V nedávném vláknu na StackExchange měl uživatel následující problém:
Chci dotaz, který vrátí první osobu v tabulce s GroupID =2. Pokud neexistuje nikdo s GroupID =2, chci první osobu s RoleID =2.
Zahoďme prozatím skutečnost, že „první“ je strašně definované. Ve skutečnosti bylo uživateli jedno, jakou osobu získal, zda to přišlo náhodně, svévolně nebo prostřednictvím nějaké explicitní logiky kromě jejich hlavních kritérií. Když to ignorujeme, řekněme, že máte základní tabulku:
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT );
V reálném světě pravděpodobně existují další sloupce, další omezení, možná cizí klíče k jiným tabulkám a určitě další indexy. Ale nechme to jednoduché a pojďme s dotazem.
Pravděpodobná řešení
S tím designem stolu se řešení problému zdá být jednoduché, že? První pokus, který byste pravděpodobně udělali, je:
SELECT TOP (1) UserID, GroupID, RoleID FROM dbo.Users WHERE GroupID = 2 OR RoleID = 2 ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
Toto používá TOP a podmíněné ORDER BY považovat uživatele s GroupID =2 za vyšší prioritu. Plán pro tento dotaz je docela jednoduchý, přičemž většina nákladů se odehrává v operaci řazení. Zde jsou metriky běhu s prázdnou tabulkou:
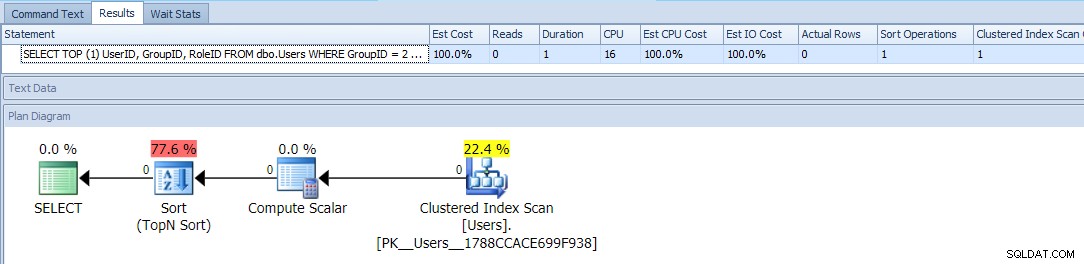
Zdá se, že je to tak dobré, jak jen můžete – jednoduchý plán, který tabulku prohledá pouze jednou, a kromě otravného typu, se kterým byste měli být schopni žít, žádný problém, ne?
Další odpověď ve vláknu nabídla tuto složitější variantu:
SELECT TOP (1) UserID, GroupID, RoleID FROM ( SELECT TOP (1) UserID, GroupID, RoleID, o = 1 FROM dbo.Users WHERE GroupId = 2 UNION ALL SELECT TOP (1) UserID, GroupID, RoleID, o = 2 FROM dbo.Users WHERE RoleID = 2 ) AS x ORDER BY o;
Na první pohled byste si pravděpodobně mysleli, že tento dotaz je extrémně méně efektivní, protože vyžaduje dvě skenování seskupených indexů. V tom byste určitě měli pravdu; zde jsou metriky plánu a doby běhu proti prázdné tabulce:
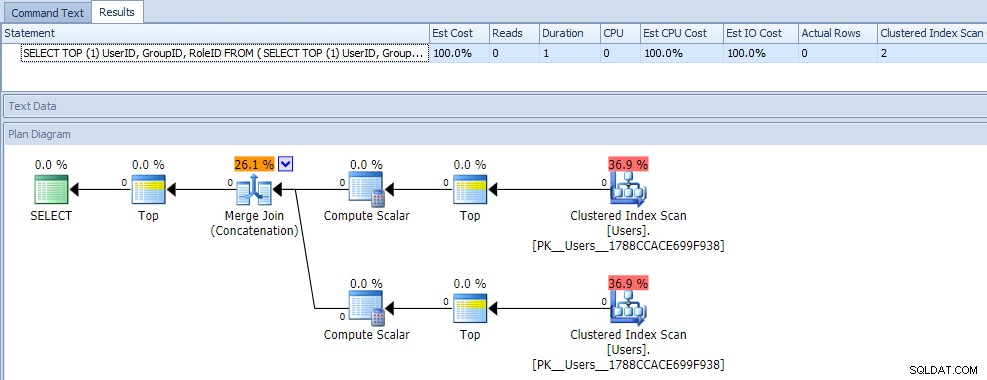
Teď ale pojďme přidat data
Abych tyto dotazy otestoval, chtěl jsem použít některá realistická data. Nejprve jsem tedy naplnil 1 000 řádků ze sys.all_objects pomocí modulo operací proti object_id, abych získal nějakou slušnou distribuci:
INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4 FROM sys.all_objects ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
Nyní, když spustím dva dotazy, zde jsou metriky běhu:

Verze UNION ALL se dodává s o něco menším počtem I/O (4 čtení oproti 5), kratší dobou trvání a nižšími odhadovanými celkovými náklady, zatímco podmíněná verze ORDER BY má nižší odhadované náklady na CPU. Údaje zde jsou dost malé na to, abychom o nich mohli dělat nějaké závěry; Chtěl jsem to jen jako kůl do země. Nyní změňme distribuci tak, aby většina řádků splňovala alespoň jedno z kritérií (a někdy obě):
DROP TABLE dbo.Users; GO CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT ); GO INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1, SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1 FROM sys.all_objects WHERE ABS([object_id]) > 9999999 ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
Tentokrát má podmíněná objednávka podle nejvyšší odhadované náklady na CPU i I/O:

Ale opět, při této velikosti dat je zde relativně nevýznamný dopad na trvání a čtení a kromě odhadovaných nákladů (které jsou stejně z velké části tvořeny) je těžké zde vyhlásit vítěze.
Přidejme tedy mnohem více dat
I když mě spíše baví vytvářet ukázková data z katalogových pohledů, protože je má každý, tentokrát budu kreslit do tabulky Sales.SalesOrderHeaderEnlarged z AdventureWorks2012, rozšířené pomocí tohoto skriptu od Jonathana Kehayiase. V mém systému má tato tabulka 1 258 600 řádků. Následující skript vloží milion těchto řádků do naší tabulky dbo.Users:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4 FROM Sales.SalesOrderHeaderEnlarged; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
Dobře, teď, když spustíme dotazy, vidíme problém:variace ORDER BY přešla paralelně a vymazala jak čtení, tak CPU, což vedlo k téměř 120násobnému rozdílu v trvání:
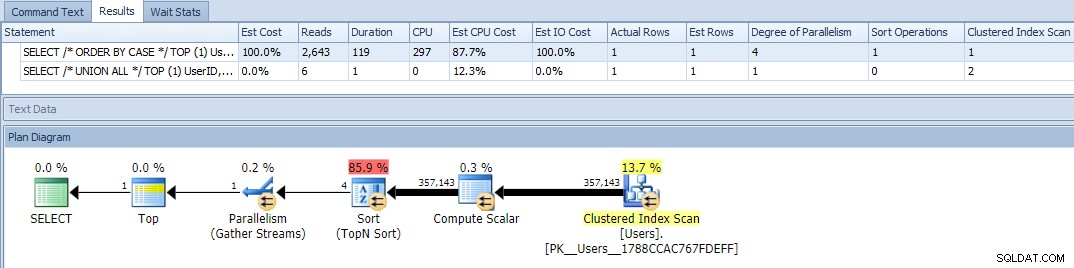
Odstranění paralelismu (pomocí MAXDOP) nepomohlo:
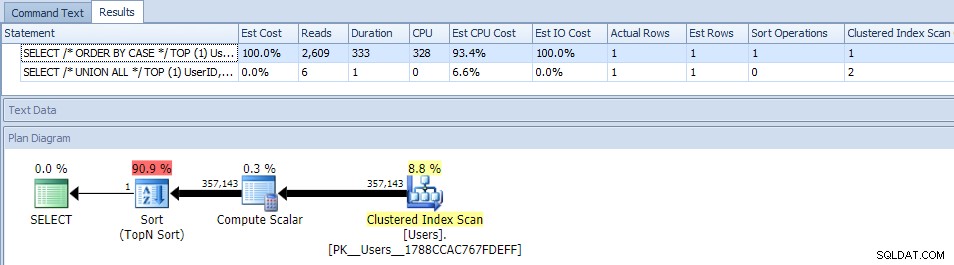
(Plán UNION ALL vypadá stále stejně.)
A pokud změníme zešikmení na sudé, kde 95 % řádků splňuje alespoň jedno kritérium:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 1 UNION ALL SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 0; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, 1, 1 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
Dotazy stále ukazují, že řazení je neúměrně drahé:

A s MAXDOP =1 to bylo mnohem horší (stačí se podívat na trvání):

A konečně, co asi 95 % zkosení v obou směrech (např. většina řádků splňuje kritéria GroupID nebo většina řádků splňuje kritéria RoleID)? Tento skript zajistí, že alespoň 95 % dat bude mít GroupID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Výsledky jsou docela podobné (od této chvíle přestanu zkoušet MAXDOP):

A když to přechýlíme opačně, kde alespoň 95 % dat má RoleID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Výsledky:

Závěr
Ani v jednom případě, který jsem mohl vyrobit, „jednodušší“ dotaz ORDER BY – dokonce ani s jedním méně seskupeným indexovým skenem – nepřekonal složitější dotaz UNION ALL. Někdy musíte být velmi opatrní ohledně toho, co musí SQL Server udělat, když do sémantiky dotazu zavádíte operace, jako je řazení, a nespoléhat se pouze na jednoduchost plánu (nevadí žádné zaujatosti, které byste mohli mít na základě předchozích scénářů).
Váš první instinkt může být často správný, ale vsadím se, že jsou chvíle, kdy existuje lepší možnost, která navenek vypadá, jako by nemohla fungovat lépe. Jako v tomto příkladu. Jsem o něco lepší, pokud jde o zpochybňování předpokladů, které jsem si vytvořil z pozorování, a nedělám paušální prohlášení jako „skenování nikdy nefunguje dobře“ a „jednodušší dotazy vždy běží rychleji“. Pokud ze svého slovníku vyloučíte slova nikdy a vždy, možná zjistíte, že zkoušíte více těchto domněnek a obecných tvrzení a skončíte mnohem lépe.