Mysqldump je nejoblíbenější nástroj pro logické zálohování pro MySQL. Je součástí distribuce MySQL, takže je připraven k použití ve všech instancích MySQL.
Logické zálohy však nejsou nejrychlejším ani prostorově nejefektivnějším způsobem zálohování databází MySQL, ale oproti fyzickým zálohám mají obrovskou výhodu.
Fyzické zálohy jsou obvykle zálohy typu všechno nebo nic. I když by mohlo být možné vytvořit částečnou zálohu pomocí Xtrabackup (to jsme popsali v jednom z našich předchozích blogových příspěvků), obnovení takové zálohy je složité a časově náročné.
Pokud chceme obnovit jednu tabulku, musíme zastavit celý replikační řetězec a provést obnovu na všech uzlech najednou. To je hlavní problém – v dnešní době si jen zřídka můžete dovolit zastavit všechny databáze.
Dalším problémem je, že úroveň tabulky je nejnižší úroveň granularity, které můžete pomocí Xtrabackup dosáhnout:můžete obnovit jednu tabulku, ale nemůžete obnovit její část. Logické zálohování však lze obnovit způsobem spouštění příkazů SQL, takže jej lze snadno provádět na běžícím clusteru a můžete (nenazývali bychom to snadno, ale přesto) si vybrat, které příkazy SQL chcete spustit, abyste mohli provést částečnou obnovu tabulky.
Pojďme se podívat, jak to lze provést v reálném světě.
Obnova jedné tabulky MySQL pomocí mysqldump
Na začátku mějte prosím na paměti, že částečné zálohy neposkytují konzistentní pohled na data. Když pořídíte zálohy samostatných tabulek, nemůžete takovou zálohu obnovit do známé pozice v čase (například za účelem zřízení replikačního slave zařízení), i když byste obnovili všechna data ze zálohy. Když to máme za sebou, pojďme dál.
Máme pána a otroka:
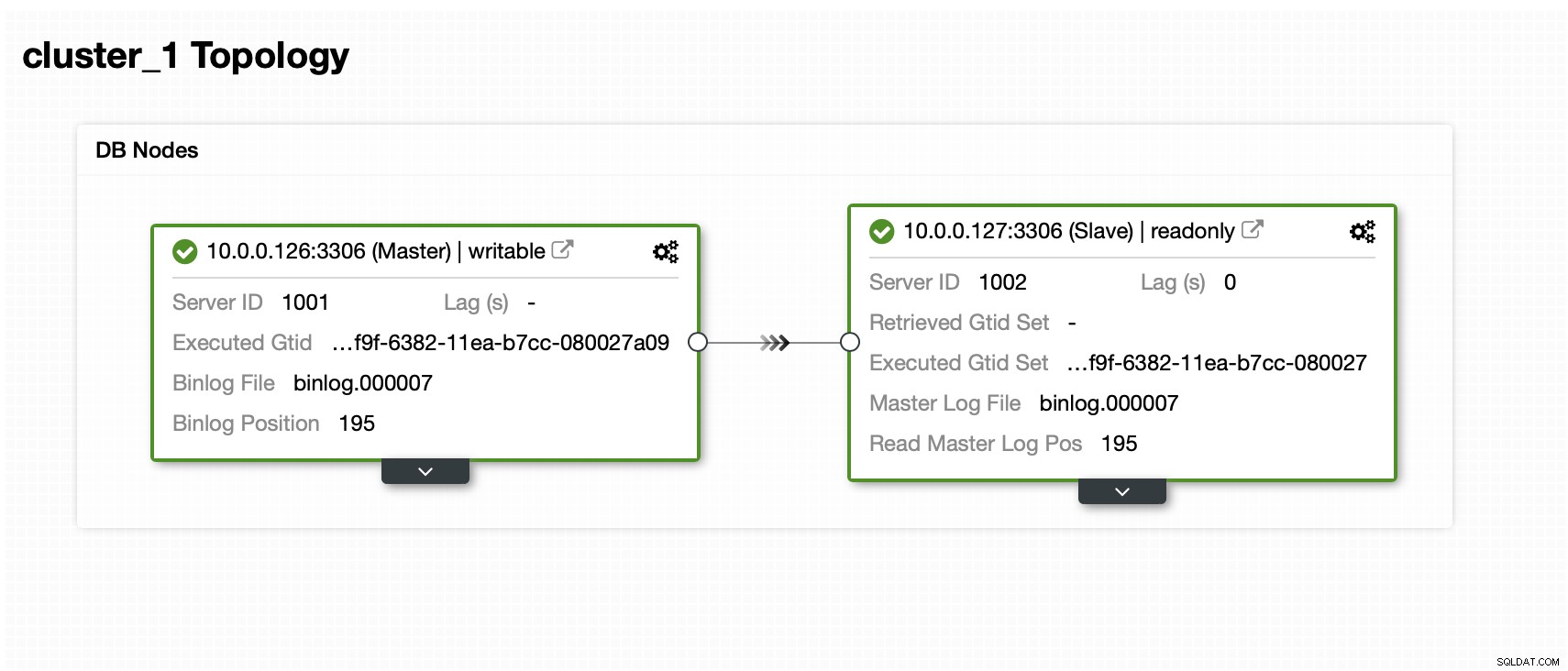
Datová sada obsahuje jedno schéma a několik tabulek:
mysql> SHOW SCHEMAS;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sbtest |
| sys |
+--------------------+
5 rows in set (0.01 sec)
mysql> SHOW TABLES FROM sbtest;
+------------------+
| Tables_in_sbtest |
+------------------+
| sbtest1 |
| sbtest10 |
| sbtest11 |
| sbtest12 |
| sbtest13 |
| sbtest14 |
| sbtest15 |
| sbtest16 |
| sbtest17 |
| sbtest18 |
| sbtest19 |
| sbtest2 |
| sbtest20 |
| sbtest21 |
| sbtest22 |
| sbtest23 |
| sbtest24 |
| sbtest25 |
| sbtest26 |
| sbtest27 |
| sbtest28 |
| sbtest29 |
| sbtest3 |
| sbtest30 |
| sbtest31 |
| sbtest32 |
| sbtest4 |
| sbtest5 |
| sbtest6 |
| sbtest7 |
| sbtest8 |
| sbtest9 |
+------------------+
32 rows in set (0.00 sec)Nyní musíme udělat zálohu. Existuje několik způsobů, jak k tomuto problému můžeme přistupovat. Můžeme pouze provést konzistentní zálohu celé datové sady, ale vygeneruje se velký, jediný soubor se všemi daty. Abychom obnovili jedinou tabulku, museli bychom z tohoto souboru extrahovat data pro tabulku. Je to samozřejmě možné, ale je to poměrně časově náročné a je to do značné míry ruční operace, kterou lze skriptovat, ale pokud nemáte na místě správné skripty, psaní kódu ad hoc, když je vaše databáze mimo provoz a jste pod velkým tlakem, je není nutně nejbezpečnější nápad.
Místo toho můžeme připravit zálohu tak, že každá tabulka bude uložena v samostatném souboru:
example@sqldat.com:~/backup# d=$(date +%Y%m%d) ; db='sbtest'; for tab in $(mysql -uroot -ppass -h127.0.0.1 -e "SHOW TABLES FROM ${db}" | grep -v Tables_in_${db}) ; do mysqldump --set-gtid-purged=OFF --routines --events --triggers ${db} ${tab} > ${d}_${db}.${tab}.sql ; doneUpozorňujeme, že jsme nastavili --set-gtid-purged=OFF. Potřebujeme to, pokud bychom tato data později načítali do databáze. Jinak se MySQL pokusí nastavit @@GLOBAL.GTID_PURGED, což s největší pravděpodobností selže. MySQL by také nastavilo SET @@SESSION.SQL_LOG_BIN=0; což rozhodně není to, co chceme. Tato nastavení jsou vyžadována, pokud bychom provedli konzistentní zálohu celé datové sady a chtěli bychom ji použít k vytvoření nového uzlu. V našem případě víme, že to není konzistentní záloha a neexistuje způsob, jak z ní něco znovu sestavit. Vše, co chceme, je vygenerovat výpis, který můžeme načíst na master a nechat ho replikovat na podřízené.
Tento příkaz vygeneroval pěkný seznam souborů SQL, které lze nahrát do produkčního clusteru:
example@sqldat.com:~/backup# ls -alh
total 605M
drwxr-xr-x 2 root root 4.0K Mar 18 14:10 .
drwx------ 9 root root 4.0K Mar 18 14:08 ..
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest10.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest11.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest12.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest13.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest14.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest15.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest16.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest17.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest18.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest19.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest1.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest20.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest21.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest22.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest23.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest24.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest25.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest26.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest27.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest28.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest29.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest2.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest30.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest31.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest32.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest3.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest4.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest5.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest6.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest7.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest8.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest9.sqlKdyž chcete obnovit data, vše, co musíte udělat, je načíst soubor SQL do hlavního uzlu:
example@sqldat.com:~/backup# mysql -uroot -ppass sbtest < 20200318_sbtest.sbtest11.sqlData budou načtena do databáze a replikována na všechny podřízené jednotky.
Jak obnovit jednu tabulku MySQL pomocí ClusterControl?
V současné době ClusterControl neposkytuje snadný způsob obnovení pouze jedné tabulky, ale stále je možné to provést pomocí několika ručních akcí. Můžete použít dvě možnosti. Za prvé, vhodné pro malý počet tabulek, můžete v podstatě vytvořit plán, kde budete provádět částečné zálohy samostatných tabulek jednu po druhé:
Zde provádíme zálohu tabulky sbtest.sbtest1. Můžeme snadno naplánovat další zálohu tabulky sbtest2:
Alternativně můžeme provést zálohu a umístit data z jednoho schématu do samostatný soubor:
Nyní můžete chybějící data najít buď ručně v souboru, obnovit tuto zálohu na samostatný server nebo to nechte udělat ClusterControl:
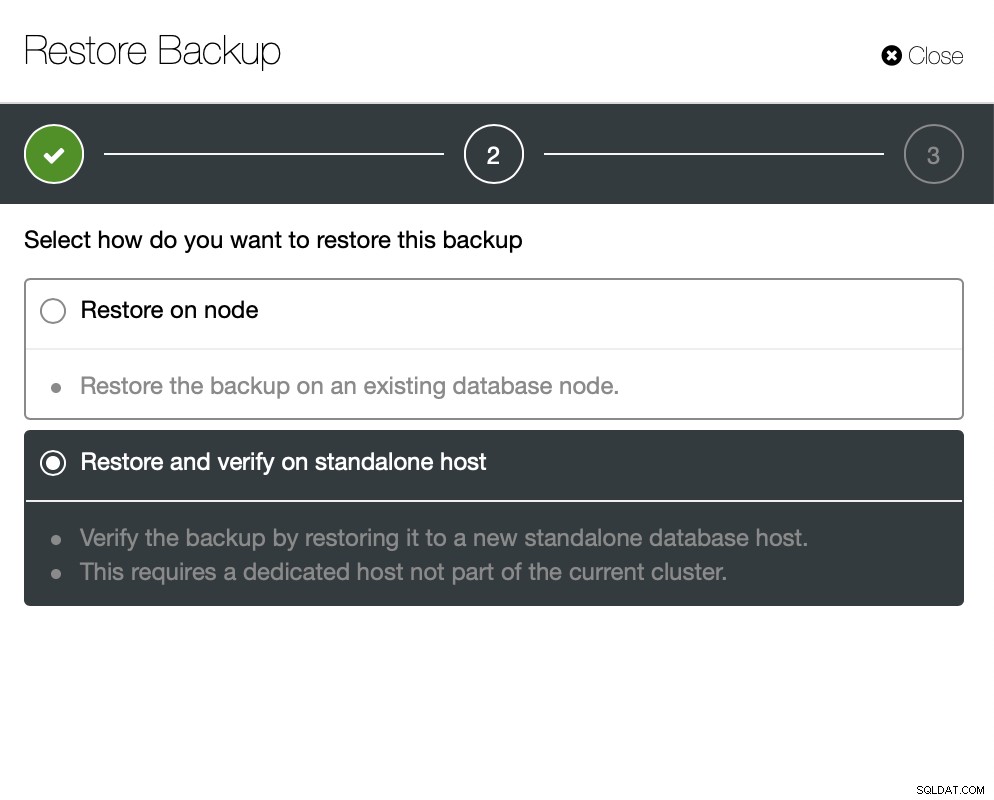
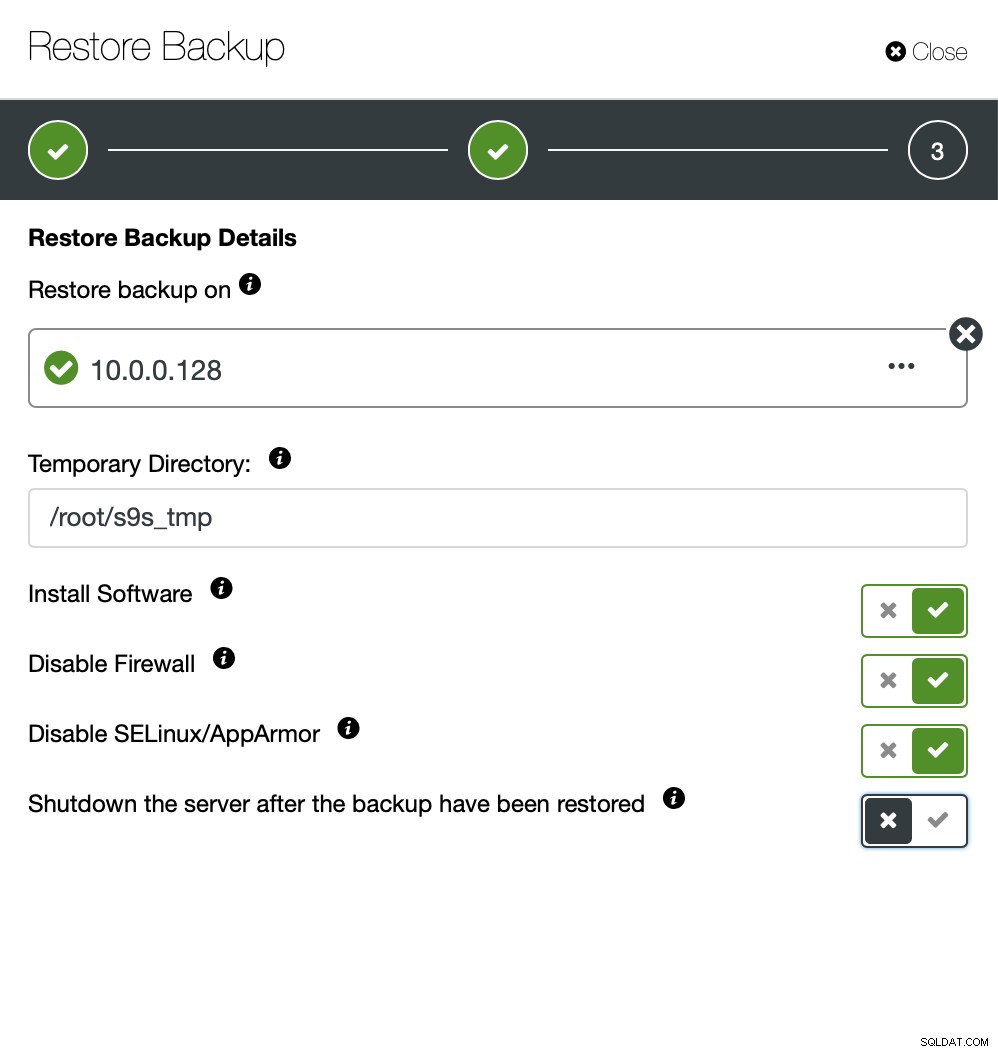
Udržíte server v provozu a můžete extrahovat data, která chtěl obnovit pomocí mysqldump nebo SELECT … INTO OUTFILE. Takto extrahovaná data budou připravena k použití v produkčním clusteru.