Úvod
Dříve nebo později každý informační systém získá databázi, často více než jednu. Časem tato databáze shromažďuje velké množství dat, od několika GB až po desítky TB. Abychom pochopili, jak si funkce povedou s rostoucím objemem dat, musíme vygenerovat data, která naplní tuto databázi.

Všechny prezentované a implementované skripty budou spuštěny na JobEmplDB databáze náborové služby. Realizace databáze je k dispozici zde.
Přístupy k vyplňování databází pro testování a vývoj
Vývoj a testování databáze zahrnuje dva primární přístupy k vyplňování dat:
- Kopírování celé databáze z produkčního prostředí se změněnými osobními a jinými citlivými údaji. Tímto způsobem zajistíte data a vymažete důvěrná data.
- K generování syntetických dat. Znamená to generování testovacích dat podobných skutečným datům ve vzhledu, vlastnostech a propojení.
Výhodou přístupu 1 je, že aproximuje data a jejich distribuci podle různých kritérií do produkční databáze. Umožňuje nám vše přesně analyzovat, a proto podle toho dělat závěry a prognózy.
Tento přístup vám však neumožňuje mnohonásobně zvětšit samotnou databázi. Předvídat změny ve funkčnosti celého informačního systému v budoucnu se stává problematické.
Na druhou stranu můžete analyzovat neosobní sanitovaná data převzatá z produkční databáze. Na jejich základě můžete definovat, jak generovat testovací data, která by se podobala skutečným datům svým vzhledem, vlastnostmi a vzájemnými vztahy. Tímto způsobem přístup 1 vytvoří přístup 2.
Podívejme se nyní podrobně na oba přístupy k vyplňování databází pro testování a vývoj.
Kopírování a úprava dat v produkční databázi
Nejprve si definujme obecný algoritmus kopírování a změny dat z produkčního prostředí.
Obecný algoritmus
Obecný algoritmus je následující:
- Vytvořte novou prázdnou databázi.
- Vytvořte schéma v této nově vytvořené databázi – stejný systém jako v produkční databázi.
- Zkopírujte potřebná data z produkční databáze do nově vytvořené databáze.
- Vyčistěte a změňte tajná data v nové databázi.
- Proveďte zálohu nově vytvořené databáze.
- Doručte a obnovte zálohu v potřebném prostředí.
Algoritmus se však po kroku 5 zkomplikuje. Například krok 6 vyžaduje specifické chráněné prostředí pro předběžné testování. Tato fáze musí zajistit, aby všechna data byla neosobní a tajná data byla změněna.
Po této fázi se můžete znovu vrátit ke kroku 5 pro testovanou databázi v chráněném neprodukčním prostředí. Poté předáte testovanou zálohu do potřebných prostředí, kde ji obnovíte a použijete pro vývoj a testování.
Představili jsme obecný algoritmus kopírování a změny dat produkční databáze. Pojďme si popsat, jak to implementovat.
Realizace obecného algoritmu
Vytvoření nové prázdné databáze
Prázdnou databázi můžete vytvořit pomocí konstrukce CREATE DATABASE jako zde.
Databáze se jmenuje JobEmplDB_Test . Má tři skupiny souborů:
- PRIMÁRNÍ – ve výchozím nastavení je to primární skupina souborů. Definuje dva soubory:JobEmplDB_Test1(cesta D:\DBData\JobEmplDB_Test1.mdf) a JobEmplDB_Test2 (cesta D:\DBData\JobEmplDB_Test2.ndf) . Počáteční velikost každého souboru je 64 Mb a krok růstu je 8 Mb pro každý soubor.
- DBTableGroup – vlastní skupina souborů, která určuje dva soubory:JobEmplDB_TestTableGroup1 (cesta D:\DBData\JobEmplDB_TestTableGroup1.ndf) a JobEmplDB_TestTableGroup2 (cesta D:\DBData\JobEmplDB_TestTableGroup2.ndf) . Počáteční velikost každého souboru je 8 Gb a krok růstu je 1 Gb pro každý soubor.
- DBIindexGroup – vlastní skupina souborů, která určuje dva soubory:JobEmplDB_TestIndexGroup1 (cesta D:\DBData\JobEmplDB_TestIndexGroup1.ndf) a JobEmplDB_TestIndexGroup2 (cesta D:\DBData\JobEmplDB_TestIndexGroup2.ndf) . Počáteční velikost je 16 Gb pro každý soubor a krok růstu je 1 Gb pro každý soubor.
Tato databáze také obsahuje jeden deník transakcí:JobEmplDB_Testlog , cesta E:\DBLog\JobEmplDB_Testlog.ldf . Počáteční velikost souboru je 8 Gb a krok růstu je 1 Gb.
Kopírování schématu a potřebných dat z produkční databáze do nově vytvořené databáze
Ke zkopírování schématu a potřebných dat z výrobní databáze do nové můžete použít několik nástrojů. Za prvé je to Visual Studio (SSDT). Nebo můžete použít nástroje třetích stran jako:
- Porovnání schématu DbForge a porovnání dat DbForge
- Rozdíl ApexSQL a rozdíl dat Apex
- Nástroj pro porovnání SQL a Nástroj pro porovnání dat SQL
Vytváření skriptů pro změny dat
Základní požadavky na skripty změn dat
1. Musí být nemožné obnovit skutečná data pomocí tohoto skriptu.
např. inverze řádků nebude vyhovovat, protože nám umožňuje obnovit skutečná data. Obvykle je metodou nahrazení každého znaku nebo bajtu pseudonáhodným znakem nebo bytem. Totéž platí pro datum a čas.
2. Změna údajů nesmí změnit selektivitu jejich hodnot.
Nebude fungovat přiřazení NULL k poli tabulky. Místo toho musíte zajistit, aby stejné hodnoty ve skutečných datech zůstaly stejné ve změněných datech. Například v reálných datech máte v tabulce 12krát nalezenou hodnotu 103785. Když změníte tuto hodnotu ve změněných datech, nová hodnota musí zůstat 12krát ve stejných polích tabulky.
3. Velikost a délka hodnot by se v pozměněných datech neměla výrazně lišit. Například nahradíte každý bajt nebo znak pseudonáhodným bajtem nebo znakem. Počáteční řetězec zůstává co do velikosti a délky stejný.
4. Vzájemné vztahy v datech nesmí být po změnách narušeny. Týká se to externích klíčů a všech ostatních případů, kdy odkazujete na změněná data. Změněná data musí zůstat ve stejných vztazích jako skutečná data.
Implementace skriptů změn dat
Nyní se podívejme na konkrétní případ změny dat, aby se depersonalizovaly a skryly tajné informace. Vzorem je náborová databáze.
Vzorová databáze obsahuje následující osobní údaje, které potřebujete k depersonalizaci:
- Příjmení a jméno;
- Datum narození;
- datum vydání průkazu totožnosti;
- Certifikát vzdáleného přístupu jako sekvence bajtů;
- Poplatek za službu za propagaci životopisu.
Nejprve zkontrolujeme jednoduché příklady pro každý typ změněných dat:
- Změna data a času;
- Změna číselné hodnoty;
- Změna bajtových sekvencí;
- Změna údajů o postavách.
Změna data a času
Náhodné datum a čas můžete získat pomocí následujícího skriptu:
DECLARE @dt DATETIME;
SET @dt = CAST(CAST(@StartDate AS FLOAT) + (CAST(@FinishDate AS FLOAT) - CAST(@StartDate AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME);
Zde @StartDate a @Datum dokončení jsou počáteční a koncové hodnoty rozsahu. Korelují v tomto pořadí pro pseudonáhodné generování data a času.
K vygenerování těchto dat použijete systémové funkce RAND, CHEKSUM a NEWID.
UPDATE [dbo].[Employee]
SET [DocDate] = CAST(CAST(CAST(CAST([BirthDate] AS DATETIME) AS FLOAT) + (CAST(GETDATE() AS FLOAT) - CAST(CAST([BirthDate] AS DATETIME) AS FLOAT)) * RAND(CHECKSUM(NEWID())) AS DATETIME) AS DATE);
Pole [DocDate] představuje datum vystavení dokumentu. Nahradíme jej pseudonáhodným datem, přičemž budeme mít na paměti rozsahy dat a jejich omezení.
„Spodním“ limitem je datum narození kandidáta. „Horní“ okraj je aktuální datum. Čas zde nepotřebujeme, takže nakonec dojde k transformaci formátu času a data na potřebné datum. Stejným způsobem můžete získat pseudonáhodné hodnoty pro jakoukoli část data a času.
Změna číselné hodnoty
Náhodné celé číslo můžete získat pomocí následujícího skriptu:
DECLARE @Int INT;
SET @Int = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
@MinVal a @MaxVal jsou počáteční a koncové hodnoty rozsahu pro generování pseudonáhodných čísel. Generujeme jej pomocí systémových funkcí RAND, CHEKSUM a NEWID.
UPDATE [dbo].[Employee]
SET [CountRequest] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS INT);
Pole [CountRequest] představuje počet žádostí společností o životopis tohoto kandidáta.
Podobně můžete získat pseudonáhodné hodnoty pro jakoukoli číselnou hodnotu. Podívejte se například na náhodné číslo generování desítkového typu (18,2):
DECLARE @Dec DECIMAL(18,2);
SET @Dec=CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
Poplatek za službu propagace životopisu tedy můžete aktualizovat následujícím způsobem:
UPDATE [dbo].[Employee]
SET [PaymentAmount] = CAST(((@MaxVal + 1) - @MinVal) *
RAND(CHECKSUM(NEWID())) + @MinVal AS DECIMAL(18,2));
Změna bajtových sekvencí
Náhodnou sekvenci bajtů můžete získat pomocí následujícího skriptu:
DECLARE @res VARBINARY(MAX);
SET @res = CRYPT_GEN_RANDOM(@Length, CAST(NEWID() AS VARBINARY(16)));
@Length znamená délku sekvence. Definuje počet vrácených bajtů. Zde nesmí být @Length větší než 16.
Generování se provádí pomocí systémových funkcí CRYPT_GEN_RANDOM a NEWID.
Certifikát vzdáleného přístupu pro každého kandidáta můžete aktualizovat například následujícím způsobem:
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = CRYPT_GEN_RANDOM(CAST(LEN([RemoteAccessCertificate]) AS INT), CAST(NEWID() AS VARBINARY(16)));
Vygenerujeme pseudonáhodnou sekvenci bajtů stejné délky, která se v době změny vyskytuje v poli [RemoteAccessCertificate]. Předpokládáme, že délka sekvence bajtů nepřesáhne 16.
Podobně můžeme vytvořit naši funkci, která bude vracet pseudonáhodné sekvence bajtů libovolné délky. Spojí výsledky práce systémové funkce CRYPT_GEN_RANDOM pomocí jednoduchého operátoru sčítání „+“. Ale v praxi obvykle stačí 16 bajtů.
Udělejme ukázkovou funkci vracející pseudonáhodnou sekvenci bajtů o určité délce, kde bude možné nastavit délku více než 16 bajtů. Za tímto účelem udělejte následující prezentaci:
CREATE VIEW [test].[GetNewID]
AS
SELECT NEWID() AS [NewID];
GO
Potřebujeme to, abychom se vyhnuli omezení, které nám zakazuje používat NEWID v rámci funkce.
Stejným způsobem vytvořte další prezentaci pro stejný účel:
CREATE VIEW [test].[GetRand]
AS
SELECT RAND(CHECKSUM((SELECT TOP(1) [NewID] FROM [test].[GetNewID]))) AS [Value];
GO
Vytvořte ještě jednu prezentaci:
CREATE VIEW [test].[GetRandVarbinary16]
AS
SELECT CRYPT_GEN_RANDOM(16, CAST((SELECT TOP(1) [NewID] FROM [test].[GetNewID]) AS VARBINARY(16))) AS [Value];
GO
Definice všech tří funkcí jsou zde. A zde je implementace funkce, která vrací pseudonáhodnou sekvenci bajtů o určité délce.
Nejprve definujeme, zda je přítomna potřebná funkce. Pokud ne – nejprve vytvoříme čep. V každém případě kód zahrnuje vhodnou změnu definice funkce. Na závěr přidáme popis funkce přes rozšířené vlastnosti. Další podrobnosti o dokumentaci databáze jsou v tomto článku.
Chcete-li aktualizovat certifikát vzdáleného přístupu pro každého kandidáta, můžete provést následující:
UPDATE [dbo].[Employee]
SET [RemoteAccessCertificate] = [test].[GetRandVarbinary](CAST(LEN([RemoteAccessCertificate]) AS INT));
Jak vidíte, zde nejsou žádná omezení délky bajtové sekvence.
Změna dat – Změna znakových dat
Zde si vezmeme příklad pro anglickou a ruskou abecedu, ale můžete to udělat pro jakoukoli jinou abecedu. Jedinou podmínkou je, že její znaky musí být přítomny v typech NCHAR.
Potřebujeme vytvořit funkci, která přijme řádek, nahradí každý znak pseudonáhodným znakem a pak výsledek spojí a vrátí.
Nejprve však musíme pochopit, které postavy potřebujeme. K tomu můžeme spustit následující skript:
DECLARE @tbl TABLE ([ValueInt] INT, [ValueNChar] NCHAR(1), [ValueChar] CHAR(1));
DECLARE @ind int=0;
DECLARE @count INT=65535;
WHILE(@count>=0)
BEGIN
INSERT INTO @tbl ([ValueInt], [ValueNChar], [ValueChar])
SELECT @ind, NCHAR(@ind), CHAR(@ind)
SET @ind+=1;
SET @count-=1;
END
SELECT *
INTO [test].[TblCharactersCode]
FROM @tbl;
Vytváříme tabulku [test].[TblCharacterCode], která obsahuje následující pole:
- ValueInt – číselná hodnota znaku;
- ValueNChar – znak typu NCHAR;
- ValueChar – znak typu CHAR.
Podívejme se na obsah této tabulky. Potřebujeme následující požadavek:
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
FROM [test].[TblCharactersCode];
Čísla jsou v rozsahu 48 až 57:
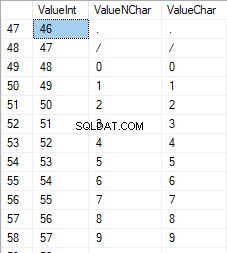
Znaky latinky ve velkých písmenech jsou v rozsahu 65 až 90:
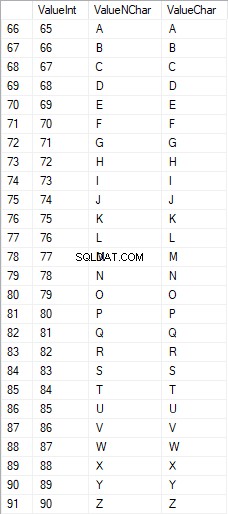
Latinské znaky v nižší péči jsou v rozsahu 97 až 122:
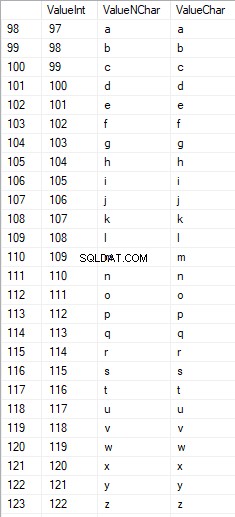
Ruské znaky s velkými písmeny jsou v rozsahu 1040 až 1071:

Ruské znaky s malými písmeny jsou v rozsahu 1072 až 1103:


A znaky v rozsahu 58 až 64:

Vybereme potřebné znaky a vložíme je do tabulky [test].[SelectCharactersCode] následujícím způsobem:
SELECT
[ValueInt]
,[ValueNChar]
,[ValueChar]
,CASE
WHEN ([ValueInt] BETWEEN 48 AND 57) THEN 1
ELSE 0
END AS [IsNumeral]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 1040 AND 1071)) THEN 1
ELSE 0
END AS [IsUpperCase]
,CASE
WHEN (([ValueInt] BETWEEN 65 AND 90) OR
([ValueInt] BETWEEN 97 AND 122)) THEN 1
ELSE 0
END AS [IsLatin]
,CASE
WHEN (([ValueInt] BETWEEN 1040 AND 1071) OR
([ValueInt] BETWEEN 1072 AND 1103)) THEN 1
ELSE 0
END AS [IsRus]
,CASE
WHEN (([ValueInt] BETWEEN 33 AND 47) OR
([ValueInt] BETWEEN 58 AND 64)) THEN 1
ELSE 0
END AS [IsExtra]
INTO [test].[SelectCharactersCode]
FROM [test].[TblCharactersCode]
WHERE ([ValueInt] BETWEEN 48 AND 57)
OR ([ValueInt] BETWEEN 65 AND 90)
OR ([ValueInt] BETWEEN 97 AND 122)
OR ([ValueInt] BETWEEN 1040 AND 1071)
OR ([ValueInt] BETWEEN 1072 AND 1103)
OR ([ValueInt] BETWEEN 33 AND 47)
OR ([ValueInt] BETWEEN 58 AND 64);
Nyní se podívejme na obsah této tabulky pomocí následujícího skriptu:
SELECT [ValueInt]
,[ValueNChar]
,[ValueChar]
,[IsNumeral]
,[IsUpperCase]
,[IsLatin]
,[IsRus]
,[IsExtra]
FROM [test].[SelectCharactersCode];
Obdržíme následující výsledek:

Tímto způsobem máme [test].[SelectCharactersCode] tabulka, kde:
- ValueInt – číselná hodnota znaku
- ValueNChar – znak typu NCHAR
- ValueChar – znak typu CHAR
- JeNumeral – kritériem toho, že znak je číslice
- IsUpperCase – kritérium znaku velkého
- Islatinka – kritériem toho, že znak je latinský znak;
- IsRus – kritérium, že znak je ruský znak
- IsExtra – kritérium, že znak je doplňkovým znakem
Nyní můžeme získat kód pro vložení potřebných znaků. Například, takto to udělat pro latinské znaky v malých písmenech:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsLatin]=1;
Obdržíme následující výsledek:

Je to stejné pro ruské znaky s malými písmeny:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+COALESCE(''''+[ValueChar]+'''', 'NULL')+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsUpperCase]=0
AND [IsRus]=1;
Dostaneme následující výsledek:

Pro postavy je to stejné:
SELECT 'SELECT '+CAST([ValueInt] AS NVARCHAR(255))+' AS [ValueInt], '+''''+[ValueNChar]+''''+' AS [ValueNChar], '+''''+[ValueChar]+''''+' AS [ValueChar] UNION ALL'
FROM [test].[SelectCharactersCode]
WHERE [IsNumeral]=1;
Výsledek je následující:

Máme tedy kódy pro samostatné vložení následujících dat:
- Latinkové znaky malými písmeny.
- Ruské znaky malými písmeny.
- Číslice.
Funguje pro oba typy NCHAR i CHAR.
Podobně můžeme připravit vkládací skript pro libovolnou sadu znaků. Kromě toho bude mít každá sada svou vlastní tabelační funkci.
Pro zjednodušení implementujeme běžnou tabelační funkci, která vrátí potřebnou datovou sadu pro dříve vybraná data následujícím způsobem:
SELECT
'SELECT ' + CAST([ValueInt] AS NVARCHAR(255)) + ' AS [ValueInt], '
+ '''' + [ValueNChar] + '''' + ' AS [ValueNChar], '
+ COALESCE('''' + [ValueChar] + '''', ‘NULL’) + ' AS [ValueChar], '
+ CAST([IsNumeral] AS NCHAR(1)) + ' AS [IsNumeral], ' +
+CAST([IsUpperCase] AS NCHAR(1)) + ' AS [IsUpperCase], ' +
+CAST([IsLatin] AS NCHAR(1)) + ' AS [IsLatin], ' +
+CAST([IsRus] AS NCHAR(1)) + ' AS [IsRus], ' +
+CAST([IsExtra] AS NCHAR(1)) + ' AS [IsExtra]' +
+' UNION ALL'
FROM [test].[SelectCharactersCode];
Konečný výsledek je následující:

Připravený skript je zabalen do funkce tabelování [test].[GetSelectCharacters].
Je důležité odstranit další UNION ALL na konci vygenerovaného skriptu a v [ValueInt]=39 musíme změnit ”’ na ””:
SELECT 39 AS [ValueInt], '''' AS [ValueNChar], '''' AS [ValueChar], 0 AS [IsNumeral], 0 AS [IsUpperCase], 0 AS [IsLatin], 0 AS [IsRus], 1 AS [IsExtra] UNION ALLTato tabelační funkce vrací následující sadu polí:
- Počet – číslo řádku ve vrácené sadě dat;
- ValueInt – číselná hodnota znaku;
- ValueNChar – znak typu NCHAR;
- ValueChar – znak typu CHAR;
- JeNumeral – kritériem toho, že znak je číslice;
- IsUpperCase – kritérium definující, že znak je velký;
- Islatinka – kritérium definující, že znak je latinský znak;
- IsRus – kritérium definující, že postava je ruský znak;
- IsExtra – kritérium definující, že postava je navíc.
Pro vstup máte následující parametry:
- @IsNumeral – pokud má vrátit čísla;
- @IsUpperCase :
- 0 – u písmen musí vracet pouze malá písmena;
- 1 – musí vrátit pouze velká písmena;
- NULL – ve všech případech musí vracet písmena.
- @IsLatin – musí vrátit znaky latinky
- @IsRus – musí vrátit ruské znaky
- @IsExtra – musí vrátit další znaky.
Všechny příznaky se používají podle logického OR. Pokud například potřebujete vrátit číslice a znaky latinky malými písmeny, zavoláte funkci tabelování následujícím způsobem:
Dostaneme následující výsledek:
declare
@IsNumeral BIT=1
,@IsUpperCase BIT=0
,@IsLatin BIT=1
,@IsRus BIT=0
,@IsExtra BIT=0;
SELECT *
FROM [test].[GetSelectCharacters](@IsNumeral, @IsUpperCase, @IsLatin, @IsRus, @IsExtra);
Dostaneme následující výsledek:

Implementujeme funkci [test].[GetRandString], která nahradí řádek pseudonáhodnými znaky při zachování původní délky řetězce. Tato funkce musí zahrnovat možnost ovládání pouze těch znaků, které jsou číslicemi. Může být například užitečné, když změníte sérii a číslo ID karty.
Když implementujeme funkci [test].[GetRandString], získáme nejprve sadu znaků nezbytných pro vygenerování pseudonáhodného řádku zadané délky ve vstupním parametru @Length. Zbývající parametry fungují tak, jak je popsáno výše.
Poté vložíme přijatou sadu dat do tabelační proměnné @tbl . Tato tabulka ukládá pole [ID] – pořadové číslo ve výsledné tabulce znaků a [Value] – prezentace postavy v typu NCHAR.
Poté v cyklu generuje pseudonáhodné číslo v rozsahu od 1 do mohutnosti dříve přijatých znaků @tbl. Toto číslo vložíme do [ID] tabelační proměnné @tbl pro vyhledávání. Když vyhledávání vrátí řádek, vezmeme znak [Hodnota] a „přilepíme“ jej k výslednému řádku @res.
Když práce cyklu skončí, přijatý řádek se vrátí zpět prostřednictvím proměnné @res.
Jméno i příjmení kandidáta můžete změnit následujícím způsobem:
UPDATE [dbo].[Employee]
SET [FirstName] = [test].[GetRandString](LEN([FirstName])),
[LastName] = [test].[GetRandString](LEN([LastName]));
Zkoumali jsme tedy implementaci funkce a její použití pro typy NCHAR a NVARCHAR. Totéž můžeme snadno udělat pro typy CHAR a VARCHAR.
Někdy však potřebujeme vygenerovat řádek podle sady znaků, nikoli podle abecedních znaků nebo čísel. Tímto způsobem musíme nejprve použít následující funkci pro více operátorů [test].[GetListCharacters].
Funkce [test].[GetListCharacters] získá dva následující parametry pro vstup:
- @str – samotný řádek znaků;
- @IsGroupUnique – určuje, zda potřebuje seskupit jedinečné znaky v řádku.
Pomocí rekurzivního CTE se vstupní řádek @str transformuje na tabulku znaků – @ListCharacters. Tato tabulka obsahuje následující pole:
- ID – pořadové číslo řádku ve výsledné tabulce znaků;
- Postava – prezentace znaku v NCHAR(1)
- Počet – počet opakování znaku v řádku (je vždy 1, pokud je parametr @IsGroupUnique=0)
Vezměme si dva příklady použití této funkce, abychom lépe porozuměli její práci:
- Transformace řádku na seznam nejedinečných znaků:
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 0);
Dostaneme výsledek:

Tento příklad ukazuje, že řádek je transformován na seznam znaků „tak, jak je“, aniž by byl seskupen podle jedinečnosti znaků (pole [Počet] vždy obsahuje 1).
- Transformace řádku na seznam jedinečných znaků
SELECT *
FROM [test].[GetListCharacters]('123456888 789 0000', 1);
Výsledek je následující:
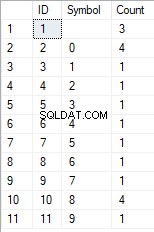
Tento příklad ukazuje, že řádek je transformován do seznamu znaků seskupených podle jejich jedinečnosti. Pole [Count] zobrazuje počet nálezů každého znaku ve vstupním řádku.
Na základě funkce pro více operátorů [test].[GetListCharacters] vytvoříme skalární funkci [test].[GetRandString2].
Definice nové skalární funkce ukazuje její podobnost se skalární funkcí [test].[GetRandString]. Jediný rozdíl je v tom, že používá víceoperátorovou funkci [test].[GetListCharacters] namísto funkce tabelování [test].[GetSelectCharacters].
Zde si projdeme dva příklady použití implementované skalární funkce :
Ze vstupního řádku znaků neseskupených podle jedinečnosti vygenerujeme pseudonáhodný řádek o délce 12 znaků:
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', DEFAULT);Výsledek je:
64017!!5!!!7
Klíčové slovo je DEFAULT. Uvádí, že výchozí hodnota nastavuje parametr. Zde je nula (0).
Nebo
Ze vstupního řádku znaků seskupených podle jedinečnosti vygenerujeme pseudonáhodný řádek o délce 12 znaků:
SELECT [test].[GetRandString2](12, '123456789!!!!!!!!0!!!', 1);Výsledek je:
35792!428273
Implementace obecného skriptu pro dezinfekci dat a změny tajných dat
Prozkoumali jsme jednoduché příklady pro každý typ změněných dat:
- změna data a času;
- změna číselné hodnoty;
- Změna sekvence bajtů;
- Změna údajů postav.
Tyto příklady však nesplňují kritéria 2 a 3 pro skripty měnící data:
- Kritérium 2 :selektivita hodnot se ve změněných datech výrazně nezmění. Pro pole tabulky nelze použít hodnotu NULL. Místo toho musíte zajistit, aby stejné hodnoty skutečných dat zůstaly stejné ve změněných datech. Např. pokud skutečná data obsahují 12krát hodnotu 103785 v poli tabulky, které podléhá změnám, musí upravená data obsahovat jinou (změněnou) hodnotu, která se ve stejném poli tabulky nachází 12krát.
- Kritérium 3 :délka a velikost hodnot by se ve změněných datech neměla výrazně měnit. Např. každý znak/bajt nahradíte pseudonáhodným znakem/bajtem.
Potřebujeme tedy vytvořit skript, který zohlední selektivitu hodnot v polích tabulky.
Pojďme se podívat na naši databázi pro náborovou službu. Jak vidíme, osobní údaje jsou uvedeny pouze v tabulce kandidátů [dbo].[Zaměstnanec].
Předpokládejme, že tabulka obsahuje následující pole:
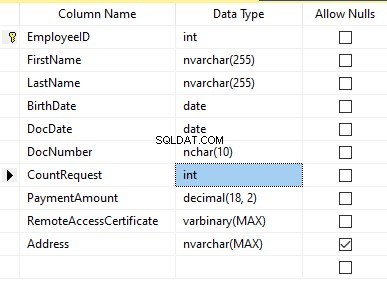
Popisy:
- Jméno – název, řádek NVARCHAR(255)
- Příjmení – příjmení, řádek NVARCHAR(255)
- Datum narození – datum narození, DATUM
- Číslo dokumentu – číslo průkazu totožnosti se dvěma číslicemi na začátku pro řadu pasů a dalších sedm číslic představuje číslo dokumentu. Mezi nimi máme pomlčku jako řádek NCHAR(10).
- DocDate – datum vydání občanského průkazu, DATUM
- CountRequest – počet žádostí o daného kandidáta při hledání životopisu, celé číslo INT
- Částka platby – obdržený poplatek za službu propagace životopisu, desetinné číslo (18,2)
- RemoteAccessCertificate – certifikát pro vzdálený přístup, posloupnost bajtů VARBINARY
- Adresa – adresa bydliště nebo registrační adresa, řádek NVARCHAR(MAX)
Pak, abychom zachovali počáteční selektivitu, musíme implementovat následující algoritmus:
- Extrahujte všechny jedinečné hodnoty pro každé pole a výsledky uchovávejte v dočasných tabulkách nebo tabelačních proměnných;
- Pro každou jedinečnou hodnotu vygenerujte pseudonáhodnou hodnotu. Tato pseudonáhodná hodnota se nesmí výrazně lišit délkou a velikostí od původní hodnoty. Výsledek uložte na stejné místo, kam jsme uložili výsledky bodu 1. Každá nově vygenerovaná hodnota musí mít jedinečnou korelaci aktuální hodnoty.
- Nahraďte všechny hodnoty v tabulce novými hodnotami z bodu 2.
Na začátku odosobňujeme jména a příjmení kandidátů. Předpokládáme, že příjmení a křestní jméno jsou vždy uvedena a v každém poli nejsou kratší než dva znaky.
Nejprve vybereme jedinečná jména. Poté pro každé jméno vygeneruje pseudonáhodný řádek. Délka jména zůstává stejná; první znak je velký a ostatní znaky jsou malé. Dříve vytvořenou skalární funkci [test].[GetRandString] používáme ke generování pseudonáhodného řádku specifické délky podle definovaných kritérií znaků.
Poté aktualizujeme jména v tabulce kandidátů podle jejich jedinečných hodnot. Totéž platí pro příjmení.
Depersonalizujeme pole DocNumber. Je to číslo občanského průkazu (pasu). První dva znaky představují sérii dokumentu a posledních sedm číslic je číslo dokumentu. Pomlčka je mezi nimi. Poté provedeme sanitační operaci.
Shromažďujeme všechna jedinečná čísla dokumentů a pro každý z nich vygenerujeme pseudonáhodný řádek. Formát řádku je 'XX-XXXXXXX,' kde X je číslice v rozsahu 0 až 9. Zde používáme dříve vytvořenou skalární funkci [test].[GetRandString] ke generování pseudonáhodného řádku zadané délky podle nastavené parametry znaků.
Poté se pole [DocNumber] aktualizuje v tabulce kandidátů [dbo].[Zaměstnanec].
Depersonalizujeme pole DocDate (datum vydání občanského průkazu) a pole BirthDate (datum narození kandidáta).
First, we select all the unique pairs made of “date of birth &date of the ID-card issue.” For each such pair, we create a pseudorandom date for the date of birth. The pseudorandom date of the ID-card issue is made according to that “date of birth” – the date of the document’s issue must not be earlier than the date of birth.
After that, these data are updated in the respective fields of the candidates’ table [dbo].[Employee].
And, we update the remaining fields of the table.
The CountRequest value stands for the number of requests made for that candidate by companies during the resume search.
The PaymentAmount is the final amount of the resume promotion service fee paid. We calculate these numbers similarly to the previous fields.
Note that it generates a pseudorandom integer for the first case and a pseudorandom decimal for the second case. In both cases, the pseudorandom number generation occurs in the range of “two times less than original” to “two times more than original.” The selectivity of values in the fields is not changed too much.
After that, it writes the values into the fields of the candidates’ table [dbo].[Employee].
Further, we collect unique values of the RemoteAccessCertificate field for the remote access certificate. We generate a pseudorandom byte sequence for each such value. The length of the sequence must be the same as the original. Here, we use the previously created [test].[GetRandVarbinary] scalar function to generate the pseudorandom byte sequence of the specified length.
Then recording into the respective field [RemoteAccessCertificate] of the [dbo].[Employee] candidates’ table takes place.
The last step is the collection of the unique addresses from the [Address] field. For each value, we generate a pseudorandom line of the same length as the original. Note that if it was NULL originally, it must be NULL in the generated field. It allows you to keep NULL and don’t replace it with an empty line. It minimizes the selectivity values’ mismatch in this field between the production database and the altered data.
We use the previously created [test].[GetRandString] scalar function to generate the pseudorandom line of the specified length according to the characters’ parameters defined.
It then records the data into the respective [Address] field of the candidates’ table [dbo].[Employee].
This way, we get the full script for depersonalization and altering of the confidential data.
Finally, we get the database with altered personal and confidential data. The algorithms we used make it impossible to restore the original data from the altered data. Also, the values’ selectivity, length, and size aren’t changed significantly. So, the three criteria for the personal and secret data altering scripts are ensured.
We won’t review the criterion 4 separately here. Our database contains all the data subject to change in one candidates’ table [dbo].[Employee]. The data conformity is needed within this table only. Thus, criterion 4 is also here. However, we need to remember this criterion 4 claiming that all interrelations must remain the same in the altered data.
We often see other conditions for personal and confidential data altering algorithms, but we won’t review them here. Besides, the four criteria described above are always present. In many cases, it is enough to estimate the functionality of the algorithm suitable to use it.
Now, we need to make a backup of the created database, check it by restoring on another instance, and transfer that copy into the necessary environment for development and testing. For this, we examine the full database backup creation.
Full database backup creation
We can make a database backup with construction BACKUP DATABASE as in our example.
Make a compressed full backup of the database JobEmplDB_Test. The checksum calculation takes place in the file E:\Backup\JobEmplDB_Test.bak. Further, we check the backup created.
Then, we check the backup created by restoring the database for it. Let’s examine the database restoring.
Restoring the database
You can restore the database with the help of RESTORE DATABASE construction in the following way:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the JobEmplDB_Test database of the E:\Backup\JobEmplDB_Test.bak backup. The files will be overwritten, and the data file will be transferred into the file E:\DBData\JobEmplDB.mdf , while the transactions log file will be moved into F:\DBLog\JobEmplDB_log.ldf .
After we successfully check how the database is restored from the backup, we forward the backup to the development and testing environments. It will be restored again with the same method as described above.
We’ve examined the first approach to the data populating into the database for testing and development. This approach implies copying and altering the data from the production database. Now, we’ll examine the second approach – the synthetic data generation.
Synthetic data generation
The General algorithm for the synthetic data generation is following:
- Make a new empty database or clear a previously created database by purging all data.
- Create or renew a scheme in the newly created database – the same as that of the production databases.
- Copy of renew guidelines and regulations from the production database and transfer them into the new database.
- Generate synthetic data into the necessary tables of the new database.
- Make a backup of a new database.
- Deliver and restore the new backup in the necessary environment.
We already have the JobEmplDB_Test database to practice, and we have reviewed the means of creating a schema in the new database. Let’s focus on the tasks that are specific to this approach.
Clean up the database with the data purge
To clear the database off all its data, we need to do the following:
- Keep the definitions of all external keys.
- Disable all limitations and triggers.
- Delete all external keys.
- Clear the tables using the TRUNCATE construction.
- Restore all the external keys deleted in point 3.
- Enable all the limitations disabled in point 2.
You can save the definitions of all external keys with the following script:
1. The external keys’ definitions are saved in the tabulation variable @tbl_create_FK
2. You can disable the limitations and triggers with the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? NOCHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? DISABLE TRIGGER ALL";
To enable the limitations and triggers, you can use the following script:
EXEC sp_MSforeachtable "ALTER TABLE ? WITH CHECK CHECK CONSTRAINT ALL";
EXEC sp_MSforeachtable "ALTER TABLE ? ENABLE TRIGGER ALL";
Here, we use the saved procedure sp_MSforeachtable that applies the construction to all the database’s tables.
3. To delete external keys, use the special script. Here, we receive the information about the external keys through the INFORMATION_SCHEMA.TABLE_CONSTRAINTS system presentation. We delete external keys through the cursor, one by one, using the formed dynamic script T-SQL, transferring the request into the system saved procedure sp_executesql .
4. To clear the tables with the TRUNCATE construction, use the dedicated script. The script works in the same way as above, but it receives the data for tables, and then it clears the tables one by one through the cursor, using the TRUNCATE construction.
5. Restoring the external keys is possible with the below script (earlier, we saved the external keys’ definitions in the tabulation variable @tbl_create_FK):
DECLARE @tsql NVARCHAR(4000);
DECLARE FK_Create CURSOR LOCAL FOR SELECT
[Script]
FROM @tbl_create_FK;
OPEN FK_Create;
FETCH NEXT FROM FK_Create INTO @tsql;
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
FETCH NEXT FROM FK_Create INTO @tsql;
END
CLOSE FK_Create;
DEALLOCATE FK_Create;
The script works in the same way as the two other scripts we mentioned above. But it restores the external keys’ definitions through the cursor, one for each iteration.
A particular case of data purging in the database is the current script. To get this output, we need the below construction in the scripts:
EXEC sp_executesql @tsql = @tsql;Before this construction, or instead of it, we need to write the generated construction output. It is necessary to call it manually or via the dynamic T-SQL query. We do it via the system saved procedure sp_executesql.
Instead of the below code fragment in all cases:
WHILE (@@fetch_status = 0)
BEGIN
EXEC sp_executesql @tsql = @tsql;
...
We write:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
EXEC sp_executesql @tsql = @tsql;
...
Or:
WHILE (@@fetch_status = 0)
BEGIN
PRINT @tsql;
...
The first case implies both the output of constructions and their execution. The second case if for the output only – it is helpful for the scripts’ debugging.
Thus, we get the general database cleaning script.
Copy guidelines and references from the production database to the new one
Here you can use the T-SQL scripts. Our example database of the recruitment service includes 5 guidelines:
- [dbo].[Company] – companies
- [dbo].[Skill] – skills
- [dbo].[Position] – positions (occupation)
- [dbo].[Project] – projects
- [dbo].[ProjectSkill] – project and skills’ correlations
The “skills” table [dbo].[Skill] serves to show how to make a script for the data insertion from the production database into the test database.
We form the following script:
SELECT 'SELECT '+CAST([SkillID] AS NVARCHAR(255))+' AS [SkillID], '+''''+[SkillName]+''''+' AS [SkillName] UNION ALL'
FROM [dbo].[Skill]
ORDER BY [SkillID];
We execute it in a copy of the production database that is usually available in read-only mode. It is a replica of the production database.
Výsledek je:
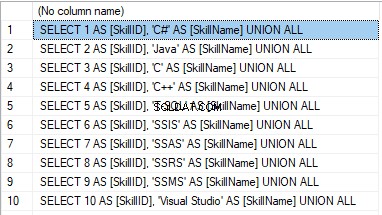
Now, wrap the result up into the script for the data adding as here. We have a script for the skills’ guideline compilation. The scripts for other guidelines are made in the same way.
However, it is much easier to copy the guidelines’ data through the data export and import in SSMS. Or, you can use the data import and export wizard.
Generate synthetic data
We’ve determined the pseudorandom values’ generation for lines, numbers, and byte sequences. It took place when we examined the implementation of the data sanitization and the confidential data altering algorithms for approach 1. Those implemented functions and scripts are also used for the synthetic data generation.
The recruitment service database requires us to fill the synthetic data in two tables only:
- [dbo].[Employee] – candidates
- [dbo].[JobHistory] – a candidate’s work history (experience), the resume itself
We can fill the candidates’ table [dbo].[Employee] with synthetic data using this script.
At the beginning of the script, we set the following parameters:
- @count – the number of lines to be generated
- @LengthFirstName – the name’s length
- @LengthLastName – the last name’s length
- @StartBirthDate – the lower limit of the date for the date of birth
- @FinishBirthDate – the upper limit of the date for the date of birth
- @StartCountRequest – the lower limit for the field [CountRequest]
- @FinishCountRequest – the upper limit for the field [CountRequest]
- @StartPaymentAmount – the lower limit for the field [PaymentAmount]
- @FinishPaymentAmount – the upper limit for the field [PaymentAmount]
- @LengthRemoteAccessCertificate – the byte sequence’s length for the certificate
- @LengthAddress – the length for the field [Address]
- @count_get_unique_DocNumber – the number of attempts to generate the unique document’s number [DocNumber]
The script complies with the uniqueness of the [DocNumber] field’s value.
Now, let’s fill the [dbo].[JobHistory] table with synthetic data as follows.
The start date of work [StartDate] is later than the issuing date of the candidate’s document [DocDate]. The end date of work [FinishDate] is later than the start date of work [StartDate].
It is important to note that the current script is simplified, as it does not deal with parameters of the generated data selectivity configuration.
Make a full database backup
We can make a database backup with the construction BACKUP DATABASE, using our script.
We create a full compressed backup of the database JobEmplDB_Test. The checksum is calculated into the file E:\Backup\JobEmplDB_Test.bak. It also ensures further testing of the backup.
Let’s check the backup by restoring the database from it. We need to examine the database restoring then.
Restore the database
You can restore the database with the help of the RESTORE DATABASE construction, as shown below:
USE [master]
RESTORE DATABASE [JobEmplDB_Test]
FROM DISK = N'E:\Backup\JobEmplDB_Test.bak' WITH FILE = 1,
MOVE N'JobEmplDB' TO N'E:\DBData\JobEmplDB.mdf',
MOVE N'JobEmplDB_log' TO N'F:\DBLog\JobEmplDB_log.ldf',
NOUNLOAD,
REPLACE,
STATS = 5;
GO
We restore the database JobEmplDB_Test from the backup E:\Backup\JobEmplDB_Test.bak. The files are overwritten, and the data file is transferred to the file E:\DBData\JobEmplDB.mdf. The transaction log file is transferred to file F:\DBLog\JobEmplDB_log.ldf.
After checking the database restoring from the backup successfully, we transfer the backup to the necessary environments. It will be used for testing and development, and further deployment through the database restoring, as described above.
This way, we’ve examined the second approach to filling the database in with data for testing and development purposes. It is the synthetic data generation approach.
Data generation tools (for external resources)
When we have a job to fill in the database with data for testing and development purposes, it can be much faster and easier with the help of specialized tools. Let’s review the most popular and powerful data generation tools and explore their practical usage.
Full list of tools
DATPROF
IRI RowGen
Data Generator for SQL Server
Redgate SQL Data Generator
DTM Data Generator
Datanamic Data Generator MultiDB
Now, let’s examine one of these tools more precisely.
An overview of the employees’ generation by the Data Generator for SQL Server
The Data Generator for SQL Server utility is embedded in SSMS, and also it is a part of dbForge Studio. We reviewed this utility here. Let’s now examine how it works for synthetic data generation. As examples, we use the [dbo].[Employee] and the [dbo].[JobHistory] tables.
This generator can quickly generate first and last names of candidates for the [FirstName] and [LastName] fields respectively:
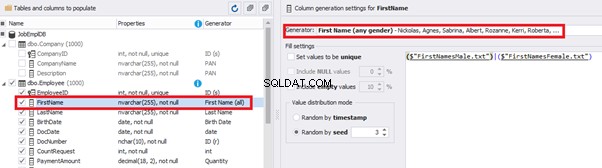
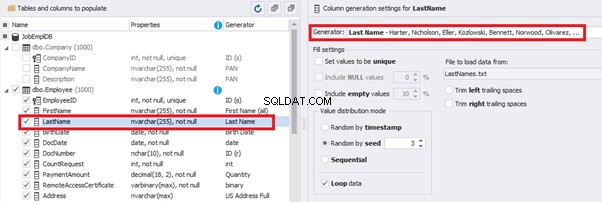
Note that FirstName requires choosing the “First Name” value in the “Generator” section. For LastName, you need to select the “Last Name” value from the “Generator” section.
It is important to note that the generator automatically determines which generation type it needs to apply to every field. The settings above were set by the generator itself, without manual correction.
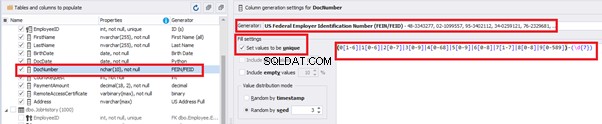
You can configure distribution of values for the date of birth [BirthDate]:
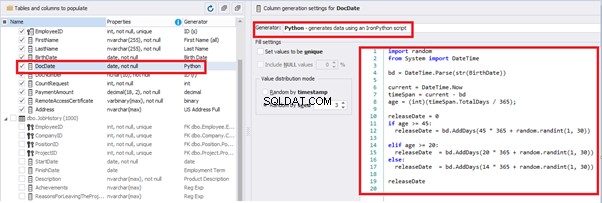
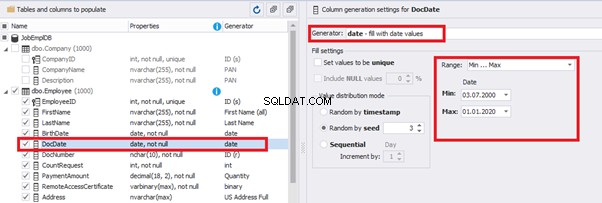
Set the distribution for the document’s date of issue [DocDate] through the Phyton generator using the below script:
import random
from System import DateTime
# receive the value from the Birthday field
bd = DateTime.Parse(str(BirthDate))
# receive the current date
current = DateTime.Now
# calculate the age in years
timeSpan = current - bd
age = (int)(timeSpan.TotalDays / 365);
# passport’s date of issue
releaseDate = 0
if age >= 45:
releaseDate = bd.AddDays(45 * 365 + random.randint(1, 30))
# randomize the issue during the month
elif age >= 20:
releaseDate = bd.AddDays(20 * 365 + random.randint(1, 30))
# randomize the issue during the month
else:
releaseDate = bd.AddDays(14 * 365 + random.randint(1, 30))
# randomize the issue during the month
releaseDateThis way, the [DocDate] configuration will look as follows:
For the document’s number [DocNumber], we can select the necessary type of unique data generation, and edit the generated data format, if needed:
E.g., instead of the format
(0[1-6]|1[0-6]|2[0-7]|3[0-9]|4[0-68]|5[0-9]|6[0-8]|7[1-7]|8[0-8]|9[0-589])-(\d{7})We can set the following format:
(\d{2})-(\d{7})This format means that the line will be generated in format XX-XXXXXXX (X – is a digit in the range of 0 to 9).
We set up the generator for [CountRequest] and [PaymentAmount] fields in the same way, according to the generated data type:
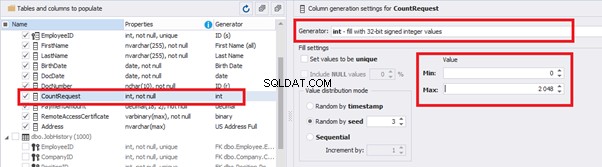
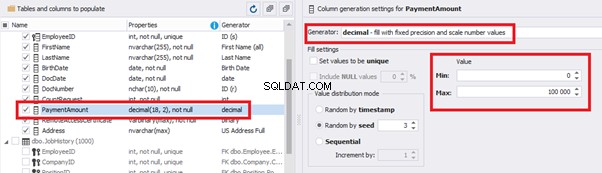
In the first case, we set the values’ range of 0 to 2048 for [CountRequest]. In the second case, it is the range of 0 to 100000 for [PaymentAmount].
We configure generation for [RemoteAccessCertificate] and [Address] fields in the same way:
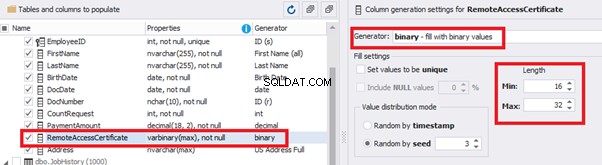
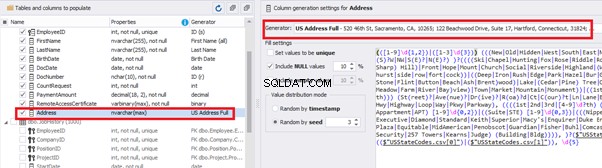
In the first case, we limit the byte sequence [RemoteAccessCertificate] with the range of lengths of 16 to 32. In the second case, we select values for [Address] as real addresses. It makes the generated values looking like the real ones.
This way, we’ve configured the synthetic data generation settings for the candidates’ table [dbo].[Employee]. Let’s now set up the synthetic data generation for the [dbo].[JobHistory] table.
We set it to take the data for the [EmployeeID] field from the candidates’ table [dbo].[Employee] in the following way:
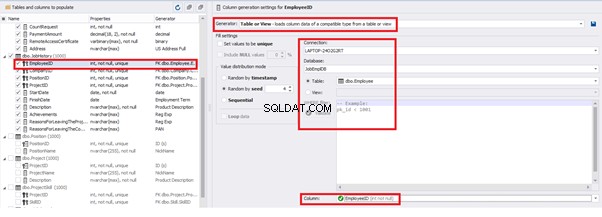
We select the generator’s type from the table or presentation. We then define the sample of MS SQL Server, the database, and the table to take the data from. We can also configure filters in the “WHERE filter” section, and select the [EmployeeID] field.
Here we suppose that we generate the “employees” first, and then we generate the data for the [dbo].[JobHistory] table, basing on the filled [dbo].[Employee] reference.
However, if we need to generate the data for both [dbo].[Employee] and [dbo].[JobHistory] at the same time, we need to select “Foreign Key (manually assigned) – references a column from the parent table,” referring to the [dbo].[Employee].[EmployeeID] column:
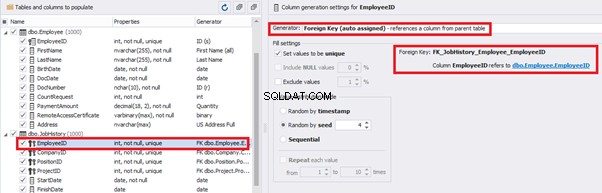
Similarly, we set up the data generation for the following fields.
[CompanyID] – from [dbo].[Company], the “companies” table:
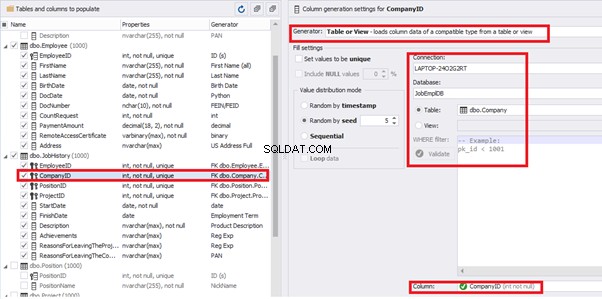
[PositionID] – from the table of positions [dbo].[Position]:
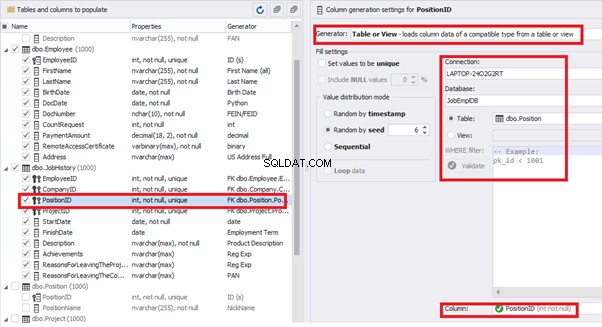
[ProjectID] – from the table of projects [dbo].[Project]:
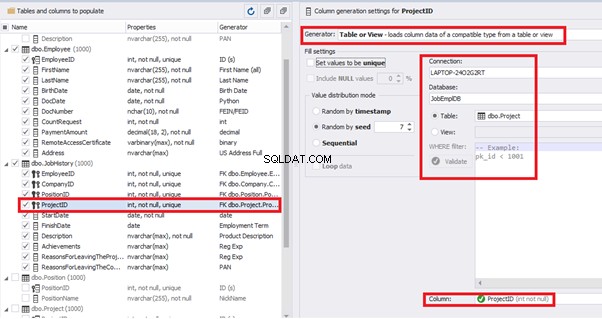
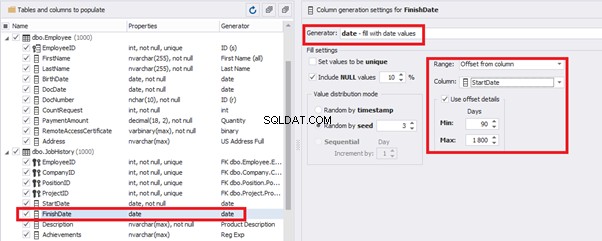
The tool cannot link the columns from different tables and shift them in some way. However, the generator can shift the date within one table – the “date” generator – fill with date values with Range – Offset from the column. Also, it can use data from a different table, but without any transformation (Table or View, SQL query, Foreign key generators).
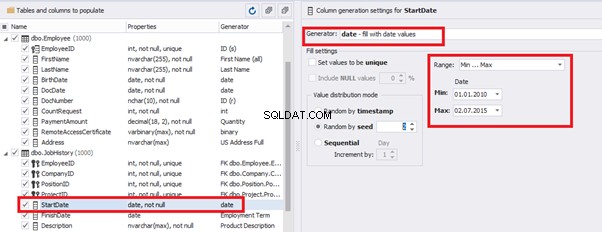
That’s why we resolve the dates’ problem (BirthDate
E.g., we limit the BirthDate with the 40-50 years’ interval. Then, we restrict the DocDate with 20-40 years’ interval. The StartDate is, respectively, limited with 25-35 years’ interval, and we set up the FinishDate with the offset from StartDate.
We set up the date of birth:
Set up the date of the document’s issue
Then, the StartDate will match the age from 35 to 45:
The simple offset generator sets FinishDate:
The result is, a person has worked for three months till the current date.
Also, to configure the date of the working end, we can use a small Python script:
This way, we receive the below configuration for the dates of work end [FinishDate] data generation:
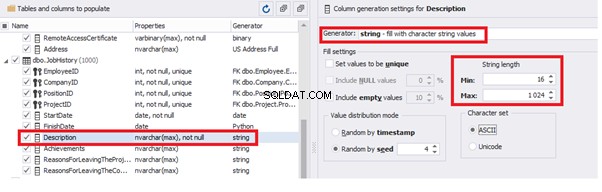
Similarly, we fill in the rest of fields. We set the generator type – string, and set the range for generated lines’ lengths:
Also, you can save the data generation project as dgen-file consisting of:
We can save all these settings:it is enough to keep the project’s file and work with the database further, using that file:
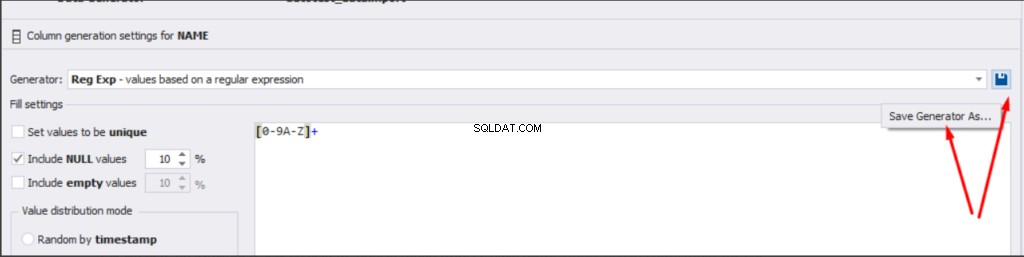
There is also the possibility to both save the new generators from scratch and save the custom settings in a new generator:
Thus, we’ve configured the synthetic data generation settings used for the jobs’ history table [dbo].[JobHistory].
We have examined two approaches to filling the data in the database for testing and development:
We’ve defied the objects for each approach and each script implementation. These objects are here. We’ve also provided scripts for changing the data from the production database and synthetic data generation. An example is the database of recruitment services. In the end, we’ve examined popular data generation tools and explored one of these tools in detail.
SQL SERVER – How to Disable and Enable All Constraint for Table and Database 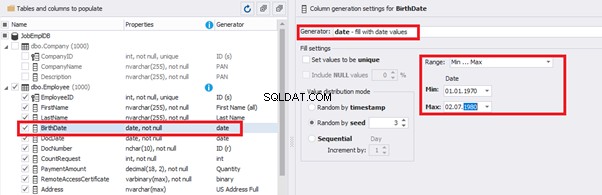
import random
from System import DateTime
bd = DateTime.Parse(str(StartDate))
releaseDate = bd.AddDays(random.randint(1, 30))
releaseDate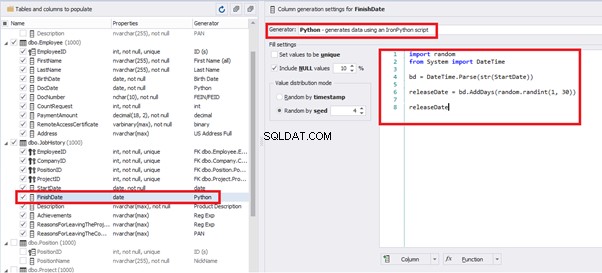
Závěr
Odkazy
Microsoft TechNet Wiki
Top 10 Best Test Data Generation Tools In 2020
SQL Server Documentation