V této 3. části Benchmarking Managed PostgreSQL Cloud Solutions , využil jsem bezplatnou nabídku GCP společnosti Google. Byla to cenná zkušenost a jako správce systému trávící většinu času u konzole jsem si nemohl nechat ujít příležitost vyzkoušet cloud shell, jednu z funkcí konzole, která odlišuje Google od poskytovatele cloudu, kterého znám lépe. , Amazon Web Services.
Abych to rychle zrekapituloval, v části 1 jsem se podíval na dostupné nástroje pro srovnávání a vysvětlil jsem, proč jsem si pro Auroru vybral AWS Benchmark Procedure. Také jsem testoval Amazon Aurora pro PostgreSQL verze 10.6. V části 2 jsem recenzoval AWS RDS pro PostgreSQL verze 11.1.
Během tohoto kola budou testy založené na AWS Benchmark Procedure pro Aurora spuštěny proti Google Cloud SQL pro PostgreSQL 9.6, protože verze 11.1 je stále v beta verzi.
Cloudové instance
Předpoklady
Jak bylo zmíněno v předchozích dvou článcích, rozhodl jsem se ponechat nastavení PostgreSQL na jejich výchozích cloudových GUC, pokud nebrání spuštění testů (viz dále níže). Připomeňme si z předchozích článků, že se předpokládalo, že poskytovatel cloudu by měl mít instanci databáze nakonfigurovanou tak, aby poskytovala přiměřený výkon.
Oprava časování AWS pgbench pro PostgreSQL 9.6.5 byla čistě aplikována na Google Cloud verzi PostgreSQL 9.6.10.
Pomocí informací, které Google zveřejnil na svém blogu Google Cloud for AWS Professionals, jsem porovnal specifikace pro klienta a cílové instance s ohledem na komponenty Compute, Storage a Networking. Například ekvivalentu Google Cloud pro AWS Enhanced Networking je dosaženo dimenzováním výpočetního uzlu na základě vzorce:
max( [vCPU x 2Gbps/vCPU], 16Gbps) Pokud jde o nastavení instance cílové databáze, podobně jako u AWS, Google Cloud neumožňuje žádné repliky, nicméně úložiště je v klidu šifrováno a není možné jej zakázat.
A konečně, pro dosažení nejlepšího výkonu sítě musí být klient a cílové instance umístěny ve stejné zóně dostupnosti.
Klient
Specifikace instance klienta, které odpovídají nejbližší instanci AWS, jsou:
- vCPU:32 (16 jader x 2 vlákna/jádro)
- RAM:208 GiB (maximum pro instanci 32 vCPU)
- Úložiště:Trvalý disk Compute Engine
- Síť:16 Gb/s (max. [32 vCPU x 2 Gb/s/vCPU] a 16 Gb/s)
Podrobnosti o instanci po inicializaci:
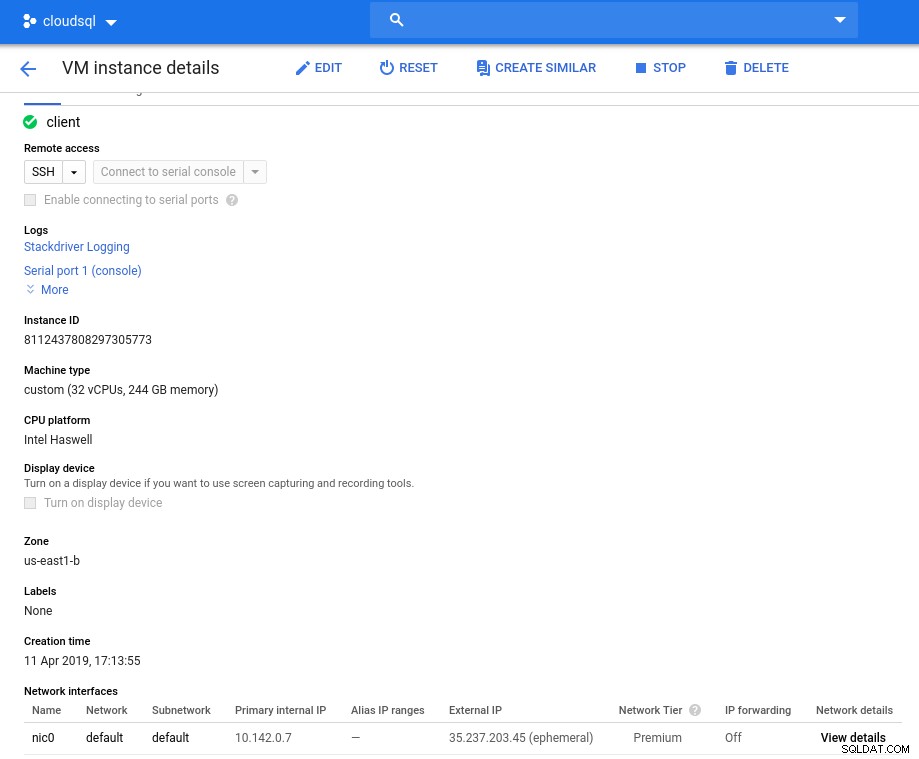 Instance klienta:Compute and Network
Instance klienta:Compute and Network Poznámka:Instance jsou ve výchozím nastavení omezeny na 24 vCPU. Technická podpora Google musí schválit zvýšení kvóty na 32 vCPU na instanci.

I když jsou takové požadavky obvykle vyřízeny do 2 pracovních dnů, musím dát službám podpory Google palec nahoru za dokončení mého požadavku za pouhé 2 hodiny.
Pro zvědavé je vzorec rychlosti sítě založen na dokumentaci výpočetního stroje, na kterou odkazuje tento blog GCP.
DB cluster
Níže jsou specifikace instance databáze:
- vCPU:8
- RAM:52 GiB (maximum)
- Úložiště:144 MB/s, 9 000 IOPS
- Síť:2 000 MB/s
Všimněte si, že maximální dostupná paměť pro 8 instanci vCPU je 52 GiB. Více paměti lze přidělit výběrem větší instance (více vCPU):
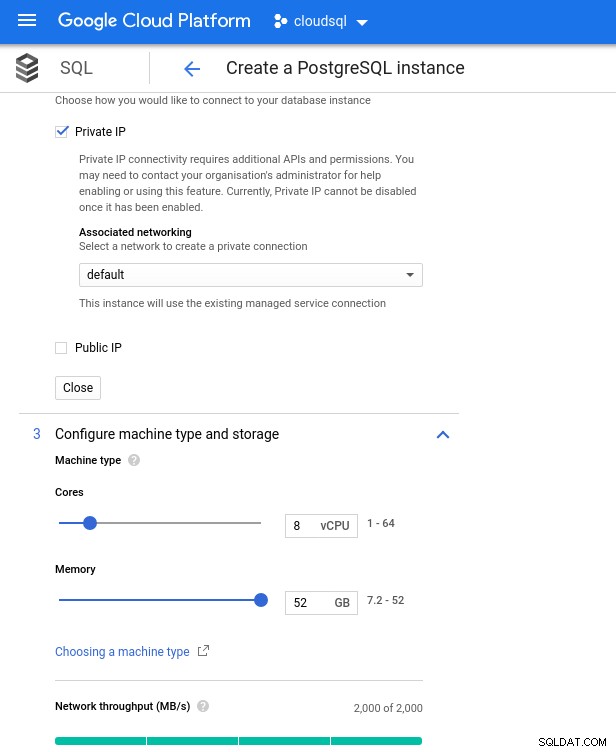 Dimenzování CPU a paměti databáze
Dimenzování CPU a paměti databáze Zatímco Google SQL může automaticky rozšířit základní úložiště, což je mimochodem opravdu skvělá funkce, rozhodl jsem se tuto možnost deaktivovat, aby byla v souladu se sadou funkcí AWS a vyhnuli se potenciálnímu dopadu na I/O během operace změny velikosti. („potenciální“, protože by to nemělo mít vůbec žádný negativní dopad, nicméně podle mých zkušeností změna velikosti jakéhokoli typu základního úložiště zvyšuje I/O, i když na několik sekund).
Připomeňme, že instance databáze AWS byla zálohována optimalizovaným úložištěm EBS, které poskytovalo maximum:
- Šířka pásma 1 700 Mb/s
- Propustnost 212,5 MB/s
- 12 000 IOPS
S Google Cloud dosáhneme podobné konfigurace úpravou počtu vCPU (viz výše) a kapacity úložiště:
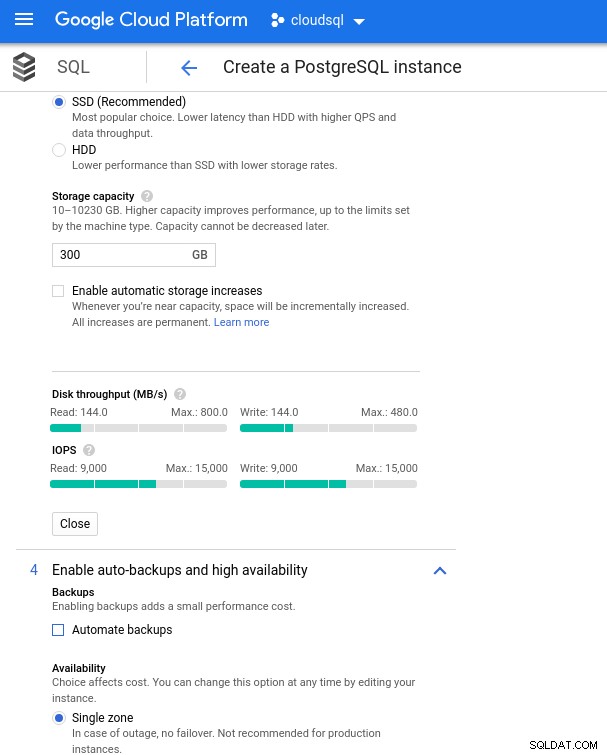 Nastavení úložiště databáze a zálohování
Nastavení úložiště databáze a zálohování Spuštění srovnávacích testů
Nastavení
Dále nainstalujte nástroje pro srovnávání, pgbench a sysbench podle pokynů v příručce Amazon přizpůsobené PostgreSQL verze 9.6.10.
Inicializujte proměnné prostředí PostgreSQL v .bashrc a nastavte cesty k PostgreSQL binárním souborům a knihovnám:
export PGHOST=10.101.208.7export PGUSER=postgresexport PGPASSWORD=postgresexport PGDATABASE=postgresexport PGPORT=5432export PATH=$PATH:/usr/local/pgsql/binexport LD_LIBRALDY_BRALITHgs/usq$lPALDlo_BRALITHgs/us lib Kontrolní seznam před výstupem:
[example@sqldat.com ~]# psql --versionpsql (PostgreSQL) 9.6.10[example@sqldat.com ~]# pgbench --versionpgbench (PostgreSQL) 9.6.10[example@sqldat.com ~]# sysbench --versionsysbench 0.5postgres=> vybrat verzi(); verze------------------------------------------------- -------------------------------------------------- ------ PostgreSQL 9.6.10 na x86_64-pc-linux-gnu, zkompilovaný gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit (1 řádek) A jsme připraveni ke vzletu:
pgbench
Inicializujte databázi pgbench.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000 …a o několik minut později:
POZNÁMKA:tabulka "pgbench_history" neexistuje, přeskakováníNOTICE:tabulka "pgbench_tellers" neexistuje, přeskakováníNOTICE:tabulka "pgbench_accounts" neexistuje, přeskakováníNOTICE:tabulka "pgbench_branches" neexistuje, přeskakování vytváření tabulek.. 0,100 000 z 1000000000 n-tic (0 %) hotovo (uplynulo 0,09 s, zbývajících 872,42 s)200 000 z 1000000000 n-tic (0 %) hotovo (uplynulo 0,19 s, zbývá 0,000 0,000 s) 00000 s 000 , zbývajících 1105,08 s)400000 z 1000000000 n-tic (0%) hotovo (uplynulo 0,53 s, zbývajících 1317,56 s)500000 z 1000000000 n-tic (0%) hotovo (uplynulo 0,653 s,007 00...07 zbývá 0,07 s %) hotovo (uplynulo 943,93 s, zbývajících 943,93 s)500100000 z 1000000000 n-tic (50 %) hotovo (uplynulo 944,08 s, zbývajících 943,71 s)500200000 zbývá 03%) z 100000000 z 10000000000000020200000000000000000000000000 z 100000000000 1000000000 ntic (50 %) hotovo (uplynulo 944,33 s, zbývajících 943,20 s) 500400000 z 1000000000 ntic (50 %) hotovo (el apsováno 944,47 s, zbývajících 942,96 s)500500000 z 1000000000 n-tic (50 %) hotovo (uplynulo 944,59 s, zbývajících 942,70 s)500600000 z 0.0 % z 0.0 % z 1000000000 zbylých 0.000000000000000000000000 s tuple n-tic (99 %) hotovo (uplynulo 1878,28 s, zbývajících 0,75 s)999700000 z 1000000000 n-tic (99 %) hotovo (uplynulo 1878,41 s, zbývajících 0,56 s.)999800000 z 10050000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000 )999900000 z 1000000000 n-tic (99 %) hotovo (uplynulo 1878,70 s, zbývajících 0,19 s)1000000000 z 1000000000 z 1000000000 n-tic (100 %) hotovo (uplynulý čas 1878,83 n-tic, zbývající čas svacto...83 sum 5978,44 s (vložení 1878,90 s, potvrzení 0,04 s, vakuum 2484,96 s, index 1614,54 s) hotovo. Jak jsme již zvyklí, velikost databáze musí být 160 GB. Pojďme si to ověřit:
postgres=> SELECTpostgres-> d.datname AS Name,postgres-> pg_catalog.pg_get_userbyid(d.datdba) AS Owner,postgres-> pg_catalog.pg_size_pretty(pg_catalog.pg_database_size) AS(d.postgres_name) -> FROM pg_catalog.pg_database dpostgres-> WHERE d.datname ='postgres'; jméno | majitel | velikost----------+-------------------+--------postgres | cloudsqlsuperuser | 160 GB (1 řádek) Po dokončení všech příprav spusťte test čtení/zápisu:
[example@sqldat.com ~]# pgbench --protocol=připraveno -P 60 --time=600 --client=1000 --jobs=2048spouštění vakua...konec.připojení k databázi "postgres " failed:FATAL:omlouvám se, příliš mnoho klientů již ::proc.c:341připojení k databázi "postgres" selhalo:FATAL:omlouváme se, příliš mnoho klientů již ::proc.c:341připojení k databázi "postgres" selhalo:FATAL:zbývající připojovací sloty jsou vyhrazeny pro nereplikační připojení superuživatele Jejda! Jaké je maximum?
postgres=> show max_connections; max_connections----------------- 600 (1 řádek) Takže zatímco AWS nastavuje z velké části dostatek max_connections, protože jsem se s tímto problémem nesetkal, Google Cloud vyžaduje malé vylepšení...Vraťte se do cloudové konzole, aktualizujte parametr databáze, počkejte několik minut a poté zkontrolujte:
postgres=> show max_connections; max_connections----------------- 1005 (1 řádek) Po restartování testu se zdá, že vše funguje dobře:
spouštěcí vakuum...konc.progres:60,0 s, 5461,7 tps, lat 172,821 ms stddev 251,666progress:120,0 s, 4444,5 tps, lat 225,162 ms,4162 ms 4150 ms stddev 373,998 ...ale má to ještě jeden háček. Při pokusu o otevření nové relace psql, abych spočítal počet připojení, mě překvapilo:
psql:FATAL:zbývající připojovací sloty jsou vyhrazeny pro připojení superuživatele bez replikace Je možné, že superuser_reserved_connections nejsou ve výchozím nastavení?
postgres=> show superuser_reserved_connections; superuser_reserved_connections-------------------------------- 3(1 řádek) To je výchozí, co jiného by to mohlo být?
postgres=> vyberte uživatelské jméno z pg_stat_activity; usename---------------cloudsqladmincloudsqlagentpostgres(3 řádky) Bingo! Postará se o to další náraz max_connections, ale vyžadovalo to restartování testu pgbench. A to je, lidé, příběh za zjevným duplicitním během v grafech níže.
A nakonec jsou výsledky v:
Progress:60,0 s, 4553,6 TPS, Lat 194,696 ms stddev 250,663press:120,0 s, 3646,5 TPS, Lat 278,793 ms stddev 434,459press:180,0 s, 3130,4 TPS, lat 332,936 ms stddevs. 3998.3 tps, lat 250.136 ms stddev 319.215progress:300.0 s, 3305.3 tps, lat 293.250 ms stddev 549.216progress:360.0 s, 3547.9 tps, lat 289.526 ms stddev 454.484progress:420.0 s, 3770.5 tps, lat 265.977 ms stddev 470.451progress:480.0 S, 3050,5 TPS, LAT 327,917 MS STDDEV 643,983 PROGRESS:540,0 s, 3591,7 TPS, LAT 273,906 MS STDDEV 482.020 PROGRESS:600,0 s, 3350,9 TPS (SOUHRED TPC-B (SOUHRESS> sysbench
Naplňte databázi:
sysbench --test=/usr/local/share/sysbench/oltp.lua \--pgsql-host=${PGHOST} \--pgsql-db=${PGDATABASE} \--pgsql- user=${PGUSER} \--pgsql-password=${PGPASSWORD} \--pgsql-port=${PGPORT} \--oltp-tables-count=250\--oltp-table-size=450000 \prepare
Výstup:
sysbench 0.5:srovnávací hodnocení vícevláknového systému Vytváření tabulky 'sbtest1'...Vložení 450 000 záznamů do 'sbtest1'Vytvoření sekundárních indexů na 'sbtest1'...Vytvoření tabulky 'sbtest2'...Vložení 450000 záznamů do 'sbtest2'...Vytváření tabulky 'sbtest249'...Vložení 450 000 záznamů do 'sbtest249'Vytvoření sekundárních indexů na 'sbtest249'...Vytvoření tabulky 'sbtest250'...Vložení 450000 záznamů do 'sbtest250'Cre na 'sbtest250'...
A nyní spusťte test:
sysbench --test=/usr/local/share/sysbench/oltp.lua \--pgsql-host=${PGHOST} \--pgsql-db=${PGDATABASE} \--pgsql- user=${PGUSER} \--pgsql-password=${PGPASSWORD} \--pgsql-port=${PGPORT} \--oltp-tables-count=250 \--oltp-table-size=450000 \- -max-requests=0 \--nucené-vypnutí \--report-interval=60 \--oltp_simple_ranges=0 \--oltp-distinct-ranges=0 \--oltp-sum-ranges=0 \--oltp -order-ranges=0 \--oltp-point-selects=0 \--rand-type=uniform \--max-time=600 \--num-threads=1000 \run
A výsledky:
sysbench 0.5:srovnávací hodnocení vícevláknového systému Spuštění testu s následujícími možnostmi:Počet vláken:1000Hlásit mezivýsledky každých 60 sekund Počátek generátoru náhodných čísel je 0 a bude ignorovánVynucené vypnutí za 630 sekund Inicializace pracovních vláken ...Vlákna spuštěna![ 60s] vlákna:1000, tps:1320,25, čtení:0,00, zápisy:5312,62, doba odezvy:1484,54 ms (95 %), chyby:0,00, opětovné připojení:0,00[ 120tps] vlákna :1486,77, čtení:0,00, zápis:5944,30, doba odezvy:1290,87 ms (95 %), chyby:0,00, opětovné připojení:0,00[ 180s] vlákna:1000, tps:1143,60, doba odezvy:800,60, čtení 1649,50 ms (95 %), chyby:0,02, opětovné připojení:0,00[ 240 s] vlákna:1000, tps:1498,23, čtení:0,00, zápis:5993,06, doba odezvy:1269,03 ms, 0,0,0,03 ms:chyby:0,0 [ 300s] vlákna:1000, tps:1520,53, čtení:0,00, zápisy:6058,57, doba odezvy:1439,90 ms (95 %), chyby:0,02, opětovné připojení:0,00[ 360s:4057 vláken, 1 stps:1s 0,00, zápisy:4958,08, doba odezvy:1550,39 ms (95 %), chyby:0,02, opětovné připojení:0,00[ 420s] vlákna:1000, tps:1722,25, čtení:0,00 (95% doba zápisu:29,51 ms odezvy:29,51 ms ), chyby:0,00, opětovné připojení:0,00[ 480s] vlákna:1000, tps:2306,25, čtení:0,00, zápisy:9233,84, doba odezvy:842,11 ms (95 %), chyby:0,00:0000s, opětovné připojení 1000, tps:1432,85, čtení:0,00, zápis:5720,15, doba odezvy:1709,83 ms (95 %), chyby:0,02, opětovné připojení:0,00[ 600s, vlákna:1000, 303,04 tps zápis:1:03,04 tps:1:1 doba odezvy:1443,78 ms (95 %), chyby:0,02, opětovné připojení:0,00 Statistika testu OLTP:provedené dotazy:čtení:0 zápis:3603595 jiné:1801795 celkem:5405390 transakcí:900895 (1500,68 požadavků) čtení/sec. 3603595 (6002,76 za sec.) ostatní operace:180 1795 (3001,38 za sekundu) ignorované chyby:5 (0,01 za sekundu) opětovné připojení:0 (0,00 za sekundu) Obecná statistika:celkový čas:600,3231s celkový počet událostí:900895 celková doba odezvy potřebná k provedení události:600164,2510 čas:min:6,78 ms prům.:666,19 ms max.:4218,55 ms cca. %
Stáhněte si Whitepaper Today Správa a automatizace PostgreSQL s ClusterControlZjistěte, co potřebujete vědět k nasazení, monitorování, správě a škálování PostgreSQLStáhněte si Whitepaper Srovnávací metriky
Plugin PostgreSQL pro Stackdriver byl ukončen 28. února 2019. Přestože Google doporučuje Blue Medora, pro účely tohoto článku jsem se rozhodl skoncovat s vytvářením účtu a spoléhat se na dostupné metriky Stackdriver.
- Využití CPU:
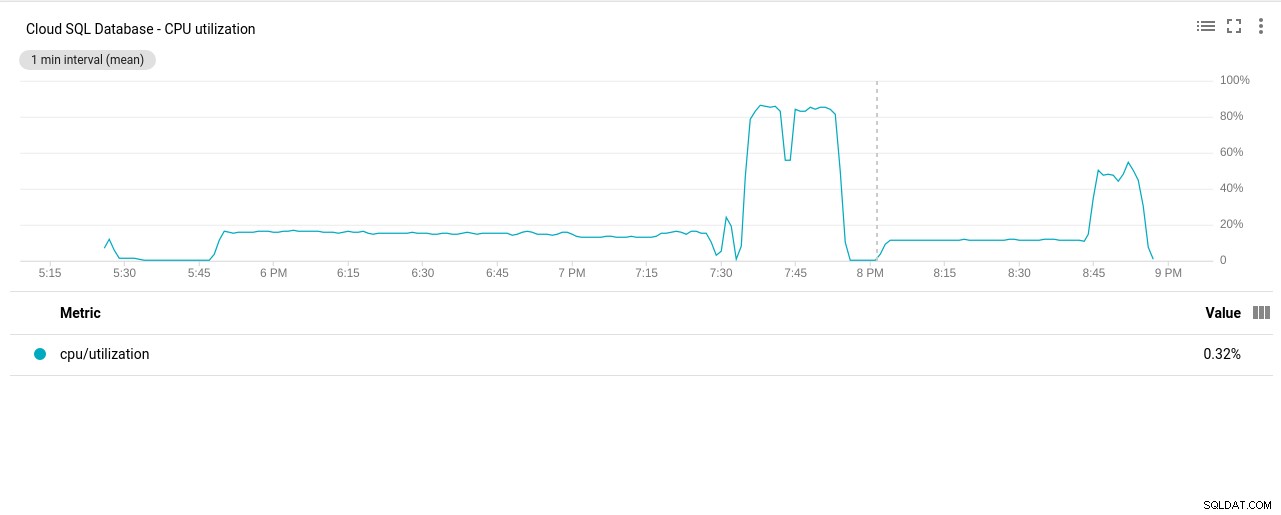 Autor fotografie Google Cloud SQL:Využití procesoru PostgreSQL
Autor fotografie Google Cloud SQL:Využití procesoru PostgreSQL
- Operace čtení/zápisu na disk:
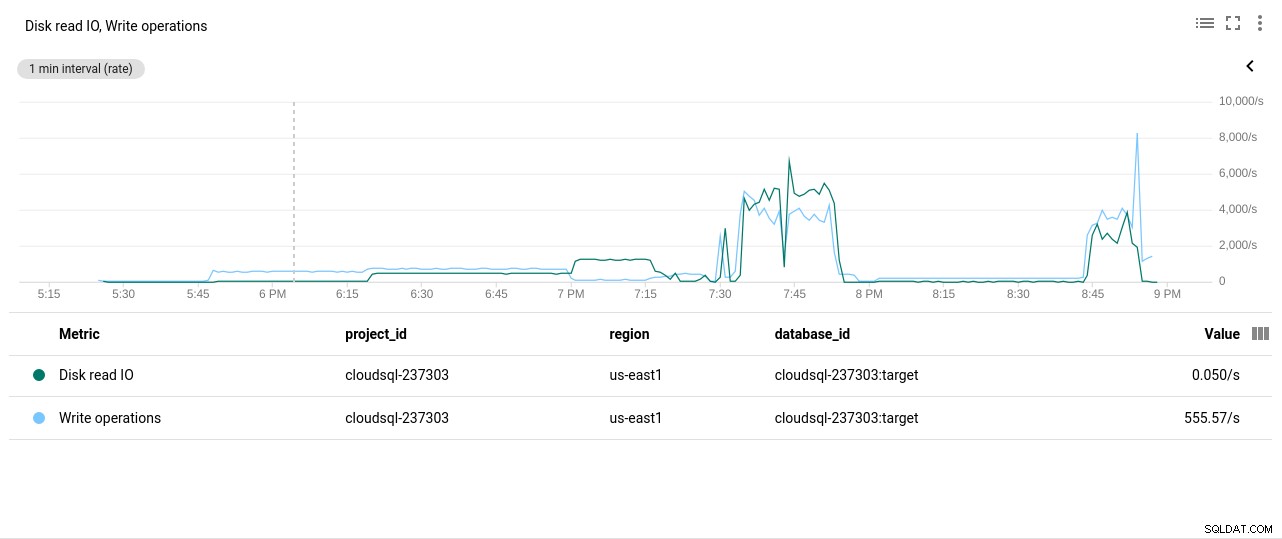 Autor fotografie Google Cloud SQL:Operace čtení/zápis z disku PostgreSQL
Autor fotografie Google Cloud SQL:Operace čtení/zápis z disku PostgreSQL
- Síťové odeslané/přijaté bajty:
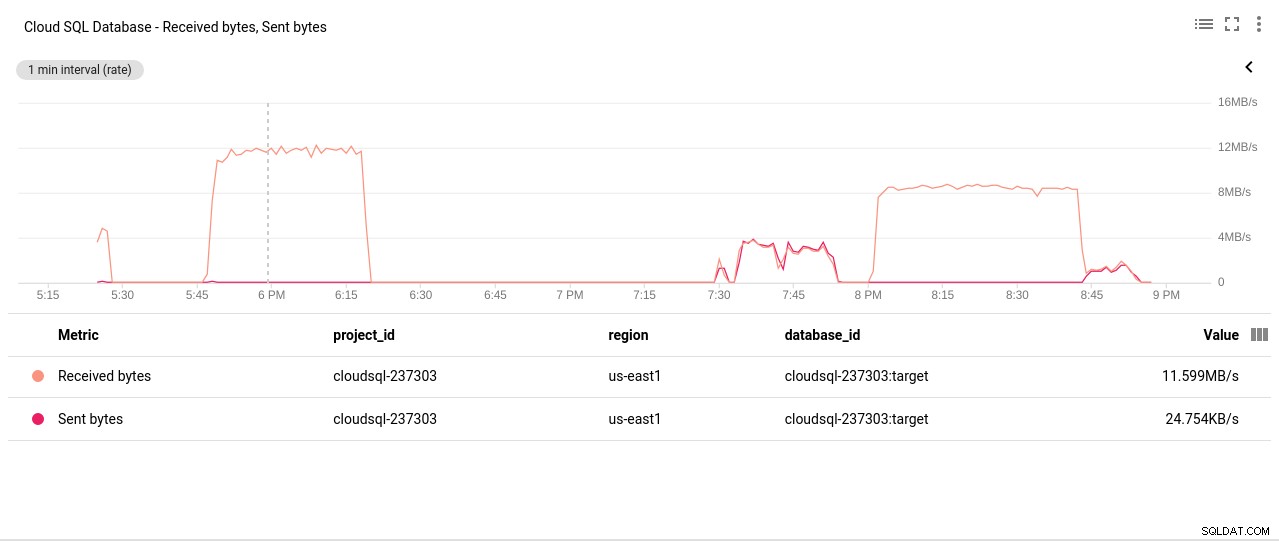 Autor fotografie Google Cloud SQL:PostgreSQL Network Sent/Received bytes
Autor fotografie Google Cloud SQL:PostgreSQL Network Sent/Received bytes
- Počet připojení PostgreSQL:
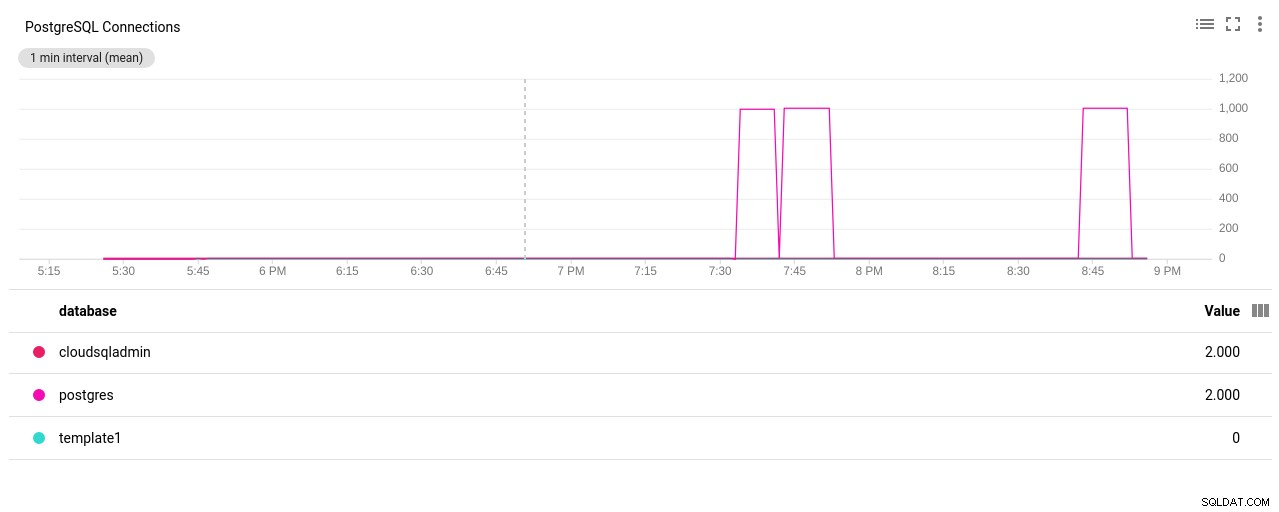 Autor fotografie Google Cloud SQL:Počet připojení PostgreSQL
Autor fotografie Google Cloud SQL:Počet připojení PostgreSQL
Výsledky srovnání
Inicializace pgbench
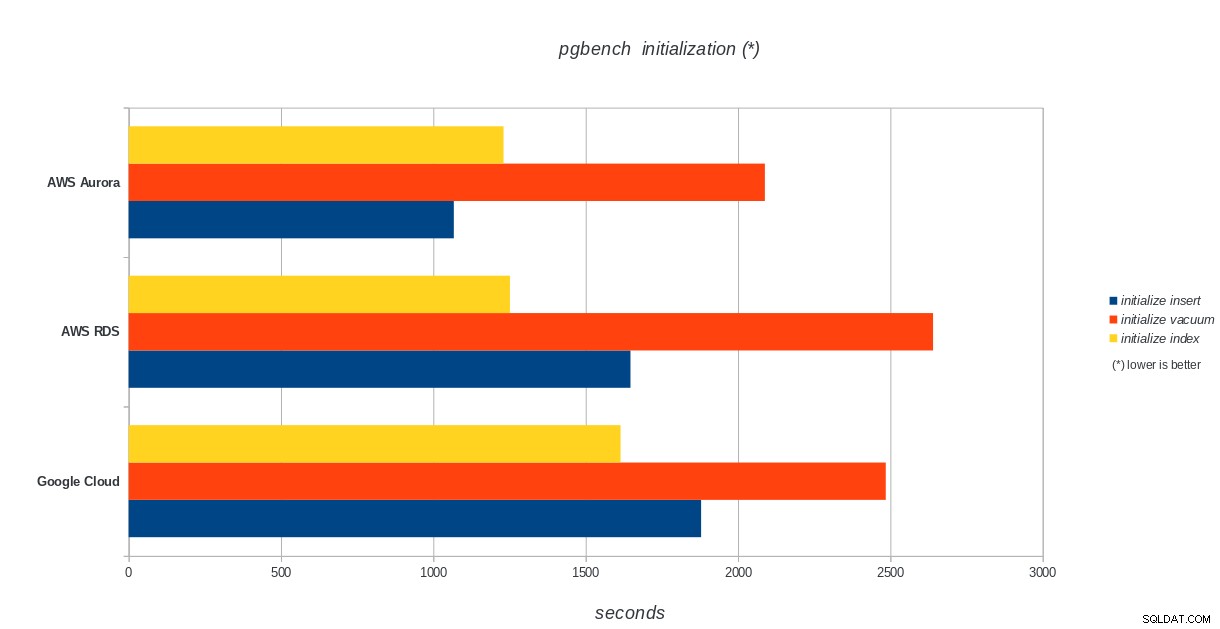 AWS Aurora, AWS RDS, Google Cloud SQL:Výsledky inicializace PostgreSQL pgbench
AWS Aurora, AWS RDS, Google Cloud SQL:Výsledky inicializace PostgreSQL pgbench spuštění pgbench
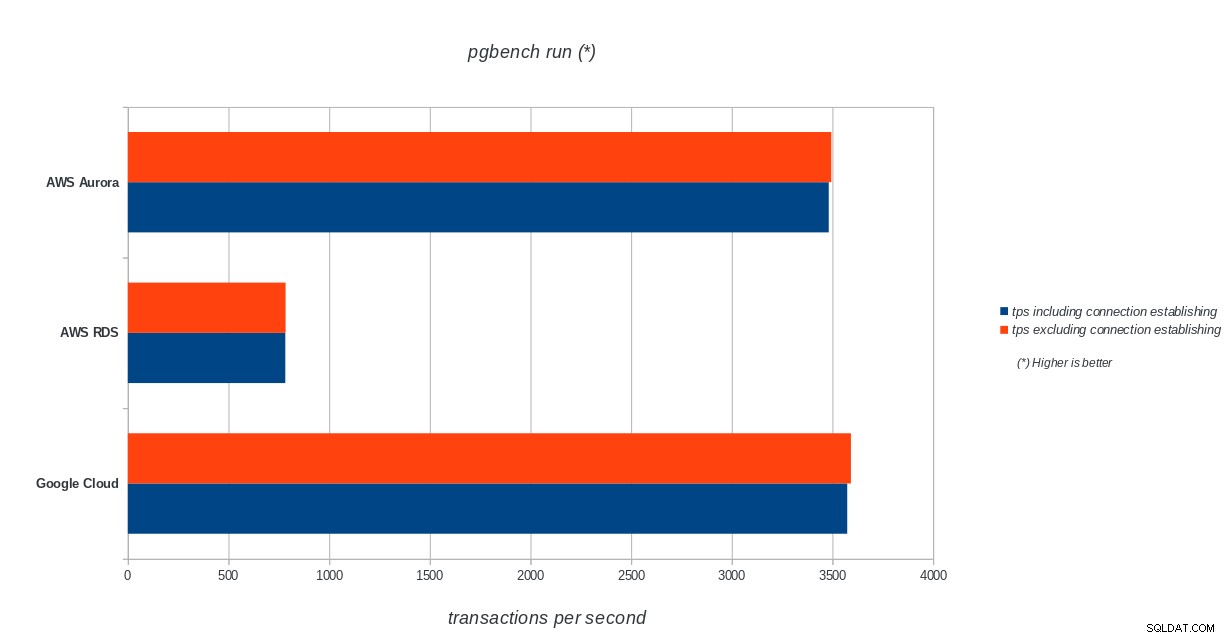 AWS Aurora, AWS RDS, Google Cloud SQL:Výsledky běhu PostgreSQL pgbench
AWS Aurora, AWS RDS, Google Cloud SQL:Výsledky běhu PostgreSQL pgbench sysbench
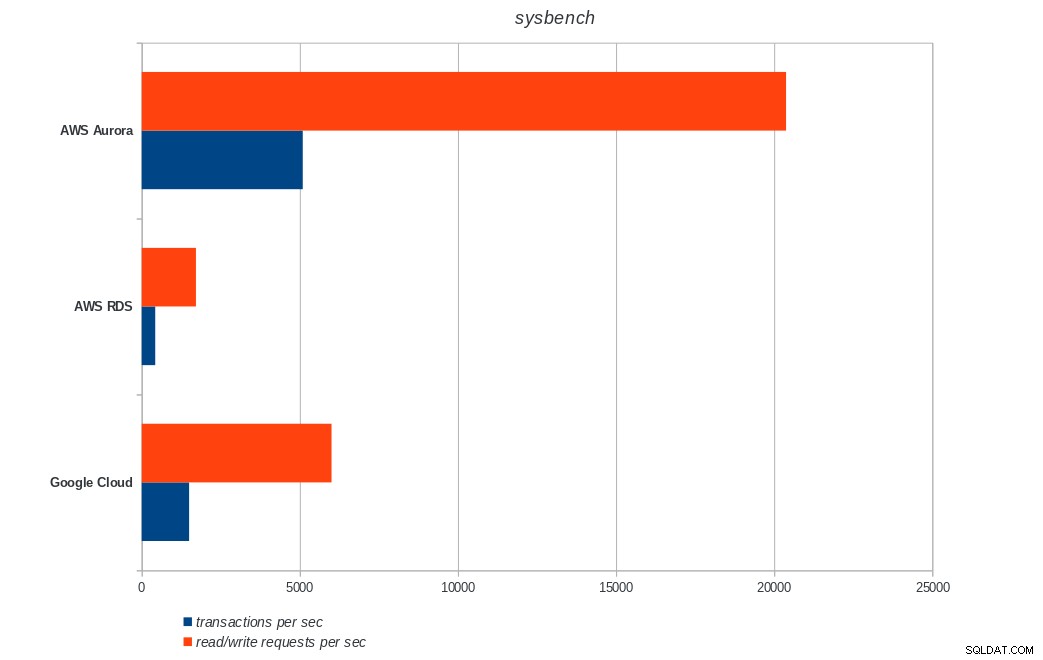 AWS Aurora, AWS RDS, Google Cloud SQL:výsledky PostgreSQL sysbench
AWS Aurora, AWS RDS, Google Cloud SQL:výsledky PostgreSQL sysbench Závěr
Amazon Aurora je zdaleka první v testech zápisu (sysbench) a je na stejné úrovni jako Google Cloud SQL v testech čtení/zápisu pgbench. Zátěžový test (inicializace pgbench) staví na první místo Google Cloud SQL, následovaný Amazon RDS. Na základě zběžného pohledu na cenové modely pro AWS Aurora a Google Cloud SQL bych riskoval, že bych řekl, že Google Cloud je hned po vybalení lepší volbou pro průměrného uživatele, zatímco AWS Aurora je vhodnější pro vysoce výkonná prostředí. Po dokončení všech benchmarků bude následovat další analýza.
Další a poslední díl této série benchmarků bude na Microsoft Azure PostgreSQL.
Děkujeme za přečtení a pokud máte zpětnou vazbu, napište komentář níže.