Každý programátor vám řekne, že psaní bezpečného vícevláknového kódu může být obtížné. Vyžaduje velkou péči a dobré porozumění souvisejícím technickým problémům. Jako databázový člověk si možná myslíte, že tyto druhy potíží a komplikací při psaní T-SQL neplatí. Takže může být trochu šok, když si uvědomíme, že kód T-SQL je také zranitelný vůči druhu rasových podmínek a dalším rizikům integrity dat, která jsou nejčastěji spojována s vícevláknovým programováním. To platí, ať už mluvíme o jediném příkazu T-SQL nebo o skupině příkazů uzavřených v explicitní transakci.
Jádrem problému je skutečnost, že databázové systémy umožňují provádění více transakcí současně. Toto je dobře známý (a velmi žádoucí) stav věcí, ale velká část produkčního kódu T-SQL stále tiše předpokládá, že základní data se během provádění transakce nebo jediného příkazu DML, jako je SELECT , INSERT , UPDATE , DELETE nebo MERGE .
I když si je autor kódu vědom možných účinků souběžných změn dat, příliš často se předpokládá, že použití explicitních transakcí poskytuje větší ochranu, než je skutečně oprávněné. Tyto domněnky a mylné představy mohou být rafinované a jistě dokážou uvést v omyl i zkušené databázové odborníky.
Nyní existují případy, kdy tyto problémy nebudou v praktickém smyslu příliš důležité. Databáze může být například pouze pro čtení nebo může existovat jiná pravá záruka že nikdo jiný nezmění podkladová data, když s nimi pracujeme. Stejně tak dotyčná operace nemusí vyžadovat výsledky, které jsou přesně opravit; naši spotřebitelé dat mohou být naprosto spokojeni s přibližným výsledkem (dokonce i s takovým, který nepředstavuje potvrzený stav databáze v žádném bod v čase).
Problémy se souběhem
Otázka interference mezi souběžně prováděnými úkoly je známým problémem vývojářů aplikací pracujících v programovacích jazycích jako C# nebo Java. Řešení je mnoho a jsou různorodá, ale obecně zahrnují použití atomových operací nebo získání vzájemně se vylučujícího zdroje (jako je zámek ), zatímco probíhá citlivá operace. Pokud nejsou přijata náležitá opatření, pravděpodobným výsledkem jsou poškozená data, chyba nebo možná dokonce úplná havárie.
Ve světě databází existuje mnoho stejných pojmů (např. atomické operace a zámky), ale bohužel často mají zásadní rozdíly ve významu . Většina databázových lidí si je vědoma vlastností ACID databázových transakcí, kde A znamená atomový . SQL Server také používá zámky (a další interně vylučující zařízení). Ani jeden z těchto termínů neznamená přesně to, co by zkušený programátor v C# nebo Java rozumně očekával, a mnoho databázových profesionálů má rovněž zmatené chápání těchto témat (jak dosvědčí rychlé vyhledávání pomocí vašeho oblíbeného vyhledávače).
Znovu opakuji, že někdy tyto problémy nebudou praktickým problémem. Pokud napíšete dotaz pro počítání počtu aktivních objednávek v databázovém systému, jak důležité je, když je počet trochu mimo? Nebo pokud odráží stav databáze v nějakém jiném časovém okamžiku?
Je běžné, že skutečné systémy dělají kompromis mezi souběžností a konzistencí (i když si toho návrhář v té době nebyl vědom – informován kompromisy jsou možná vzácnější zvíře). Skutečné systémy často fungují dostatečně s jakýmikoli anomáliemi krátkodobými nebo považovanými za nedůležité. Uživatel, který vidí na webové stránce nekonzistentní stav, často problém vyřeší obnovením stránky. Pokud je problém nahlášen, bude s největší pravděpodobností uzavřen jako Nereprodukovatelný. Neříkám, že je to žádoucí stav věcí, jen uznávám, že k tomu dochází.
Nicméně je nesmírně užitečné porozumět problémům souběžnosti na základní úrovni. Jejich vědomí nám umožňuje psát správně (nebo informovaně správně-dost) T-SQL, jak to okolnosti vyžadují. Ještě důležitější je, že nám umožňuje vyhnout se psaní T-SQL, které by mohlo ohrozit logickou integritu našich dat.
Ale SQL Server poskytuje záruky ACID!
Ano, je, ale nejsou vždy takové, jaké byste očekávali, a nechrání všechno. Lidé častěji čtou mnohem více do KYSELIN než je oprávněné.
Nejčastěji nepochopenými složkami zkratky ACID jsou slova Atomic, Consistent a Isolated – k těm se za chvíli dostaneme. Druhý, Odolný , je dostatečně intuitivní, pokud si pamatujete, že se vztahuje pouze na trvalé (obnovitelné) uživatel data.
Se vším, co bylo řečeno, začíná SQL Server 2014 poněkud rozmazávat hranice vlastnosti Durable zavedením obecné opožděné trvanlivosti a trvanlivosti pouze podle schématu OLTP v paměti. Uvádím je pouze pro úplnost, dále se o těchto novinkách nebudeme rozepisovat. Přejděme k problematičtějším vlastnostem ACID:
Atomová vlastnost
Mnoho programovacích jazyků poskytuje atomické operace které lze použít k ochraně proti rasovým podmínkám a dalším nežádoucím souběžným efektům, kdy více vláken provádění může přistupovat nebo upravovat sdílené datové struktury. Pro vývojáře aplikace přichází atomická operace s explicitní zárukou úplné izolace od účinků jiného souběžného zpracování ve vícevláknovém programu.
Obdobná situace nastává v databázovém světě, kde více T-SQL dotazů současně přistupuje a upravuje sdílená data (tj. databázi) z různých vláken. Všimněte si, že zde nehovoříme o paralelních dotazech; běžné jednovláknové dotazy jsou běžně naplánovány tak, aby se spouštěly souběžně v rámci serveru SQL Server v samostatných pracovních vláknech.
Bohužel, atomová vlastnost transakcí SQL pouze zaručuje, že úpravy dat provedené v rámci transakce uspějí nebo selžou jako celek . Nic víc než to. Rozhodně neexistuje žádná záruka úplné izolace od účinků jiného souběžného zpracování. Všimněte si také, že vlastnost atomické transakce neříká nic o žádných zárukách ohledně čtení data.
Jednotlivé příkazy
Na jednotném prohlášení také není nic zvláštního v SQL Serveru. Kde explicitně obsahující transakci (BEGIN TRAN...COMMIT TRAN ) neexistuje, jeden příkaz DML se stále provádí v rámci transakce automatického potvrzení. Stejné záruky ACID platí pro jediné prohlášení a také stejná omezení. Jednotlivý výpis je dodáván bez zvláštních záruk, že se data během zpracování nezmění.
Zvažte následující dotaz na hračku AdventureWorks:
SELECT
TH.TransactionID,
TH.ProductID,
TH.ReferenceOrderID,
TH.ReferenceOrderLineID,
TH.TransactionDate,
TH.TransactionType,
TH.Quantity,
TH.ActualCost
FROM Production.TransactionHistory AS TH
WHERE TH.ReferenceOrderID =
(
SELECT TOP (1)
TH2.ReferenceOrderID
FROM Production.TransactionHistory AS TH2
WHERE TH2.TransactionType = N'P'
ORDER BY
TH2.Quantity DESC,
TH2.ReferenceOrderID ASC
); Dotaz je určen k zobrazení informací o Zakázce, která je na prvním místě podle Množství. Prováděcí plán je následující:
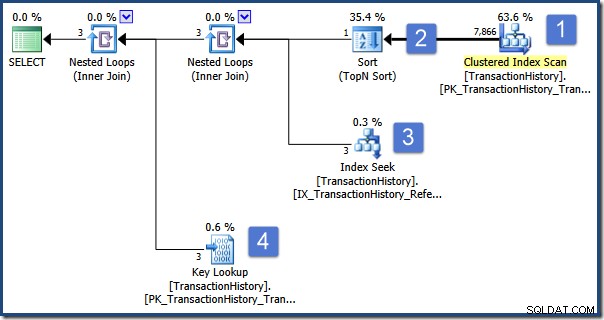
Hlavní operace v tomto plánu jsou:
- Naskenujte tabulku a vyhledejte řádky s požadovaným typem transakce
- Najděte ID objednávky, které se řadí nejvýše podle specifikace v dílčím dotazu
- Najděte řádky (ve stejné tabulce) s vybraným ID objednávky pomocí neseskupeného indexu
- Vyhledejte zbývající data sloupců pomocí seskupeného indexu
Nyní si představte, že souběžný uživatel upraví příkaz 495, změní jeho typ transakce z P na W a provede tuto změnu do databáze. Naštěstí tato úprava projde, zatímco náš dotaz provádí operaci řazení (krok 2).
Když se řazení dokončí, hledání indexu v kroku 3 najde řádky s vybraným ID objednávky (které je shodou okolností 495) a vyhledávání klíčů v kroku 4 načte zbývající sloupce ze základní tabulky (kde je nyní Typ transakce W). .
Tato sekvence událostí znamená, že náš dotaz produkuje zdánlivě nemožný výsledek:

Místo hledání příkazů s typem transakce P jako zadaným dotazem výsledky ukazují typ transakce W.
Hlavní příčina je jasná:náš dotaz implicitně předpokládal, že se data nemohou změnit, dokud náš dotaz s jedním příkazem probíhal. Okno příležitosti v tomto případě bylo relativně velké kvůli blokujícímu řazení, ale stejný druh sporu může nastat v jakékoli fázi provádění dotazu, obecně řečeno. Přirozeně jsou rizika obvykle vyšší se zvýšenou úrovní souběžných úprav, většími tabulkami a tam, kde se v plánu dotazů objevují blokující operátory.
Dalším přetrvávajícím mýtem ve stejné obecné oblasti je, že MERGE má být preferováno před samostatným INSERT , UPDATE a DELETE příkazy, protože jeden příkaz MERGE je atomový. To je samozřejmě nesmysl. K tomuto druhu uvažování se vrátíme později v seriálu.
Obecnou zprávou v tomto bodě je, že pokud nebudou učiněny explicitní kroky k zajištění opaku, mohou se datové řádky a položky indexu kdykoli během procesu provádění změnit, přesunout nebo zcela zmizet. Mentální obraz neustálých a náhodných změn v databázi je dobré mít na paměti při psaní T-SQL dotazů.
Vlastnost konzistence
Druhé slovo ze zkratky ACID má také řadu možných interpretací. V databázi SQL Server znamená Konzistence pouze že transakce opustí databázi ve stavu, který neporušuje žádná aktivní omezení. Je důležité si plně uvědomit, jak omezené je toto prohlášení:Jediné ACID záruky integrity dat a logické konzistence jsou ty, které poskytují aktivní omezení.
SQL Server poskytuje omezený rozsah omezení k vynucení logické integrity, včetně PRIMARY KEY , FOREIGN KEY , CHECK , UNIQUE a NOT NULL . To vše je zaručeno, že budou splněny v okamžiku potvrzení transakce. Kromě toho SQL Server zaručuje fyzické integritu databáze za všech okolností, samozřejmě.
Vestavěná omezení nejsou vždy dostatečná k vynucení všech obchodních pravidel a pravidel integrity dat, která bychom chtěli. Je jistě možné být kreativní se standardními zařízeními, ale ty se rychle stanou složitými a mohou vést k ukládání duplicitních dat.
V důsledku toho většina skutečných databází obsahuje alespoň některé rutiny T-SQL napsané k vynucení dalších pravidel, například v uložených procedurách a spouštěcích mechanismech. Odpovědnost za zajištění správného fungování tohoto kódu spočívá výhradně na autorovi – vlastnost Consistency neposkytuje žádnou specifickou ochranu.
Abychom to zdůraznili, pseudoomezení napsaná v T-SQL musí fungovat správně bez ohledu na to, jaké souběžné úpravy mohou nastat. Vývojář aplikace může chránit citlivou operaci, jako je tato, příkazem lock. Nejbližší věc, kterou mají programátoři T-SQL k tomuto zařízení pro rizikové uložené procedury a spouštěcí kód, je poměrně zřídka používaný sp_getapplock uložená procedura systému. To neznamená, že je to jediná, nebo dokonce preferovaná možnost, jen to, že existuje a za určitých okolností může být tou správnou volbou.
Vlastnost izolace
Toto je snadno nejčastěji nepochopená vlastnost transakce ACID.
V zásadě zcela izolovaný transakce se provede jako jediná úloha spouštěná proti databázi během její životnosti. Jiné transakce mohou začít až po úplném dokončení aktuální transakce (tj. potvrzení nebo vrácení zpět). Transakce provedená tímto způsobem by skutečně byla atomovou operací , v přísném smyslu, že by frázi připsala osoba, která není v databázi.
V praxi databázové transakce místo toho fungují s stupněm izolace specifikovaná aktuálně platnou úrovní izolace transakcí (což platí stejně pro samostatné příkazy, pamatujte). Tento kompromis (stupeň izolace) je praktickým důsledkem výše zmíněných kompromisů mezi souběžností a správností. Systém, který doslova zpracovával transakce jednu po druhé, bez časového překrývání, by poskytoval úplnou izolaci, ale celková propustnost systému by byla pravděpodobně špatná.
Příště
Další část této série bude pokračovat ve zkoumání problémů souběžnosti, vlastností ACID a izolace transakcí s podrobným pohledem na úroveň serializovatelné izolace, což je další příklad něčeho, co nemusí znamenat to, co si myslíte.
[ Viz rejstřík pro celou sérii ]