Vrstva proxy může být docela užitečná pro zvýšení dostupnosti vaší databázové vrstvy. Může snížit množství kódu na straně aplikace pro zpracování selhání databáze a změn topologie replikace. V tomto příspěvku na blogu probereme, jak nastavit HAProxy, aby fungovala nad PostgreSQL.
Za prvé – HAProxy pracuje s databázemi jako proxy na síťové vrstvě. Neexistuje žádné pochopení základní, někdy složité topologie. Vše, co HAProxy dělá, je posílat pakety v režimu round-robin na definované backendy. Nekontroluje pakety ani nerozumí protokolu, ve kterém aplikace mluví s PostgreSQL. V důsledku toho neexistuje způsob, jak by HAProxy implementovalo rozdělení čtení/zápisu na jeden port – vyžadovalo by to analýzu dotazů. Pokud vaše aplikace může rozdělit čtení od zápisů a odesílat je na různé IP adresy nebo porty, můžete implementovat rozdělení R/W pomocí dvou backendů. Pojďme se podívat, jak to lze provést.
Konfigurace HAProxy
Níže můžete najít příklad dvou PostgreSQL backendů nakonfigurovaných v HAProxy.
listen haproxy_10.0.0.101_3307_rw
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 check
listen haproxy_10.0.0.101_3308_ro
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running.
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 checkJak vidíme, používají porty 3307 pro zápis a 3308 pro čtení. V tomto nastavení jsou tři servery - jeden aktivní a dvě záložní repliky. Co je důležité, tcp-check se používá ke sledování stavu uzlů. HAProxy se připojí k portu 9201 a očekává, že se mu vrátí řetězec. Zdraví členové backendu vrátí očekávaný obsah, ti, kteří nevrátí řetězec, budou označeni jako nedostupní.
Nastavení Xinetd
Jak HAProxy kontroluje port 9201, něco na něm musí poslouchat. Můžeme použít xinetd, aby tam naslouchal a spouštěl za nás nějaké skripty. Příklad konfigurace takové služby může vypadat takto:
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}Musíte se ujistit, že jste přidali řádek:
postgreschk 9201/tcpdo /etc/services.
Xinetd spustí skript postgreschk, který má obsah jako níže:
#!/bin/bash
#
# This script checks if a PostgreSQL server is healthy running on localhost. It will
# return:
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
# - OR -
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring PostgreSQL properly
#
export PGHOST='10.0.0.101'
export PGUSER='someuser'
export PGPASSWORD='somepassword'
export PGPORT='5432'
export PGDATABASE='postgres'
export PGCONNECT_TIMEOUT=10
FORCE_FAIL="/dev/shm/proxyoff"
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"
return_ok()
{
echo -e "HTTP/1.1 200 OK\r\n"
echo -e "Content-Type: text/html\r\n"
if [ "$1x" == "masterx" ]; then
echo -e "Content-Length: 56\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL master is running.</body></html>\r\n"
elif [ "$1x" == "slavex" ]; then
echo -e "Content-Length: 55\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL slave is running.</body></html>\r\n"
else
echo -e "Content-Length: 49\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is running.</body></html>\r\n"
fi
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 0
}
return_fail()
{
echo -e "HTTP/1.1 503 Service Unavailable\r\n"
echo -e "Content-Type: text/html\r\n"
echo -e "Content-Length: 48\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is *down*.</body></html>\r\n"
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 1
}
if [ -f "$FORCE_FAIL" ]; then
return_fail;
fi
# check if in recovery mode (that means it is a 'slave')
SLAVE=$(psql -qt -c "$SLAVE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $SLAVE | egrep -i "(t|true|on|1)" 2>/dev/null >/dev/null; then
return_ok "slave"
fi
# check if writable (then we consider it as a 'master')
READONLY=$(psql -qt -c "$WRITABLE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $READONLY | egrep -i "(f|false|off|0)" 2>/dev/null >/dev/null; then
return_ok "master"
fi
return_ok "none";Logika scénáře je následující. Existují dva dotazy, které se používají ke zjištění stavu uzlu.
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"První zkontroluje, zda je PostgreSQL v obnově – bude to „false“ pro aktivní server a „pravda“ pro záložní servery. Druhý zkontroluje, zda je PostgreSQL v režimu pouze pro čtení. Aktivní server se vrátí do stavu „vypnuto“, zatímco servery v pohotovostním režimu se vrátí na „zapnuto“. Na základě výsledků skript zavolá funkci return_ok() se správným parametrem („master“ nebo „slave“, podle toho, co bylo zjištěno). Pokud se dotazy nezdaří, bude provedena funkce „return_fail“.
Funkce Return_ok vrací řetězec na základě argumentu, který jí byl předán. Pokud je hostitelem aktivní server, skript vrátí „PostgreSQL master je spuštěn“. Pokud se jedná o pohotovostní režim, vrácený řetězec bude:„PostgreSQL slave běží“. Pokud stav není jasný, vrátí se:„PostgreSQL běží“. Tady smyčka končí. HAProxy kontroluje stav připojením k xinetd. Ten spustí skript, který pak vrátí řetězec, který HAProxy analyzuje.
Jak si možná pamatujete, HAProxy očekává následující řetězce:
tcp-check expect string master\ is\ runningpro backend pro zápis a
tcp-check expect string is\ running.pro backend pouze pro čtení. Díky tomu je aktivní server jediným hostitelem dostupným v backendu pro zápis, zatímco na backendu pro čtení lze použít aktivní i záložní servery.
PostgreSQL a HAProxy v ClusterControl
Výše uvedené nastavení není složité, ale jeho nastavení nějakou dobu trvá. ClusterControl lze použít k nastavení toho všeho za vás.
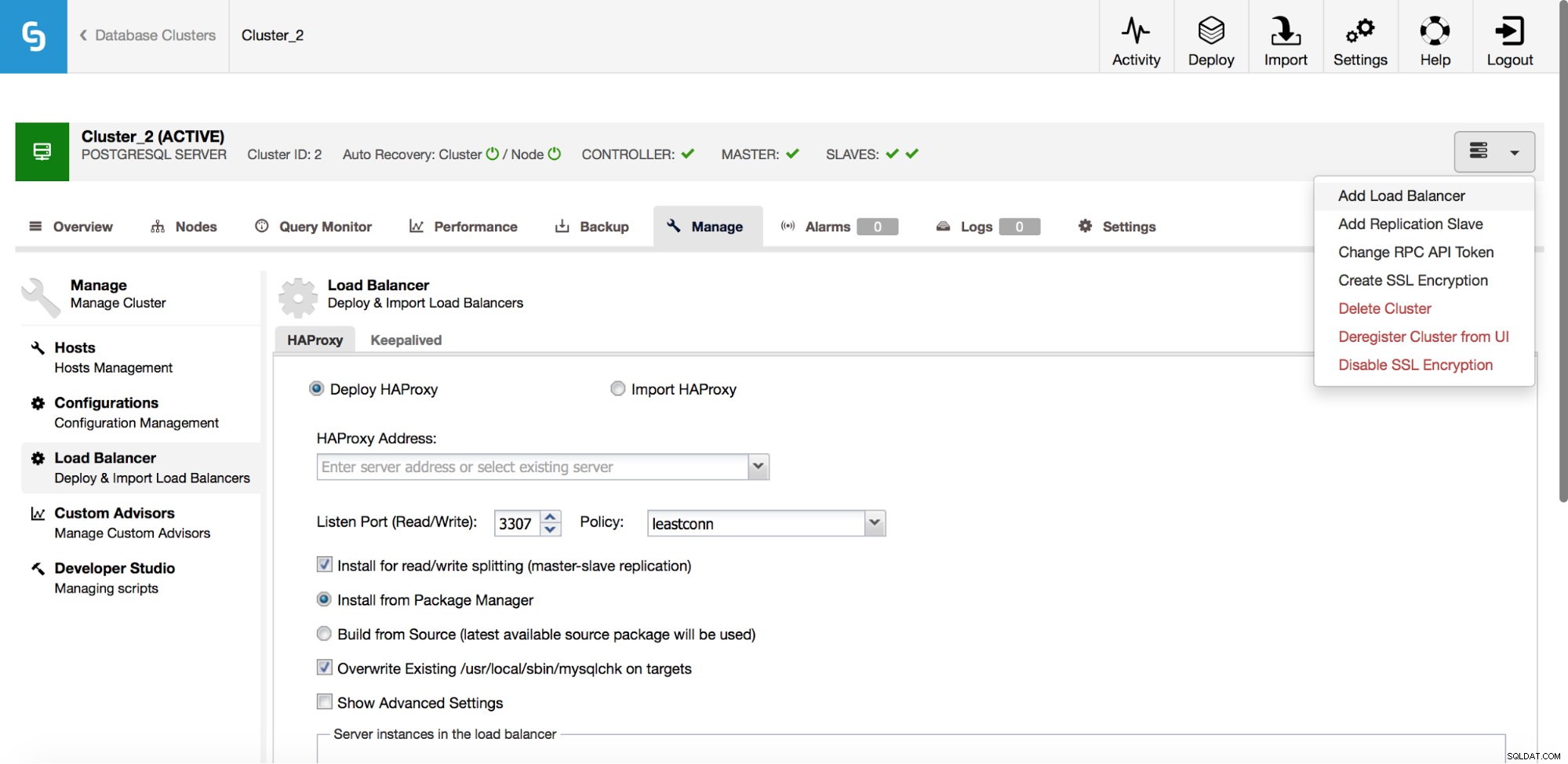
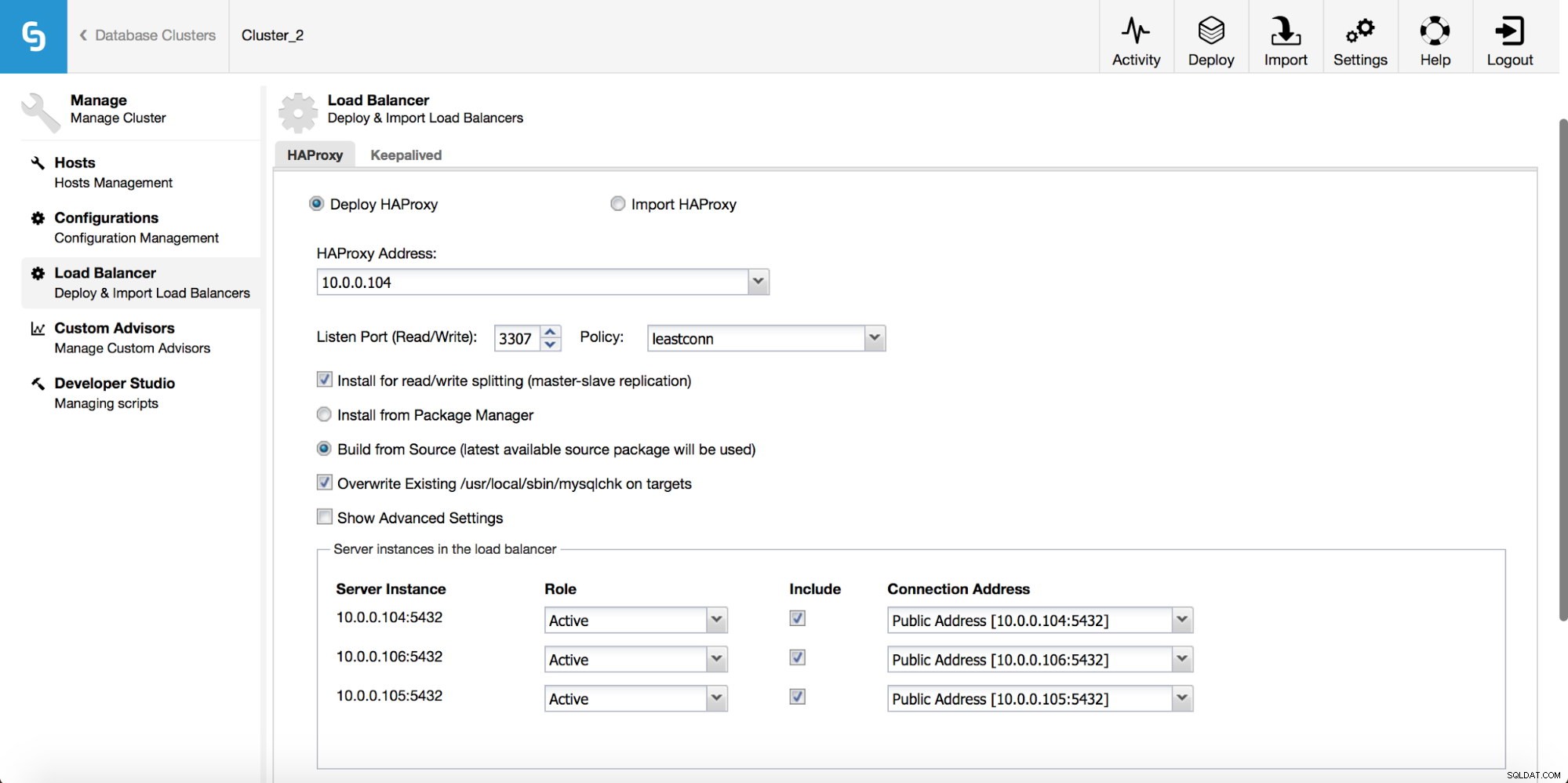
V rozevírací nabídce klastrové úlohy máte možnost přidat nástroj pro vyrovnávání zatížení. Poté se zobrazí možnost nasazení HAProxy. Musíte vyplnit, kam jej chcete nainstalovat, a učinit některá rozhodnutí:z repozitářů, které jste nakonfigurovali na hostiteli, nebo z nejnovější verze, zkompilované ze zdrojového kódu. Budete také muset nakonfigurovat, které uzly v clusteru chcete přidat do HAProxy.
Jakmile je instance HAProxy nasazena, máte přístup k některým statistikám na kartě „Nodes“:
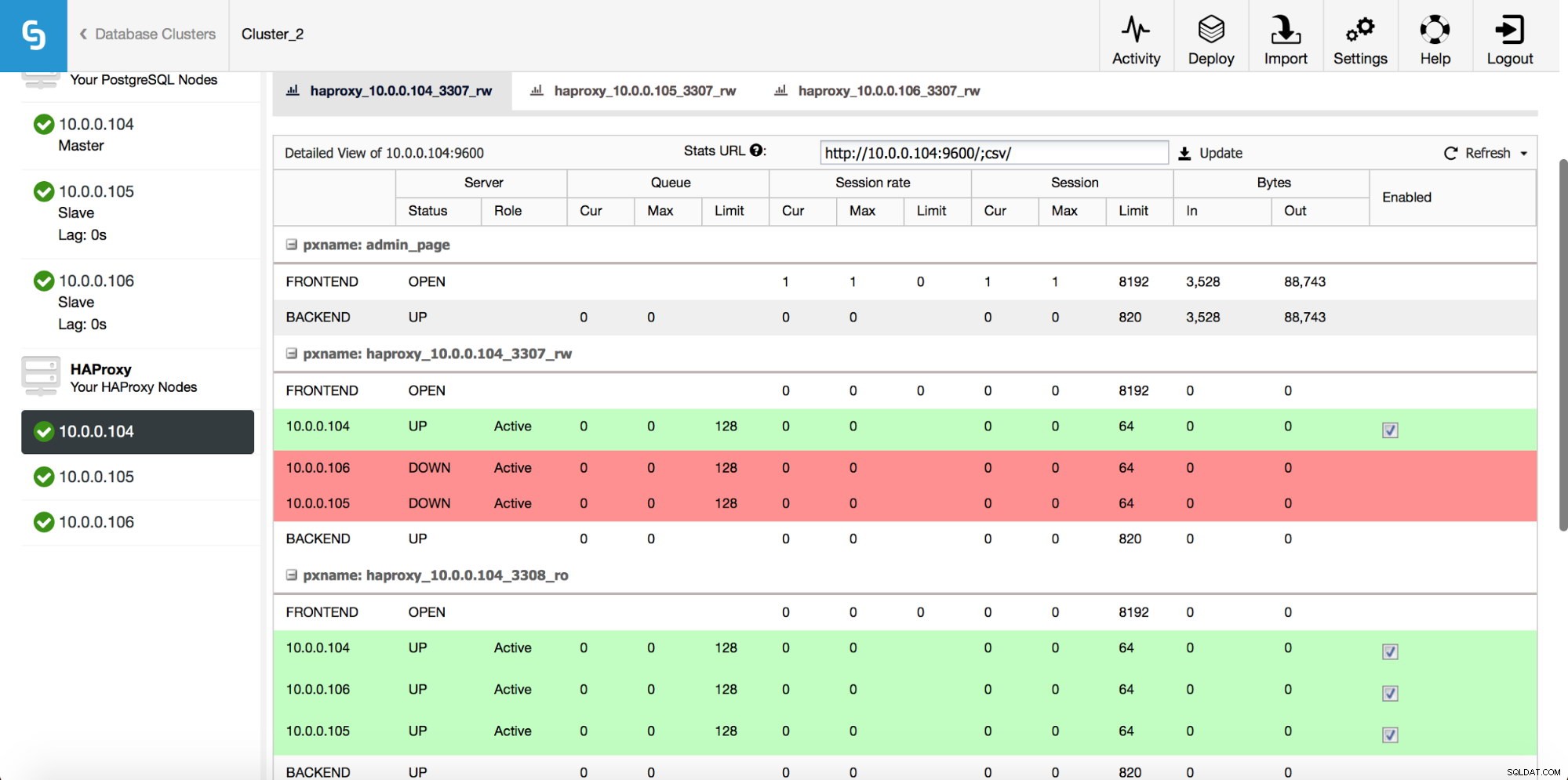
Jak vidíme, pro R/W backend je pouze jeden hostitel (aktivní server) označen jako up. U backendu pouze pro čtení jsou všechny uzly aktivní.
Stáhněte si Whitepaper Today Správa a automatizace PostgreSQL s ClusterControlZjistěte, co potřebujete vědět k nasazení, monitorování, správě a škálování PostgreSQLStáhněte si WhitepaperZachováno
HAProxy bude sedět mezi vašimi aplikacemi a instancemi databáze, takže bude hrát ústřední roli. Bohužel se také může stát jediným bodem selhání, pokud selže, nebude žádná cesta do databází. Chcete-li se takové situaci vyhnout, můžete nasadit více instancí HAProxy. Pak je ale otázka – jak se rozhodnout, ke kterému proxy hostiteli se připojit. Pokud jste nasadili HAProxy z ClusterControl, je to stejně jednoduché jako spuštění další úlohy „Add Load Balancer“, tentokrát nasazení Keepalived.
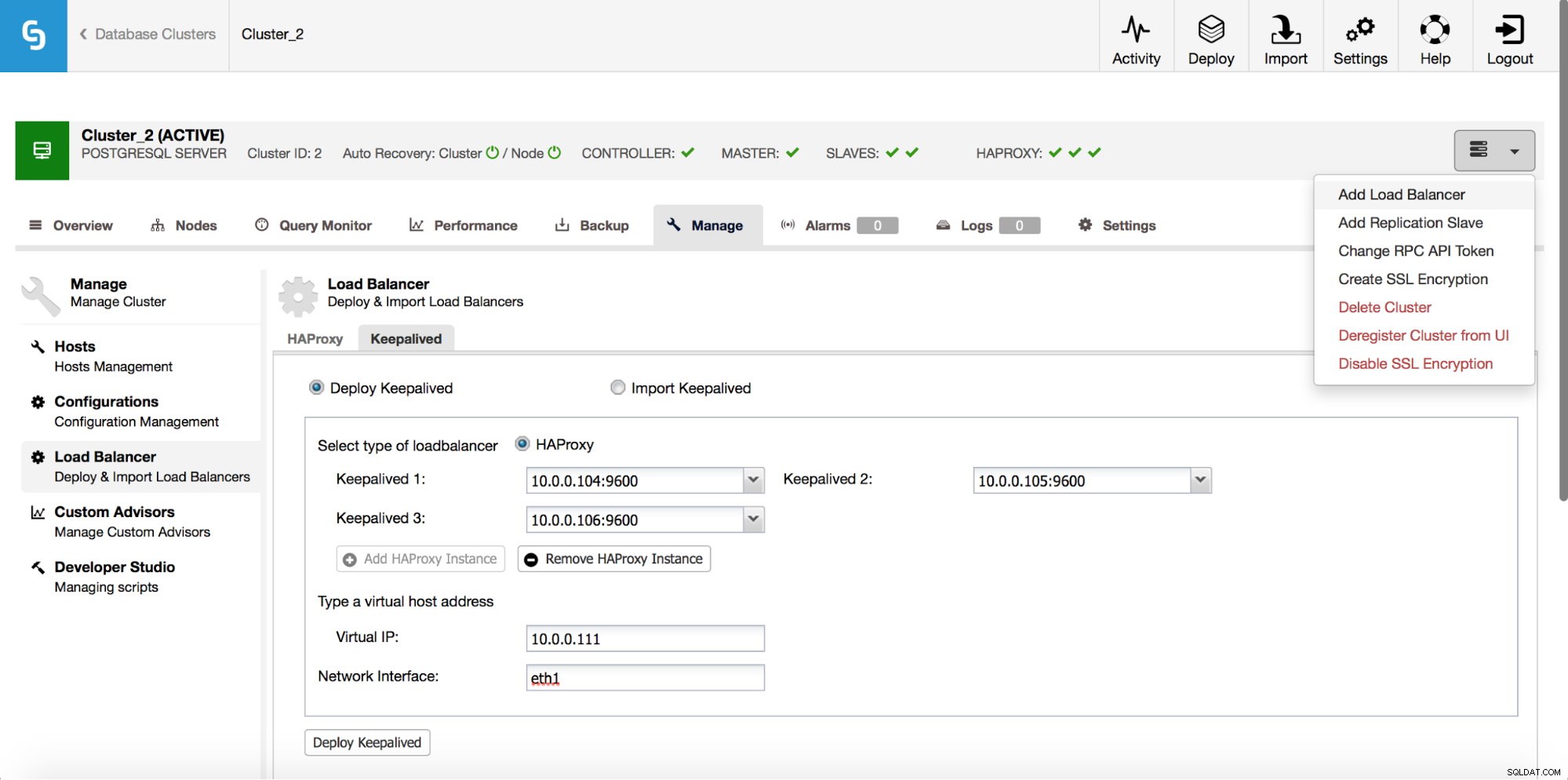
Jak můžeme vidět na obrázku výše, můžete si vybrat až tři hostitele HAProxy a na nich bude nasazen Keepalived, který bude sledovat jejich stav. Jednomu z nich bude přiřazena virtuální IP (VIP). Vaše aplikace by měla používat tento VIP pro připojení k databázi. Pokud bude „aktivní“ HAProxy nedostupné, VIP bude přesunuto na jiného hostitele.
Jak jsme viděli, je docela snadné nasadit plný zásobník s vysokou dostupností pro PostgreSQL. Vyzkoušejte to a dejte nám vědět, pokud máte nějakou zpětnou vazbu.