Publikoval jsem několik benchmarků porovnávajících různé verze PostgreSQL, jako je například přednáška o archeologii výkonu (hodnocení PostgreSQL 7.4 až 9.4) a všechny tyto benchmarky předpokládaly pevné prostředí (hardware, jádro, …). Což je v mnoha případech v pořádku (např. při vyhodnocování dopadu opravy na výkon), ale ve výrobě se tyto věci časem mění – získáte upgrady hardwaru a čas od času získáte aktualizaci s novou verzí jádra.
U upgradů hardwaru (lepší úložiště, více paměti RAM, rychlejší CPU, …) je dopad obvykle poměrně snadno předvídatelný a lidé si navíc obecně uvědomují, že musí dopad posoudit analýzou úzkých míst ve výrobě a možná i testováním nového hardwaru. .
Ale co aktualizace jádra? Bohužel v této oblasti obvykle moc benchmarkingu neprovádíme. Většinou se předpokládá, že nová jádra jsou lepší než starší (rychlejší, efektivnější, škálovatelná na více jader CPU). Ale je to skutečně pravda? A jak velký je rozdíl? Co když například upgradujete jádro z 3.0 na 4.7 – ovlivní to výkon, a pokud ano, zlepší se výkon nebo ne?
Čas od času dostáváme zprávy o závažných regresích s konkrétní verzí jádra nebo náhlém zlepšení mezi verzemi jádra. Je tedy zřejmé, že verze jádra mohou ovlivnit výkon.
Jsem si vědom jediného benchmarku PostgreSQL porovnávajícího různé verze jádra, který v roce 2014 vytvořil Sergey Konoplev v reakci na doporučení vyhnout se jádrům 3.0 – 3.8. Ale tento benchmark je poměrně starý (poslední dostupná verze jádra před ~18 měsíci byla 3.13, zatímco dnes máme 3.19 a 4.6), takže jsem se rozhodl spustit nějaké benchmarky se současnými jádry (a PostgreSQL 9.6beta1).
PostgreSQL vs. verze jádra
Nejprve mi však dovolte prodiskutovat některé významné rozdíly mezi politikami, kterými se řídí závazky v těchto dvou projektech. V PostgreSQL máme koncept hlavních a vedlejších verzí – hlavní verze (např. 9.5) vycházejí zhruba jednou ročně a obsahují různé nové funkce. Menší verze (např. 9.5.2) obsahují pouze opravy chyb a jsou vydávány přibližně každé tři měsíce (nebo častěji, když je objevena závažná chyba). Mezi vedlejšími verzemi by tedy nemělo docházet k žádným velkým změnám výkonu nebo chování, takže nasazení vedlejších verzí bez rozsáhlého testování je poměrně bezpečné.
U verzí jádra je situace mnohem méně jasná. Linuxové jádro má také větve (např. 2.6, 3.0 nebo 4.7), které se v žádném případě nevyrovnají „hlavním verzím“ z PostgreSQL, protože stále dostávají nové funkce a nejen opravy chyb. Netvrdím, že politika verzování PostgreSQL je nějak automaticky lepší, ale důsledkem je, že aktualizace mezi menšími verzemi jádra může snadno významně ovlivnit výkon nebo dokonce zavést chyby (např. 3.18.37 trpí problémy OOM kvůli takové opravě bez chyb spáchat).
Distribuce si tato rizika samozřejmě uvědomují a často zamykají verzi jádra a provádějí další testování, aby odstranily nové chyby. Tento příspěvek však používá dlouhodobá jádra vanilla, která jsou dostupná na www.kernel.org.
Srovnávací
Existuje mnoho benchmarků, které bychom mohli použít – tento příspěvek představuje sadu testů pgbench, tedy poměrně jednoduchý benchmark OLTP (TPC-B-like). Plánuji provést další testy s dalšími typy benchmarků (zejména orientovanými na DWH/DSS) a v budoucnu je představím na tomto blogu.
Nyní zpět k pgbench – když říkám „sbírka testů“, mám na mysli kombinace
- pouze pro čtení vs. pro čtení a zápis
- velikost datové sady – aktivní sada se (ne)vejde do sdílených vyrovnávacích pamětí / RAM
- počet klientů – jeden klient vs. mnoho klientů (uzamykání/plánování)
Hodnoty samozřejmě závisí na použitém hardwaru, takže se podívejme, na jakém hardwaru toto kolo benchmarků běželo:
- CPU:Intel i5-2500k @ 3,3 GHz (3,7 GHz turbo)
- RAM:8 GB (DDR3 @ 1333 MHz)
- úložiště:6x Intel SSD DC S3700 v RAID-10 (Linux sw raid)
- systém souborů:ext4 s výchozím plánovačem I/O (cfq)
Takže je to stejný stroj, který jsem používal pro řadu předchozích benchmarků – poměrně malý stroj, ne úplně nejnovější CPU atd., ale věřím, že je to stále rozumný „malý“ systém.
Parametry benchmarku jsou:
- Měřítko datové sady:30, 300 a 1500 (tedy zhruba 450 MB, 4,5 GB a 22,5 GB)
- počet klientů:1, 4, 16 (stroj má 4 jádra)
Pro každou kombinaci byly 3 běhy pouze pro čtení (každý 15 minut) a 3 běhy pro čtení a zápis (každý 30 minut). Skutečný skript řídící benchmark je k dispozici zde (spolu s výsledky a dalšími užitečnými daty).
Poznámka :Pokud máte výrazně odlišný hardware (např. rotační disky), můžete vidět velmi odlišné výsledky. Máte-li systém, který byste chtěli otestovat, dejte mi vědět a já vám s tím pomohu (za předpokladu, že budu mít povolení publikovat výsledky).
Verze jádra
Pokud jde o verze jádra, testoval jsem nejnovější verze ve všech dlouhodobých větvích od 2.6.x (2.6.39, 3.0.101, 3.2.81, 3.4.112, 3.10.102, 3.12.61, 3.14.73, 3.16. 36, 3.18.38, 4.1.29, 4.4.16, 4.6.5 a 4.7). Na jádrech 2.6.x stále běží spousta systémů, takže je užitečné vědět, kolik výkonu můžete získat (nebo ztratit) upgradem na novější jádro. Ale kompiloval jsem všechna jádra sám (tj. pomocí vanilla kernelů, žádné záplaty specifické pro distribuci) a konfigurační soubory jsou v repozitáři git.
Výsledky
Jako obvykle jsou všechna data dostupná na bitbucket, včetně
- soubor .config jádra
- srovnávací skript (run-pgbench.sh)
- Konfigurace PostgreSQL (s určitým základním vyladěním hardwaru)
- Protokoly PostgreSQL
- různé systémové protokoly (dmesg, sysctl, mount, …)
Následující grafy ukazují průměrné tps pro každý srovnávací případ – výsledky pro tři běhy jsou poměrně konzistentní, s ~2% rozdílem mezi minimem a maximem ve většině případů.
pouze pro čtení
U nejmenšího souboru dat je zřetelný pokles výkonu mezi 3,4 a 3,10 pro všechny počty klientů. Výsledky pro 16 klientů (čtyřnásobek počtu jader), ale více než se obnoví v 3.12.
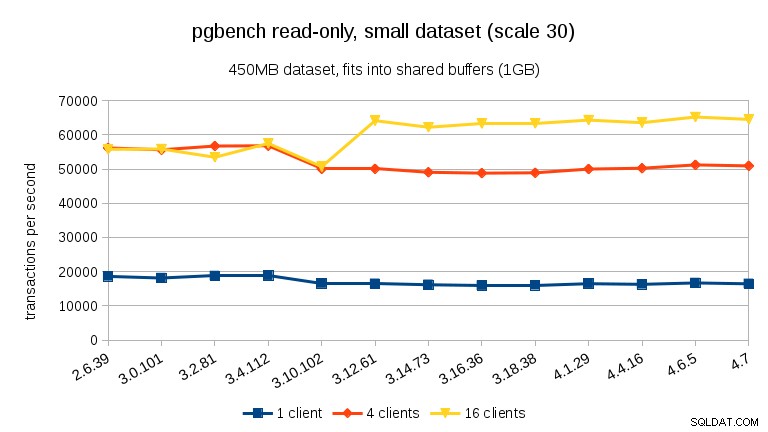
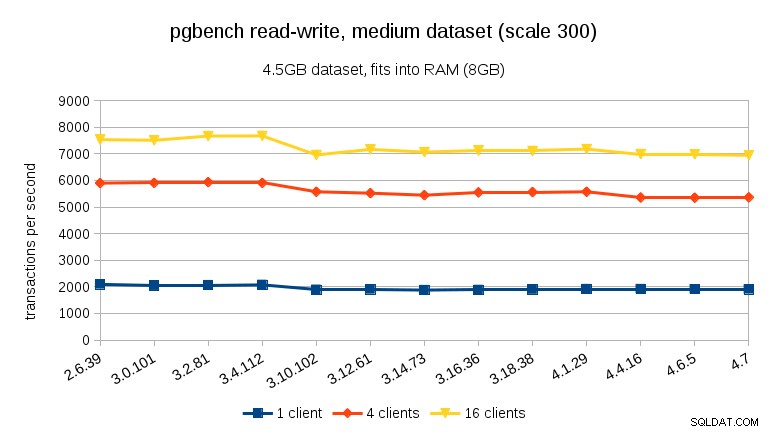
U střední datové sady (vejde se do RAM, ale ne do sdílených vyrovnávacích pamětí) můžeme vidět stejný pokles mezi 3.4 a 3.10, ale nikoli obnovu ve 3.12.
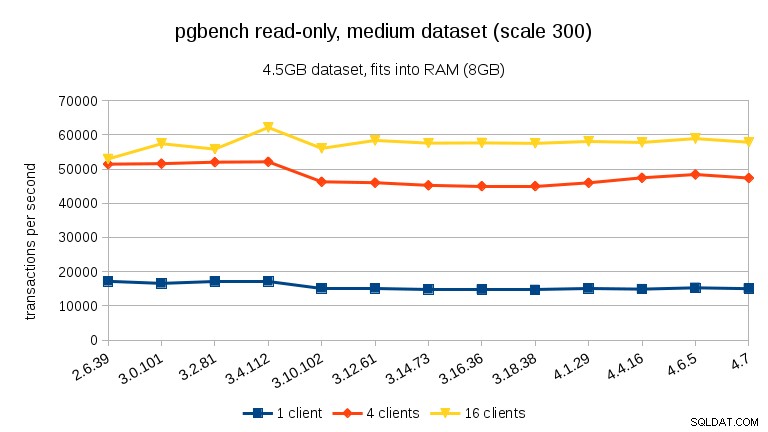
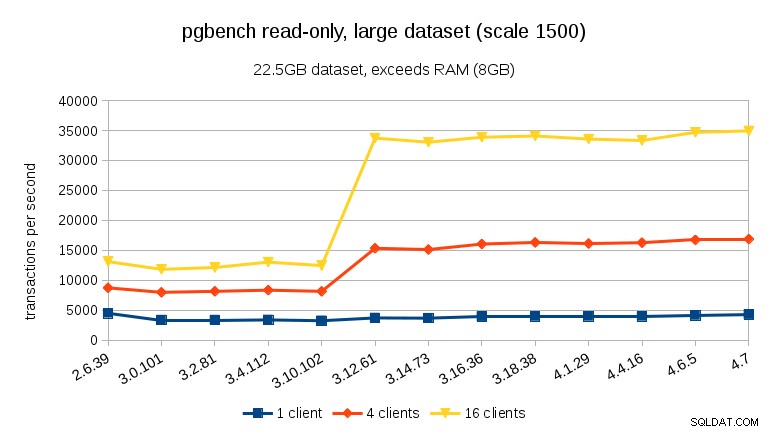
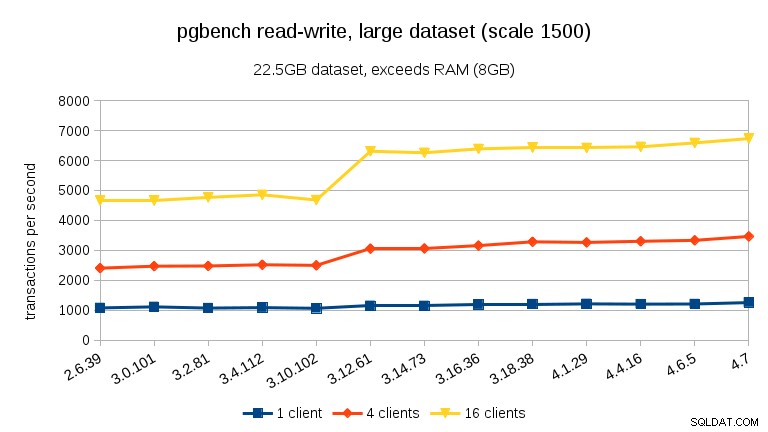
U velkých datových sad (přesahujících RAM, tak silně vázané na I/O) jsou výsledky velmi odlišné – nejsem si jistý, co se stalo mezi 3.10 a 3.12, ale zlepšení výkonu (zejména u vyššího počtu klientů) je docela ohromující.
čtení-zápis
U zátěže čtení a zápisu jsou výsledky dost podobné. U malých a středních souborů dat můžeme pozorovat stejný ~10% pokles mezi 3.4 a 3.10, ale bohužel žádné zotavení v 3.12.
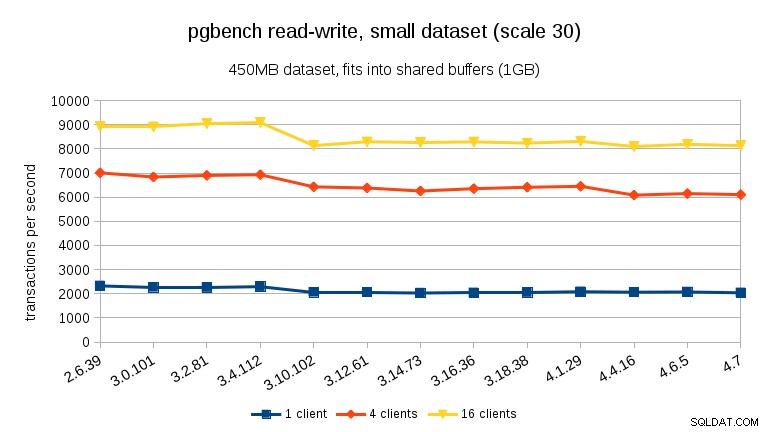
U velkého souboru dat (opět výrazně vázaných na I/O) můžeme vidět podobné zlepšení ve verzi 3.12 (ne tak významné jako u zátěže pouze pro čtení, ale stále významné):
Shrnutí
Netroufám si dělat závěry z jediného benchmarku na jednom počítači, ale myslím, že je bezpečné říci:
- Celkový výkon je poměrně stabilní, ale můžeme zaznamenat určité významné změny výkonu (v obou směrech).
- U souborů dat, které se vejdou do paměti (buď do sdílených vyrovnávací paměti nebo alespoň do RAM), vidíme měřitelný pokles výkonu mezi 3,4 a 3,10. Při testu pouze pro čtení se to částečně obnoví ve verzi 3.12 (ale pouze pro mnoho klientů).
- S datovými sadami přesahujícími paměť, a tedy primárně I/O vázané, nezaznamenáváme žádné takové poklesy výkonu, ale naopak výrazné zlepšení ve verzi 3.12.
Pokud jde o důvody, proč k těmto náhlým změnám dochází, nejsem si zcela jistý. Mezi verzemi existuje mnoho pravděpodobně relevantních commitů, ale nejsem si jistý, jak identifikovat ten správný bez rozsáhlého (a časově náročného) testování. Pokud máte jiné nápady (např. jste si vědomi takových závazků), dejte mi vědět.