PostgreSQL je úžasný projekt a vyvíjí se úžasnou rychlostí. Zaměříme se na vývoj schopností odolnosti proti chybám v PostgreSQL ve všech jeho verzích s řadou blogových příspěvků. Toto je čtvrtý příspěvek série a budeme hovořit o synchronním odevzdání a jeho účincích na odolnost vůči chybám a spolehlivost PostgreSQL.
Pokud byste chtěli být svědky pokroku ve vývoji od začátku, podívejte se prosím na první tři blogové příspěvky této série níže. Každý příspěvek je nezávislý, takže vlastně nemusíte číst jeden, abyste porozuměli druhému.
- Vývoj odolnosti vůči chybám v PostgreSQL
- Vývoj odolnosti vůči chybám v PostgreSQL:Replikační fáze
- Vývoj odolnosti vůči chybám v PostgreSQL:Cestování časem
Synchronní potvrzení
Ve výchozím nastavení PostgreSQL implementuje asynchronní replikaci, kde jsou data streamována, kdykoli je to pro server vhodné. To může znamenat ztrátu dat v případě selhání. Je možné požádat Postgres, aby vyžadoval jeden (nebo více) pohotovostních režimů pro potvrzení replikace dat před potvrzením, nazývá se to synchronní replikace (synchronní potvrzení ) .
U synchronní replikace se replikace zpožďuje přímo ovlivňuje uplynulý čas transakcí na hlavním serveru. S asynchronní replikací může hlavní server pokračovat plnou rychlostí.
Synchronní replikace zaručuje, že data budou zapsána nejméně dva uzly předtím, než je uživateli nebo aplikaci sděleno, že transakce byla potvrzena.
Uživatel si může vybrat režim potvrzení každé transakce , takže je možné mít synchronní i asynchronní transakce potvrzení spuštěné souběžně.
To umožňuje flexibilní kompromisy mezi výkonem a jistotou trvanlivosti transakce.
Konfigurace synchronního potvrzení
Pro nastavení synchronní replikace v Postgres musíme nakonfigurovat synchronous_commit parametr v postgresql.conf.
Parametr určuje, zda bude potvrzení transakce čekat na zapsání záznamů WAL na disk, než příkaz vrátí úspěch indikaci klientovi. Platné hodnoty jsou zapnuto , remote_apply , remote_write , místní a vypnuto . Probereme, jak věci fungují z hlediska synchronní replikace, když nastavíme synchronous_commit parametr s každou z definovaných hodnot.
Začněme dokumentací Postgres (9.6):
Zde rozumíme konceptu synchronního potvrzení, jak jsme popsali v úvodní části příspěvku, můžete si nastavit synchronní replikaci, ale pokud tak neučiníte, vždy existuje riziko ztráty dat. Ale bez rizika vytvoření nekonzistence databáze, na rozdíl od vypnutí fsync off – to je však téma na jiný příspěvek -. Nakonec dojdeme k závěru, že pokud potřebujeme, nechceme ztratit žádná data mezi zpožděními replikace a chceme si být jisti, žedata jsou zapsána alespoň do dvou uzlů předtím, než je uživatel/aplikace informována o potvrzení transakce , musíme se smířit se ztrátou určité výkonnosti.
Podívejme se, jak fungují různá nastavení pro různé úrovně synchronizace. Než začneme, promluvme si o tom, jak je commit zpracováván replikací PostgreSQL. Klient provádí dotazy na hlavním uzlu, změny se zapisují do protokolu transakcí (WAL) a přes síť se zkopírují do WAL v pohotovostním uzlu. Proces obnovy v pohotovostním uzlu pak načte změny z WAL a aplikuje je na datové soubory stejně jako při obnově po havárii. Pokud je pohotovostní režim v horkém pohotovostním režimu Během tohoto režimu mohou klienti na uzlu zadávat dotazy pouze pro čtení. Další podrobnosti o tom, jak replikace funguje, si můžete prohlédnout v příspěvku na blogu replikace v této sérii.
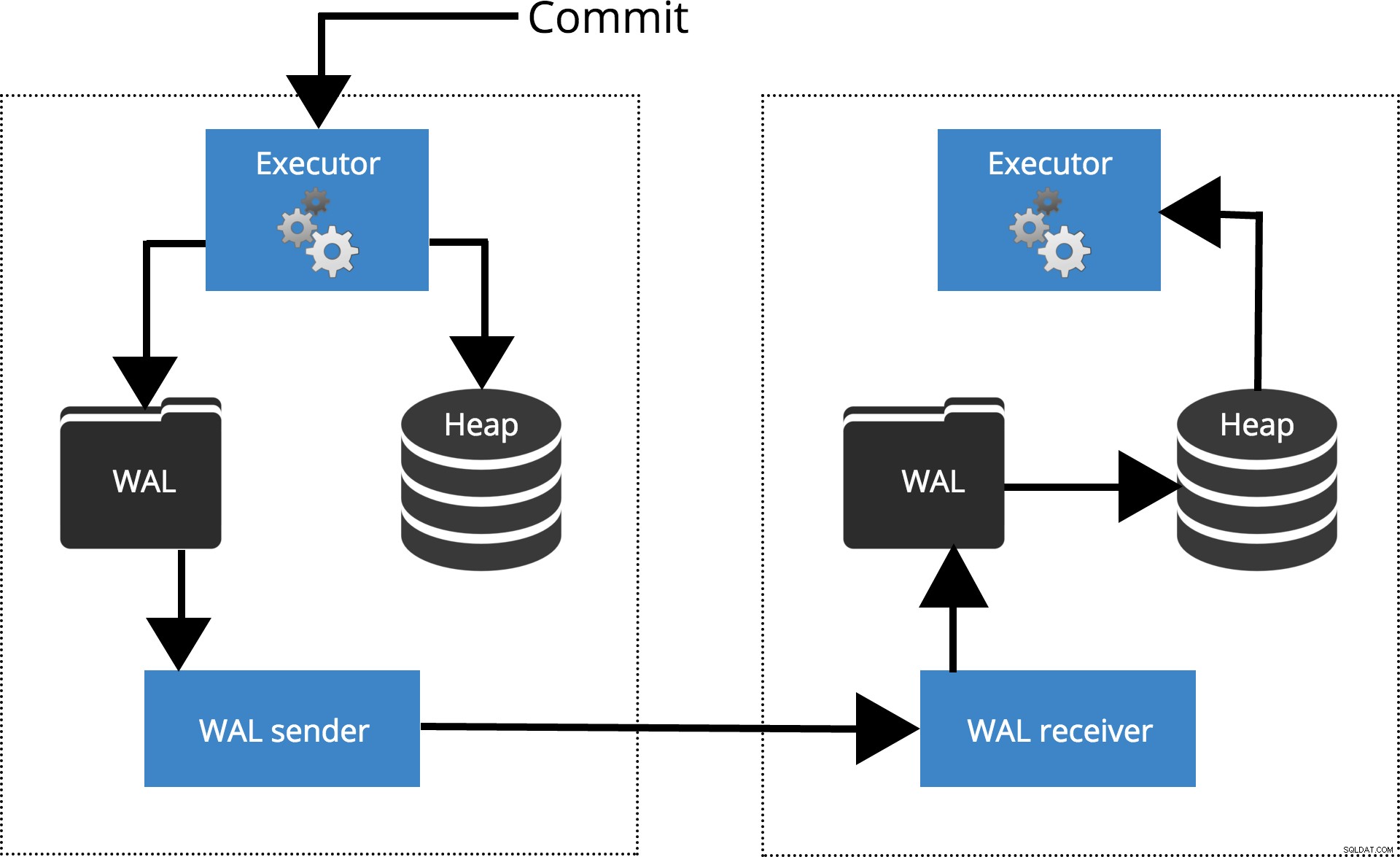
Obr.1 Jak funguje replikace
synchronous_commit =off
Když nastavíme sychronous_commit = off, COMMIT nečeká na vyprázdnění záznamu transakce na disk. To je zvýrazněno na obr. 2 níže.
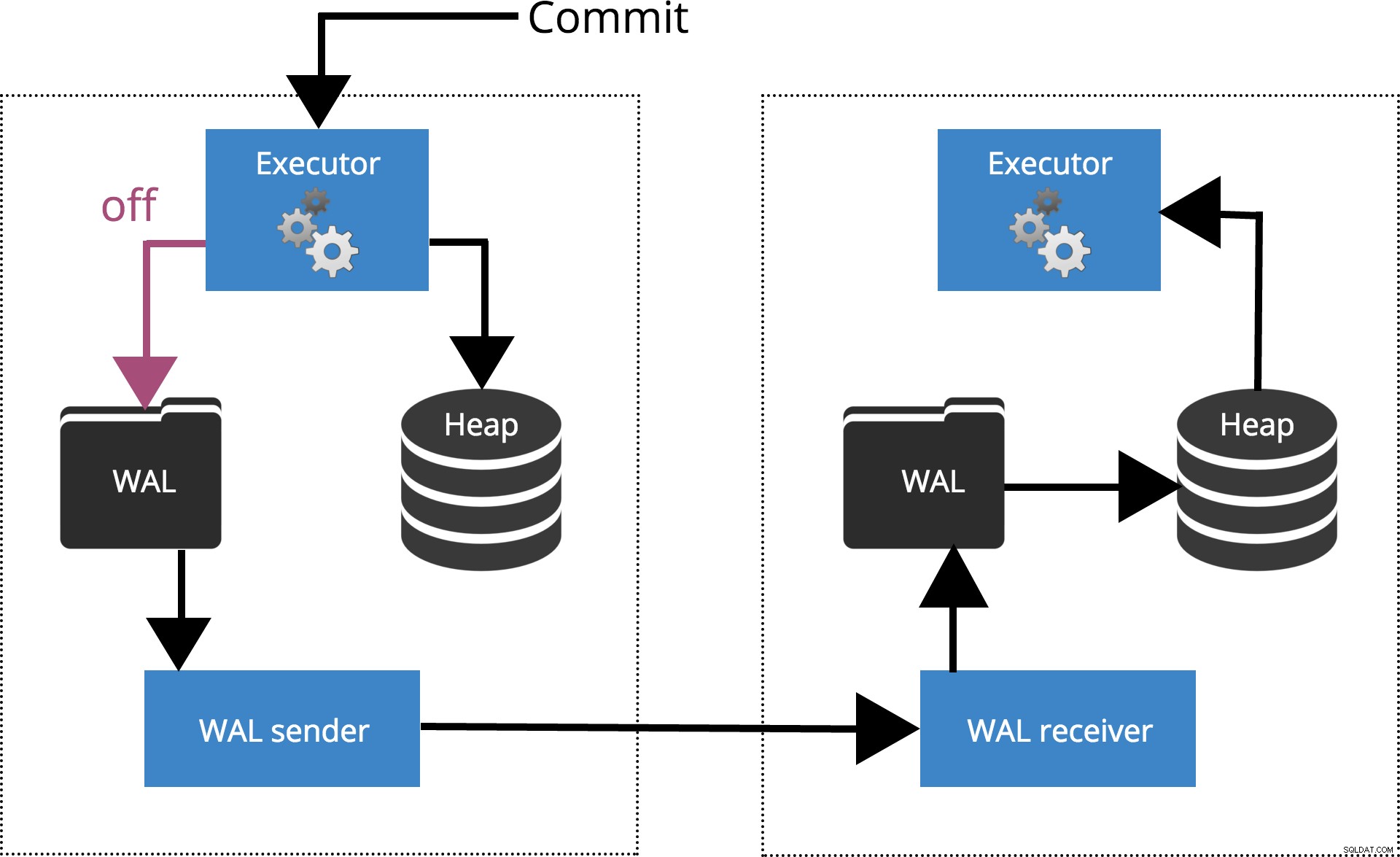
Obr. 2 synchronous_commit =off
synchronous_commit =local
Když nastavíme synchronous_commit = local, COMMIT čeká, dokud nebude záznam transakce vyprázdněn na místní disk. To je zvýrazněno na obr. 3 níže.
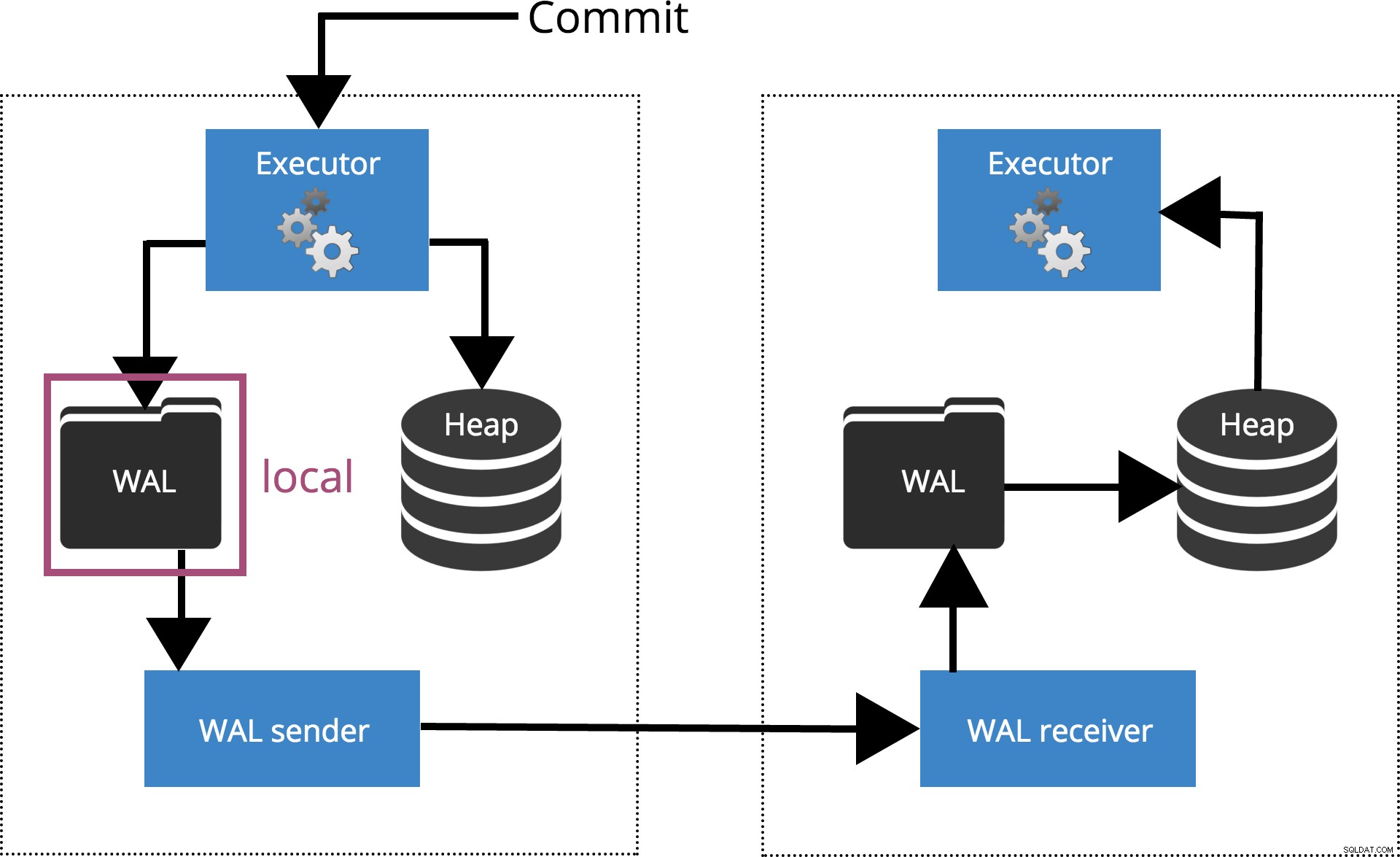
Obr.3 synchronous_commit =local
synchronous_commit =on (výchozí)
Když nastavíme synchronous_commit = on, COMMIT bude čekat, dokud server(y) nezadá synchronous_standby_names potvrďte, že záznam transakce byl bezpečně zapsán na disk. To je zvýrazněno na obr. 4 níže.
Poznámka: Když synchronous_standby_names je prázdné, toto nastavení se chová stejně jako synchronous_commit = local .
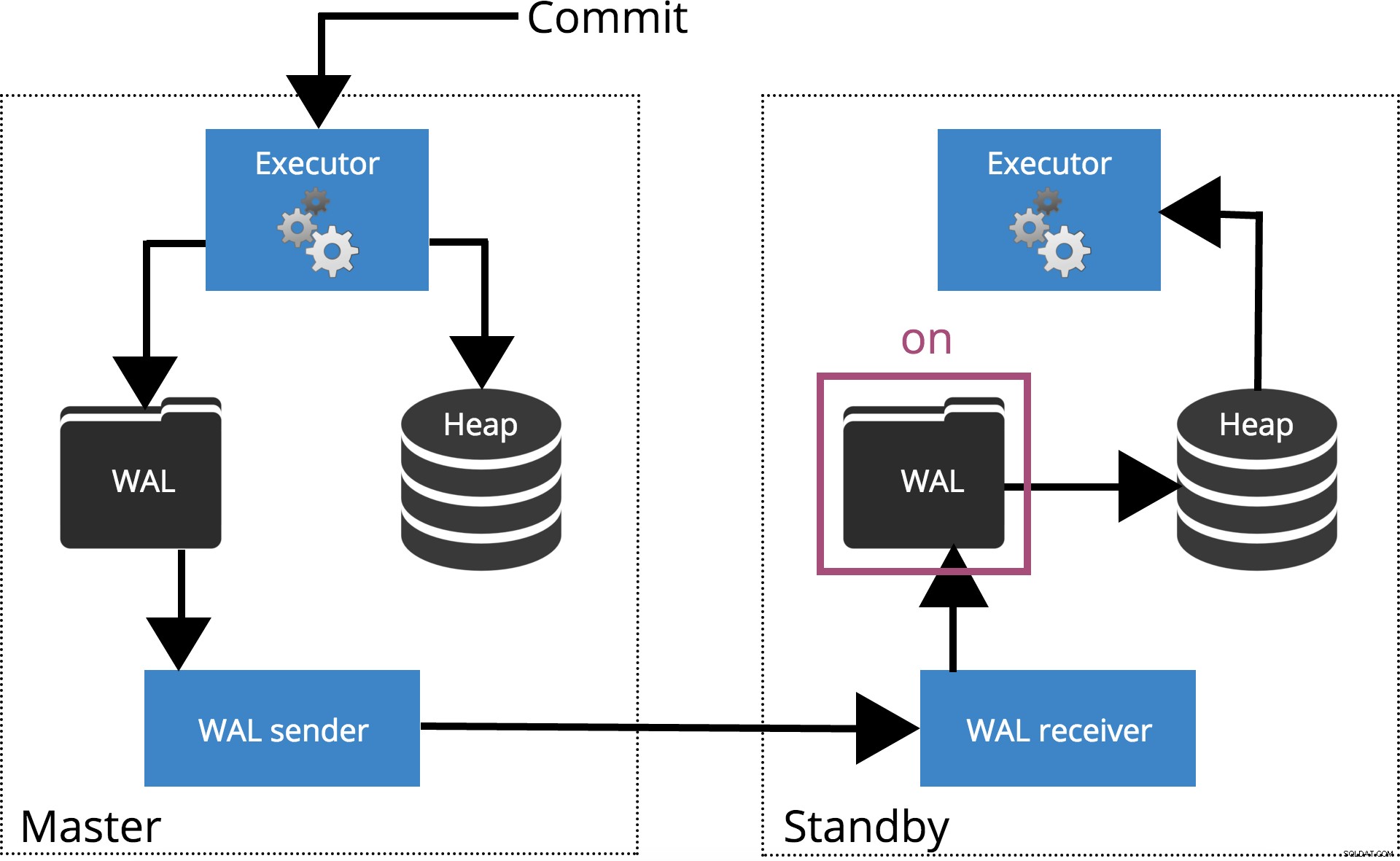
Obr. 4 synchronous_commit =on
synchronous_commit =remote_write
Když nastavíme synchronous_commit = remote_write, COMMIT bude čekat, dokud server(y) nezadá synchronous_standby_names potvrdit zápis záznamu transakce do operačního systému, ale nemusí se nutně dostat na disk. To je zvýrazněno na obr. 5 níže.
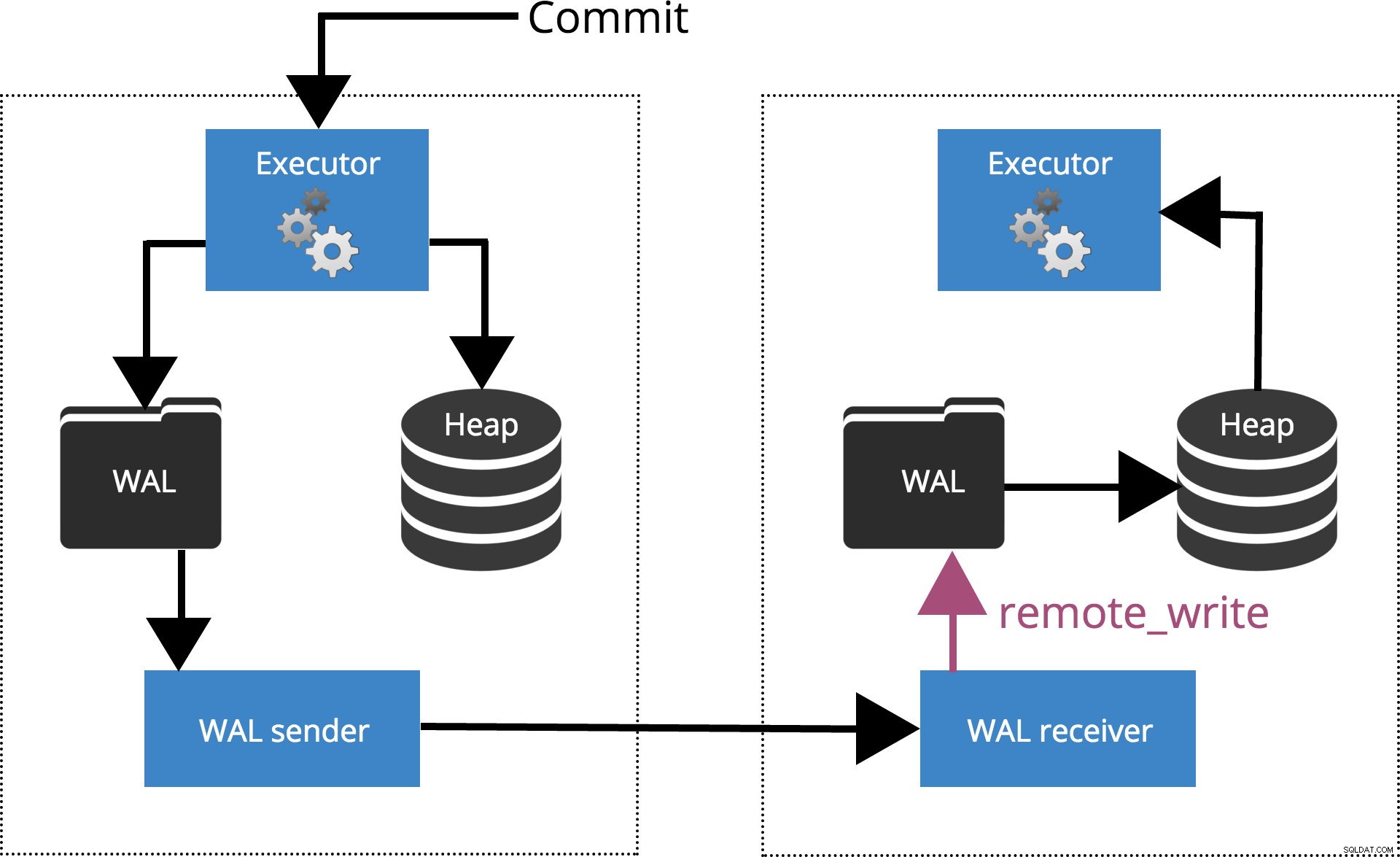
Obr.5 synchronous_commit =remote_write
synchronous_commit =remote_apply
Když nastavíme synchronous_commit = remote_apply, COMMIT bude čekat, dokud server(y) nezadá synchronous_standby_names potvrdit, že záznam transakce byl použit v databázi. To je zvýrazněno na obr. 6 níže.
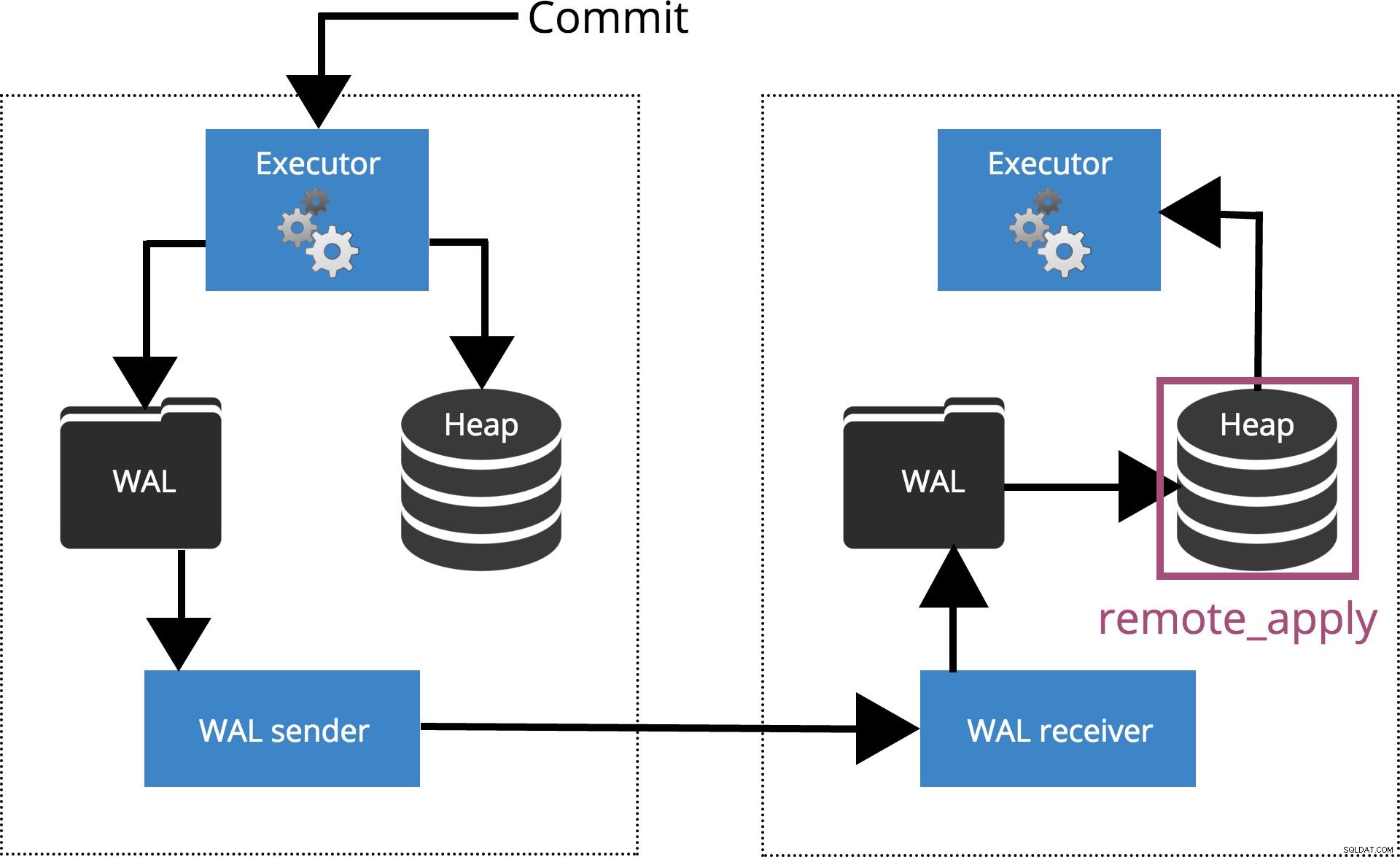
Obr. 6 synchronous_commit =remote_apply
Nyní se podívejme na sychronous_standby_names parametr podrobně, na který se odkazuje výše při nastavování synchronous_commit jako on , remote_apply nebo remote_write .
synchronous_standby_names =‚pohotovostní_název [, …]‘
Synchronní potvrzení bude čekat na odpověď z jednoho z pohotovostních režimů uvedených v pořadí priority. To znamená, že pokud je připojen první pohotovostní režim a streamuje se, synchronní odevzdání bude vždy čekat na odpověď od něj, i když druhý pohotovostní režim již odpověděl. Speciální hodnota * lze použít jako stanby_name který bude odpovídat jakémukoli připojenému pohotovostnímu režimu.
synchronous_standby_names =‘num (pohotovostní_název [, …])’
Synchronní odevzdání bude čekat na odpověď od alespoň num počet pohotovostních režimů uvedený v pořadí priority. Platí stejná pravidla jako výše. Například nastavení synchronous_standby_names = '2 (*)' synchronní odevzdání bude čekat na odpověď z libovolných 2 pohotovostních serverů.
synchronous_standby_names je prázdné
Pokud je tento parametr prázdný, jak je uvedeno, změní chování nastavení synchronous_commit do on , remote_write nebo remote_apply chovat se stejně jako local (tj. COMMIT bude čekat pouze na vyprázdnění na místní disk).
Závěr
V tomto blogovém příspěvku jsme diskutovali o synchronní replikaci a popsali různé úrovně ochrany, které jsou dostupné v Postgresu. V dalším příspěvku na blogu budeme pokračovat v logické replikaci.
Odkazy
Zvláštní poděkování patří mému kolegovi Petru Jelínkovi za nápad na ilustrace.
Dokumentace PostgreSQL
Administrační kuchařka PostgreSQL 9 – druhé vydání