Minulý měsíc jsem se zabýval hádankou Petera Larssona o sladění nabídky s poptávkou. Ukázal jsem Peterovo přímočaré řešení založené na kurzoru a vysvětlil jsem, že má lineární škálování. Výzva, kterou jsem vám nechal, je pokusit se přijít s řešením tohoto úkolu na základě sady, a chlapče, ať se lidé této výzvě postaví! Díky Luca, Kamil Kosno, Daniel Brown, Brian Walker, Joe Obbish, Rainer Hoffmann, Paul White, Charlie a samozřejmě Peter Larsson za zaslání vašich řešení. Některé nápady byly skvělé a přímo ohromující.
Tento měsíc začnu zkoumat předložená řešení, zhruba od těch s horším výkonem k těm s nejlepším výkonem. Proč se vůbec obtěžovat s těmi špatně fungujícími? Protože se od nich můžete ještě hodně naučit; například identifikací anti-vzorců. První pokus o vyřešení této výzvy pro mnoho lidí, včetně mě a Petra, je založen na konceptu intervalových křižovatek. Stává se, že klasická technika identifikace protínání intervalů založená na predikátu má špatný výkon, protože neexistuje žádné dobré schéma indexování, které by ji podporovalo. Tento článek je věnován tomuto přístupu se špatným výkonem. Přes slabý výkon je práce na řešení zajímavým cvičením. Vyžaduje to nácvik dovednosti modelování problému způsobem, který se hodí k léčbě na základě sady. Je také zajímavé identifikovat důvod špatného výkonu, což usnadňuje vyhnout se anti-vzoru v budoucnu. Mějte na paměti, že toto řešení je pouze výchozím bodem.
DDL a malá sada ukázkových dat
Připomínáme, že tento úkol zahrnuje dotazování na tabulku s názvem "Aukce." Pomocí následujícího kódu vytvořte tabulku a naplňte ji malou sadou ukázkových dat:
PUSTIT TABULKU, POKUD EXISTUJE dbo.Auctions; CREATE TABLE dbo.Auctions( ID INT NOT NULL IDENTITY(1, 1) OMEZENÍ pk_Auctions PRIMÁRNÍ KLÍČ SE SLUSTROVANÝM, kód CHAR(1) NOT NULL CONSTRAINT CK_Auctions_Code CHECK (Kód ='D' OR Kód ='S'S'), Quantity , 6) NOT NULL CONSTRAINT ck_Auctions_Quantity CHECK (množství> 0)); SET NOCOUNT ON; VYMAZAT Z dbo.Aukce; SET IDENTITY_INSERT dbo.Auctions ON; INSERT INTO dbo.Auctions(ID, Kód, Množství) HODNOTY (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, 'S', 2.0), (4000, 'S', 2.0), (5000, 'S', 4.0), (6000, 'S', 3.0), (7000, 'S', 2,0); SET IDENTITY_INSERT dbo.Auctions OFF;
Vaším úkolem bylo vytvořit páry, které odpovídají položkám nabídky a poptávky na základě ID objednávek a zapsat je do dočasné tabulky. Následující je požadovaný výsledek pro malou sadu vzorových dat:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5,0000002 1000 3,0000003 2000 6,03000003 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
Minulý měsíc jsem také poskytl kód, který můžete použít k naplnění tabulky Aukce velkou sadou vzorových dat, která řídí počet položek nabídky a poptávky a také rozsah jejich množství. Ujistěte se, že ke kontrole výkonu řešení používáte kód z článku z minulého měsíce.
Modelování dat jako intervalů
Jedna zajímavá myšlenka, která se hodí k podpoře řešení založených na množinách, je modelovat data jako intervaly. Jinými slovy, představujte každý vstup poptávky a nabídky jako interval počínaje průběžným celkovým množstvím stejného druhu (poptávka nebo nabídka) až po, ale bez proudu, a končící průběžným součtem včetně proudu, samozřejmě na základě ID objednávání. Například při pohledu na malou sadu vzorových dat je první záznam poptávky (ID 1) pro množství 5,0 a druhý (ID 2) pro množství 3,0. První položka poptávky může být reprezentována začátkem intervalu:0,0, koncem:5,0 a druhá se začátkem intervalu:5,0, koncem:8,0 atd.
Podobně první položka nabídky (ID 1000) je pro množství 8,0 a druhý (ID 2000) je pro množství 6,0. První položka nabídky může být reprezentována začátkem intervalu:0,0, koncem:8,0 a druhá se začátkem intervalu:8,0, koncem:14,0 atd.
Páry poptávky a nabídky, které musíte vytvořit, jsou potom překrývající se segmenty protínajících se intervalů mezi těmito dvěma druhy.
To je pravděpodobně nejlépe pochopitelné s vizuálním zobrazením intervalového modelování dat a požadovaného výsledku, jak je znázorněno na obrázku 1.
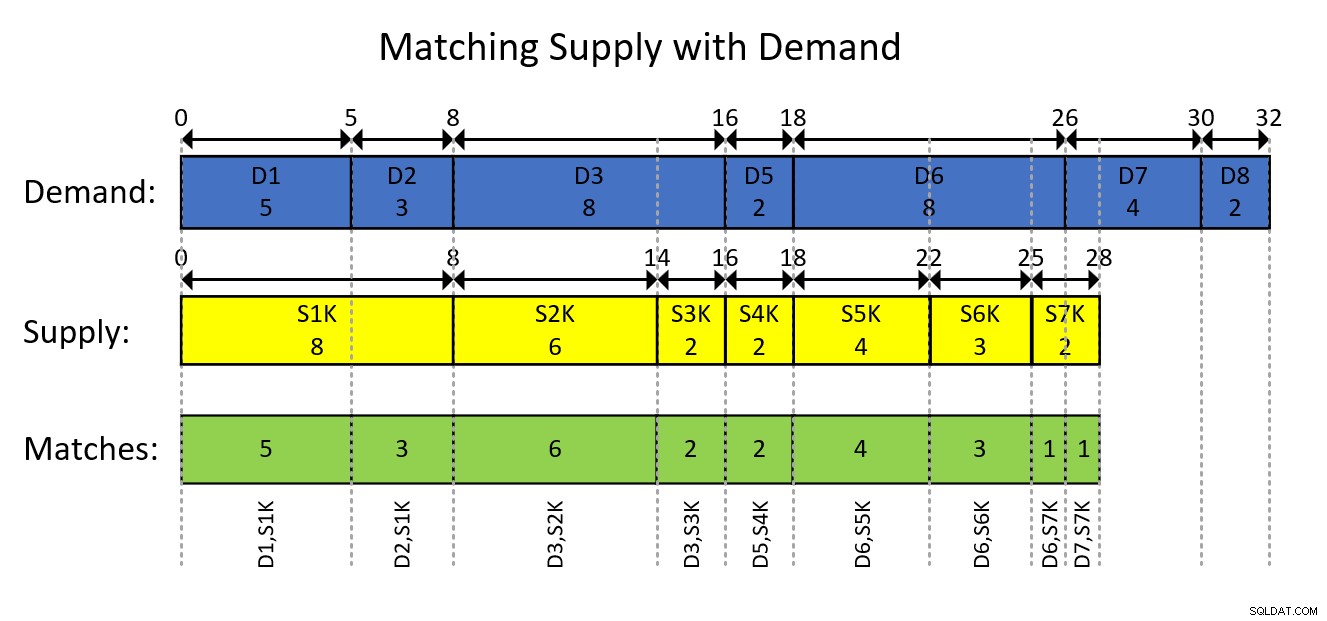 Obrázek 1:Modelování dat jako intervalů
Obrázek 1:Modelování dat jako intervalů
Vizuální zobrazení na obrázku 1 je docela samovysvětlující, ale ve zkratce…
Modré obdélníky představují položky poptávky jako intervaly, zobrazující exkluzivní průběžné celkové množství jako začátek intervalu a včetně průběžného součtu jako konec intervalu. Žluté obdélníky dělají totéž pro položky spotřebního materiálu. Pak si všimněte, že překrývající se segmenty protínajících se intervalů těchto dvou druhů, které jsou znázorněny zelenými obdélníky, jsou páry poptávky a nabídky, které potřebujete vytvořit. Například první dvojice výsledků je s ID poptávky 1, ID nabídky 1000, množství 5. Druhá dvojice výsledků je s ID poptávky 2, ID nabídky 1000, množství 3. A tak dále.
Intervalové průniky pomocí CTE
Než začnete psát kód T-SQL s řešeními založenými na myšlence intervalového modelování, měli byste již mít intuitivní smysl pro to, jaké indexy zde budou pravděpodobně užitečné. Vzhledem k tomu, že budete pravděpodobně používat funkce okna k výpočtu průběžných součtů, mohli byste mít prospěch z krycího indexu s klíčem založeným na sloupcích Kód, ID a včetně sloupce Množství. Zde je kód pro vytvoření takového indexu:
VYTVOŘTE UNIKÁTNÍ NEZAHRNUTÝ INDEX idx_Code_ID_i_Quantity NA dbo.Auctions(Kód, ID) INCLUDE(Množství);
To je stejný index, který jsem doporučil pro řešení založené na kurzoru, kterým jsem se zabýval minulý měsíc.
Je zde také potenciál těžit z dávkového zpracování. Můžete povolit jeho zvažování bez požadavků na dávkový režim na rowstore, např. pomocí SQL Server 2019 Enterprise nebo novější, vytvořením následujícího fiktivního indexu columnstore:
VYTVOŘTE NEZAHRNUTÝ INDEX COLUMNSTORE idx_cs NA dbo.Auctions(ID) KDE ID =-1 A ID =-2;
Nyní můžete začít pracovat na kódu T-SQL řešení.
Následující kód vytvoří intervaly představující položky poptávky:
WITH D0 AS-- D0 vypočítá běžící poptávku jako EndDemand( VYBERTE ID, Množství, SOUČET (množství) NAD (POŘADÍ PODLE ŘÁDKŮ ID BEZ OMEZENÍ PŘEDCHOZÍM) JAKO EndDemand OD dbo.Auctions WHERE Code ='D'),-- D extrakty předchozí EndDemand jako StartDemand, vyjadřující počáteční a koncovou poptávku jako intervalD AS( SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand FROM D0)SELECT *FROM D;
Dotaz definující CTE D0 filtruje položky poptávky z tabulky Aukce a vypočítá průběžné celkové množství jako koncový oddělovač intervalů poptávky. Poté dotaz definující druhý CTE nazvaný D dotazuje D0 a vypočítá počáteční oddělovač intervalů poptávky odečtením aktuálního množství od koncového oddělovače.
Tento kód generuje následující výstup:
ID Množství StartDemand EndDemand---- --------- ------------ ----------1 5,000000 0,000000 5,0000002 3,000000 5,0000000 8.0 8,000000 16,0000005 2,000000 16,000000 18,0000006 8,000000 18,000000 26,0000000 26,0000007 4,0000007 4,000000 26,030,0 Intervaly dodávek jsou generovány velmi podobně použitím stejné logiky na položky dodávky pomocí následujícího kódu:S S0 AS-- S0 počítá běžící zdroj jako EndSupply( VYBERTE ID, Množství, SOUČET (množství) NAD (POŘADÍ PODLE ŘÁDKŮ ID BEZ ODPOVĚDNOSTI PŘEDCHOZÍM) JAKO EndSupply OD dbo.Auctions WHERE Code ='S'),-- S extrakty předchozí EndSupply jako StartSupply, vyjadřující počáteční-endovou dodávku jako intervalS AS( SELECT ID, Množství, EndSupply - Množství AS StartSupply, EndSupply FROM S0)SELECT *FROM S;Tento kód generuje následující výstup:
ID Množství StartSupply EndSupply----- --------- ------------ ----------1000 8,000000 0,000000 8,0000002000 6,000000 000,00 00,000 8,00 2.000000 14.000000 16.0000004000 2.000000 16.000000 18.0000005000 4.000000 18.000000 22.0000006000 3,000000 22.000000 25.0000007000 2,000000 25.000000 27.000000Zbývá pak identifikovat protínající se intervaly poptávky a nabídky z CTE D a S a vypočítat překrývající se segmenty těchto protínajících se intervalů. Pamatujte, že párování výsledků by mělo být zapsáno do dočasné tabulky. To lze provést pomocí následujícího kódu:
-- Drop temp table if existsDROP TABLE IF EXISTS #MyPairings; WITH D0 AS-- D0 vypočítá běžící poptávku jako EndDemand( VYBERTE ID, Množství, SUM(Množství) NAD (POŘADÍ PODLE ŘÁDKŮ ID BEZ ODPOVĚDNOSTI PŘEDCHOZÍM) JAKO EndDemand OD dbo.Auctions WHERE Code ='D'),-- D výpisy předchozí EndDemand jako StartDemand, vyjadřující počáteční-koncovou poptávku jako intervalD AS( SELECT ID, Množství, EndDemand - Množství AS StartDemand, EndDemand FROM D0),S0 AS-- S0 počítá běžící nabídku jako EndSupply( SELECT ID, Quantity, SUM(Quantity) OVER (POŘADÍTE PODLE ŘÁDKŮ ID BEZ PŘEDCHÁZEJÍCÍCH) JAKO EndSupply OD dbo.Auctions WHERE Code ='S'),-- S extrakty předchozí EndSupply jako StartSupply, vyjadřující počáteční-endovou dodávku jako intervalS AS( SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply OD S0)-- Vnější dotaz identifikuje obchody jako překrývající se segmenty protínajících se intervalů-- V protínajících se intervalech poptávky a nabídky je pak obchodní množství -- LEAST(EndDemand, EndSupply) - GREATEST(StartDemsnad, StartSupply)SELECT D.ID JAKO ID poptávky, S.ID JAKO SupplyID, CASE WH EN EndDemandStartSupply THEN StartDemand ELSE StartSupply KONEC JAKO TradeQuantityDO #MyPairingsFROM D VNITŘNÍ PŘIPOJTE SE K D.StartDemand Kromě kódu, který vytváří intervaly poptávky a nabídky, který jste již viděli dříve, je zde hlavním doplňkem vnější dotaz, který identifikuje protínající se intervaly mezi D a S a počítá překrývající se segmenty. K identifikaci protínajících se intervalů vnější dotaz spojí D a S pomocí následujícího predikátu spojení:
D.StartDemandS.StartSupply To je klasický predikát k identifikaci průsečíku intervalů. Je to také hlavní zdroj slabého výkonu řešení, jak krátce vysvětlím.
Vnější dotaz také vypočítá obchodní množství v seznamu SELECT jako:
NEJMENŠÍ (EndDemand, EndSupply) – NEJVĚTŠÍ (StartDemand, StartSupply)Pokud používáte Azure SQL, můžete použít tento výraz. Pokud používáte SQL Server 2019 nebo starší, můžete použít následující logicky ekvivalentní alternativu:
CASE WHEN EndDemandStartSupply THEN StartDemand ELSE StartSupply END Protože požadavkem bylo zapsat výsledek do dočasné tabulky, vnější dotaz k tomu používá příkaz SELECT INTO.
Myšlenka modelovat data jako intervaly je zjevně zajímavá a elegantní. Ale co výkon? Bohužel toto konkrétní řešení má velký problém související s tím, jak se identifikuje průsečík intervalů. Prohlédněte si plán tohoto řešení znázorněný na obrázku 2.
Obrázek 2:Plán dotazů pro křižovatky pomocí řešení CTEs
Začněme s levnými částmi plánu.
Vnější vstup spojení Nested Loops počítá intervaly poptávky. Používá operátor Index Seek k načtení položek poptávky a operátor dávkového režimu Window Aggregate k výpočtu oddělovače konce intervalu poptávky (v tomto plánu označovaného jako Expr1005). Oddělovač začátku intervalu odběru je pak Expr1005 – Množství (od D).
Jako okrajovou poznámku zde může překvapit použití explicitního operátoru řazení před dávkovým režimem Window Aggregate operátor, protože položky poptávky načtené z Index Seek jsou již seřazeny podle ID, jak je potřebuje funkce okna. Souvisí to se skutečností, že v současné době SQL Server nepodporuje účinnou kombinaci paralelní operace indexu zachování pořadí před paralelním dávkovým režimem Window Aggregate operátor. Pokud vynutíte sériový plán pouze pro účely experimentování, uvidíte, že operátor řazení zmizí. SQL Server se rozhodl celkově, použití paralelismu zde bylo preferováno, přestože to vedlo k přidanému explicitnímu řazení. Ale opět, tato část plánu představuje malou část práce ve velkém schématu věcí.
Podobně vnitřní vstup spojení Nested Loops začíná výpočtem intervalů dodávky. Je zvláštní, že SQL Server se rozhodl pro zpracování této části použít operátory v režimu řádků. Na jedné straně operátory v režimu řádků používané k výpočtu průběžných součtů vyžadují větší režii než alternativa dávkového režimu Window Aggregate; na druhou stranu má SQL Server účinnou paralelní implementaci operace indexu zachování pořadí následované výpočtem funkce okna, čímž se u této části vyhýbá explicitnímu řazení. Je zvláštní, že optimalizátor zvolil jednu strategii pro intervaly poptávky a jinou pro intervaly nabídky. V každém případě operátor Index Seek načte položky nabídky a následná sekvence operátorů až po operátor Compute Scalar vypočítá oddělovač konce intervalu zásob (v tomto plánu označovaný jako Expr1009). Oddělovač začátku intervalu dodávky je pak Expr1009 – Množství (od S).
Navzdory množství textu, který jsem použil k popisu těchto dvou částí, je skutečně nákladná část práce v plánu to, co přijde dál.
Další část potřebuje spojit intervaly poptávky a intervaly nabídky pomocí následujícího predikátu:
D.StartDemandS.StartSupply Bez podpůrného indexu, za předpokladu intervalů poptávky DI a intervalů dodávek SI, by to znamenalo zpracování řádků DI * SI. Plán na obrázku 2 byl vytvořen po naplnění tabulky Aukce 400 000 řádky (200 000 položek poptávky a 200 000 položek nabídky). Takže bez podpůrného indexu by plán potřeboval zpracovat 200 000 * 200 000 =40 000 000 000 řádků. Ke zmírnění těchto nákladů se optimalizátor rozhodl vytvořit dočasný index (viz operátor Spool indexu) s oddělovačem konce intervalu zásobování (Expr1009) jako klíčem. To je asi to nejlepší, co může udělat. To však řeší pouze část problému. Se dvěma predikáty rozsahu může predikát vyhledávání indexu podporovat pouze jeden. S tím druhým je třeba zacházet pomocí zbytkového predikátu. V plánu skutečně můžete vidět, že hledání v dočasném indexu používá predikát hledání Expr1009> Expr1005 – D.Quantity, za nímž následuje operátor Filter zpracovávající zbytkový predikát Expr1005> Expr1009 – S.Quantity.
Za předpokladu, že predikát vyhledávání v průměru izoluje polovinu řádků nabídky z indexu na řádek poptávky, celkový počet řádků emitovaných operátorem Index Spool a zpracovaných operátorem Filtr je pak DI * SI / 2. V našem případě s 200 000 řádky poptávky a 200 000 řádků nabídky, to znamená 20 000 000 000. Šipka přecházející z operátoru Index Spool k operátoru Filter hlásí počet řádků blízkých tomuto.
Tento plán má kvadratické škálování ve srovnání s lineárním škálováním řešení založeného na kurzoru z minulého měsíce. Výsledek testu výkonu srovnávajícího obě řešení můžete vidět na obrázku 3. Můžete jasně vidět pěkně tvarovanou parabolu pro řešení založené na množině.
Obrázek 3:Výkon křižovatek pomocí řešení CTE versus řešení založené na kurzoru
Intervalové průniky pomocí dočasných tabulek
Věci můžete poněkud zlepšit nahrazením použití CTE pro intervaly poptávky a nabídky dočasnými tabulkami a abyste se vyhnuli zařazování indexů, vytvořte si vlastní index na dočasné tabulce obsahující intervaly nabídky s koncovým oddělovačem jako klíčem. Zde je úplný kód řešení:
-- Zrušte tabulky temp, pokud existujíDROP TABLE IF EXISTS #MyPairings, #Demand, #Supply; WITH D0 AS-- D0 vypočítá běžící poptávku jako EndDemand( VYBERTE ID, Množství, SUM(Množství) NAD (POŘADÍ PODLE ŘÁDKŮ ID BEZ ODPOVĚDNOSTI PŘEDCHOZÍM) JAKO EndDemand OD dbo.Auctions WHERE Code ='D'),-- D výpisy předchozí EndDemand jako StartDemand, vyjadřující počáteční a koncovou poptávku jako intervalD AS( SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand FROM D0)SELECT ID, Quantity, CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand, CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemandINTO #DemandFROM D;WITH S0 AS-- S0 vypočítá běžící dodávku jako EndSupply( SELECT ID, Quantity, SUM(Qantity) OVER (ORDER BY ID PŘEDCHOZÍ ŘÁDKY BEZ ODPOVĚDNOSTI) JAKO EndSupply FROM dbo.Auctions WHERE Code ='S'),-- S extrakty předchozí EndSupply jako StartSupply, vyjadřující počáteční koncovou dodávku jako intervalS AS( SELECT ID, Množství, EndSupply - Množství JAKO StartSupply, EndSupply FROM S0) VYBERTE ID, množství, CAST(ISNULL(StartSupply, 0,0) AS DECIMAL(19, 6)) AS StartSupply, CAST(ISNULL(EndSupply, 0,0) JAKO DECIMAL(19, 6)) AS EndSupplyINTO #SupplyFROM S; VYTVOŘTE UNIKÁTNÍ CLUSTEROVANÝ INDEX idx_cl_ES_ID ON #Supply(EndSupply, ID); -- Vnější dotaz identifikuje obchody jako překrývající se segmenty protínajících se intervalů -- V protínajících se intervalech poptávky a nabídky je pak obchodní množství -- LEAST(EndDemand, EndSupply) - GREATEST(StartDemsnad, StartSupply)SELECT D.ID AS PoptávkaID, S.ID JAKO SupplyID, CASE WHEN EndDemandStartSupply THEN StartDemand ELSE StartSupply KONEC JAKO TradeQuantityINTO #MyPairingsFROM #Demand AS D INNER JOINSE #WTHDSup S.EndSupply A D.EndDemand> S.StartSupply; Plány tohoto řešení jsou znázorněny na obrázku 4:
Obrázek 4:Plán dotazů pro křižovatky pomocí řešení Temp Tables
První dva plány používají kombinaci operátorů hledání indexu + řazení + okna v dávkovém režimu k výpočtu intervalů nabídky a poptávky a zapisují je do dočasných tabulek. Třetí plán zpracovává vytvoření indexu v tabulce #Supply s oddělovačem EndSupply jako úvodním klíčem.
Čtvrtý plán představuje zdaleka většinu práce s operátorem spojení Nested Loops, který odpovídá každému intervalu z #Demand, protínajícím se intervalům z #Supply. Všimněte si, že také zde operátor Index Seek spoléhá na predikát #Supply.EndSupply> #Demand.StartDemand jako predikát vyhledávání a #Demand.EndDemand> #Supply.StartSupply jako zbytkový predikát. Takže pokud jde o složitost/škálování, získáte stejnou kvadratickou složitost jako u předchozího řešení. Pouze zaplatíte méně za řádek, protože používáte svůj vlastní index namísto zařazování indexů používané předchozím plánem. Výkon tohoto řešení ve srovnání s předchozími dvěma můžete vidět na obrázku 5.
Obrázek 5:Výkon křižovatek pomocí dočasných tabulek ve srovnání s dalšími dvěma řešeními
Jak můžete vidět, řešení s dočasnými tabulkami funguje lépe než to s CTE, ale stále má kvadratické škálování a ve srovnání s kurzorem si vede velmi špatně.
Co bude dál?
Tento článek se zabýval prvním pokusem o zvládnutí úlohy klasického párování nabídky s poptávkou pomocí řešení založeného na množinách. Cílem bylo modelovat data jako intervaly, porovnat nabídku se vstupy poptávky identifikací protínajících se intervalů nabídky a poptávky a poté vypočítat obchodní množství na základě velikosti překrývajících se segmentů. Určitě zajímavá myšlenka. Hlavním problémem je také klasický problém identifikace průsečíku intervalů pomocí dvou predikátů rozsahu. I když je na místě nejlepší index, můžete s hledáním indexu podporovat pouze jeden predikát rozsahu; druhý predikát rozsahu musí být zpracován pomocí zbytkového predikátu. Výsledkem je plán s kvadratickou složitostí.
Co tedy můžete udělat, abyste tuto překážku překonali? Existuje několik různých nápadů. Jeden skvělý nápad patří Joeovi Obbishovi, o kterém si můžete podrobně přečíst v jeho příspěvku na blogu. Dalšími nápady se budu zabývat v nadcházejících článcích této série.
[ Přejít na:Původní výzva | Řešení:Část 1 | Část 2 | část 3]