Zpracování NULL je jedním ze složitějších aspektů datového modelování a manipulace s daty pomocí SQL. Začněme tím, že pokus vysvětlit, přesně, co je NULL není samo o sobě triviální. Dokonce i mezi lidmi, kteří mají dobré znalosti relační teorie a SQL, uslyšíte velmi silné názory pro i proti používání hodnot NULL ve vaší databázi. Ať se vám to líbí nebo ne, jako databázový odborník se s nimi často musíte vypořádat, a vzhledem k tomu, že NULL přidávají složitost při psaní kódu SQL, je dobré jim dobře porozumět jako prioritu. Tímto způsobem se můžete vyhnout zbytečným chybám a nástrahám.
Tento článek je první ze série o složitosti NULL. Začnu pokrytím toho, co jsou NULL a jak se chovají ve srovnáních. Poté pokryjem nekonzistence zacházení s NULL v různých jazykových prvcích. Nakonec se zabývám chybějícími standardními funkcemi souvisejícími se zpracováním NULL v T-SQL a navrhuji alternativy, které jsou v T-SQL dostupné.
Většina pokrytí je relevantní pro jakoukoli platformu, která implementuje dialekt SQL, ale v některých případech zmiňuji aspekty, které jsou specifické pro T-SQL.
Ve svých příkladech použiji ukázkovou databázi nazvanou TSQLV5. Skript, který vytváří a naplňuje tuto databázi, najdete zde a její ER diagram zde.
NULL jako značka pro chybějící hodnotu
Začněme pochopením toho, co jsou NULL. V SQL je NULL značka nebo zástupný symbol pro chybějící hodnotu. Je to pokus SQL reprezentovat ve vaší databázi realitu, kde je určitá hodnota atributu někdy přítomna a někdy chybí. Předpokládejme například, že potřebujete uložit data zaměstnanců do tabulky Zaměstnanci. Máte atributy pro jméno, prostřední jméno a příjmení. Atributy jméno a příjmení jsou povinné, a proto je definujete jako nepovolující hodnoty NULL. Atribut middlename je volitelný, a proto jej definujete jako povolení hodnot NULL.
Pokud vás zajímá, co říká vztahový model o chybějících hodnotách, tvůrce modelu Edgar F. Codd v ně věřil. Ve skutečnosti dokonce rozlišoval mezi dvěma druhy chybějících hodnot:Missing But Applicable (značka A-hodnot) a Missing But Inapplicable (značka I-Values). Vezmeme-li jako příklad atribut prostředního jména, v případě, kdy má zaměstnanec prostřední jméno, ale z důvodu ochrany soukromí se rozhodne informace nesdílet, použijete značku A-Values. V případě, že zaměstnanec vůbec nemá druhé jméno, použijete značku I-Values. Zde může být tentýž atribut někdy relevantní a přítomen, někdy chybí, ale je použitelný a někdy chybí, ale nelze použít. Jiné případy by mohly být jasnější a podporovaly pouze jeden druh chybějících hodnot. Předpokládejme například, že máte tabulku Objednávky s atributem s názvem shippeddate, který obsahuje datum odeslání objednávky. Objednávka, která byla odeslána, bude mít vždy aktuální a relevantní datum odeslání. Jediným případem, kdy by nebylo známé datum odeslání, by byly objednávky, které ještě nebyly odeslány. Zde tedy musí být přítomna příslušná hodnota data odeslání, nebo by měla být použita značka I-Values.
Návrháři SQL se rozhodli nezabývat se rozlišováním mezi použitelnými a nepoužitelnými chybějícími hodnotami a poskytli nám NULL jako značku pro jakýkoli druh chybějící hodnoty. Z větší části bylo SQL navrženo tak, aby předpokládalo, že hodnoty NULL představují chybějící, ale použitelný druh chybějící hodnoty. V důsledku toho, zejména pokud používáte hodnotu NULL jako zástupný symbol pro nepoužitelnou hodnotu, nemusí být výchozí zpracování SQL NULL takové, které považujete za správné. Někdy budete muset přidat explicitní logiku zpracování NULL, abyste získali léčbu, kterou považujete za správnou pro vás.
Pokud víte, že atribut nemá povolovat hodnoty NULL, osvědčeným postupem je, abyste jej vynutili s omezením NOT NULL jako součást definice sloupce. Existuje pro to několik důležitých důvodů. Jedním z důvodů je, že pokud to nebudete prosazovat, v jednom nebo druhém bodě se tam dostanou NULL. Může to být důsledek chyby v aplikaci nebo importu špatných dat. Pomocí omezení víte, že hodnoty NULL se nikdy nedostanou do tabulky. Dalším důvodem je, že optimalizátor vyhodnocuje omezení jako NOT NULL pro lepší optimalizaci, čímž se vyhne zbytečné práci při hledání hodnot NULL a povolí určitá pravidla transformace.
Porovnání zahrnující hodnoty NULL
Při vyhodnocování predikátů SQL je určitá záludnost, když se jedná o hodnoty NULL. Nejprve se budu zabývat srovnáními zahrnujícími konstanty. Později se budu zabývat srovnáními zahrnujícími proměnné, parametry a sloupce.
Když použijete predikáty, které porovnávají operandy v prvcích dotazu, jako je WHERE, ON a HAVING, možné výsledky porovnání závisí na tom, zda některý z operandů může mít hodnotu NULL. Pokud s jistotou víte, že žádný z operandů nemůže být NULL, bude výsledek predikátu vždy buď PRAVDA, nebo NEPRAVDA. To je to, co je známé jako dvouhodnotová predikátová logika, nebo zkráceně jednoduše dvouhodnotová logika. To je případ, kdy například porovnáváte sloupec, který je definován jako nepovolující hodnoty NULL, s jiným operandem, který není NULL.
Pokud některý z operandů v porovnání může být NULL, řekněme, sloupec, který umožňuje hodnoty NULL pomocí operátorů rovnosti (=) i nerovnosti (<>,>, <,>=, <=atd.), jste nyní vydán na milost a nemilost trojhodnotové predikátové logice. Pokud v daném srovnání tyto dva operandy náhodou nejsou hodnoty NULL, stále dostanete jako výsledek buď PRAVDA, nebo NEPRAVDA. Pokud je však některý z operandů NULL, získáte třetí logickou hodnotu s názvem UNKNOWN. Všimněte si, že je tomu tak i při porovnávání dvou hodnot NULL. Zacházení s TRUE a FALSE většinou prvků SQL je docela intuitivní. Léčba NEZNÁMÉHO není vždy tak intuitivní. Kromě toho různé prvky SQL zacházejí s NEZNÁMÝM případem odlišně, jak podrobně vysvětlím později v článku pod „Nekonzistence léčby NULL“.
Předpokládejme například, že potřebujete dotaz na tabulku Sales.Orders ve vzorové databázi TSQLV5 a vrátit objednávky, které byly odeslány 2. ledna 2019. Použijte následující dotaz:
POUŽÍVEJTE TSQLV5; SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate ='20190102';
Je jasné, že predikát filtru se vyhodnotí jako PRAVDA pro řádky, kde je datum odeslání 2. ledna 2019, a že by tyto řádky měly být vráceny. Je také jasné, že predikát má hodnotu FALSE pro řádky, kde je uvedeno datum odeslání, ale není 2. ledna 2019, a že tyto řádky by měly být vyřazeny. Ale co řádky s datem odeslání NULL? Pamatujte, že predikáty založené na rovnosti i predikáty založené na nerovnosti vrátí NEZNÁMÝ, pokud je některý z operandů NULL. Filtr WHERE je navržen tak, aby takové řádky vyřadil. Musíte si pamatovat, že filtr WHERE vrací řádky, pro které je predikát filtru vyhodnocen jako PRAVDA, a zahazuje řádky, u kterých je predikát vyhodnocen jako FALSE nebo UNKNOWN.
Tento dotaz generuje následující výstup:
objednací datum odeslání----------- -----------10771 2019-01-0210794 2019-01-0210802 2019-01-02
Předpokládejme, že potřebujete vrátit objednávky, které nebyly odeslány 2. ledna 2019. Pokud jde o vás, objednávky, které ještě nebyly odeslány, mají být zahrnuty do výstupu. Použijete dotaz podobný poslednímu, pouze negujete predikát, například takto:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE NOT (shippeddate ='20190102');
Tento dotaz vrátí následující výstup:
Výstup přirozeně vylučuje řádky s datem odeslání 2. ledna 2019, ale také vylučuje řádky s datem odeslání NULL. Co by zde mohlo být kontraintuitivní, je to, co se stane, když použijete operátor NOT k negaci predikátu, který se vyhodnotí jako UNKNOWN. Je zřejmé, že NOT TRUE je NEPRAVDA a NOT FALSE je PRAVDA. NOT UNKNOWN však zůstává NEZNÁMÝ. Logika SQL za tímto návrhem spočívá v tom, že pokud nevíte, zda je návrh pravdivý, nevíte ani, zda návrh není pravdivý. To znamená, že při použití operátorů rovnosti a nerovnosti v predikátu filtru ani kladná, ani záporná forma predikátu nevrací řádky s hodnotami NULL.
Tento příklad je docela jednoduchý. Existují složitější případy zahrnující poddotazy. Při použití predikátu NOT IN s poddotazem, kdy poddotaz vrátí mezi vrácenými hodnotami hodnotu NULL, se vyskytuje běžná chyba. Dotaz vždy vrátí prázdný výsledek. Důvodem je, že kladná forma predikátu (část IN) vrací TRUE, když je nalezena vnější hodnota, a UNKNOWN, když není nalezena kvůli srovnání s NULL. Potom negace predikátu s operátorem NOT vždy vrátí hodnotu FALSE nebo UNKNOWN, v tomto pořadí – nikdy NEPRAVDU. Podrobně se této chybě věnuji v T-SQL chybách, úskalích a osvědčených postupech – dílčích dotazech, včetně navrhovaných řešení, úvah o optimalizaci a osvědčených postupů. Pokud tuto klasickou chybu ještě neznáte, nezapomeňte si přečíst tento článek, protože chyba je poměrně běžná a existují jednoduchá opatření, jak se jí vyhnout.
Zpět k naší potřebě, co takhle pokusit se vrátit objednávky s jiným datem odeslání než 2. ledna 2019 pomocí operátoru jiný než (<>):
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate <> '20190102';
Bohužel, oba operátory rovnosti i nerovnosti dávají NEZNÁMÝ, když je některý z operandů NULL, takže tento dotaz generuje následující výstup jako předchozí dotaz, s výjimkou NULL:
Abychom izolovali problém srovnání s hodnotami NULL, které dávají NEZNÁMÝ pomocí rovnosti, nerovnosti a negace dvou druhů operátorů, všechny následující dotazy vracejí prázdnou sadu výsledků:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE NOT (shippeddate =NULL); SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate <> NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE NOT (shippeddate <> NULL);
Podle SQL byste neměli kontrolovat, zda se něco rovná NULL nebo se liší od NULL, spíše zda je něco NULL nebo není NULL, pomocí speciálních operátorů IS NULL a IS NOT NULL. Tyto operátory používají dvouhodnotovou logiku, která vždy vrací buď PRAVDA, nebo NEPRAVDA. Operátor IS NULL například použijte k vrácení neodeslaných objednávek, např.:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate IS NULL;
Tento dotaz generuje následující výstup:
ID objednávky datum odeslání----------- -----------11008 NULL11019 NULL11039 NULL...(21 ovlivněných řádků)
K vrácení odeslaných objednávek použijte operátor IS NOT NULL, například:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate IS NOT NULL;
Tento dotaz generuje následující výstup:
Pomocí následujícího kódu můžete vrátit objednávky, které byly odeslány v jiný den než 2. ledna 2019, a také neodeslané objednávky:
SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate <> '20190102' OR shippeddate IS NULL;
Tento dotaz generuje následující výstup:
objednací datum odeslání----------- -----------11008 NULL11019 NULL11039 NULL...10249 2017-07-1010252 2017-07-1110-0250 2017 ...11050 2019-05-0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06 (827 dotčených řádků)
V pozdější části seriálu se zabývám standardními funkcemi pro zpracování NULL, které v T-SQL aktuálně chybí, včetně DISTINCT predikátu , které mají potenciál značně zjednodušit práci s NULL.
Porovnání s proměnnými, parametry a sloupci
Předchozí část se zaměřila na predikáty, které porovnávají sloupec s konstantou. Ve skutečnosti však budete většinou porovnávat sloupec s proměnnými/parametry nebo s jinými sloupci. Taková srovnání zahrnují další složitosti.
Z hlediska zpracování NULL se s proměnnými a parametry zachází stejně. Ve svých příkladech použiji proměnné, ale body, které uvádím o jejich manipulaci, jsou stejně důležité pro parametry.
Zvažte následující základní dotaz (nazývám ho Dotaz 1), který filtruje objednávky, které byly odeslány k danému datu:
DECLARE @dt AS DATE ='20190212'; SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =@dt;
V tomto příkladu používám proměnnou a inicializuji ji nějakým vzorovým datem, ale stejně dobře to mohl být parametrizovaný dotaz v uložené proceduře nebo uživatelsky definovaná funkce.
Toto provedení dotazu generuje následující výstup:
Plán pro Dotaz 1 je znázorněn na obrázku 1.
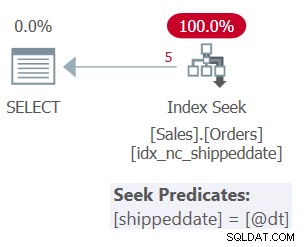 Obrázek 1:Plán pro dotaz 1
Obrázek 1:Plán pro dotaz 1
Tabulka má krycí index pro podporu tohoto dotazu. Index se nazývá idx_nc_shippeddate a je definován pomocí seznamu klíčů (shippeddate, orderid). Predikát filtru dotazu je vyjádřen jako argument vyhledávání (SARG) , což znamená, že umožňuje optimalizátoru zvážit použití operace hledání v podpůrném indexu a přejít přímo k rozsahu kvalifikačních řádků. To, co dělá predikát filtru SARGable, je to, že používá operátor, který představuje po sobě jdoucí rozsah kvalifikujících řádků v indexu, a že na filtrovaný sloupec neaplikuje manipulaci. Plán, který získáte, je optimální plán pro tento dotaz.
Ale co když chcete uživatelům umožnit žádat o neodeslané objednávky? Takové objednávky mají NULL datum odeslání. Zde je pokus předat jako vstupní datum NULL:
DECLARE @dt AS DATE =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =@dt;
Jak již víte, predikát používající operátor rovnosti vytváří NEZNÁMÝ, když je některý z operandů NULL. V důsledku toho tento dotaz vrátí prázdný výsledek:
ID objednávky datum odeslání----------- -----------(0 ovlivněných řádků)
I když T-SQL podporuje operátor IS NULL, nepodporuje explicitní operátor IS
DECLARE @dt AS DATE =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE ISNULL(shippeddate, '99991231') =ISNULL(@dt, '99991231');
Tento dotaz generuje správný výstup:
ID objednávky datum odeslání----------- -----------11008 NULL11019 NULL11039 NULL...11075 NULL11076 NULL11077 NULL (ovlivněno 21 řádků)
Ale plán pro tento dotaz, jak ukazuje obrázek 2, není optimální.
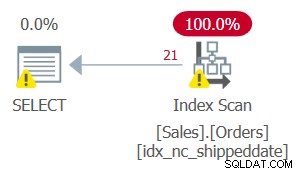 Obrázek 2:Plán pro dotaz 2
Obrázek 2:Plán pro dotaz 2
Protože jste na filtrovaný sloupec použili manipulaci, predikát filtru již není považován za SARG. Index je stále krycí, takže jej lze použít; ale namísto použití hledání v indexu přímo na rozsah kvalifikačních řádků je naskenován celý list indexu. Předpokládejme, že tabulka měla 50 000 000 objednávek, přičemž pouze 1 000 byly neodeslané objednávky. Tento plán by naskenoval všech 50 000 000 řádků, místo aby prováděl hledání, které by šlo přímo na kvalifikačních 1 000 řádků.
Jedna forma predikátu filtru, která má správný význam, po kterém sledujeme, a je považována za argument hledání, je (shippeddate =@dt OR (shippeddate IS NULL AND @dt IS NULL)). Zde je dotaz používající tento predikát SARGable (budeme mu říkat Dotaz 3):
DECLARE @dt AS DATE =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE (shippeddate =@dt OR (shippeddate IS NULL AND @dt IS NULL));
Plán pro tento dotaz je znázorněn na obrázku 3.
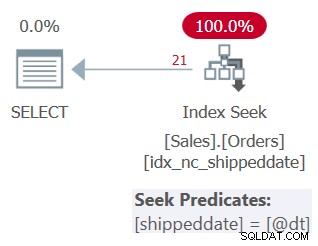 Obrázek 3:Plán pro dotaz 3
Obrázek 3:Plán pro dotaz 3
Jak vidíte, plán používá hledání v podpůrném indexu. Predikát seek říká shippeddate =@dt, ale je vnitřně navržen tak, aby z důvodu srovnání zpracovával hodnoty NULL stejně jako hodnoty bez hodnoty NULL.
Toto řešení je obecně považováno za rozumné. Je standardní, optimální a správný. Jeho hlavní nevýhodou je, že je podrobný. Co kdybyste měli více predikátů filtru založených na sloupcích s možností NULL? Rychle byste skončili se zdlouhavou a těžkopádnou klauzulí WHERE. A je to mnohem horší, když potřebujete napsat predikát filtru zahrnující sloupec s hodnotou NULL, který hledá řádky, kde se sloupec liší od vstupního parametru. Predikát se pak změní na:(shippeddate <> @dt AND ((shippeddate IS NULL AND @dt NOT NULL) OR (shippeddate IS NOT NULL and @dt IS NULL))).
Jasně vidíte potřebu elegantnějšího řešení, které je stručné a optimální. Bohužel se někteří uchýlí k nestandardnímu řešení, kde vypnete možnost relace ANSI_NULLS. Tato možnost způsobí, že SQL Server použije nestandardní zpracování rovnosti (=) a operátory odlišné od (<>) s logikou se dvěma hodnotami namísto logiky se třemi hodnotami, přičemž pro účely porovnání zachází s hodnotami NULL stejně jako s hodnotami bez hodnoty NULL. To je alespoň případ, pokud je jedním z operandů parametr/proměnná nebo literál.
Chcete-li v relaci vypnout možnost ANSI_NULLS, spusťte následující kód:
VYPNĚTE ANSI_NULLS;
Spusťte následující dotaz pomocí jednoduchého predikátu založeného na rovnosti:
DECLARE @dt AS DATE =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE shippeddate =@dt;
Tento dotaz vrátí 21 neodeslaných objednávek. Získáte stejný plán, který je znázorněn dříve na obrázku 3, zobrazující hledání v indexu.
Spusťte následující kód a přepněte zpět na standardní chování, kde je ANSI_NULLS zapnuto:
NASTAVIT ANSI_NULLS;
Důrazně se nedoporučuje spoléhat na takové nestandardní chování. V dokumentaci je také uvedeno, že podpora pro tuto možnost bude v některé budoucí verzi serveru SQL Server odebrána. Navíc si mnozí neuvědomují, že tato možnost je použitelná pouze v případě, že alespoň jeden z operandů je parametr/proměnná nebo konstanta, přestože dokumentace je o tom zcela jasná. Neplatí to při porovnávání dvou sloupců, například ve spojení.
Jak tedy zacházet se spojeními obsahujícími sloupce spojení s možností NULL, pokud chcete dosáhnout shody, když jsou dvě strany NULL? Jako příklad použijte následující kód k vytvoření a naplnění tabulek T1 a T2:
PUSTÍ TABULU, POKUD EXISTUJE dbo.T1, dbo.T2;PŘEJĎTE VYTVOŘIT TABULKU dbo.T1(k1 INT NULL, k2 INT NULL, k3 INT NULL, hodnota1 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T1 UNIQUE CLUSTERED(k2 , k3)); CREATE TABLE dbo.T2(k1 INT NULL, k2 INT NULL, k3 INT NULL, hodnota2 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T2 UNIQUE CLUSTERED(k1, k2, k3)); INSERT INTO dbo.T1(k1, k2, k3, hodnota1) VALUES (1, NULL, 0, 'A'), (NULL, NULL, 1, 'B'), (0, NULL, NULL, 'C') ,(1, 1, 0, 'D'), (0, NULL, 1, 'F'); INSERT INTO dbo.T2(k1, k2, k3, hodnota2) VALUES (0, 0, 0, 'G'), (1, 1, 1, 'H'), (0, NULL, NULL, 'I') ,(NULL, NULL, NULL, 'J'),(0, NULL, 1, 'K');
Kód vytváří krycí indexy na obou tabulkách pro podporu spojení na základě spojovacích klíčů (k1, k2, k3) na obou stranách.
Pomocí následujícího kódu aktualizujte statistiku mohutnosti a nafoukněte čísla tak, aby si optimalizátor myslel, že máte co do činění s většími tabulkami:
AKTUALIZOVAT STATISTIKY dbo.T1(UNQ_T1) S POČTEM ŘÁDKŮ =1000000; AKTUALIZOVAT STATISTIKY dbo.T2(UNQ_T2) S POČTEM ŘÁDKŮ =1000000;
Při pokusu o spojení dvou tabulek pomocí jednoduchých predikátů založených na rovnosti použijte následující kód:
VYBERTE T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 VNITŘNÍ SPOJENÍ dbo.T2 NA T1.k1 =T2.k1 A T1.k2 =T2.k2 A T1. k3 =T2.k3;
Stejně jako u dřívějších příkladů filtrování, i zde srovnání mezi hodnotami NULL pomocí operátoru rovnosti vede k NEZNÁMÉMU, což vede k neshodám. Tento dotaz generuje prázdný výstup:
k1 K2 K3 val1 val2----------- ----------- ----------- --------- - ----------(0 ovlivněných řádků)
Použití ISNULL nebo COALESCE jako v předchozím příkladu filtrování, nahrazení NULL hodnotou, která se normálně nemůže objevit v datech na obou stranách, vede ke správnému dotazu (tento dotaz budu označovat jako Dotaz 4):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 INNER JOIN dbo.T2 ON ISNULL(T1.k1, -2147483648) =ISNULL(T2.k1, -2147483648 ) AND ISNULL(T1.k2, -2147483648) =ISNULL(T2.k2, -2147483648) AND ISNULL(T1.k3, -2147483648) =ISNULL(T2.k3, -2147483648);
Tento dotaz generuje následující výstup:
k1 K2 K3 val1 val2----------- ----------- ----------- --------- - ----------0 NULL NULL C I0 NULL 1 F K
Nicméně, stejně jako manipulace s filtrovaným sloupcem narušuje SARGability predikátu filtru, manipulace se sloupcem spojení brání možnosti spoléhat se na pořadí indexu. To lze vidět v plánu pro tento dotaz, jak je znázorněno na obrázku 4.
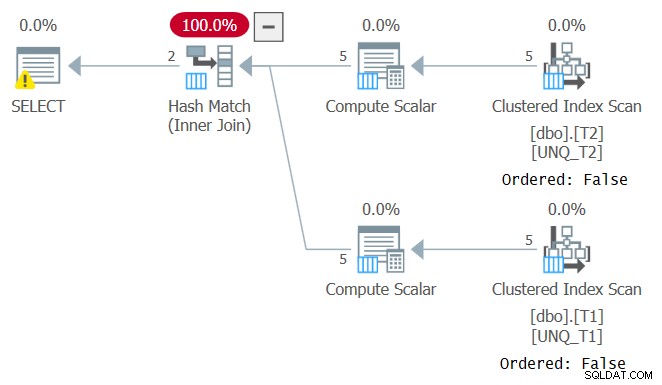 Obrázek 4:Plán pro dotaz 4
Obrázek 4:Plán pro dotaz 4
Optimální plán pro tento dotaz je takový, který použije uspořádané skenování dvou krycích indexů následované algoritmem Merge Join bez explicitního řazení. Optimalizátor zvolil jiný plán, protože se nemohl spolehnout na pořadí indexů. Pokud se pokusíte vynutit algoritmus Merge Join pomocí INNER MERGE JOIN, plán bude stále spoléhat na neuspořádané skenování indexů, po kterém bude následovat explicitní řazení. Zkuste to!
Samozřejmě můžete pro úkoly filtrování použít dlouhé predikáty podobné predikátům SARGable uvedeným výše:
VYBERTE T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 VNITŘNÍ PŘIPOJENÍ dbo.T2 ZAPNUTO (T1.k1 =T2.k1 NEBO (T1.k1 JE NULL A T2. K1 JE NULL)) AND (T1.k2 =T2.k2 NEBO (T1.k2 JE NULOVÉ A T2.K2 JE NULOVÉ)) AND (T1.k3 =T2.k3 OR (T1.k3 JE NULOVÉ A T2.K3 JE NULL));
Tento dotaz poskytuje požadovaný výsledek a umožňuje optimalizátoru spoléhat se na pořadí indexů. Doufáme však, že najdeme řešení, které bude optimální a zároveň stručné.
Existuje málo známá elegantní a stručná technika, kterou můžete použít ve spojeních i filtrech, a to jak pro účely identifikace shod, tak pro identifikaci neshod. Tato technika byla objevena a zdokumentována již před lety, například ve vynikajícím zápisu Paula Whitea Undocumented Query Plans:Equality Comparisons z roku 2011. Ale z nějakého důvodu se zdá, že si to stále mnoho lidí neuvědomuje a bohužel nakonec používají neoptimální, zdlouhavé a nestandardní řešení. Určitě si zaslouží více expozice a lásky.
Tato technika se opírá o skutečnost, že množinové operátory jako INTERSECT a EXCEPT používají při porovnávání hodnot přístup založený na odlišnosti, nikoli přístup založený na rovnosti nebo nerovnosti.
Vezměme si jako příklad naši úlohu spojení. Pokud bychom nepotřebovali vracet jiné sloupce než klíče spojení, použili bychom jednoduchý dotaz (budu ho označovat jako Dotaz 5) s operátorem INTERSECT, například takto:
SELECT k1, k2, k3 FROM dbo.T1INTERSECTSELECT k1, k2, k3 FROM dbo.T2;
Tento dotaz generuje následující výstup:
k1 k2 k3----------- ----------- -----------0 NULL NULL0 NULL 1
Plán pro tento dotaz je znázorněn na obrázku 5, což potvrzuje, že optimalizátor se mohl spolehnout na pořadí indexů a použít algoritmus Merge Join.
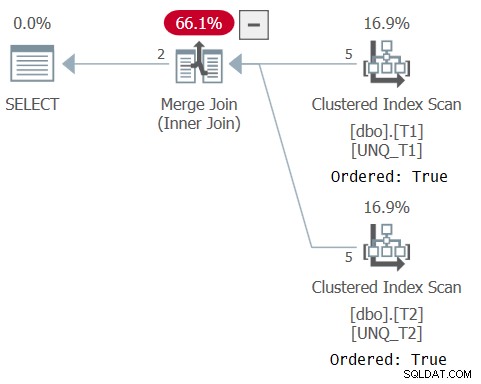 Obrázek 5:Plán pro dotaz 5
Obrázek 5:Plán pro dotaz 5
Jak poznamenává Paul ve svém článku, plán XML pro operátora množiny používá implicitní operátor porovnání IS (CompareOp="IS" ) na rozdíl od operátoru porovnání EQ používaného v normálním spojení (CompareOp="EQ" ). Problém s řešením, které se spoléhá pouze na operátor množiny, je ten, že vás omezuje na vrácení pouze sloupců, které porovnáváte. To, co skutečně potřebujeme, je jakýsi hybrid mezi operátorem spojení a množiny, který vám umožní porovnávat podmnožinu prvků a zároveň vracet další, jako to dělá spojení, a používat porovnání založené na odlišnosti (IS), jako to dělá operátor množiny. Toho lze dosáhnout použitím spojení jako vnější konstrukce a predikátu EXISTS v klauzuli ON spojení na základě dotazu s operátorem INTERSECT porovnávajícím klíče spojení ze dvou stran, jako je to (budu odkazovat na toto řešení jako Query 6):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2. k1, T2.k2, T2.k3);
Operátor INTERSECT pracuje se dvěma dotazy, z nichž každý tvoří sadu jednoho řádku na základě spojovacích klíčů z obou stran. Když jsou dva řádky stejné, dotaz INTERSECT vrátí jeden řádek; predikát EXISTS vrátí hodnotu TRUE, výsledkem je shoda. Když dva řádky nejsou stejné, dotaz INTERSECT vrátí prázdnou sadu; predikát EXISTS vrátí hodnotu FALSE, což vede k neshodě.
Toto řešení generuje požadovaný výstup:
k1 K2 K3 val1 val2----------- ----------- ----------- --------- - ----------0 NULL NULL C I0 NULL 1 F K
Plán pro tento dotaz je znázorněn na obrázku 6, což potvrzuje, že optimalizátor se mohl spolehnout na pořadí indexů.
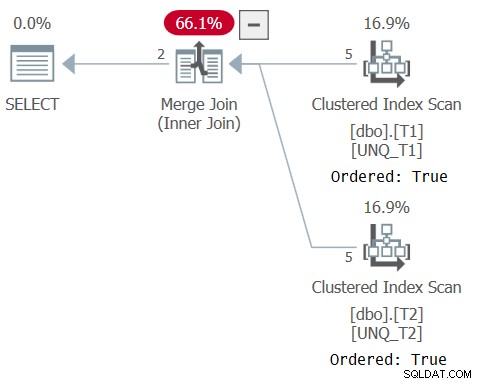 Obrázek 6:Plán pro dotaz 6
Obrázek 6:Plán pro dotaz 6
Podobnou konstrukci můžete použít jako predikát filtru zahrnující sloupec a parametr/proměnnou k hledání shod na základě odlišnosti, například takto:
DECLARE @dt AS DATE =NULL; SELECT orderid, shippeddateFROM Sales.OrdersWHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Plán je stejný jako na obrázku 3.
Můžete také negovat predikát a hledat neshody, například takto:
DECLARE @dt AS DATE ='20190212'; SELECT orderid, shippeddateFROM Sales.OrdersWHERE NOT EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Tento dotaz generuje následující výstup:
objednací datum odeslání----------- -----------11008 NULL11019 NULL11039 NULL...10847 2019-02-1010856 2019-02-1010-871 2019 2019 2019-02-1110874 2019-02-1110870 2019-02-1310884 2019-02-1310840 2019-02-1610887 2019-02-16...(825 dotčených řad)Případně můžete použít kladný predikát, ale nahradit INTERSECT výrazem EXCEPT, například takto:
DECLARE @dt AS DATE ='20190212'; SELECT orderid, shippeddateFROM Sales.OrdersWHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);Všimněte si, že plány v těchto dvou případech se mohou lišit, takže nezapomeňte experimentovat oběma způsoby s velkým množstvím dat.
Závěr
Hodnoty NULL přidávají svůj podíl na složitosti psaní kódu SQL. Vždy se chcete zamyslet nad potenciálem přítomnosti hodnot NULL v datech a ujistěte se, že používáte správné konstrukty dotazů a přidáváte do svých řešení příslušnou logiku, abyste správně zacházeli s hodnotami NULL. Jejich ignorování je jistý způsob, jak skončit s chybami ve vašem kódu. Tento měsíc jsem se zaměřil na to, co jsou hodnoty NULL a jak se s nimi zachází při porovnávání konstant, proměnných, parametrů a sloupců. Příští měsíc budu pokračovat v pokrytí diskusí o nekonzistentnosti zacházení s NULL v různých jazykových prvcích a chybějících standardních funkcích pro zpracování NULL.