PostgreSQL je úžasný projekt a vyvíjí se úžasnou rychlostí. Zaměříme se na vývoj schopností odolnosti proti chybám v PostgreSQL ve všech jeho verzích s řadou blogových příspěvků. Toto je třetí příspěvek série a budeme hovořit o problémech s časovou osou a jejich účincích na odolnost vůči chybám a spolehlivost PostgreSQL.
Pokud byste chtěli být svědky pokroku ve vývoji od začátku, podívejte se prosím na první dva blogové příspěvky série:
- Vývoj odolnosti vůči chybám v PostgreSQL
- Vývoj odolnosti vůči chybám v PostgreSQL:Replikační fáze

Časové osy
Schopnost obnovit databázi do předchozího bodu v čase vytváří určité složitosti, které některé případy pokryjeme vysvětlením failover (obr. 1), přepínač (obr. 2) a pg_rewind (obr. 3) případy dále v tomto tématu.
Například v původní historii databáze předpokládejme, že jste v úterý večer v 17:15 zahodili kritickou tabulku, ale svou chybu jste si uvědomili až ve středu v poledne. Bez obav vytáhnete zálohu, obnovíte se k bodu v čase v úterý večer v 17:14 a vše funguje. V této historii databázového vesmíru jste nikdy neupustili tabulku. Ale předpokládejme, že si později uvědomíte, že to nebyl tak skvělý nápad, a rádi byste se vrátili někdy ve středu ráno do původní historie. Nebudete moci, pokud během provozu databáze přepíše některé soubory segmentů WAL, které vedly do doby, do které se nyní chcete vrátit.
Abyste tomu zabránili, musíte odlišit řadu záznamů WAL vygenerovaných poté, co jste provedli obnovu v určitém okamžiku, od těch, které byly vygenerovány v původní historii databáze.
Pro řešení tohoto problému má PostgreSQL pojem časové osy. Kdykoli se dokončí obnova archivu, vytvoří se nová časová osa k identifikaci série záznamů WAL vygenerovaných po této obnově. ID časové osy je součástí názvů souborů segmentů WAL, takže nová časová osa nepřepíše data WAL vygenerovaná předchozími časovými osami. Ve skutečnosti je možné archivovat mnoho různých časových os.
Zvažte situaci, kdy si nejste zcela jisti, do kterého bodu v čase se zotavit, a tak musíte provést několik obnovení v určitém čase metodou pokusu a omylu, dokud nenajdete nejlepší místo, kde se oddělit od staré historie. Bez časových os by tento proces brzy vytvořil neovladatelný nepořádek. Pomocí časových os se můžete vrátit do jakéhokoli předchozího stavu, včetně stavů ve větvích časové osy, které jste opustili dříve.
Pokaždé, když je vytvořena nová časová osa, PostgreSQL vytvoří soubor „historie časové osy“, který ukazuje, ze které časové osy se větvila a kdy. Tyto soubory historie jsou nezbytné, aby umožnily systému vybrat správné soubory segmentů WAL při obnově z archivu, který obsahuje více časových os. Proto jsou archivovány do oblasti archivu WAL stejně jako soubory segmentů WAL. Soubory historie jsou pouze malé textové soubory, takže je levné a vhodné je uchovávat po neomezenou dobu (na rozdíl od segmentových souborů, které jsou velké). Pokud chcete, můžete do souboru historie přidávat komentáře, abyste zaznamenali své vlastní poznámky o tom, jak a proč byla tato konkrétní časová osa vytvořena. Takové komentáře budou obzvláště cenné, když budete mít jako výsledek experimentování houšť různých časových os.
Výchozím chováním obnovy je obnova ve stejné časové ose, která byla aktuální, když byla pořízena základní záloha. Pokud se chcete obnovit do nějaké podřízené časové osy (to znamená, že se chcete vrátit do nějakého stavu, který byl sám vygenerován po pokusu o obnovu), musíte zadat ID cílové časové osy v recovery.conf. Nelze obnovit do časových os, které se rozvětvovaly dříve než základní záloha.
Pro zjednodušení konceptu časových os v PostgreSQL problémy související s časovou osou v případě failoveru , přepnutí a pg_rewind jsou shrnuty a vysvětleny na obr. 1, obr. 2 a obr. 3.
Scénář převzetí služeb při selhání:
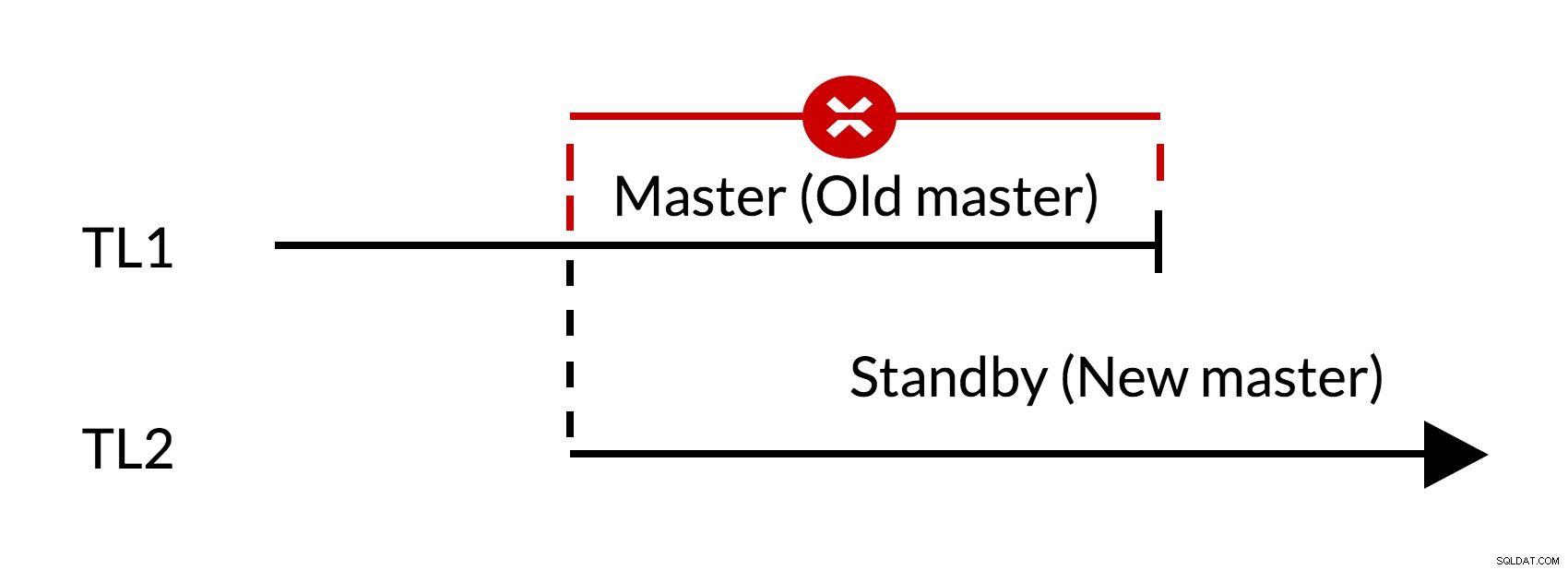
Obr. 1 Failover
- Ve staré předloze (TL1) jsou výrazné změny
- Zvýšení časové osy představuje novou historii změn (TL2)
- Změny ze staré časové osy nelze znovu přehrát na serverech, které přešly na novou časovou osu
- Starý mistr nemůže následovat nového předlohy
Scénář přepnutí:
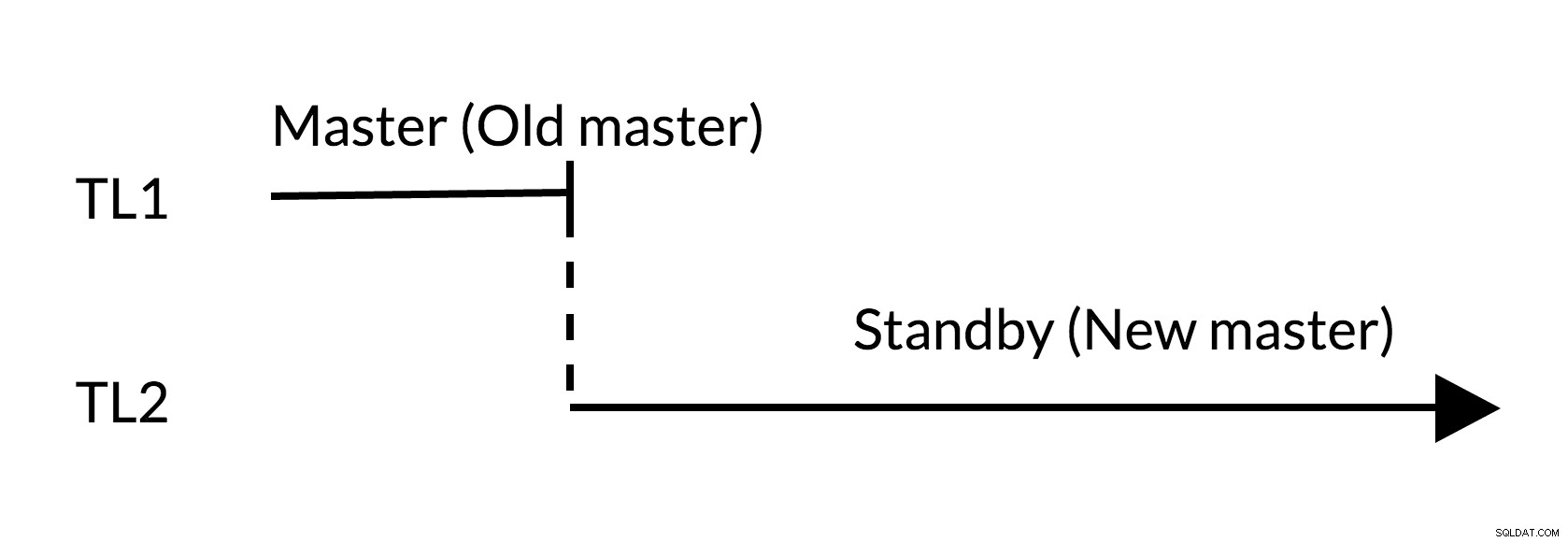 Obr. 2 Přepnutí
Obr. 2 Přepnutí
- Ve staré předloze (TL1) nejsou žádné nevyřízené změny
- Zvýšení časové osy představuje novou historii změn (TL2)
- Stará předloha se může stát pohotovostním pro novou předlohu
scénář pg_rewind:
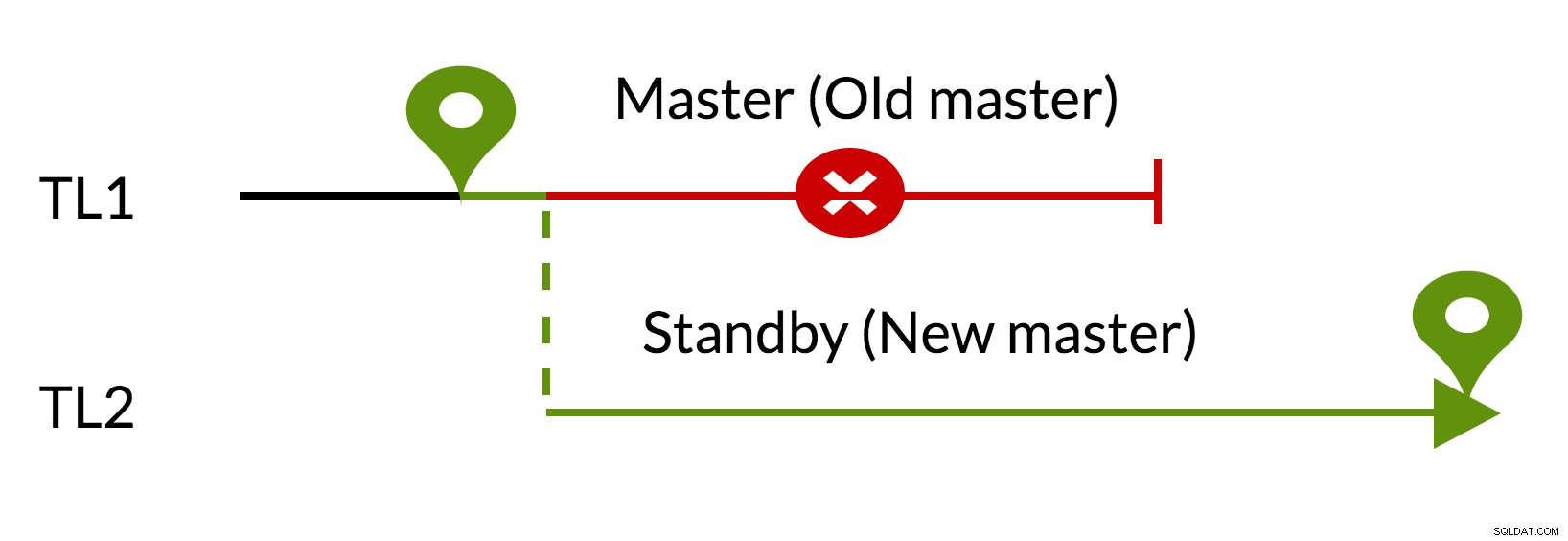 Obr.3 pg_rewind
Obr.3 pg_rewind
- Nevyřízené změny jsou odstraněny pomocí dat z nového hlavního serveru (TL1)
- Stará předloha může následovat novou předlohu (TL2)
pg_rewind
pg_rewind je nástroj pro synchronizaci clusteru PostgreSQL s jinou kopií stejného clusteru poté, co se časové osy clusterů rozcházejí. Typickým scénářem je uvést starý hlavní server po převzetí služeb při selhání zpět do režimu online jako pohotovostní režim, který následuje po novém hlavním serveru.
Výsledek je ekvivalentní nahrazení cílového datového adresáře zdrojovým. Všechny soubory jsou zkopírovány, včetně konfiguračních souborů. Výhodou pg_rewind oproti pořízení nové základní zálohy nebo nástrojů jako rsync je, že pg_rewind nevyžaduje čtení všech nezměněných souborů v clusteru. Díky tomu je mnohem rychlejší, když je databáze velká a pouze její malá část se mezi shluky liší.
Jak to funguje?
Základní myšlenkou je zkopírovat vše z nového clusteru do starého clusteru, kromě bloků, o kterých víme, že jsou stejné.
- Naskenujte protokol WAL starého clusteru, počínaje posledním kontrolním bodem před bodem, kde se historie časové osy nového clusteru oddělila od starého clusteru. Pro každý záznam WAL si poznamenejte bloky dat, kterých jste se dotkli. Získáte tak seznam všech datových bloků, které byly změněny ve starém clusteru poté, co se nový cluster rozdělil.
- Zkopírujte všechny změněné bloky z nového clusteru do starého clusteru.
- Zkopírujte všechny ostatní soubory, jako jsou blokovací a konfigurační soubory, z nového clusteru do starého clusteru, vše kromě souborů vztahů.
- Použijte WAL z nového clusteru, počínaje kontrolním bodem vytvořeným při převzetí služeb při selhání. (Přísně vzato, pg_rewind nepoužije WAL, pouze vytvoří záložní soubor se štítkem, který značí, že po spuštění PostgreSQL začne přehrávání od tohoto kontrolního bodu a použije všechny požadované WAL.)
Poznámka: Aby pg_rewind mohl fungovat, musí být v postgresql.conf nastaven wal_log_hints. Tento parametr lze nastavit pouze při spuštění serveru. Výchozí hodnota je vypnuto .
Závěr
V tomto blogovém příspěvku jsme diskutovali o časových osách v Postgres a o tom, jak řešíme případy převzetí služeb při selhání a přepnutí. Také jsme hovořili o tom, jak pg_rewind funguje a jeho přínosy pro odolnost vůči chybám a spolehlivost Postgresu. V dalším příspěvku na blogu budeme pokračovat se synchronním potvrzením.
Odkazy
Dokumentace PostgreSQL
Administrační kuchařka PostgreSQL 9 – druhé vydání
pg_rewind Prezentace Nordic PGDay od Heikki Linnakangas