ně, aby lépe pochopili, jakou úroveň stability plánujete pro službu, kterou si koupili nebo plánují koupit. Existuje mnoho metod, které můžete využít k přípravě SLA, ale typické jsou:
- Dostupnost služby (procenta)
- Reakce služby – latence (průměrná, maximální, 95 percentil, 99 percentil)
- Ztráta paketů v síti (procenta)
- Propustnost (průměr, minimum, 95 percentil, 99 percentil)
Může to být ale složitější. Ve sdíleném prostředí pro více uživatelů můžete definovat, řekněme, svou smlouvu SLA jako:„Služba bude dostupná 99,99 % času, výpadek je deklarován, když se to dotkne více než 2 % uživatelů. Vyřešení žádného incidentu nemůže trvat déle než 15 minut." Takovou smlouvu SLA lze také rozšířit tak, aby zahrnovala dobu odezvy na dotaz:„prostoj je volán, pokud 99 percentil latence pro dotazy překročí 200 milisekund“.
Devítky
Dostupnost se obvykle měří v „devítkách“, podívejme se, co přesně dané množství „devítek“ zaručuje. Níže uvedená tabulka je převzata z Wikipedie:
| Dostupnost % | Prostoj za rok | Prostoj za měsíc | Týdenní výpadky | Prostoj za den |
|---|---|---|---|---|
| 90 % („jedna devět“) | 36,5 dne | 72 hodin | 16,8 hodin | 2,4 hodiny |
| 95 % („jedna a půl devítky“) | 18,25 dne | 36 hodin | 8,4 hodiny | 1,2 hodiny |
| 97 % | 10,96 dne | 21,6 hodin | 5,04 hodin | 43,2 min |
| 98 % | 7,30 dne | 14,4 hodiny | 3,36 hodin | 28,8 min |
| 99 % ("dvě devítky") | 3,65 dne | 7,20 hodin | 1,68 hodiny | 14,4 min |
| 99,5 % ("dvě a půl devítky") | 1,83 dne | 3,60 hodin | 50,4 min | 7,2 min |
| 99,8 % | 17,52 hodin | 86,23 min | 20,16 min | 2,88 min |
| 99,9 % („tři devítky“) | 8,76 hodin | 43,8 min | 10,1 min | 1,44 min |
| 99,95 % („tři a půl devítky“) | 4,38 hodin | 21,56 min | 5,04 min | 43,2 s |
| 99,99 % („čtyři devítky“) | 52,56 min | 4,38 min | 1,01 min | 8,64 s |
| 99,995 % ("čtyři a půl devítky") | 26,28 min | 2,16 min | 30,24 s | 4,32 s |
| 99,999 % („pět devítek“) | 5,26 min | 25,9 s | 6,05 s | 864,3 ms |
| 99,9999 % ("šest devítek") | 31,5 s | 2,59 s | 604,8 ms | 86,4 ms |
| 99,99999 % ("sedm devítek") | 3,15 s | 262,97 ms | 60,48 ms | 8,64 ms |
| 99,999999 % ("osm devítek") | 315,569 ms | 26,297 ms | 6,048 ms | 0,864 ms |
| 99,9999999 % ("devět devítek") | 31,5569 ms | 2,6297 ms | 0,6048 ms | 0,0864 ms |
Jak vidíme, rychle se to stupňuje. Pět devítek (99 999% dostupnost) odpovídá 5,26 minutám odstávky v průběhu roku. Dostupnost lze také vypočítat v různých menších rozsazích:za měsíc, za týden, za den. Mějte na paměti tato čísla, protože budou užitečná, až začneme diskutovat o nákladech spojených s udržováním různých úrovní dostupnosti.
Měření dostupnosti
Chcete-li zjistit, zda došlo k prostojům nebo ne, musíte mít vhled do prostředí. Musíte sledovat metriky, které definují dostupnost vašich systémů. Je důležité mít na paměti, že byste to měli měřit z pohledu zákazníka a brát v úvahu širší obrázek. Nezáleží na tom, zda jsou vaše databáze aktivní, pokud se k nim, řekněme, kvůli problému se sítí žádná aplikace nedostane. Každý jednotlivý stavební blok vašeho nastavení má vliv na dostupnost.
Jedním z dobrých míst, kde hledat údaje o dostupnosti, jsou protokoly webového serveru. Všechny požadavky, které skončily s chybami, znamenají, že se něco stalo. Může to být chyba HTTP 500 vrácená aplikací, protože selhalo připojení k databázi. Mohly by to být programové chyby poukazující na některé problémy s databází, které skončily v protokolu chyb Apache. Jako uptime databázových serverů můžete také použít jednoduchou metriku, i když u složitějších SLA může být obtížné určit, jak nedostupnost jedné databáze ovlivnila vaši uživatelskou základnu. Bez ohledu na to, co děláte, měli byste použít více než jednu metriku – to je potřeba k zachycení problémů, které se mohly vyskytnout v různých vrstvách vašeho prostředí.
Magické číslo:„Tři“
I když vysoká dostupnost je také o redundanci, v případě databázových clusterů jsou tři magické číslo. Pro redundanci nestačí mít dva uzly – takové nastavení neposkytuje žádnou vestavěnou vysokou dostupnost. Jistě, může to být lepší než jen jeden uzel, ale k obnovení služeb je nutný lidský zásah. Podívejme se, proč tomu tak je.
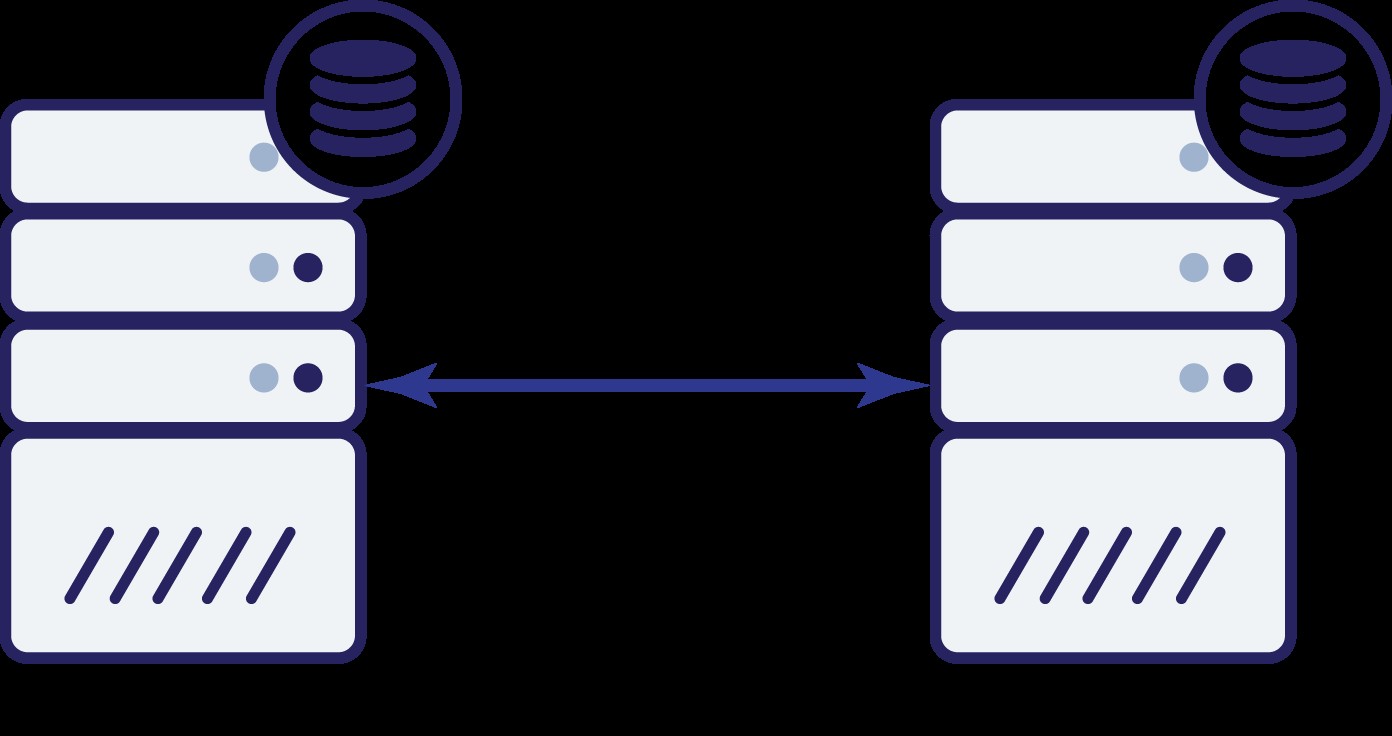
Předpokládejme, že máme dva uzly, A a B. Mezi nimi je síťové spojení. Předpokládejme, že A i B obsluhují zápisy a aplikace náhodně vybírá, kam se má připojit (což znamená, že část aplikace se připojí k uzlu A a druhá část k uzlu B). Nyní si představme, že máme problém se sítí, který má za následek ztrátu síťového připojení mezi A a B.
Co teď? Ani A, ani B nemohou znát stav druhého uzlu. Oba uzly mohou provádět dvě akce:
- Mohou nadále přijímat provoz
- Mohou přestat fungovat a odmítnout obsluhovat jakýkoli provoz
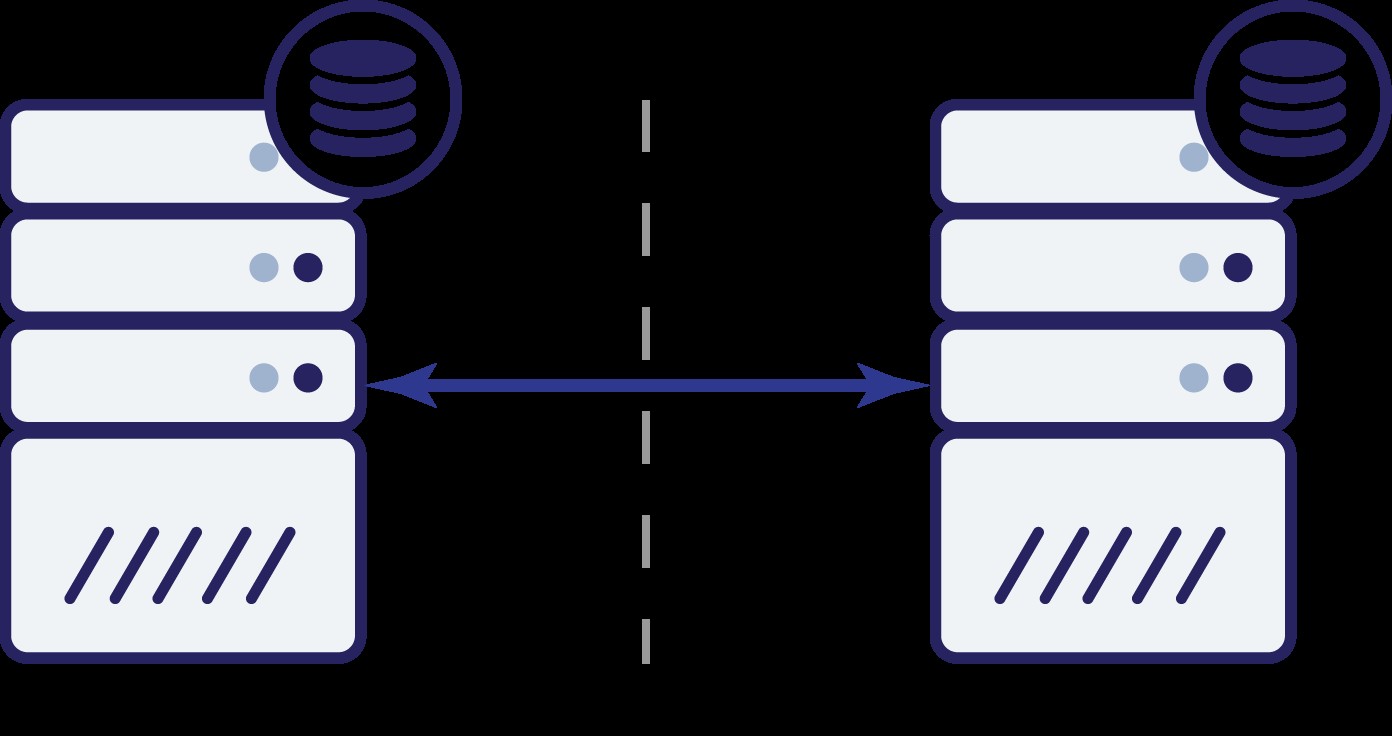
Zamysleme se nad první možností. Dokud je druhý uzel skutečně mimo provoz, jedná se o preferovanou akci – chceme, aby naše databáze nadále obsluhovala provoz. To je ostatně hlavní myšlenka vysoké dostupnosti. Co by se však stalo, kdyby oba uzly nadále přijímaly provoz, zatímco by byly navzájem odpojeny? Na obou stranách budou přidána nová data a datové sady se nebudou synchronizovat. Až bude problém se sítí vyřešen, bude sloučení těchto dvou datových sad náročný úkol. Proto není přijatelné udržovat oba uzly v provozu. Problém je - jak může uzel A zjistit, zda je uzel B živý nebo ne (a naopak)? Odpověď zní – nemůže. Pokud dojde k výpadku veškerého připojení, neexistuje způsob, jak rozlišit neúspěšný uzel od neúspěšné sítě. Výsledkem je, že jedinou bezpečnou akcí je pro oba uzly zastavit veškerý provoz a odmítnout
obsluhovat provoz.
Pojďme se nyní zamyslet nad tím, jak nám v takové situaci může pomoci třetí uzel.
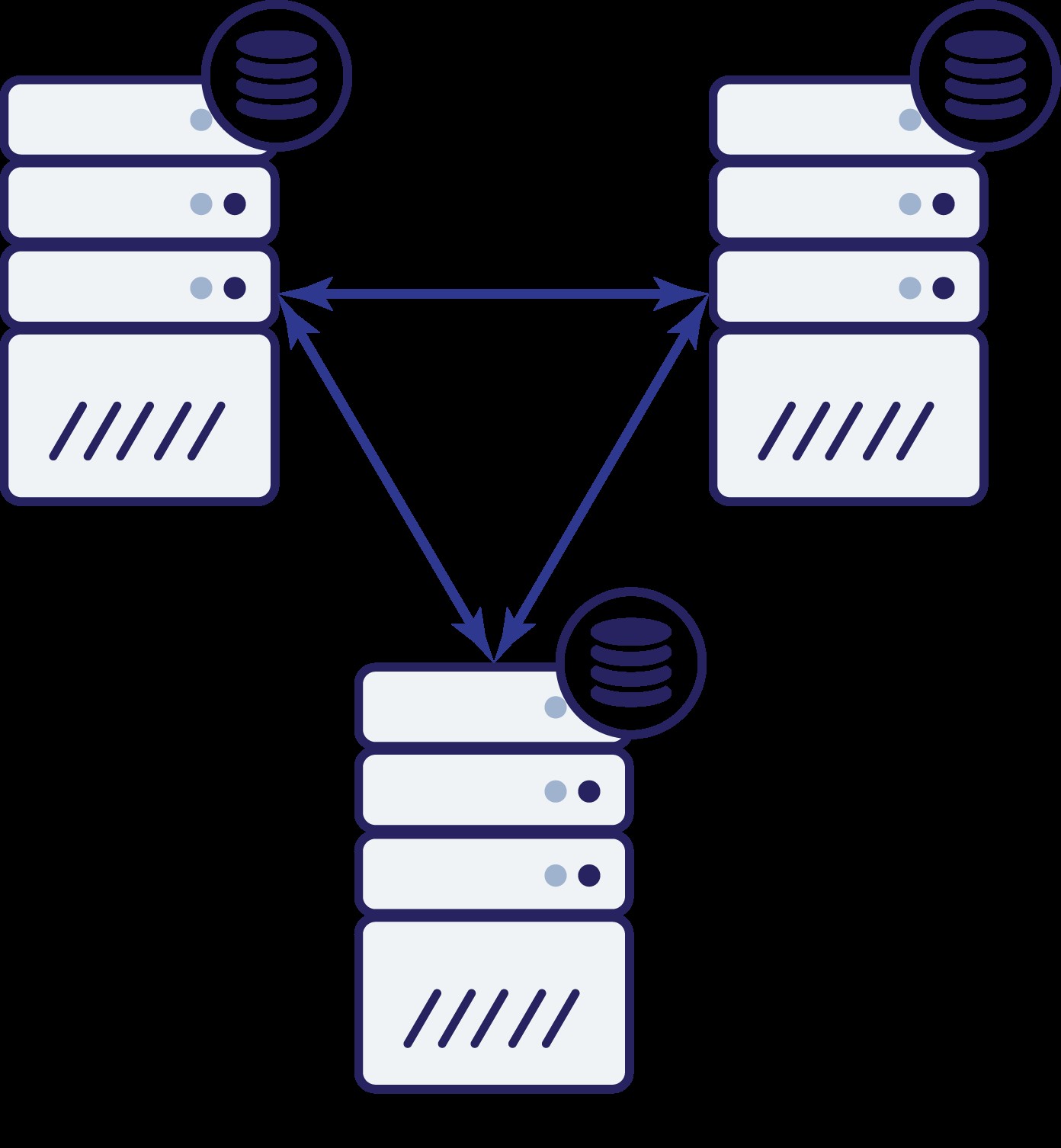
Nyní tedy máme tři uzly:A, B a C. Všechny jsou propojené, všechny se starají o čtení a zápis.
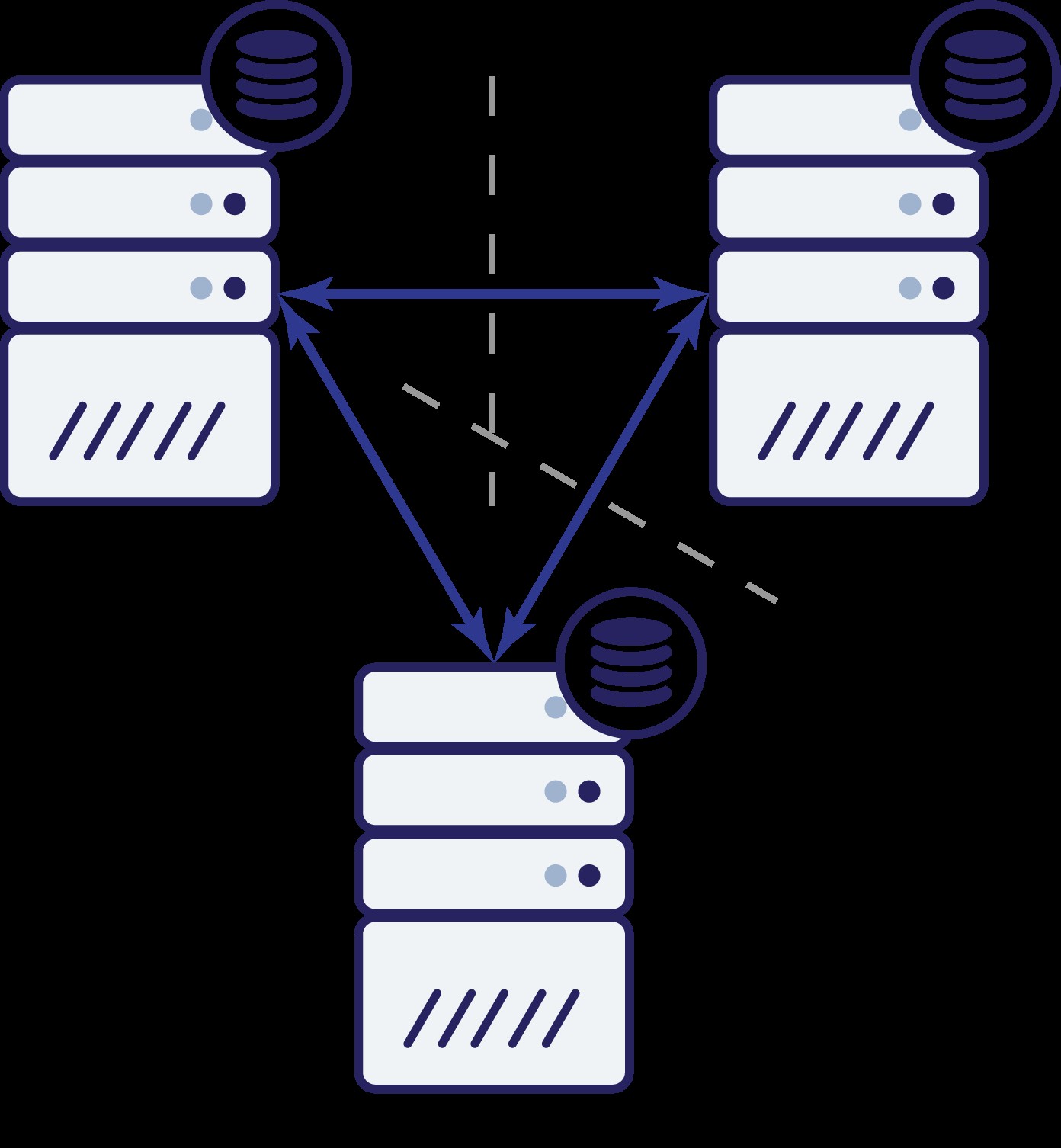
Opět, stejně jako v předchozím příkladu, byl uzel B odříznut od zbytku clusteru kvůli problémům se sítí. Co se může stát dál? No, situace je docela podobná té, o které jsme hovořili dříve. Dvě možnosti – uzel B může být buď dole (a zbytek clusteru by měl pokračovat), nebo může být nahoře, v takovém případě by neměl mít povoleno zpracovávat žádný provoz. Můžeme nyní říci, jaký je stav shluku? Vlastně ano. Vidíme, že uzly A a C spolu mohou mluvit a v důsledku toho se mohou dohodnout, že uzel B není dostupný. Nebudou schopni říct, proč se to stalo, ale vědí, že ze tří uzlů v klastru jsou dva mezi sebou stále propojeny. Vzhledem k tomu, že tyto dva uzly tvoří většinu clusteru, je možné pokračovat v řízení provozu. Současně může uzel B také odvodit, že problém je na jeho straně. Nemůže přistupovat k uzlu A ani k uzlu C, takže uzel B je oddělený od zbytku klastru. Jelikož je izolovaná a není součástí většiny (1 ze 3), jedinou bezpečnou akcí, kterou může podniknout, je zastavit provoz a odmítnout přijímat jakékoli dotazy, čímž zajistíte, že nedojde k přesunu dat.
Samozřejmě to neznamená, že můžete mít v clusteru pouze tři uzly. Pokud chcete lepší odolnost proti selhání, možná budete chtít přidat další. Mějte však na paměti, že pokud chcete zlepšit vysokou dostupnost, mělo by to být liché číslo. Ve výše uvedených příkladech jsme také hovořili o „uzlech“. Mějte prosím na paměti, že to platí také pro datová centra, zóny dostupnosti atd. Pokud máte dvě datová centra, z nichž každé má stejný počet uzlů (řekněme tři uzly každý), a ztratíte konektivitu mezi těmito dvěma DC, platí zde stejné zásady - nemůžete určit, která polovina clusteru by měla začít provozovat. Abyste to mohli říct, musíte mít pozorovatele ve třetím datovém centru. Může to být ještě další sada uzlů nebo jen jeden hostitel s úkolem
sledovat stav zbývajících dataceterů a podílet se na rozhodování (příkladem může být arbitr Galera).
Jeden bod selhání
Vysoká dostupnost je o odstranění jednotlivých bodů selhání (SPOF) a nezavádění nových do procesu. Co jsou SPOFy? Jakákoli část vaší infrastruktury, která, když selže, způsobí výpadek definovaný v SLA, se nazývá SPOF. Návrh infrastruktury vyžaduje holistický přístup, různé komponenty nelze navrhovat nezávisle na sobě. S největší pravděpodobností nejste odpovědní za celý design -
správci databází mají tendenci se zaměřovat na databáze a ne například na síťovou vrstvu. Přesto musíte mít na paměti ostatní části a spolupracovat s týmy, které za ně zodpovídají, abyste se ujistili, že nejen část, za kterou zodpovídáte, je navržena správně, ale také že zbývající části infrastruktury byly navrženy pomocí stejné principy. Navíc taková znalost toho, jak je celá
infrastruktura navržena, vám pomůže navrhnout i databázový zásobník. Vědět, jaké problémy mohou nastat, pomáhá vytvořit určité mechanismy, které jim zabrání ovlivnit dostupnost databáze.