Často vidím, jak lidé bojují se serverem SQL, když vidí dva různé plány provádění pro to, co považují za stejný dotaz. Obvykle se to zjistí po jiných pozorováních, jako jsou výrazně odlišné doby provádění. Říkám, že věří, že je to stejný dotaz, protože někdy je a někdy není.
Jedním z nejčastějších případů je, když testují dotaz v SSMS a dostávají jiný plán, než jaký získávají ze své aplikace. Potenciálně zde hrají roli dva faktory (které mohou být také relevantní, když NENÍ srovnání mezi aplikací a SSMS):
- Aplikace má téměř vždy jiný
SETnastavení než SSMS (to jsou věci jakoARITHABORT,ANSI_NULLSaQUOTED_IDENTIFIER). To přinutí SQL Server ukládat dva plány samostatně; Erland Sommarskog se tím velmi podrobně zabýval ve svém článku Pomalu v aplikaci, rychle v SSMS?
- Parametry používané aplikací při první kompilaci její kopie plánu mohly být velmi odlišné a vést k jinému plánu, než ty, které byly použity při prvním spuštění dotazu ze SSMS – toto je známé jako sniffování parametrů . Erland o tom také mluví do hloubky a já nehodlám jeho doporučení opakovat, ale shrnu to tím, že vám připomenu, že testování dotazu aplikace v SSMS není vždy užitečné, protože je docela nepravděpodobné, že by šlo o test jablek na jablka.
Existuje několik dalších scénářů, které jsou o něco nejasnější a které uvádím ve své přednášce o špatných návycích a osvědčených postupech. To jsou případy, kdy se plány neliší, ale existuje více kopií stejného plánu, které naplňují mezipaměť plánu. Myslel jsem, že bych je zde měl zmínit, protože vždy překvapí tolik lidí.
CasE a mezery jsou důležité
SQL Server hashuje text dotazu do binárního formátu, což znamená, že každý jednotlivý znak v textu dotazu je zásadní. Vezměme si následující jednoduché dotazy:
USE AdventureWorks2014; DBCC FREEPROCCACHE WITH NO_INFOMSGS; GO SELECT StoreID FROM Sales.Customer; GO -- original query GO SELECT StoreID FROM Sales.Customer; GO ----^---- extra space GO SELECT storeid FROM sales.customer; GO ---- lower case names GO select StoreID from Sales.Customer; GO ---- lower case keywords GO
Ty samozřejmě generují přesně stejné výsledky a generují přesně stejný plán. Pokud se však podíváme na to, co máme v mezipaměti plánu:
SELECT t.[text], p.size_in_bytes, p.usecounts FROM sys.dm_exec_cached_plans AS p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t WHERE LOWER(t.[text]) LIKE N'%sales'+'.'+'customer%';
Výsledky jsou nešťastné:
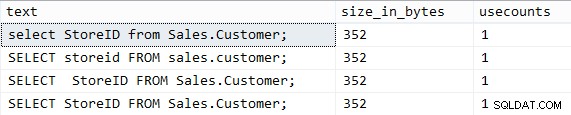
V tomto případě je tedy jasné, že velká a malá písmena a mezery jsou velmi důležité. Mluvil jsem o tom mnohem podrobněji loni v květnu.
Odkazy na schéma jsou důležité
Již dříve jsem psal na blogu o důležitosti specifikování předpony schématu při odkazování na jakýkoli objekt, ale v té době jsem si nebyl plně vědom, že to má také důsledky pro mezipaměť plánu.
Podívejme se na velmi jednoduchý případ, kdy máme dva uživatele s různými výchozími schématy, kteří spouštějí přesně stejný text dotazu, aniž by odkazovali na objekt podle jeho schématu:
USE AdventureWorks2014; DBCC FREEPROCCACHE WITH NO_INFOMSGS; GO CREATE USER SQLPerf1 WITHOUT LOGIN WITH DEFAULT_SCHEMA = Sales; CREATE USER SQLPerf2 WITHOUT LOGIN WITH DEFAULT_SCHEMA = Person; GO CREATE TABLE dbo.AnErrorLog(id INT); GRANT SELECT ON dbo.AnErrorLog TO SQLPerf1, SQLPerf2; GO EXECUTE AS USER = N'SQLPerf1'; GO SELECT id FROM AnErrorLog; GO REVERT; GO EXECUTE AS USER = N'SQLPerf2'; GO SELECT id FROM AnErrorLog; GO REVERT; GO
Nyní, když se podíváme na mezipaměť plánu, můžeme stáhnout sys.dm_exec_plan_attributes abyste přesně viděli, proč získáváme dva různé plány pro identické dotazy:
SELECT t.[text], p.size_in_bytes, p.usecounts, [schema_id] = pa.value, [schema] = s.name FROM sys.dm_exec_cached_plans AS p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t CROSS APPLY sys.dm_exec_plan_attributes(p.plan_handle) AS pa INNER JOIN sys.schemas AS s ON s.[schema_id] = pa.value WHERE t.[text] LIKE N'%AnError'+'Log%' AND pa.attribute = N'user_id';
Výsledky:

A pokud to všechno spustíte znovu, ale přidáte dbo. prefix pro oba dotazy, uvidíte, že existuje pouze jeden plán, který se použije dvakrát. To se stává velmi přesvědčivým argumentem pro vždy plně odkazující objekty.
SET nastavení redux
Jako vedlejší poznámku můžete použít podobný přístup k určení, zda SET nastavení se liší pro dvě nebo více verzí stejného dotazu. V tomto případě zkoumáme dotazy spojené s více plány generovanými různými voláními stejné uložené procedury, ale můžete je také identifikovat podle textu dotazu nebo hash dotazu.
SELECT p.plan_handle, p.usecounts, p.size_in_bytes, set_options = MAX(a.value) FROM sys.dm_exec_cached_plans AS p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t CROSS APPLY sys.dm_exec_plan_attributes(p.plan_handle) AS a WHERE t.objectid = OBJECT_ID(N'dbo.procedure_name') AND a.attribute = N'set_options' GROUP BY p.plan_handle, p.usecounts, p.size_in_bytes;
Pokud zde máte více výsledků, měli byste vidět různé hodnoty pro set_options (což je bitová maska). To je jen začátek; Vysvětlím vám, že můžete určit, která sada možností je povolena pro každý plán, rozbalením hodnoty podle části „Vyhodnocení možností sady“ zde. Ano, jsem tak líný.
Závěr
Existuje několik důvodů, proč můžete vidět různé plány pro stejný dotaz (nebo to, co si myslíte, že je stejný dotaz). Ve většině případů můžete izolovat příčinu docela snadno; výzvou je často vědět, že je na prvním místě hledat. V dalším příspěvku budu mluvit o trochu jiném tématu:proč databáze obnovená na "identický" server může přinést různé plány pro stejný dotaz.