Zapojení do ladění výkonu může skončit tak, že se během něj vystřídá mnoho střídání – vše závisí na tom, co se ukazuje jako problém a co vám řeknou data. Některé dny přistane na konkrétním dotazu nebo sadě dotazů, které lze vylepšit pomocí indexů – buď nových, nebo úprav stávajících indexů. Jednou z mých oblíbených částí ladění je práce s indexy a když jsem přemýšlel o tomto příspěvku, byl jsem v pokušení označit ladění indexů jako „snazší“ úkol… ale ve skutečnosti tomu tak není.
Ladění indexů považuji za umění a vědu. Musíte se snažit myslet jako optimalizátor a musíte rozumět schématu tabulky a dotazu (nebo dotazům), který se snažíte vyladit. Oba jsou založeny na datech, a proto spadají do kategorie vědy. Umělecká složka vstupuje do hry, když přemýšlíte o jiném indexy v tabulce a všechny ostatní dotazy, které zahrnují tabulku, která by mohla být ovlivněna změnami indexu.
Krok 1:Identifikujte dotaz a zkontrolujte plán
Když identifikuji dotaz, který by mohl těžit z indexu, okamžitě dostanu jeho plán. Plán provádění často získám z mezipaměti plánu nebo úložiště dotazů a poté pomocí SSMS získám plán provádění plus statistiky za běhu (neboli skutečný plán provádění). Mnohokrát je tvar těchto dvou plánů stejný; ale není to záruka, a proto rád vidím obojí.
V plánu může chybět doporučení indexu, může mít skenování seskupeného indexu (nebo skenování haldy, pokud žádný seskupený index neexistuje), může používat neshlukovaný index, ale pak má vyhledávání k načtení dalších sloupců. Oprava každého z těchto problémů jednotlivě zní docela snadno. Stačí přidat chybějící index, že? Pokud existuje skenování seskupeného indexu nebo haldy, vytvořte index, který potřebuji pro dotaz, a hotovo? Nebo pokud se používá index, ale přejde do tabulky, aby získal další sloupce, stačí přidat sloupce do tohoto indexu?
Obvykle to není tak snadné, a i když je, stále procházím procesem, který zde popisuji.
Krok 2:Určete, které tabulky chcete zkontrolovat
Nyní, když mám dotaz, musím zjistit, které tabulky nejsou správně indexovány. Kromě kontroly plánu povoluji také statistiky IO a TIME v SSMS. To je pravděpodobně ode mě stará škola, protože prováděcí plány obsahují s každým vydáním stále více informací – včetně doby trvání a čísel IO na operátora, ale líbí se mi statistika IO, protože rychle vidím hodnoty pro každou tabulku. U dotazů, které jsou složité s více spojeními nebo poddotazy nebo CTE nebo vnořenými pohledy, pochopení toho, kde se tráví vstup a/nebo čas v dotazu, vede k tomu, kde trávím čas. Kdykoli je to od tohoto bodu možné, vezmu větší, komplexní dotaz a zredukuji jej na část, která způsobuje největší problém.
Pokud například existuje dotaz, který se připojuje k 10 tabulkám a má dva dílčí dotazy, plán (spolu s informacemi o IO a trvání) mi pomůže určit, kde problém existuje. Pak vytáhnu tu část dotazu – problematickou tabulku a možná pár dalších, ke kterým se připojuje – a zaměřím se na ni. Někdy je to jen dílčí dotaz, takže začnu tam.
Krok 3:Podívejte se na existující indexy
S definovaným dotazem (nebo částí dotazu) se pak zaměřím na existující indexy pro příslušné tabulky. V tomto kroku se spoléhám na Kimberlyinu verzi sp_helpindex. Mnohem preferuji její verzi před standardním sp_helpindex, protože také uvádí zahrnuty sloupce a definici filtru (pokud existuje). V závislosti na počtu indexů, které se pro tabulku zobrazí, to často zkopíruji a vložím do Excelu a poté seřadím na základě klíče indexu a poté zahrnutých sloupců. To mi umožňuje rychle najít jakékoli nadbytečné.
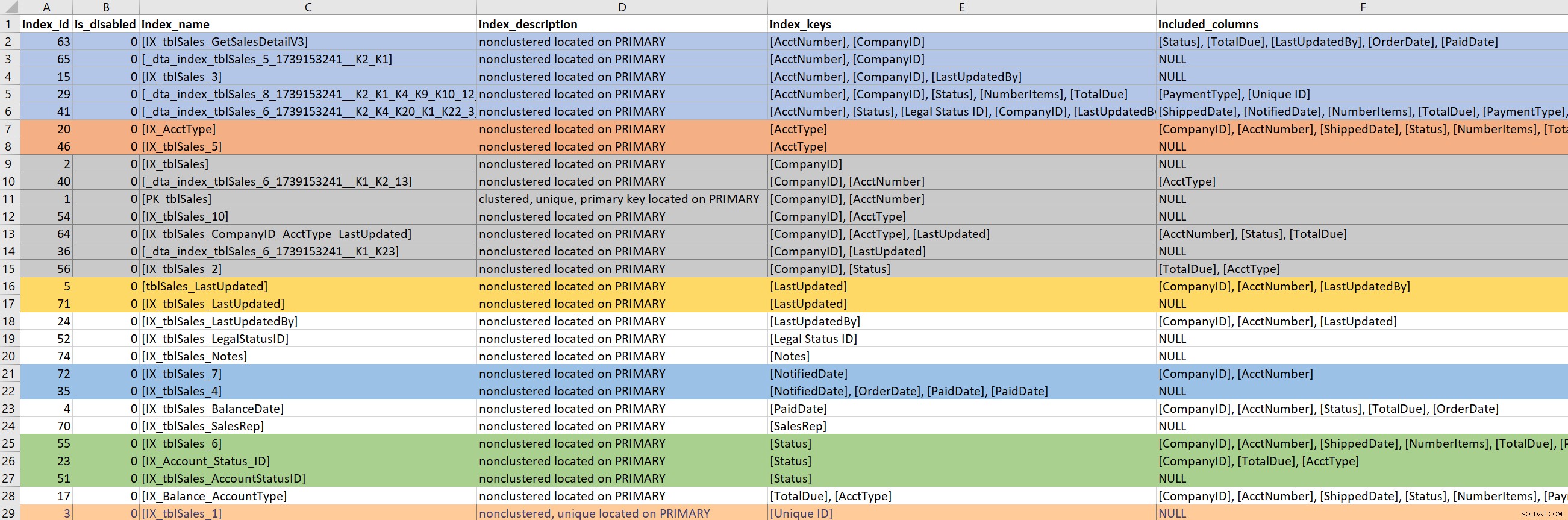
Na základě výše uvedeného příkladu výstupu existuje sedm indexů, které začínají na CompanyID, pět, které začínají na AcctNumber, a některé další potenciální redundance. I když se zdá ideální mít jen jeden index, který vede na konkrétní sloupec (např. CompanyID), pro některé vzory dotazů to nestačí.
Když se dívám na existující indexy, je velmi snadné jít do králičí nory. Podívám se na výstup výše a hned se začnu ptát, proč existuje sedm indexů, které začínají na CompanyID, a chci vědět, kdo je vytvořil, proč a na jaký dotaz. Ale… pokud můj problematický dotaz nepoužívá CompanyID, mělo by mi to být jedno? Ano… protože obecně jsem tu od toho, abych zlepšil výkon, a pokud to znamená, že se po cestě podívám na další indexy na stole, tak budiž. Ale tady je snadné ztratit pojem o čase (a skutečném účelu).
Pokud můj problematický dotaz potřebuje index, který vede na PaidDate, musím se vypořádat pouze s jedním existujícím indexem. Pokud můj problematický dotaz potřebuje index, který vede na AcctNumber, je to složitější. Když existující indexy nějakým způsobem pokrývají dotaz a já chci index rozšířit (přidat další sloupce) nebo konsolidovat (sloučit dva nebo možná tři indexy do jednoho), musím se do toho pustit.
Krok 4:Statistiky využití indexu
Zjistil jsem, že mnoho lidí průběžně nezachycuje statistiky využití indexu. To je nešťastné, protože data považuji za užitečná při rozhodování, které indexy ponechat a které vypustit nebo sloučit. V případě, že nemám historické statistiky využití, alespoň zkontroluji, jak využití aktuálně vypadá (od posledního restartu služby):
SELECT
DB_NAME(ius.database_id),
OBJECT_NAME(i.object_id) [TableName],
i.name [IndexName],
ius.database_id,
i.object_id,
i.index_id,
ius.user_seeks,
ius.user_scans,
ius.user_lookups,
ius.user_updates
FROM sys.indexes i
INNER JOIN sys.dm_db_index_usage_stats ius
ON ius.index_id = i.index_id AND ius.object_id = i.object_id
WHERE ius.database_id = DB_ID(N'Sales2020')
AND i.object_id = OBJECT_ID('dbo.tblSales');
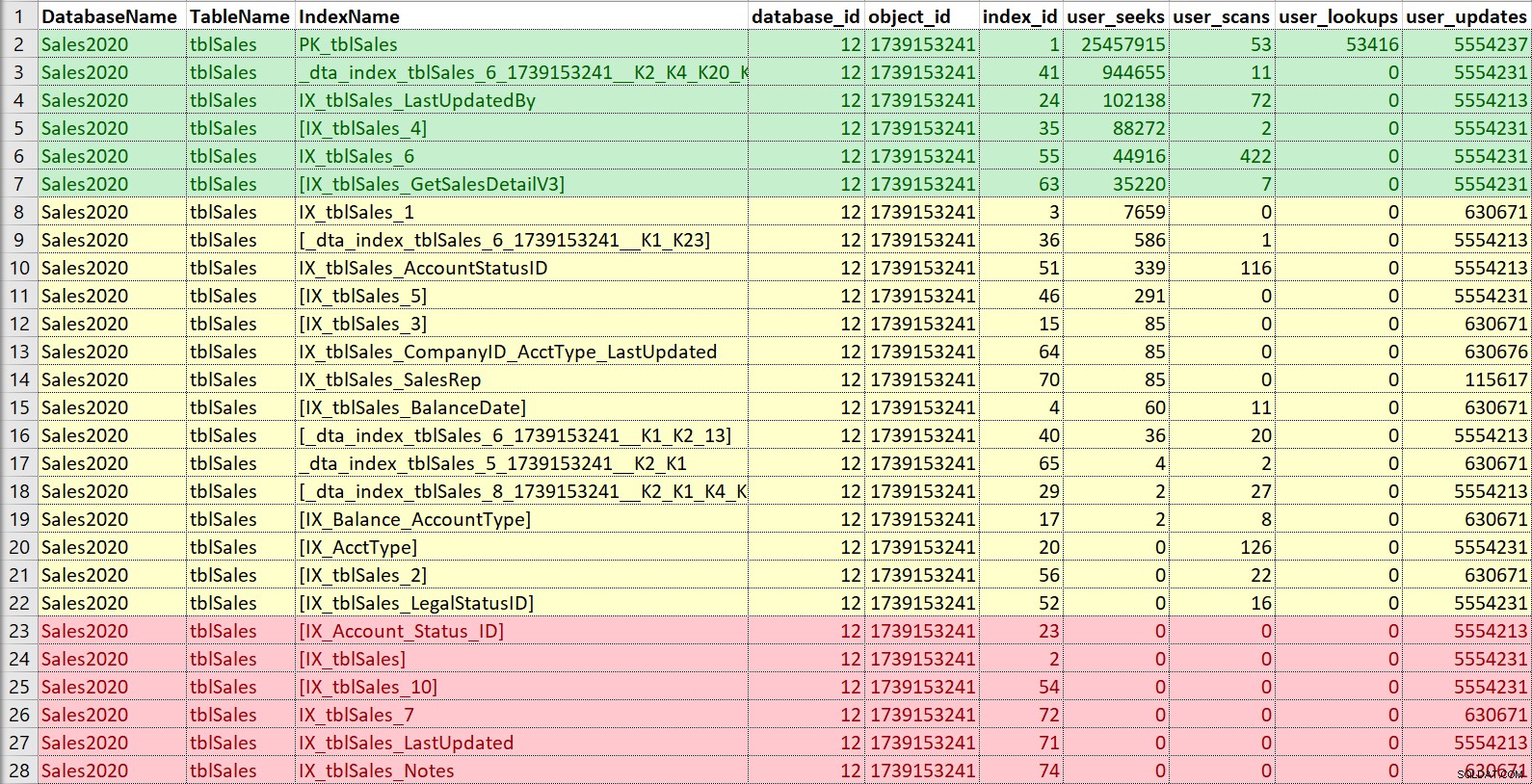
Opět to rád vkládám do Excelu, třídím podle hledání a poté skenuji a také si všímám aktualizací. V tomto příkladu jsou červené indexy, které nemají žádné hledání, skenování nebo vyhledávání… pouze aktualizace. Jsou to kandidáti na deaktivaci a potenciálně vyřazení, pokud se skutečně nepoužívají (zde by opět pomohlo mít historii použití). Indexy v zelené barvě se určitě používají, chci je ponechat (i když možná v některých případech by se daly upravit). Ty žluté... některé se tak nějak používají, některé se téměř nepoužívají. Zde by opět pomohla historie nebo kontext od ostatních – někdy může být index zásadní pro sestavu nebo proces, který neběží neustále.
Pokud se snažím pouze upravit nebo přidat nový index, oproti skutečnému vyčištění a konsolidaci, pak se většinou zabývám indexy, které jsou podobné tomu, co chci přidat nebo změnit. Ujistím se však, že zákazníka upozorním na informace o použití, a pokud mi to čas dovolí, pomohu mu s celkovou strategií indexování tabulky.
Co bude dál?
ještě nekončíme! Toto je část 1 mého přístupu k ladění indexu a moje další část uvede zbytek mých kroků. Pokud mezitím nezaznamenáváte statistiky využití indexu, můžete to zavést pomocí výše uvedeného dotazu nebo jiné varianty. Doporučil bych zachytit statistiky využití pro všechny uživatelské databáze, nejen pro konkrétní tabulku a databázi, jak jsem to udělal výše, takže podle potřeby upravte predikát. A nakonec, jako součást této naplánované úlohy zaznamenat tyto informace do tabulky, nezapomeňte na další krok k vyčištění tabulky poté, co tam data nějakou dobu byla (uchovávám je alespoň šest měsíců; někdo by mohl říci, že rok je nezbytný).