ANY agregace není něco, co můžeme psát přímo v Transact SQL. Je to pouze interní funkce používaná optimalizátorem dotazů a prováděcím jádrem.
Osobně mám docela rád ANY agregátu, takže bylo trochu zklamáním, když jsem se dozvěděl, že je rozbitý docela zásadním způsobem. Konkrétní příchuť ‚broken‘, o které zde mluvím, je odrůda se špatnými výsledky.
V tomto příspěvku se podívám na dvě konkrétní místa, kde je ANY agregace se běžně zobrazuje, demonstruje problém se špatnými výsledky a v případě potřeby navrhuje náhradní řešení.
Pro pozadí na ANY souhrn, viz můj předchozí příspěvek Plány nezdokumentovaných dotazů:JAKÉKOLI Agregáty.
1. Jeden řádek na skupinové dotazy
Toto musí být jeden z nejběžnějších požadavků na každodenní dotazy s velmi dobře známým řešením. Pravděpodobně píšete tento druh dotazu každý den, automaticky podle vzoru, aniž byste o tom skutečně přemýšleli.
Cílem je očíslovat vstupní sadu řádků pomocí ROW_NUMBER funkce okna, rozdělená podle seskupovacího sloupce nebo sloupců. To je zabaleno do Common Table Expression nebo odvozená tabulka a filtrovány dolů na řádky, kde se vypočítané číslo řádku rovná jedné. Od ROW_NUMBER restartuje na jednom pro každou skupinu, to nám dává požadovaný jeden řádek na skupinu.
S tímto obecným vzorem není žádný problém. Typ jednoho řádku na skupinový dotaz, který podléhá ANY agregovaný problém je ten, kdy nám nezáleží na tom, který konkrétní řádek je vybrán z každé skupiny.
V takovém případě není jasné, který sloupec by měl být použit v povinném ORDER BY klauzule ROW_NUMBER funkce okna. Ostatně nás to výslovně nezajímá který řádek je vybrán. Jedním z běžných přístupů je opětovné použití PARTITION BY sloupce v ORDER BY doložka. Zde může nastat problém.
Příklad
Podívejme se na příklad pomocí datové sady hraček:
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Group 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222);
Požadavek je vrátit libovolný jeden úplný řádek dat z každé skupiny, kde členství ve skupině je definováno hodnotou ve sloupci c1 .

Za ROW_NUMBER vzor, můžeme napsat dotaz jako je následující (všimněte si ORDER BY klauzule ROW_NUMBER funkce okna odpovídá PARTITION BY klauzule):
WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Jak je uvedeno, tento dotaz se provede úspěšně se správnými výsledky. Výsledky jsou technicky nedeterministické protože SQL Server mohl platně vrátit kterýkoli z řádků v každé skupině. Pokud však tento dotaz spustíte sami, pravděpodobně uvidíte stejný výsledek jako já:
Plán provádění závisí na použité verzi SQL Server a nezávisí na úrovni kompatibility databáze.
Na SQL Server 2014 a starších verzích je plán:

Pro SQL Server 2016 nebo novější uvidíte:

Oba plány jsou bezpečné, ale z různých důvodů. Odlišné řazení plán obsahuje ANY agregát, ale Odlišné řazení implementace operátora neprojevuje chybu.
Složitější plán SQL Server 2016+ nepoužívá ANY agregovat vůbec. Řadit zařadí řádky do pořadí potřebného pro operaci číslování řádků. Segment operátor nastaví příznak na začátku každé nové skupiny. Projekt sekvence vypočítá číslo řádku. Nakonec Filtr operátor předá pouze ty řádky, které mají vypočítané číslo řádku jedna.
Chyba
Abychom získali nesprávné výsledky s touto sadou dat, musíme používat SQL Server 2014 nebo starší a ANY agregáty je třeba implementovat do agregátu streamů nebo Eager Hash Aggregate operátor (Flow Distinct Hash Match Aggregate neprodukuje chybu).
Jedním ze způsobů, jak povzbudit optimalizátor, aby zvolil Souhrnný zdroj místo Odlišné řazení je přidat seskupený index, který zajistí řazení podle sloupce c1 :
CREATE CLUSTERED INDEX c ON #Data (c1);
Po této změně se plán provádění změní na:

ANY agregáty jsou viditelné v Vlastnostech v okně Stream Aggregate je vybrán operátor:

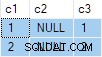
Výsledek dotazu je:
To je špatné . SQL Server vrátil řádky, které neexistují ve zdrojových datech. Neexistují žádné zdrojové řádky, kde by c2 = 1 a c3 = 1 například. Připomínáme, že zdrojová data jsou:
Prováděcí plán chybně počítá oddělené ANY agregáty pro c2 a c3 sloupce, ignorování hodnot null. Každý agreguje nezávisle vrátí první není null hodnota, na kterou narazí, což dává výsledek, kde jsou hodnoty pro c2 a c3 pocházejí z různých zdrojových řádků . Toto není to, co původní specifikace SQL dotazu požadovala.
Stejný chybný výsledek lze vytvořit s nebo bez seskupený index přidáním OPTION (HASH GROUP) tip na vytvoření plánu s Eager Hash Aggregate namísto Stream Aggregate .
Podmínky
Tento problém může nastat pouze při více ANY jsou přítomny agregáty a agregovaná data obsahují hodnoty null. Jak bylo uvedeno, problém se týká pouze Stream Aggregate a Eager Hash Aggregate operátoři; Odlišné řazení a Flow Distinct nejsou ovlivněny.
SQL Server 2016 a novější se snaží vyhnout zavádění více ANY agreguje pro libovolný jeden řádek na skupinu vzoru číslování řádků, když zdrojové sloupce mají hodnotu null. Když k tomu dojde, plán provádění bude obsahovat Segment , Projekt sekvence a Filtrovat operátory místo agregátu. Tento tvar plánu je vždy bezpečný, protože žádný ANY se používají agregáty.
Reprodukování chyby v SQL Server 2016+
Optimalizátor SQL Server není dokonalý při zjišťování, kdy byl sloupec původně omezen na hodnotu NOT NULL může stále vytvářet nulovou střední hodnotu prostřednictvím manipulací s daty.
Abychom to reprodukovali, začneme tabulkou, kde jsou všechny sloupce deklarovány jako NOT NULL :
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Group 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3);
Z této datové sady můžeme vytvořit hodnoty null mnoha způsoby, z nichž většinu dokáže optimalizátor úspěšně detekovat, a tak se vyhneme zavádění ANY agregáty během optimalizace.
Jeden způsob, jak přidat nuly, které náhodou proklouznou pod radar, je znázorněn níže:
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2; Tento dotaz vytvoří následující výstup:
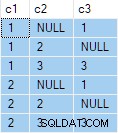
Dalším krokem je použít tuto specifikaci dotazu jako zdrojová data pro standardní dotaz „libovolný jeden řádek na skupinu“:
WITH
SneakyNulls AS
(
-- Introduce nulls the optimizer can't see
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Na libovolnou verzi SQL Server, který vytváří následující plán:
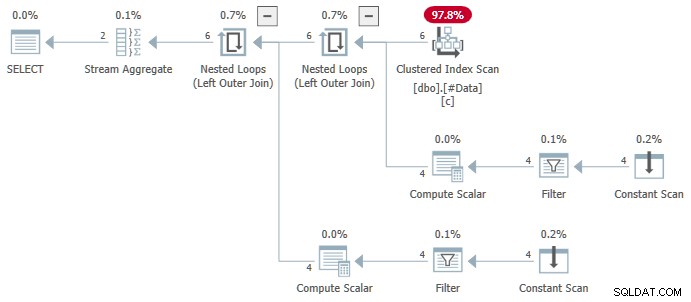
Agregace streamů obsahuje více ANY agregáty a výsledek je špatný . Žádný z vrácených řádků se neobjeví ve zdrojové sadě dat:
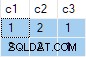
db<>online ukázka houslí
Řešení
Jediným plně spolehlivým řešením, dokud nebude tato chyba opravena, je vyhnout se vzoru, kde je ROW_NUMBER má stejný sloupec v ORDER BY klauzule tak, jak je v PARTITION BY doložka.
Když je nám jedno, které z každé skupiny je vybrán jeden řádek, je nešťastné, že ORDER BY doložka je vůbec potřeba. Jedním ze způsobů, jak problém obejít, je použít konstantu doby běhu jako ORDER BY @@SPID ve funkci okna.
2. Nedeterministická aktualizace
Problém s více ANY agregace na vstupech s možnou hodnotou null není omezena na žádný jeden řádek na vzor dotazu skupiny. Optimalizátor dotazů může zavést interní ANY agregovat za mnoha okolností. Jedním z těchto případů je nedeterministická aktualizace.
Nedeterministický aktualizace je tam, kde příkaz nezaručuje, že každý cílový řádek bude aktualizován nejvýše jednou. Jinými slovy, existuje více zdrojových řádků pro alespoň jeden cílový řádek. Dokumentace na to výslovně upozorňuje:
Při zadávání klauzule FROM, která poskytuje kritéria pro operaci aktualizace, buďte opatrní.Výsledky příkazu UPDATE nejsou definovány, pokud příkaz obsahuje klauzuli FROM, která není specifikována tak, že pro každý výskyt sloupce, který je aktualizován, je k dispozici pouze jedna hodnota, tj. je, pokud příkaz UPDATE není deterministický.
Aby optimalizátor zpracoval nedeterministickou aktualizaci, seskupuje řádky podle klíče (index nebo RID) a použije ANY agregáty do zbývajících sloupců. Základní myšlenkou je vybrat jeden řádek z více kandidátů a použít hodnoty z tohoto řádku k provedení aktualizace. Existují zřejmé paralely s předchozím ROW_NUMBER problém, takže není překvapením, že je docela snadné prokázat nesprávnou aktualizaci.
Na rozdíl od předchozího vydání SQL Server aktuálně neprovádí žádné zvláštní kroky abyste se vyhnuli vícenásobným ANY agreguje na sloupcích s možnou hodnotou Null při provádění nedeterministické aktualizace. Následující text se proto týká všech verzí SQL Server , včetně SQL Server 2019 CTP 3.0.
Příklad
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
SELECT * FROM @Target AS T; db<>online ukázka houslí
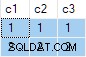
Logicky by tato aktualizace měla vždy způsobit chybu:Cílová tabulka nepovoluje hodnoty null v žádném sloupci. Bez ohledu na to, který odpovídající řádek je vybrán ze zdrojové tabulky, pokus o aktualizaci sloupce c2 nebo c3 na hodnotu null musí dojít.
Aktualizace se bohužel zdařila a konečný stav cílové tabulky je v rozporu s dodanými daty:
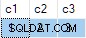
Nahlásil jsem to jako chybu. Řešením je vyhnout se psaní nedeterministického UPDATE příkazy, takže ANY k vyřešení nejednoznačnosti nejsou potřeba agregáty.
Jak bylo zmíněno, SQL Server může zavést ANY agreguje za více okolností než dva zde uvedené příklady. Pokud k tomu dojde, když agregovaný sloupec obsahuje hodnoty null, existuje možnost nesprávných výsledků.