Jednotlivé predikáty
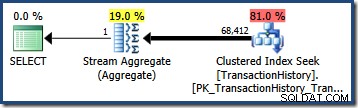
Odhad počtu řádků kvalifikovaných jedním predikátem dotazu je často přímočarý. Když predikát provede jednoduché srovnání mezi sloupcem a skalární hodnotou, je velká šance, že odhad mohutnosti bude schopen odvodit kvalitní odhad ze statistického histogramu. Například následující dotaz AdventureWorks vytváří přesně správný odhad 203 řádků (za předpokladu, že od vytvoření statistik nebyly provedeny žádné změny v datech):
SELECT COUNT_BIG(*)FROM Production.TransactionHistory AS THWHERE TH.TransactionDate ='20070903';
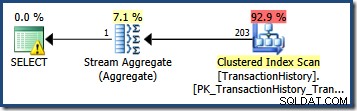
Podívejte se na statistický histogram pro TransactionDate je jasně vidět, odkud tento odhad pochází:
DBCC SHOW_STATISTICS ( 'Production.TransactionHistory', 'TransactionDate')S HISTOGRAMEM;
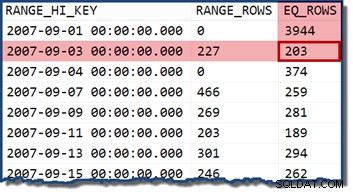
Pokud změníme dotaz tak, aby specifikoval datum, které spadá do segmentu histogramu, odhadce mohutnosti předpokládá, že hodnoty jsou rovnoměrně rozloženy. Použití data 2007-09-02 vytváří odhad 227 řádků (z RANGE_ROWS vstup). Zajímavou vedlejší poznámkou je, že odhad zůstává na 227 řádcích bez ohledu na jakoukoli časovou část, kterou bychom mohli přidat k hodnotě data (TransactionDate sloupec je datetime datový typ).
Pokud zkusíme dotaz znovu s datem 2007-09-05 nebo 2007-09-06 (obě spadají mezi 2007-09-04 a 2007-09-07 kroky histogramu), estimátor mohutnosti předpokládá 466 RANGE_ROWS jsou rovnoměrně rozděleny mezi dvě hodnoty, přičemž v obou případech se odhaduje 233 řádků.
Existuje mnoho dalších podrobností o odhadu mohutnosti pro jednoduché predikáty, ale výše uvedené poslouží jako osvěžení pro naše současné účely.
Problémy více predikátů
Pokud dotaz obsahuje více než jeden sloupcový predikát, je odhad mohutnosti obtížnější. Zvažte následující dotaz se dvěma jednoduchými predikáty (každý z nich lze snadno odhadnout samostatně):
SELECT COUNT_BIG(*)FROM Production.TransactionHistory AS THWHERE TH.TransactionID BETWEEN 100000 AND 168412 AND TH.TransactionDate BETWEEN '20070901' AND '20080313';
Konkrétní rozsahy hodnot v dotazu jsou záměrně zvoleny tak, aby oba predikáty identifikovaly přesně stejné řádky. Mohli bychom snadno upravit hodnoty dotazu tak, aby výsledkem bylo libovolné množství překrytí, včetně žádného překrytí. Představte si nyní, že jste odhadcem mohutnosti:jak byste odvodili odhad mohutnosti pro tento dotaz?
Problém je těžší, než by se na první pohled mohlo zdát. Ve výchozím nastavení SQL Server automaticky vytváří jednosloupcové statistiky pro oba predikátové sloupce. Vícesloupcové statistiky můžeme vytvářet i ručně. Poskytuje nám to dostatek informací k vytvoření dobrého odhadu pro tyto konkrétní hodnoty? A co obecnější případ, kdy mohou existovat nějaké stupeň překrývání?
Pomocí dvou jednosloupcových statistických objektů můžeme snadno odvodit odhad pro každý predikát pomocí metody histogramu popsané v předchozí části. U konkrétních hodnot ve výše uvedeném dotazu histogramy ukazují, že TransactionID Očekává se, že rozsah bude odpovídat 68412,4 řádků a TransactionDate Očekává se, že rozsah bude odpovídat 68 413 řádky. (Pokud by byly histogramy dokonalé, tato dvě čísla by byla úplně stejná.)
Co histogramy neumějí řekněte nám, kolik z těchto dvou sad řádků bude stejných řádků . Na základě informací z histogramu můžeme říci pouze to, že náš odhad by měl být někde mezi nulou (bez jakéhokoli překrytí) a 68412,4 řádků (úplné překrytí).
Vytváření vícesloupcové statistiky neposkytuje pro tento dotaz (nebo obecně pro dotazy na rozsah) žádnou pomoc. Vícesloupcové statistiky stále vytvářejí pouze histogram přes první jmenovaný sloupec, v podstatě duplikují histogram spojený s jednou z automaticky vytvořených statistik. Dodatečná hustota informace poskytované vícesloupcovou statistikou mohou být užitečné pro poskytování informací o průměrné velikosti písmen pro dotazy, které obsahují více predikátů rovnosti, ale zde nám nepomohou.
K vytvoření odhadu s vysokou mírou spolehlivosti bychom potřebovali, aby SQL Server poskytoval lepší informace o distribuci dat – něco jako vícerozměrné statistický histogram. Pokud vím, žádný komerční databázový stroj v současné době nenabízí takové zařízení, ačkoli na toto téma bylo publikováno několik technických dokumentů (včetně jednoho výzkumu společnosti Microsoft, který používal interní vývoj SQL Server 2000).
Bez znalosti datových korelací a překrývání pro konkrétní rozsahy hodnot není jasné, jak bychom měli postupovat, abychom vytvořili dobrý odhad pro náš dotaz. Co zde tedy SQL Server dělá?
SQL Server 7 – 2012
Odhad mohutnosti v těchto verzích SQL Server obecně předpokládá, že hodnoty různých atributů v tabulce jsou distribuovány zcela nezávisle na sobě. Tento předpoklad nezávislosti je zřídka přesným odrazem skutečných dat, ale má tu výhodu, že umožňuje jednodušší výpočty.
A Selektivita
Pomocí předpokladu nezávislosti jsou dva predikáty spojené AND (známé jako konjunkce ) se selektivitami S1 a S2 výsledkem je kombinovaná selektivita:
(S1 * S2)
V případě, že vám tento termín není znám, selektivita je číslo mezi 0 a 1, které představuje zlomek řádků v tabulce, které předávají predikát. Pokud například predikát vybere 12 řádků z tabulky o 100 řádcích, selektivita je (12/100) =0,12.
V našem příkladu TransactionHistory tabulka obsahuje celkem 113 443 řádků. Predikát na TransactionID odhaduje se (z histogramu) na kvalifikaci 68 412,4 řádků, takže selektivita je (68 412,4 / 113 443) nebo zhruba 0,603055 . Predikát TransactionDate podobně se odhaduje, že má selektivitu (68 413 / 113 443) =zhruba 0,603061 .
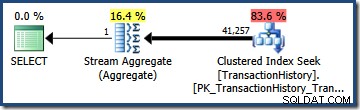
Vynásobením dvou selektivit (pomocí výše uvedeného vzorce) získáte kombinovaný odhad selektivity 0,363679 . Vynásobením této selektivity mohutností tabulky (113 443) získáme konečný odhad 41 256,8 řádky:
NEBO Selektivita
Dva predikáty spojené pomocí OR (disjunkce ) se selektivitami S1 a S2 výsledkem je kombinovaná selektivita:
(S1 + S2) – (S1 * S2)
Intuice za vzorcem je sečíst dvě selektivity a poté odečíst odhad pro jejich konjunkci (pomocí předchozího vzorce). Je jasné, že bychom mohli mít dva predikáty, každý se selektivitou 0,8, ale jejich jednoduchým sečtením by vznikla nemožná kombinovaná selektivita 1,6. Navzdory předpokladu nezávislosti musíme uznat, že se oba predikáty mohou překrývat, takže abychom se vyhnuli dvojímu započítání, odhadovaná selektivita konjunkce se odečte.
Náš běžící příklad můžeme snadno upravit tak, aby používal OR :
SELECT COUNT_BIG(*)FROM Production.TransactionHistory AS THWHERE TH.TransactionID BETWEEN 100000 AND 168412 OR TH.TransactionDate BETWEEN '20070901' AND '20080313';
Dosazení selektivity predikátu do OR vzorec dává kombinovanou selektivitu:
(0.603055 + 0.603061) - (0.603055 * 0.603061) = 0.842437
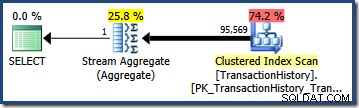
Tato selektivita vynásobená počtem řádků v tabulce nám dává konečný odhad mohutnosti 95 568,6 :
Ani jeden odhad (41 257 pro AND dotaz; 95 569 pro OR dotaz) je zvláště dobrý, protože oba jsou založeny na předpokladu modelování, který příliš dobře neodpovídá distribuci dat. Oba dotazy ve skutečnosti vrátí 68 413 řádky (protože predikáty identifikují přesně stejné řádky).
Trace Flag 4137 – Minimální selektivita
Pro SQL Server 2008 (R1) až 2012 včetně vydala společnost Microsoft opravu, která mění způsob výpočtu selektivity pro AND pouze pád (konjunktivní predikáty). Článek znalostní báze v tomto odkazu neobsahuje mnoho podrobností, ale ukázalo se, že oprava mění použitý vzorec selektivity. Namísto násobení jednotlivých selektiv se nyní odhad mohutnosti pro konjunktivní predikáty používá pouze s nejnižší selektivitou.
K aktivaci změněného chování je vyžadován podporovaný příznak trasování 4137. Samostatný článek znalostní báze dokládá, že tento příznak trasování je podporován také pro použití na dotaz prostřednictvím QUERYTRACEON nápověda:
SELECT COUNT_BIG(*)FROM Production.TransactionHistory AS THWHERE TH.TransactionID BETWEEN 100000 AND 168412 AND TH.TransactionDate BETWEEN '20070901' AND '20080313'OPTION);preQUERYTRA7CEONTION);Když je tento příznak aktivní, odhad mohutnosti používá minimální selektivitu dvou predikátů, což vede k odhadu 68 412,4 řádky:
To je pro náš dotaz téměř dokonalé, protože naše testovací predikáty jsou přesně korelované (a odhady odvozené ze základních histogramů jsou také velmi dobré).
Je poměrně vzácné, aby predikáty takto dokonale korelovaly se skutečnými daty, ale příznak trasování může přesto v některých případech pomoci. Všimněte si, že chování minimální selektivity bude platit pro všechny konjunktivy (
AND) predikáty v dotazu; neexistuje způsob, jak specifikovat chování na podrobnější úrovni.Neexistuje žádný odpovídající příznak trasování pro odhad disjunktivy (
OR) predikáty využívající minimální selektivitu.SQL Server 2014
Výpočet selektivity v SQL Server 2014 se chová stejně jako předchozí verze (a příznak trasování 4137 funguje jako dříve), pokud je úroveň kompatibility databáze nastavena na hodnotu nižší než 120 nebo pokud je příznak trasování 9481 je aktivní. Nastavení úrovně kompatibility databáze je oficiální způsob použití odhadu mohutnosti před rokem 2014 v SQL Server 2014. Příznak trasování 9481 je účinný při provádění stejné věci jako v době psaní tohoto článku a funguje také s
QUERYTRACEON, i když to není zdokumentováno. Neexistuje způsob, jak zjistit, jaké bude RTM chování tohoto příznaku.Pokud je aktivní nový odhad mohutnosti, SQL Server 2014 používá jiný výchozí vzorec pro kombinování konjunktivních a disjunktivních predikátů. Ačkoli to není zdokumentováno, vzorec selektivity pro konjunkce byl objeven a zdokumentován již několikrát. Pamatuji si, že první, který jsem viděl, je v tomto portugalském blogovém příspěvku a druhá část byla vydána o několik týdnů později. Abychom to shrnuli, přístup z roku 2014 ke konjunktivním predikátům je použít exponenciální backoff: daný stůl s mohutností C, a predikát selectivities S1 , S2 , S3 … Sn , kde S1 je nejselektivnější a Sn nejméně:
Estimate = C * S1 * SQRT(S2) * SQRT(SQRT(S3)) * SQRT(SQRT(SQRT(S4))) …Odhad je vypočítán jako nejselektivnější predikát vynásobený kardinalitou tabulky, vynásobený druhou odmocninou dalšího nejselektivnějšího predikátu a tak dále, přičemž každá nová selektivita získává další druhou odmocninu.
Připomínáme-li, že selektivita je číslo mezi 0 a 1, je jasné, že použití druhé odmocniny posune číslo blíže k 1. Výsledkem je zohlednění všech predikátů v konečném odhadu, ale snížení dopadu méně selektivních predikátů. exponenciálně. Tato myšlenka má pravděpodobně větší logiku než předpoklad nezávislosti , ale stále jde o pevný vzorec – nemění se na základě skutečného stupně korelace dat.
Odhad mohutnosti pro rok 2014 používá exponenciální ústupový vzorec pro obě konjunktivní a disjunktivní predikáty, i když vzorec použitý v disjunktivu (
OR) případ ještě nebyl zdokumentován (oficiálně ani jinak).Příznaky trasování selektivity SQL Server 2014
Příznak trasování 4137 (pro použití minimální selektivity) ne pracovat v SQL Server 2014, pokud se při sestavování dotazu použije nový odhad mohutnosti. Místo toho je zde nový příznak trasování 9471 . Když je tento příznak aktivní, použije se minimální selektivita k odhadu více konjunktivních a disjunktivních predikáty. Toto je změna oproti chování 4137, které ovlivnilo pouze konjunktivní predikáty.
Podobně příznak trasování 9472 lze zadat tak, aby předpokládala nezávislost pro více predikátů, jak to dělaly předchozí verze. Tento příznak se liší od 9481 (pro použití odhadu mohutnosti před rokem 2014), protože pod 9472 se bude stále používat nový odhad mohutnosti, ovlivněn je pouze vzorec selektivity pro více predikátů.
9471 ani 9472 nejsou v době psaní tohoto článku zdokumentovány (ačkoli mohou být v RTM).
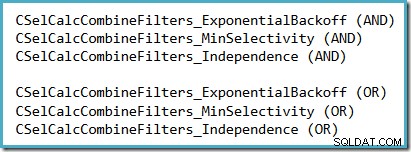
Pohodlný způsob, jak zjistit, který předpoklad selektivity se používá v SQL Server 2014 (s aktivním novým estimátorem mohutnosti), je prozkoumat výstup ladění výpočtu selektivity vytvořený při příznaku trasování 2363 a 3604 jsou aktivní. Část, kterou je třeba hledat, se týká kalkulátoru selektivity, který kombinuje filtry, kde uvidíte jeden z následujících v závislosti na tom, který předpoklad je použit:
Neexistuje žádná reálná vyhlídka, že 2363 bude zdokumentován nebo podporován.
Poslední myšlenky
Na exponenciálním ústupu, minimální selektivitě nebo nezávislosti není nic magického. Každý přístup představuje (velmi) zjednodušující předpoklad, který může nebo nemusí poskytnout přijatelné odhady pro jakýkoli konkrétní dotaz nebo distribuci dat.
V některých ohledech exponenciální ústup představuje kompromis mezi dvěma extrémy nezávislosti a minimální selektivita . I tak je důležité nemít od toho nepřiměřená očekávání. Dokud nebude nalezen přesnější způsob odhadu selektivity pro více predikátů (s přiměřenými výkonnostními charakteristikami), zůstává důležité být si vědom omezení modelu a podle toho dávat pozor na (potenciální) chyby v odhadu.
Různé příznaky trasování poskytují určitou kontrolu nad tím, který předpoklad se použije, ale situace není zdaleka dokonalá. Za prvé, nejjemnější granularita, se kterou lze příznak použít, je jediný dotaz – chování odhadu nelze specifikovat na úrovni predikátu. Pokud máte dotaz, kde jsou některé predikáty korelované a jiné nezávislé, příznaky trasování vám nemusí moc pomoci, aniž byste dotaz tím či oním způsobem refaktorovali. Stejně tak problematický dotaz může mít predikátové korelace, které nejsou dobře modelovány žádnou z dostupných možností.
Ad-hoc použití příznaků trasování vyžaduje stejná oprávnění jako
DBCC TRACEON– jmenovitě sysadmin . To je pravděpodobně v pořádku pro osobní testování, ale pro produkci použijte průvodce plánem pomocíQUERYTRACEONnápověda je lepší varianta. S průvodcem plánem nejsou k provedení dotazu vyžadována žádná další oprávnění (ačkoli jsou k vytvoření průvodce plánem samozřejmě vyžadována zvýšená oprávnění).