Recovery Time Objective (RTO) je časové období, během kterého musí být služba obnovena, aby se předešlo nepřijatelným následkům. Výpočtem, jak dlouho může trvat zotavení po selhání databáze, můžeme vědět, jakou úroveň přípravy vyžaduje. Trvá-li RTO několik minut, je nutná značná investice do převzetí služeb při selhání. RTO 36 hodin vyžaduje výrazně nižší investici. Zde přichází na řadu automatizace převzetí služeb při selhání.
V našich předchozích blozích jsme diskutovali o převzetí služeb při selhání pro MongoDB, MySQL/MariaDB/Percona, PostgreSQL nebo TimeScaleDB. Abych to shrnul, „Failover " je schopnost systému pokračovat v činnosti, i když dojde k nějaké poruše. To naznačuje, že funkce systému přebírají sekundární komponenty, pokud primární komponenty selžou. Přepnutí při selhání je přirozenou součástí každého systému s vysokou dostupností a v některých případech musí být dokonce automatizován. Manuální převzetí služeb při selhání trvá příliš dlouho, ale existují případy, kdy automatizace nebude fungovat dobře – například v případě rozděleného mozku, kdy je replikace databáze přerušena a obě „poloviny“ stále dostávají aktualizace, efektivně což vede k odlišným souborům dat a nekonzistentnosti.
Již dříve jsme psali o hlavních principech automatického převzetí služeb při selhání ClusterControl. Tam, kde je to možné, poskytuje automatizované převzetí služeb při selhání efektivitu, protože umožňuje rychlé zotavení po selhání. V tomto blogu se podíváme na to, jak dosáhnout automatického převzetí služeb při selhání v nastavení replikace master-slave (nebo primární-standby) pomocí ClusterControl.
Požadavky na sadu technologií
Zásobník lze sestavit z komponent Open Source Software a existuje řada dostupných možností – některé jsou vhodnější než jiné v závislosti na charakteristikách převzetí služeb při selhání a také na úrovni odborných znalostí dostupných pro správu a údržbu řešení. Hardware a síť jsou také důležité aspekty.
Software
V ekosystému s otevřeným zdrojovým kódem je k dispozici spousta možností, které můžete použít k implementaci převzetí služeb při selhání. Pro MySQL můžete využít MHA, MMM, Maxscale/MRM, mysqlfailover nebo Orchestrator. Tento předchozí blog porovnává MaxScale s MHA a Maxscale/MRM. PostgreSQL má repmgr, Patroni, PostgreSQL Automatic Failover (PAF), pglookout, pgPool-II nebo stolon. Tyto různé možnosti vysoké dostupnosti byly pokryty dříve. MongoDB má sady replik s podporou automatického převzetí služeb při selhání.
ClusterControl poskytuje funkci automatického převzetí služeb při selhání pro MySQL, MariaDB, PostgreSQL a MongoDB, kterým se budeme věnovat dále. Stojí za zmínku, že má také funkci pro automatickou obnovu poškozených uzlů nebo clusterů.
Hardware
Automatické převzetí služeb při selhání je obvykle prováděno samostatným démonovým serverem, který je nastaven na vlastním hardwaru – odděleně od databázových uzlů. Sleduje stav databází a využívá informace k rozhodování o tom, jak reagovat v případě selhání.
Komoditní servery mohou fungovat dobře, pokud server nemonitoruje velké množství instancí. Obvykle jsou kontroly systému a analýza stavu z hlediska zpracování nenáročné. Pokud však máte ke kontrole velký počet uzlů, velký procesor a paměť jsou nutností, zvláště když kontroly musí být řazeny do fronty, protože se pokouší ping a shromažďovat informace ze serverů. Uzly, které jsou monitorovány a dohlíženy, se mohou někdy zastavit kvůli problémům se sítí, vysoké zátěži nebo v horším případě mohou být mimo provoz kvůli selhání hardwaru nebo poškození hostitele virtuálního počítače. Server, který spouští kontroly stavu a systému, by tedy měl být schopen odolat takovým zastavením, protože je pravděpodobné, že zpracování front může narůstat, protože odezvy na každý ze sledovaných uzlů mohou chvíli trvat, než se ověří, že již není k dispozici nebo vypršel časový limit. bylo dosaženo.
Pro cloudová prostředí existují služby, které nabízejí automatické převzetí služeb při selhání. Například Amazon RDS používá DRBD k replikaci úložiště do pohotovostního uzlu. Nebo pokud ukládáte své svazky v EBS, jsou replikovány ve více zónách.
Síť
Automatizovaný software pro převzetí služeb při selhání často spoléhá na agenty, kteří jsou nastaveni na uzlech databáze. Agent shromažďuje informace lokálně z instance databáze a na požádání je odesílá na server.
Pokud jde o požadavky na síť, ujistěte se, že máte dobrou šířku pásma a stabilní připojení k síti. Kontroly je třeba provádět často a zmeškané srdeční tepy kvůli nestabilní síti mohou vést k tomu, že software pro přepnutí při selhání (nesprávně) vydedukuje, že uzel je mimo provoz.
ClusterControl nevyžaduje na databázových uzlech nainstalovaného žádného agenta, protože v pravidelných intervalech provádí SSH do každého databázového uzlu a provádí řadu kontrol.
Automatické převzetí služeb při selhání s ClusterControl
ClusterControl nabízí možnost provádět manuální i automatizovaná převzetí služeb při selhání. Podívejme se, jak to lze provést.
Failover v ClusterControl lze nakonfigurovat tak, aby byl automatický nebo ne. Pokud se raději staráte o převzetí služeb při selhání ručně, můžete zakázat automatické obnovení clusteru. Při ručním převzetí služeb při selhání můžete přejít na Cluster → Topologie v ClusterControl. Viz snímek obrazovky níže:
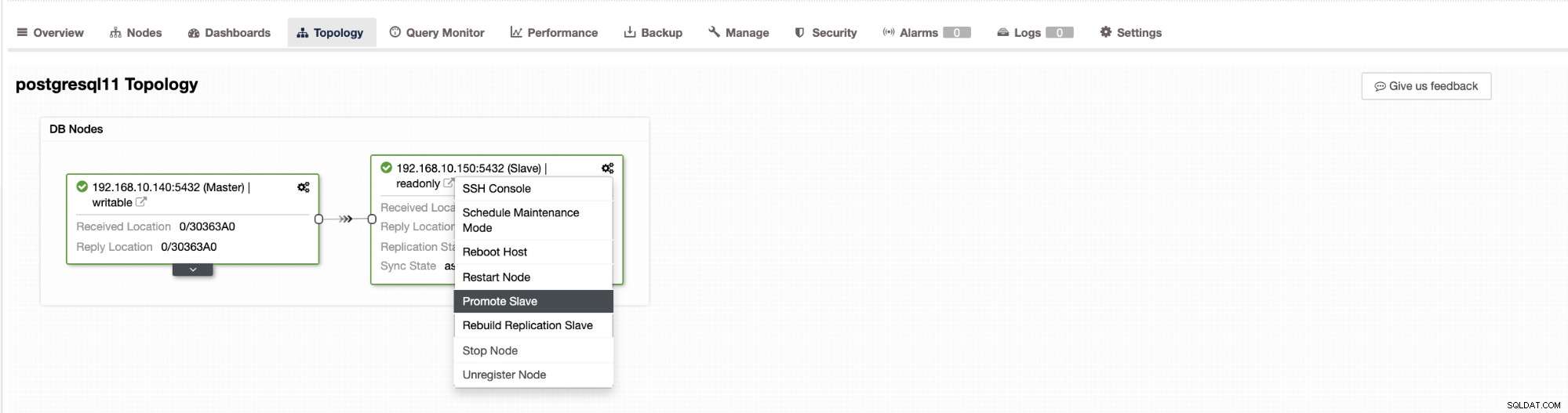
Ve výchozím nastavení je obnovení clusteru povoleno a používá se automatické převzetí služeb při selhání. Jakmile provedete změny v uživatelském rozhraní, konfigurace běhového prostředí se změní. Pokud chcete, aby nastavení přežilo restart ovladače, ujistěte se, že jste provedli také změnu v konfiguraci cmon, tj. /etc/cmon.d/cmon_

Na serveru MySQL/MariaDB/Percona zahájí ClusterControl automatické převzetí služeb při selhání, když zjistí, že neexistuje žádný hostitel s pouze pro čtení příznak zakázán. Může se to stát, protože master (který má pouze pro čtení nastavena na 0) není dostupná nebo ji může spustit uživatel nebo nějaký externí software, který změnil tento příznak na masteru. Pokud provádíte ruční změny uzlů databáze nebo máte software, který si může pohrát s nastavením pouze pro čtení, měli byste zakázat automatické převzetí služeb při selhání. O automatické převzetí služeb při selhání ClusterControl se pokusí pouze jednou, proto po neúspěšném převzetí služeb při selhání nebude následovat další převzetí služeb při selhání - až po restartování cmon.
Pro PostgreSQL vybere ClusterControl nejpokročilejšího slave, přičemž k tomuto účelu použije pg_current_xlog_location (PostgreSQL 9+) nebo pg_current_wal_lsn (PostgreSQL 10+) v závislosti na verzi naší databáze. ClusterControl také provádí několik kontrol procesu převzetí služeb při selhání, aby se zabránilo některým běžným chybám. Jedním příkladem je, že pokud se nám podaří obnovit našeho starého neúspěšného mistra, „nebude " být znovu automaticky zaveden do clusteru, ani jako hlavní, ani jako podřízený. Musíme to udělat ručně. Vyhneme se tak možnosti ztráty dat nebo nekonzistentnosti v případě, že náš podřízený (kterého jsme povýšili) byl v tu dobu zpožděn Můžeme také chtít problém podrobně analyzovat, než jej znovu zavedeme do nastavení replikace, takže bychom chtěli zachovat diagnostické informace.
Také pokud selže převzetí služeb při selhání, nejsou prováděny žádné další pokusy (to platí pro clustery založené na PostgreSQL i MySQL), je nutný ruční zásah k analýze problému a provedení odpovídajících akcí. Je to proto, aby se zabránilo situaci, kdy se ClusterControl, který zpracovává automatické převzetí služeb při selhání, pokusí povýšit další slave a další. Může nastat problém a my nechceme situaci zhoršovat pokusy o vícenásobné převzetí služeb při selhání.
ClusterControl nabízí whitelisting a blacklisting sady serverů, které se chcete zúčastnit převzetí služeb při selhání nebo vyloučit jako kandidáty.
Pro clustery typu MySQL vytváří ClusterControl seznam slave, které lze povýšit na master. Většinu času bude obsahovat všechny slave v topologii, ale uživatel má nad tím nějakou další kontrolu. V konfiguraci cmon můžete nastavit dvě proměnné:
replication_failover_whitelista
replication_failover_blacklistPro konfigurační proměnnou replication_failover_whitelist obsahuje seznam IP nebo názvů hostitelů slave, které by měly být použity jako potenciální hlavní kandidáti. Pokud je tato proměnná nastavena, budou uvažováni pouze tito hostitelé. Proměnná replikace_failover_blacklist obsahuje seznam hostitelů, kteří nikdy nebudou považováni za hlavního kandidáta. Můžete jej použít k zobrazení seznamu podřízených jednotek, které se používají pro zálohování nebo analytické dotazy. Pokud se hardware mezi podřízenými zařízeními liší, můžete sem umístit podřízené jednotky, které používají pomalejší hardware.
replication_failover_whitelist má přednost, což znamená, že replication_failover_blacklist je ignorován, pokud je nastaven replication_failover_whitelist.
Jakmile je připraven seznam podřízených jednotek, které mohou být povýšeny na hlavní, začne ClusterControl porovnávat jejich stav a hledat nejaktuálnější podřízené jednotky. Zde se zacházení s nastaveními MariaDB a MySQL liší. Pro nastavení MariaDB vybere ClusterControl slave zařízení, které má nejnižší zpoždění replikace ze všech dostupných slave zařízení. Pro nastavení MySQL ClusterControl také vybere takového slave, ale poté zkontroluje další chybějící transakce, které by mohly být provedeny na některých zbývajících slave. Pokud je taková transakce nalezena, ClusterControl podřídí hlavního kandidáta tomuto hostiteli, aby načetl všechny chybějící transakce. Tento proces můžete přeskočit a jednoduše použít nejpokročilejšího slave nastavením proměnné replication_skip_apply_missing_txs v konfiguraci CMON:
např.
replication_skip_apply_missing_txs=1Další informace o proměnných naleznete v naší dokumentaci zde.
Upozornění je, že toto musíte nastavit pouze v případě, že víte, co děláte, protože může docházet k chybným transakcím. Ty mohou způsobit přerušení replikace a také nekonzistenci dat v celém clusteru. Pokud k chybné transakci došlo v minulosti, nemusí již být k dispozici v binárních protokolech. V takovém případě se replikace přeruší, protože podřízení nebudou schopni získat chybějící data. Proto ClusterControl ve výchozím nastavení kontroluje všechny chybné transakce, než povýší hlavního kandidáta, aby se stal hlavním. Pokud je takový problém detekován, hlavní přepínač se přeruší a ClusterControl umožní uživateli opravit problém ručně.
Pokud si chcete být 100% jisti, že ClusterControl podpoří nový master, i když budou zjištěny nějaké problémy, můžete to udělat pomocí proměnné replication_stop_on_error. Viz níže:
např.
replication_stop_on_error=0Nastavte tuto proměnnou v konfiguračním souboru cmon. Jak již bylo zmíněno dříve, může to vést k problémům s replikací, protože podřízení mohou začít žádat o událost binárního protokolu, která již není dostupná. Abychom takové případy zvládli, přidali jsme experimentální podporu pro přestavbu otroků. Pokud nastavíte proměnnou
replication_auto_rebuild_slave=1v konfiguraci cmon a pokud je váš slave označen jako down s následující chybou v MySQL:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'ClusterControl se pokusí znovu sestavit podřízenou jednotku pomocí dat z hlavní jednotky. Takové nastavení nemusí být vždy vhodné, protože proces přestavby způsobí zvýšené zatížení masteru. Může se také stát, že vaše datová sada je velmi velká a pravidelná přestavba nepřipadá v úvahu – proto je toto chování ve výchozím nastavení zakázáno.
Jakmile se ujistíme, že žádná chybná transakce neexistuje a můžeme vyrazit, je tu ještě jeden problém, který musíme nějak vyřešit – může se stát, že všichni otroci zaostávají za pánem.
Jak asi víte, replikace v MySQL funguje poměrně jednoduchým způsobem. Hlavní ukládá zápisy do binárních protokolů. I/O vlákno podřízeného zařízení se připojí k hlavnímu zařízení a stáhne všechny chybějící události binárního protokolu. Poté je ukládá ve formě protokolů relé. Vlákno SQL je analyzuje a aplikuje události. Slave lag je stav, ve kterém se SQL vlákno (nebo vlákna) nedokáže vyrovnat s množstvím událostí a není schopno je použít, jakmile jsou I/O vláknem staženy z hlavního serveru. Taková situace může nastat bez ohledu na to, jaký typ replikace používáte. I když použijete semisynchronní replikaci, může zaručit pouze to, že všechny události z hlavní jednotky budou uloženy na jedné z podřízených jednotek v protokolu přenosu. Neříká nic o aplikaci těchto událostí na otroka.
Problém je v tom, že pokud je slave povýšen na master, reléové protokoly budou vymazány. Pokud se slave zařízení zpožďuje a neaplikovalo všechny transakce, ztratí data – události, které ještě nebyly použity z protokolů přenosu, budou navždy ztraceny.
Neexistuje žádný univerzální způsob, jak tuto situaci vyřešit. ClusterControl poskytuje uživatelům kontrolu nad tím, jak by to mělo být provedeno, a udržuje bezpečné výchozí hodnoty. Provádí se v konfiguraci cmon pomocí následujícího nastavení:
replication_failover_wait_to_apply_timeout=-1Ve výchozím nastavení má hodnotu „-1“, což znamená, že k převzetí služeb při selhání nedojde okamžitě, pokud hlavní kandidát zaostává, takže je nastaveno, že bude čekat věčně, pokud kandidát nedohoní. ClusterControl bude čekat neomezeně dlouho, než použije všechny chybějící transakce z protokolů přenosu. To je bezpečné, ale pokud z nějakého důvodu nejnovější slave špatně zaostává, dokončení převzetí služeb při selhání může trvat hodiny. Na druhé straně spektra je nastavení na „0“ – to znamená, že k převzetí služeb při selhání dojde okamžitě, bez ohledu na to, zda hlavní kandidát zaostává nebo ne. Můžete také jít střední cestou a nastavit ji na nějakou hodnotu. Tím nastavíte čas v sekundách, například 30 sekund, takže nastavte proměnnou na,
replication_failover_wait_to_apply_timeout=30Když je nastaveno na> 0, ClusterControl bude čekat, až hlavní kandidát použije chybějící transakce ze svých přenosových protokolů, dokud nebude splněna hodnota (což je v příkladu 30 sekund). K převzetí služeb při selhání dojde po definované době nebo když hlavní kandidát dohoní replikaci, podle toho, co nastane dříve. To může být dobrá volba, pokud má vaše aplikace specifické požadavky týkající se prostojů a musíte během krátké doby zvolit nového hlavního serveru.
Další podrobnosti o tom, jak ClusterControl funguje s automatickým převzetím služeb při selhání v PostgreSQL a MySQL, najdete v našich předchozích blozích s názvem „Přepnutí při selhání pro PostgreSQL Replication 101“ a „Automatické převzetí služeb při selhání replikace MySQL – novinka v ClusterControl 1.4“.
Závěr
Automated Failover je cenná funkce, zejména pro podniky, které vyžadují nepřetržitý provoz s minimálními prostoji. Podnik musí definovat, do jaké míry je proces automatizace předán řízení během neplánovaných výpadků. Řešení s vysokou dostupností, jako je ClusterControl, nabízí přizpůsobitelnou úroveň interakce při zpracování převzetí služeb při selhání. Pro některé organizace nemusí být automatické převzetí služeb při selhání možné, i když interakce uživatele během převzetí služeb při selhání může spotřebovat čas a ovlivnit RTO. Předpokladem je, že je příliš riskantní v případě, že automatizované převzetí služeb při selhání nefunguje správně, nebo, což je ještě horší, má za následek změť a částečnou ztrátu dat (ačkoli by se dalo namítnout, že katastrofální chyby vedoucí k podobným následkům může udělat i člověk). Ti, kteří dávají přednost těsné kontrole nad svou databází, se mohou rozhodnout vynechat automatické převzetí služeb při selhání a místo toho použít ruční proces. Takový proces trvá déle, ale umožňuje zkušenému správci posoudit stav systému a přijmout nápravná opatření na základě toho, co se stalo.