
Typický MySQL DBA může být obeznámen s prací a správou databáze OLTP (Online Transaction Processing) jako součást své každodenní rutiny. Možná víte, jak to funguje a jak řídit složité operace. Zatímco výchozí úložný modul, který dodává MySQL, je dost dobrý pro OLAP (Online Analytical Processing), je docela zjednodušující, zejména pro ty, kteří by se chtěli naučit umělou inteligenci nebo kteří se zabývají prognózováním, dolováním dat a analýzou dat.
V tomto blogu budeme diskutovat o MariaDB ColumnStore. Obsah bude přizpůsoben tak, aby byl přínosem pro MySQL DBA, který by mohl méně rozumět ColumnStore a tomu, jak by mohl být použitelný pro aplikace OLAP (Online Analytical Processing).
OLTP vs OLAP
OLTP
Související zdroje Analytics s MariaDB AX – open source sloupcové datové úložiště Úvod do databází časových řad Hybridní OLTP/Analytics Database Workloads v Galera Cluster using asynchronous SlavesTypickou aktivitou MySQL DBA pro zpracování tohoto typu dat je použití OLTP (Online Transaction Processing). OLTP se vyznačuje velkými databázovými transakcemi, které provádějí vkládání, aktualizace nebo mazání. Databáze typu OLTP se specializují na rychlé zpracování dotazů a zachování integrity dat při přístupu ve více prostředích. Jeho účinnost se měří počtem transakcí za sekundu (tps). Je poměrně běžné, že tabulky vztahů rodič-dítě (po implementaci normalizačního formuláře) snižují redundantní data v tabulce.
Záznamy v tabulce jsou běžně zpracovávány a ukládány sekvenčně způsobem orientovaným na řádky a jsou vysoce indexovány pomocí jedinečných klíčů pro optimalizaci získávání dat nebo zápisů. To je také běžné pro MySQL, zejména při práci s velkými vkládáními nebo vysokým počtem souběžných zápisů nebo hromadných vkládání. Většina úložných modulů, které MariaDB podporuje, je použitelná pro aplikace OLTP – InnoDB (výchozí modul úložiště od 10.2), XtraDB, TokuDB, MyRocks nebo MyISAM/Aria.
Aplikace jako CMS, FinTech, Web Apps se často vypořádávají s náročnými zápisy a čteními a často vyžadují vysokou propustnost. Aby tyto aplikace fungovaly, často vyžaduje hluboké odborné znalosti v oblasti vysoké dostupnosti, redundance, odolnosti a obnovy.
OLAP
OLAP řeší stejné problémy jako OLTP, ale používá jiný přístup (zejména při získávání dat). OLAP se zabývá většími datovými sadami a je běžný pro datové sklady, často používané pro aplikace typu business intelligence. Běžně se používá pro řízení výkonnosti podniku, plánování, rozpočtování, prognózování, finanční výkaznictví, analýzy, simulační modely, zjišťování znalostí a výkaznictví datového skladu.
Data uložená v OLAP obvykle nejsou tak důležitá jako data uložená v OLTP. Je to proto, že většinu dat lze simulovat přicházející z OLTP a poté je lze přivádět do vaší databáze OLAP. Tato data se obvykle používají pro hromadné načítání, často potřebné pro obchodní analýzy, které se nakonec převedou do vizuálních grafů. OLAP také provádí vícerozměrnou analýzu obchodních dat a poskytuje výsledky, které lze použít pro komplexní výpočty, analýzu trendů nebo sofistikované modelování dat.
OLAP obvykle ukládá data trvale pomocí sloupcového formátu. V MariaDB ColumnStore jsou však záznamy rozděleny na základě jeho sloupců a jsou uloženy samostatně do souboru. Tímto způsobem je získávání dat velmi efektivní, protože prohledává pouze relevantní sloupec uvedený v dotazu příkazu SELECT.
Přemýšlejte o tom takto, zpracování OLTP zpracovává vaše každodenní a klíčové datové transakce, které provozují vaši obchodní aplikaci, zatímco OLAP vám pomáhá spravovat, předvídat, analyzovat a lépe prodávat váš produkt – stavební kameny obchodní aplikace.
Co je MariaDB ColumnStore?
MariaDB ColumnStore je připojitelný sloupcový úložný modul, který běží na serveru MariaDB. Využívá paralelní distribuovanou datovou architekturu při zachování stejného rozhraní ANSI SQL, které se používá v celém portfoliu serverů MariaDB. Tento úložný engine existuje již nějakou dobu, protože byl původně portován z InfiniDB (nyní zaniklý kód, který je stále dostupný na githubu.) Je navržen pro škálování velkých dat (pro zpracování petabajtů dat), lineární škálovatelnost a skutečné -časová odezva na analytické dotazy. Využívá výhody I/O sloupcového úložiště; komprese, projekce „just-in-time“ a horizontální a vertikální dělení pro zajištění skvělého výkonu při analýze velkých souborů dat.
A konečně, MariaDB ColumnStore je páteří jejich produktu MariaDB AX jako hlavního úložiště používaného touto technologií.
Jak se MariaDB ColumnStore liší od InnoDB?
InnoDB je použitelný pro zpracování OLTP, které vyžaduje, aby vaše aplikace reagovala nejrychlejším možným způsobem. Je to užitečné, pokud se vaše aplikace zabývá touto povahou. Na druhou stranu je MariaDB ColumnStore vhodnou volbou pro správu velkých datových transakcí nebo velkých datových sad, které zahrnují komplexní spojení, agregaci na různých úrovních hierarchie dimenzí, projektování finančního součtu na široký rozsah let nebo použití rovnosti a výběrů rozsahů. . Tyto přístupy využívající ColumnStore nevyžadují, abyste tato pole indexovali, protože může fungovat dostatečně rychleji. InnoDB tento typ výkonu opravdu nezvládne, i když vám nic nebrání v tom, abyste to zkusili, jak je to možné s InnoDB, ale za cenu. To vyžaduje, abyste přidali indexy, což přidá velké množství dat na diskové úložiště. To znamená, že dokončení dotazu může trvat déle a nemusí se vůbec dokončit, pokud je uvězněn v časové smyčce.
Architektura MariaDB ColumnStore
Podívejme se na architekturu MariaDB ColumStore níže:
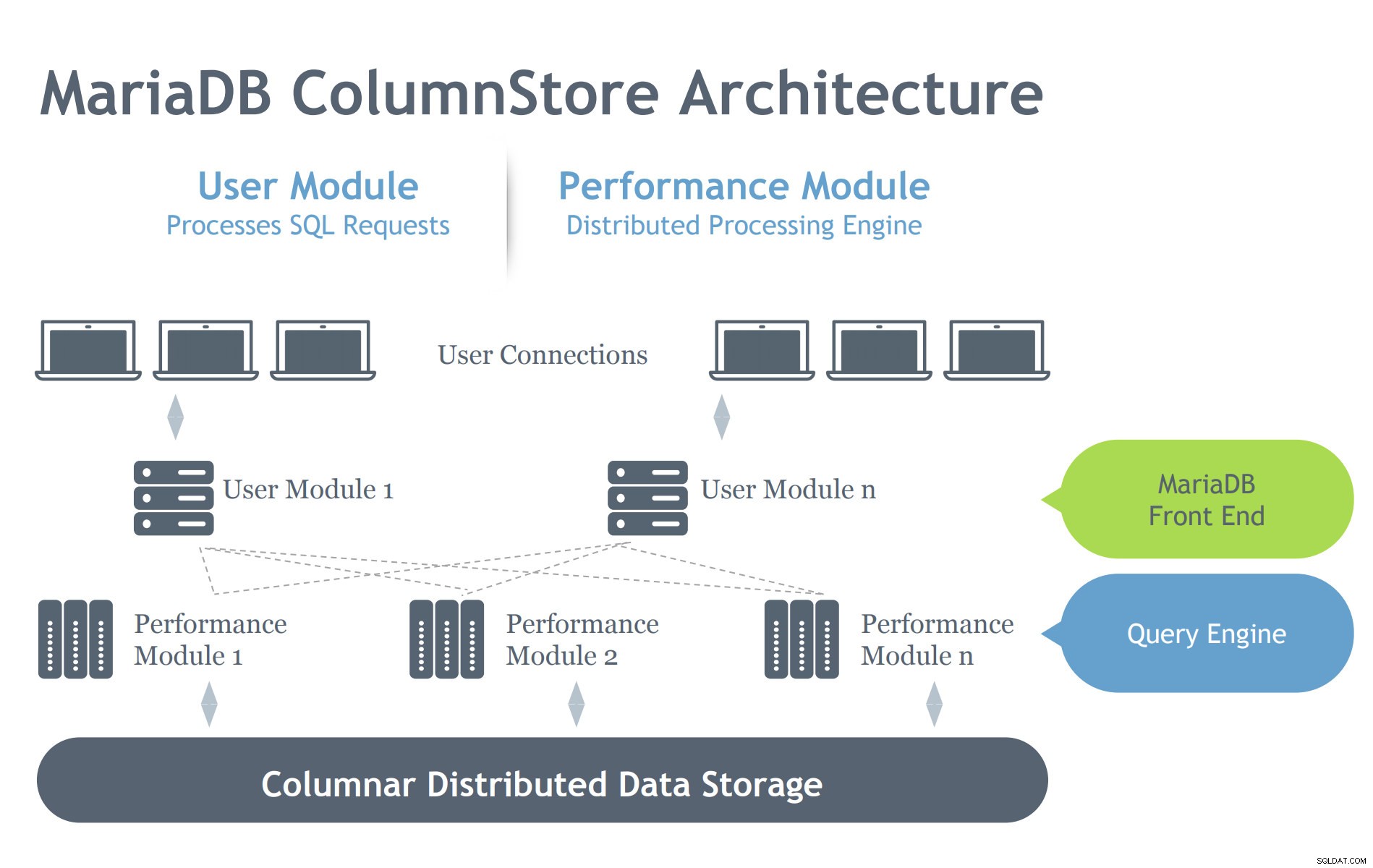 Obrázek s laskavým svolením prezentace MariaDB ColumnStore
Obrázek s laskavým svolením prezentace MariaDB ColumnStore Na rozdíl od architektury InnoDB obsahuje ColumnStore dva moduly, které označují jeho záměrem je efektivně pracovat v prostředí distribuované architektury. InnoDB je určen k škálování na serveru, ale zahrnuje více propojených uzlů v závislosti na nastavení clusteru. ColumnStore má tedy více úrovní komponent, které se starají o procesy požadované serveru MariaDB. Pojďme se podívat na tyto komponenty níže:
- Uživatelský modul (UM):UM je zodpovědný za analýzu požadavků SQL do optimalizované sady kroků primitivních úloh prováděných jedním nebo více servery PM. UM je tedy odpovědné za optimalizaci dotazů a orchestraci provádění dotazů servery PM. Zatímco v nasazení s více servery lze nasadit více instancí UM, za každý jednotlivý dotaz odpovídá jediné UM. Nástroj pro vyrovnávání zatížení databáze, jako je MariaDB MaxScale, lze nasadit, aby vhodně vyvážil externí požadavky vůči jednotlivým serverům UM.
- Performance Module (PM):PM provádí jednotlivé kroky úlohy přijaté z UM vícevláknovým způsobem. ColumnStore umožňuje distribuci práce napříč mnoha výkonnostními moduly. UM se skládá z procesu MariaDB mysqld a procesu ExeMgr.
- Mapy oblastí:ColumnStore uchovává metadata o každém sloupci ve sdíleném distribuovaném objektu známém jako mapa oblastí Server UM odkazuje na mapu oblastí, která pomáhá při generování správných primitivních kroků úlohy. PM server odkazuje na mapu oblastí, aby identifikoval správné bloky disku ke čtení. Každý sloupec se skládá z jednoho nebo více souborů a každý soubor může obsahovat více oblastí. Systém se co nejvíce snaží alokovat souvislé fyzické úložiště, aby zlepšil výkon čtení.
- Úložiště:ColumnStore může k ukládání dat používat buď místní úložiště, nebo sdílené úložiště (např. SAN nebo EBS). Použití sdíleného úložiště umožňuje, aby zpracování dat automaticky přešlo na jiný uzel v případě selhání PM serveru.
Níže je uvedeno, jak MariaDB ColumnStore zpracovává dotaz,
- Klienti zadají dotaz na server MariaDB spuštěný v uživatelském modulu. Server provede operaci tabulky pro všechny tabulky potřebné ke splnění požadavku a získá počáteční plán provádění dotazu.
- Pomocí rozhraní úložiště MariaDB ColumnStore převede objekt tabulky serveru na objekty ColumnStore. Tyto objekty jsou poté odeslány procesům uživatelského modulu.
- Uživatelský modul převede plán provádění MariaDB a optimalizuje dané objekty na plán provádění ColumnStore. Poté určí kroky potřebné ke spuštění dotazu a pořadí, ve kterém je třeba je spustit.
- Uživatelský modul poté nahlédne do mapy rozsahu, aby určil, které moduly výkonu má konzultovat s údaji, která potřebuje, a poté provede eliminaci rozsahu, přičemž ze seznamu odstraní všechny moduly výkonu, které obsahují pouze data mimo rozsah toho, co dotaz vyžaduje.
- Uživatelský modul poté odešle příkazy jednomu nebo více výkonnostním modulům k provedení blokových I/O operací.
- Výkonnostní modul nebo moduly provádějí predikátové filtrování, zpracování spojení, počáteční agregaci dat z místního nebo externího úložiště a poté odešlou data zpět do uživatelského modulu.
- Uživatelský modul provede konečnou agregaci sady výsledků a sestaví sadu výsledků pro dotaz.
- Uživatelský modul / ExeMgr implementuje jakékoli výpočty funkcí okna, stejně jako jakékoli nezbytné třídění v sadě výsledků. Poté vrátí sadu výsledků na server.
- Server MariaDB provádí v sadě výsledků libovolné funkce seznamu, operace ORDER BY a LIMIT.
- Server MariaDB vrátí sadu výsledků klientovi.
Paradigmata provádění dotazů
Pojďme se podívat trochu více na to, jak ColumnStore provádí dotaz a kdy to ovlivní.
ColumnStore se liší od standardních úložišť MySQL/MariaDB, jako je InnoDB, protože ColumnStore získává výkon pouze skenováním nezbytných sloupců, využitím systémem udržovaného dělení a využitím více vláken a serverů ke škálování doby odezvy dotazu. Výkon se zvýší, když zahrnete pouze sloupce, které jsou nezbytné pro vaše data. To znamená, že nenasytná hvězdička (*) ve vašem výběrovém dotazu má významný dopad ve srovnání s SELECT
Stejně jako u InnoDB a dalších úložných enginů má datový typ také význam pro výkon toho, co jste použili. Pokud řekněme, že máte sloupec, který může mít pouze hodnoty 0 až 100, deklarujte to jako tinyint, protože to bude reprezentováno 1 bajtem spíše než 4 bajty pro int. To sníží I/O náklady 4krát. Pro typy řetězců je důležitý práh char(9) a varchar(8) nebo vyšší. Každý soubor úložiště sloupců používá pevný počet bajtů na hodnotu. To umožňuje rychlé poziční vyhledávání dalších sloupců k vytvoření řádku. V současné době je horní limit pro ukládání sloupcových dat 8 bajtů. Takže pro řetězce delší než tento systém udržuje další rozsah „slovníku“, kde jsou hodnoty uloženy. Soubor sloupcového rozsahu pak uloží ukazatel do slovníku. Je tedy dražší číst a zpracovávat sloupec varchar(8) než například sloupec char(8). Takže pokud je to možné, dosáhnete lepšího výkonu, pokud využijete kratší řetězce, zvláště pokud se vyhnete vyhledávání ve slovníku. Všechny datové typy TEXT/BLOB ve verzi 1.1 a novější využívají slovník a provádějí vyhledávání více bloků o velikosti 8 kB, aby tato data v případě potřeby načetli, čím delší jsou data, tím více bloků je načteno a tím větší je potenciální dopad na výkon.
V systému založeném na řádcích přidávání nadbytečných sloupců zvyšuje celkovou cenu dotazu, ale ve sloupcovém systému se náklady objevují pouze tehdy, je-li na sloupec odkazováno. Proto by měly být vytvořeny další sloupce pro podporu různých přístupových cest. Například uložte úvodní část pole do jednoho sloupce, abyste umožnili rychlejší vyhledávání, ale navíc uložte hodnotu dlouhého formuláře jako další sloupec. Skenování na kratším sloupci kódu nebo úvodní části bude rychlejší.
Spojení dotazů jsou optimalizována a jsou připravena pro spojení ve velkém měřítku a vylučují potřebu indexů a režii zpracování vnořených smyček. ColumnStore udržuje statistiky tabulek, aby bylo možné určit optimální pořadí spojení. Podobné přístupy sdílí s InnoDB, jako když je spojení příliš velké pro paměť UM, použije se k dokončení dotazu spojení na disku.
ColumnStore pro agregace distribuuje souhrnné hodnocení co nejvíce. To znamená, že sdílí v rámci UM a PM, aby zpracoval dotazy zejména nebo velmi velký počet hodnot v agregovaných sloupcích. Select count(*) je interně optimalizován pro výběr nejmenšího počtu bajtů úložiště v tabulce. To znamená, že by vybral sloupec CHAR(1) (používá 1 bajt) přes sloupec INT, který zabírá 4 bajty. Implementace stále dodržuje sémantiku ANSI v tom, že select count(*) bude zahrnovat nuly v celkovém počtu, na rozdíl od explicitního select (COL-N), který v počtu null vylučuje.
Pořadí podle a limit jsou v současné době implementovány na samém konci procesem serveru mariadb v tabulce dočasné sady výsledků. To bylo zmíněno v kroku #9 o tom, jak ColumnStore zpracovává dotaz. Technicky jsou tedy výsledky předány serveru MariaDB za účelem třídění dat.
U složitých dotazů, které využívají poddotazy, je to v podstatě stejný přístup, kdy jsou prováděny v sekvenci a jsou spravovány UM, stejně jako funkce okna jsou zpracovávány UM, ale používá vyhrazený rychlejší proces řazení, takže je v podstatě rychlejší.
Dělení vašich dat na oddíly zajišťuje ColumnStore, který používá mapy oblastí, které udržují minimální/maximální hodnoty dat sloupců a poskytují logický rozsah pro rozdělení a odstraňují potřebu indexování. Extent Maps také poskytuje ruční dělení tabulek, materializované pohledy, souhrnné tabulky a další struktury a objekty, které musí řádkové databáze implementovat pro výkon dotazů. Existují určité výhody pro sloupcové hodnoty, když jsou v pořadí nebo polořadě, protože to umožňuje velmi efektivní rozdělení dat. S minimálními a maximálními hodnotami budou po filtrování a vyloučení eliminovány mapy celého rozsahu. Podívejte se na tuto stránku v jejich příručce o odstranění rozsahu. To obecně funguje zvláště dobře pro data časových řad nebo podobné hodnoty, které se časem zvyšují.
Instalace MariaDB ColumnStore
Instalace MariaDB ColumnStore může být jednoduchá a přímočará. MariaDB zde má řadu poznámek, na které se můžete odkázat. Pro tento blog je naším cílovým prostředím instalace CentOS 7. Můžete přejít na tento odkaz https://downloads.mariadb.com/ColumnStore/1.2.4/ a prohlédnout si balíčky založené na prostředí vašeho OS. Podívejte se na podrobné kroky níže, které vám pomohou urychlit:
### Note: The installation details is ideal for root user installation
cd /root/
wget https://downloads.mariadb.com/ColumnStore/1.2.4/centos/x86_64/7/mariadb-columnstore-1.2.4-1-centos7.x86_64.rpm.tar.gz
tar xzf mariadb-columnstore-1.0.7-1-centos7.x86_64.rpm.tar.gz
sudo yum -y install boost expect perl perl-DBI openssl zlib snappy libaio perl-DBD-MySQL net-tools wget jemalloc
sudo rpm -ivh mariadb-columnstore*.rpm
Po dokončení je třeba spustit postConfigure příkaz pro konečnou instalaci a nastavení vašeho MariaDB ColumnStore. V této ukázkové instalaci jsou dva uzly, které mám nastaveny spuštěné na vagrantském počítači:
csnode1:192.168.2.10
csnode2:192.168.2.20
Oba tyto uzly jsou definovány v příslušných /etc/hosts a oba uzly jsou cílené tak, aby měly své uživatelské a výkonnostní moduly kombinované v obou hostitelích. Instalace je zpočátku trochu triviální. Proto sdílíme, jak to můžete nakonfigurovat, abyste měli základ. Podívejte se na podrobnosti níže pro ukázkový instalační proces:
[example@sqldat.com ~]# /usr/local/mariadb/columnstore/bin/postConfigure -d
This is the MariaDB ColumnStore System Configuration and Installation tool.
It will Configure the MariaDB ColumnStore System and will perform a Package
Installation of all of the Servers within the System that is being configured.
IMPORTANT: This tool requires to run on the Performance Module #1
Prompting instructions:
Press 'enter' to accept a value in (), if available or
Enter one of the options within [], if available, or
Enter a new value
===== Setup System Server Type Configuration =====
There are 2 options when configuring the System Server Type: single and multi
'single' - Single-Server install is used when there will only be 1 server configured
on the system. It can also be used for production systems, if the plan is
to stay single-server.
'multi' - Multi-Server install is used when you want to configure multiple servers now or
in the future. With Multi-Server install, you can still configure just 1 server
now and add on addition servers/modules in the future.
Select the type of System Server install [1=single, 2=multi] (2) >
===== Setup System Module Type Configuration =====
There are 2 options when configuring the System Module Type: separate and combined
'separate' - User and Performance functionality on separate servers.
'combined' - User and Performance functionality on the same server
Select the type of System Module Install [1=separate, 2=combined] (1) > 2
Combined Server Installation will be performed.
The Server will be configured as a Performance Module.
All MariaDB ColumnStore Processes will run on the Performance Modules.
NOTE: The MariaDB ColumnStore Schema Sync feature will replicate all of the
schemas and InnoDB tables across the User Module nodes. This feature can be enabled
or disabled, for example, if you wish to configure your own replication post installation.
MariaDB ColumnStore Schema Sync feature, do you want to enable? [y,n] (y) >
NOTE: MariaDB ColumnStore Replication Feature is enabled
Enter System Name (columnstore-1) >
===== Setup Storage Configuration =====
----- Setup Performance Module DBRoot Data Storage Mount Configuration -----
There are 2 options when configuring the storage: internal or external
'internal' - This is specified when a local disk is used for the DBRoot storage.
High Availability Server Failover is not Supported in this mode
'external' - This is specified when the DBRoot directories are mounted.
High Availability Server Failover is Supported in this mode.
Select the type of Data Storage [1=internal, 2=external] (1) >
===== Setup Memory Configuration =====
NOTE: Setting 'NumBlocksPct' to 50%
Setting 'TotalUmMemory' to 25%
===== Setup the Module Configuration =====
----- Performance Module Configuration -----
Enter number of Performance Modules [1,1024] (1) > 2
*** Parent OAM Module Performance Module #1 Configuration ***
Enter Nic Interface #1 Host Name (csnode1) >
Enter Nic Interface #1 IP Address or hostname of csnode1 (unassigned) > 192.168.2.10
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm1' (1) >
*** Performance Module #2 Configuration ***
Enter Nic Interface #1 Host Name (unassigned) > csnode2
Enter Nic Interface #1 IP Address or hostname of csnode2 (192.168.2.20) >
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () > 2
===== Running the MariaDB ColumnStore MariaDB Server setup scripts =====
post-mysqld-install Successfully Completed
post-mysql-install Successfully Completed
Next step is to enter the password to access the other Servers.
This is either user password or you can default to using a ssh key
If using a user password, the password needs to be the same on all Servers.
Enter password, hit 'enter' to default to using a ssh key, or 'exit' >
===== System Installation =====
System Configuration is complete.
Performing System Installation.
Performing a MariaDB ColumnStore System install using RPM packages
located in the /root directory.
----- Performing Install on 'pm2 / csnode2' -----
Install log file is located here: /tmp/columnstore_tmp_files/pm2_rpm_install.log
MariaDB ColumnStore Package being installed, please wait ... DONE
===== Checking MariaDB ColumnStore System Logging Functionality =====
The MariaDB ColumnStore system logging is setup and working on local server
===== MariaDB ColumnStore System Startup =====
System Configuration is complete.
Performing System Installation.
----- Starting MariaDB ColumnStore on local server -----
MariaDB ColumnStore successfully started
MariaDB ColumnStore Database Platform Starting, please wait .......... DONE
System Catalog Successfully Created
Run MariaDB ColumnStore Replication Setup.. DONE
MariaDB ColumnStore Install Successfully Completed, System is Active
Enter the following command to define MariaDB ColumnStore Alias Commands
. /etc/profile.d/columnstoreAlias.sh
Enter 'mcsmysql' to access the MariaDB ColumnStore SQL console
Enter 'mcsadmin' to access the MariaDB ColumnStore Admin console
NOTE: The MariaDB ColumnStore Alias Commands are in /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]# . /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]#Jakmile je instalace a nastavení dokončeno, MariaDB pro to vytvoří nastavení master/slave, takže cokoli načteme z csnode1, bude replikováno do csnode2.
Ukládání velkých dat
Po instalaci možná nebudete mít žádná ukázková data k vyzkoušení. IMDB sdílela ukázková data, která si můžete stáhnout na jejich stránkách https://www.imdb.com/interfaces/. Pro tento blog jsem vytvořil skript, který udělá vše za vás. Podívejte se na to zde https://github.com/paulnamuag/columnstore-imdb-data-load. Stačí, aby byl spustitelný a poté spusťte skript. Udělá vše za vás stažením souborů, vytvořením schématu a následným načtením dat do databáze. Je to jednoduché.
Spouštění vzorových dotazů
Nyní zkusme spustit nějaké ukázkové dotazy.
MariaDB [imdb]> select count(1), 'title_akas' table_name from title_akas union all select count(1), 'name_basics' as table_name from name_basics union all select count(1), 'title_crew' as table_name from title_crew union all select count(1), 'title_episode' as table_name from title_episode union all select count(1), 'title_ratings' as table_name from title_ratings order by 1 asc;
+----------+---------------+
| count(1) | table_name |
+----------+---------------+
| 945057 | title_ratings |
| 3797618 | title_akas |
| 4136880 | title_episode |
| 5953930 | title_crew |
| 9403540 | name_basics |
+----------+---------------+
5 rows in set (0.162 sec)MariaDB [imdb]> select count(*), 'title_akas' table_name from title_akas union all select count(*), 'name_basics' as table_name from name_basics union all select count(*), 'title_crew' as table_name from title_crew union all select count(*), 'title_episode' as table_name from title_episode union all select count(*), 'title_ratings' as table_name from title_ratings order by 2;
+----------+---------------+
| count(*) | table_name |
+----------+---------------+
| 9405192 | name_basics |
| 3797618 | title_akas |
| 5953930 | title_crew |
| 4136880 | title_episode |
| 945057 | title_ratings |
+----------+---------------+
5 rows in set (0.371 sec)V zásadě je to rychlejší a rychlé. Existují dotazy, které nemůžete zpracovat stejně jako ty, které spouštíte s jinými moduly úložiště, jako je InnoDB. Zkoušel jsem si například pohrát a udělat nějaké hloupé dotazy a zjistit, jak to reaguje a výsledkem je:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select a.titleId from title_akas) limit 25;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'title_akas' are not joined.Proto jsem našel MCOL-1620 a MCOL-131 a ukazuje to na nastavení proměnné infinidb_vtable_mode. Viz níže:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'b, sub-query' are not joined.Ale nastavení infinidb_vtable_mode=0 , což znamená, že zachází s dotazem jako s obecným a vysoce kompatibilním režimem zpracování řádek po řádku. Některé komponenty klauzule WHERE mohou být zpracovány ColumnStore, ale spojení jsou zpracována výhradně mysqld pomocí mechanismu spojení vnořené smyčky. Viz níže:
MariaDB [imdb]> set infinidb_vtable_mode=0;
Query OK, 0 rows affected (0.000 sec)MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
+-----------+---------------+--------+-----------+-------------+---------------+
| titleId | title | region | id | primaryName | profession |
+-----------+---------------+--------+-----------+-------------+---------------+
| tt0082880 | Vaticano Show | ES | nm0594213 | Velda Mitzi | miscellaneous |
| tt0082880 | Il pap'occhio | IT | nm0594213 | Velda Mitzi | miscellaneous |
+-----------+---------------+--------+-----------+-------------+---------------+
2 rows in set (13.789 sec)Chvíli to trvalo, protože to vysvětluje, že to celé zpracoval mysqld. Přesto je optimalizace a psaní dobrých dotazů stále nejlepším přístupem a nedelegovat vše na ColumnStore.
Navíc vám pomůže analyzovat vaše dotazy spuštěním příkazů jako SELECT calSetTrace(1); nebo SELECT calGetStats(); . Tuto sadu příkazů můžete použít například k optimalizaci nízkých a špatných dotazů nebo zobrazení plánu dotazů. Více podrobností o analýze dotazů naleznete zde.
Správa ColumnStore
Po úplném nastavení MariaDB ColumnStore se dodává se svým nástrojem s názvem mcsadmin, který můžete použít k provádění některých administrativních úkolů. Tento nástroj můžete také použít k přidání dalšího modulu, přiřazení nebo přesunutí DBroots z PM do PM atd. Podívejte se na jejich příručku o tomto nástroji.
V zásadě můžete provést následující, například zkontrolovat systémové informace:
mcsadmin> getSystemi
getsysteminfo Mon Jun 24 12:55:25 2019
System columnstore-1
System and Module statuses
Component Status Last Status Change
------------ -------------------------- ------------------------
System ACTIVE Fri Jun 21 21:40:56 2019
Module pm1 ACTIVE Fri Jun 21 21:40:54 2019
Module pm2 ACTIVE Fri Jun 21 21:40:50 2019
Active Parent OAM Performance Module is 'pm1'
Primary Front-End MariaDB ColumnStore Module is 'pm1'
MariaDB ColumnStore Replication Feature is enabled
MariaDB ColumnStore set for Distributed Install
MariaDB ColumnStore Process statuses
Process Module Status Last Status Change Process ID
------------------ ------ --------------- ------------------------ ----------
ProcessMonitor pm1 ACTIVE Thu Jun 20 17:36:27 2019 6026
ProcessManager pm1 ACTIVE Thu Jun 20 17:36:33 2019 6165
DBRMControllerNode pm1 ACTIVE Fri Jun 21 21:40:31 2019 19890
ServerMonitor pm1 ACTIVE Fri Jun 21 21:40:33 2019 19955
DBRMWorkerNode pm1 ACTIVE Fri Jun 21 21:40:33 2019 20003
PrimProc pm1 ACTIVE Fri Jun 21 21:40:37 2019 20137
ExeMgr pm1 ACTIVE Fri Jun 21 21:40:42 2019 20541
WriteEngineServer pm1 ACTIVE Fri Jun 21 21:40:47 2019 20660
DDLProc pm1 ACTIVE Fri Jun 21 21:40:51 2019 20810
DMLProc pm1 ACTIVE Fri Jun 21 21:40:55 2019 20956
mysqld pm1 ACTIVE Fri Jun 21 21:40:41 2019 19778
ProcessMonitor pm2 ACTIVE Thu Jun 20 17:37:16 2019 9728
ProcessManager pm2 HOT_STANDBY Fri Jun 21 21:40:26 2019 25211
DBRMControllerNode pm2 COLD_STANDBY Fri Jun 21 21:40:32 2019
ServerMonitor pm2 ACTIVE Fri Jun 21 21:40:35 2019 25560
DBRMWorkerNode pm2 ACTIVE Fri Jun 21 21:40:36 2019 25593
PrimProc pm2 ACTIVE Fri Jun 21 21:40:40 2019 25642
ExeMgr pm2 ACTIVE Fri Jun 21 21:40:44 2019 25715
WriteEngineServer pm2 ACTIVE Fri Jun 21 21:40:48 2019 25768
DDLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
DMLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
mysqld pm2 ACTIVE Fri Jun 21 21:40:32 2019 25467
Active Alarm Counts: Critical = 1, Major = 0, Minor = 0, Warning = 0, Info = 0Závěr
MariaDB ColumnStore je velmi výkonný úložiště pro vaše OLAP a zpracování velkých dat. Jedná se o zcela otevřený zdroj, jehož použití je velmi výhodné než používání proprietárních a drahých databází OLAP dostupných na trhu. Přesto existují další alternativy, které můžete vyzkoušet, jako je ClickHouse, Apache HBase nebo cstore_fdw od Citus Data. Ani jeden z nich však nepoužívá MySQL/MariaDB, takže to nemusí být vaše schůdná volba, pokud se rozhodnete držet se variant MySQL/MariaDB.