Replikace hraje zásadní roli při udržování vysoké dostupnosti. Servery mohou selhat, může být nutné upgradovat operační systém nebo databázový software. To znamená přeskupení rolí serveru a přesun replikačních odkazů při zachování konzistence dat napříč všemi databázemi. Změny topologie budou vyžadovány a existují různé způsoby, jak je provést.
Propagace pohotovostního serveru
Pravděpodobně se jedná o nejběžnější operaci, kterou budete muset provést. Důvodů je více – například údržba databáze na primárním serveru, která by nepřípustným způsobem ovlivnila zátěž. Mohlo by dojít k plánovanému výpadku kvůli některým hardwarovým operacím. Zhroucení primárního serveru, kvůli kterému je pro aplikaci nedostupný. To vše jsou důvody, proč provést převzetí služeb při selhání, ať už plánované nebo ne. Ve všech případech budete muset povýšit jeden z pohotovostních serverů, aby se stal novým primárním serverem.
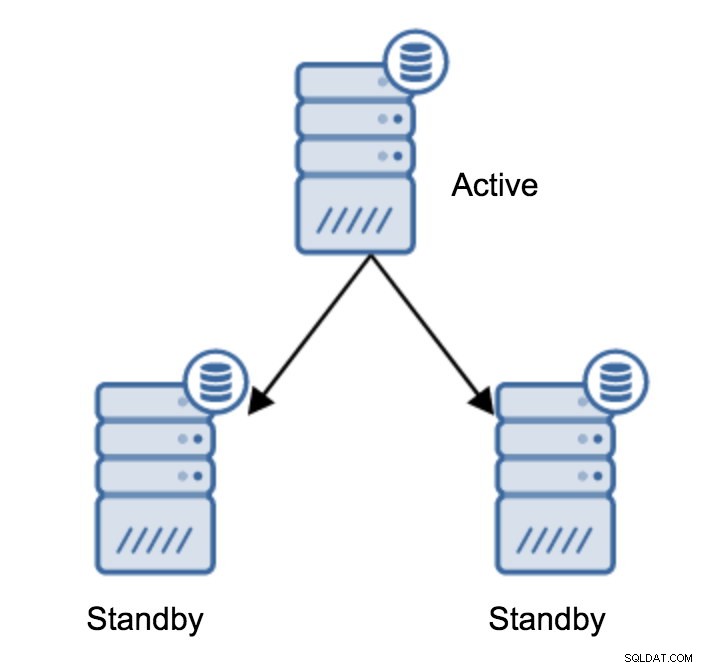
Chcete-li propagovat pohotovostní server, musíte spustit:
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_ctl promote -D /var/lib/postgresql/10/main/
waiting for server to promote.... done
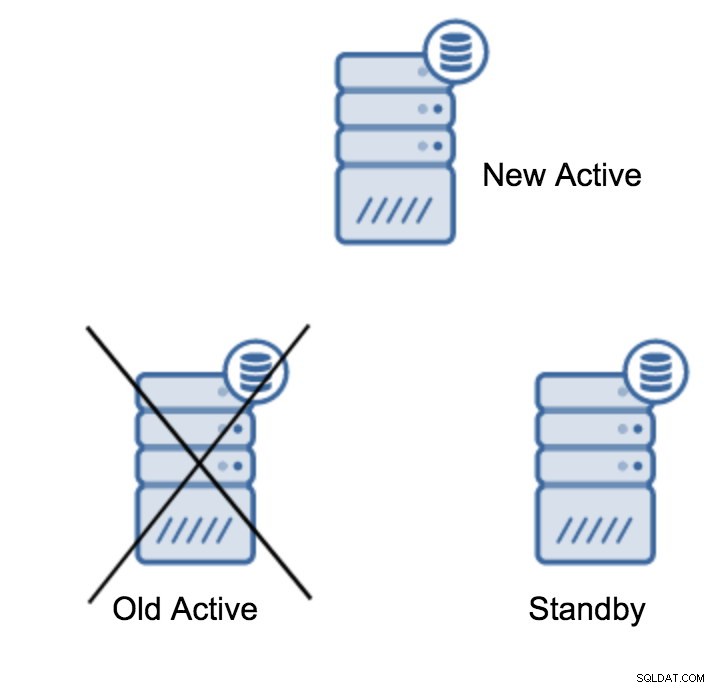
server promotedSpuštění tohoto příkazu je snadné, ale nejprve se ujistěte, že nedojde ke ztrátě dat. Pokud mluvíme o scénáři „výpadek primárního serveru“, nemusíte mít příliš mnoho možností. Pokud se jedná o plánovanou údržbu, tak je možné se na ni připravit. Musíte zastavit provoz na primárním serveru a poté ověřit, že záložní server přijal a použil všechna data. To lze provést na záložním serveru pomocí níže uvedeného dotazu:
postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn();
pg_last_wal_receive_lsn | pg_last_wal_replay_lsn
-------------------------+------------------------
1/AA2D2B08 | 1/AA2D2B08
(1 row)Jakmile je vše v pořádku, můžete zastavit starý primární server a propagovat záložní server.
Stáhněte si Whitepaper Today Správa a automatizace PostgreSQL s ClusterControlZjistěte, co potřebujete vědět k nasazení, monitorování, správě a škálování PostgreSQLStáhněte si WhitepaperVyřazení pohotovostního serveru z nového primárního serveru
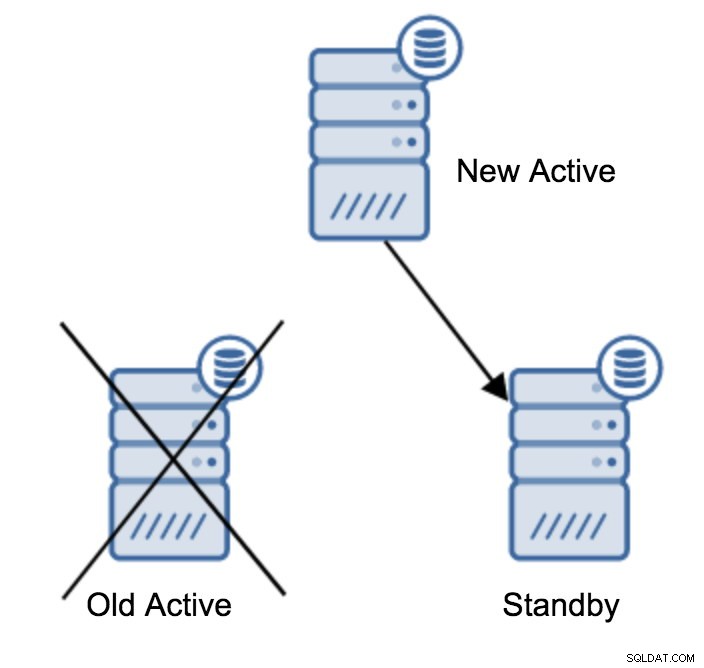
Váš primární server může být podřízen více než jedním záložním serverem. Koneckonců, pohotovostní servery jsou užitečné pro snížení zátěže provozu pouze pro čtení. Po povýšení záložního serveru na nový primární server musíte něco udělat se zbývajícími záložními servery, které jsou stále připojeny (nebo se pokoušejí připojit) ke starému primárnímu serveru. Bohužel nemůžete jen změnit recovery.conf a připojit je k novému primárnímu serveru. Chcete-li je připojit, musíte je nejprve přestavět. Zde můžete vyzkoušet dvě metody:standardní základní zálohu nebo pg_rewind.
Nebudeme se zabývat podrobnostmi, jak vytvořit základní zálohu - popsali jsme to v našem předchozím příspěvku na blogu, který se zaměřil na vytváření záloh a jejich obnovení na PostgreSQL. Pokud náhodou používáte ClusterControl, můžete jej také použít k vytvoření základní zálohy:
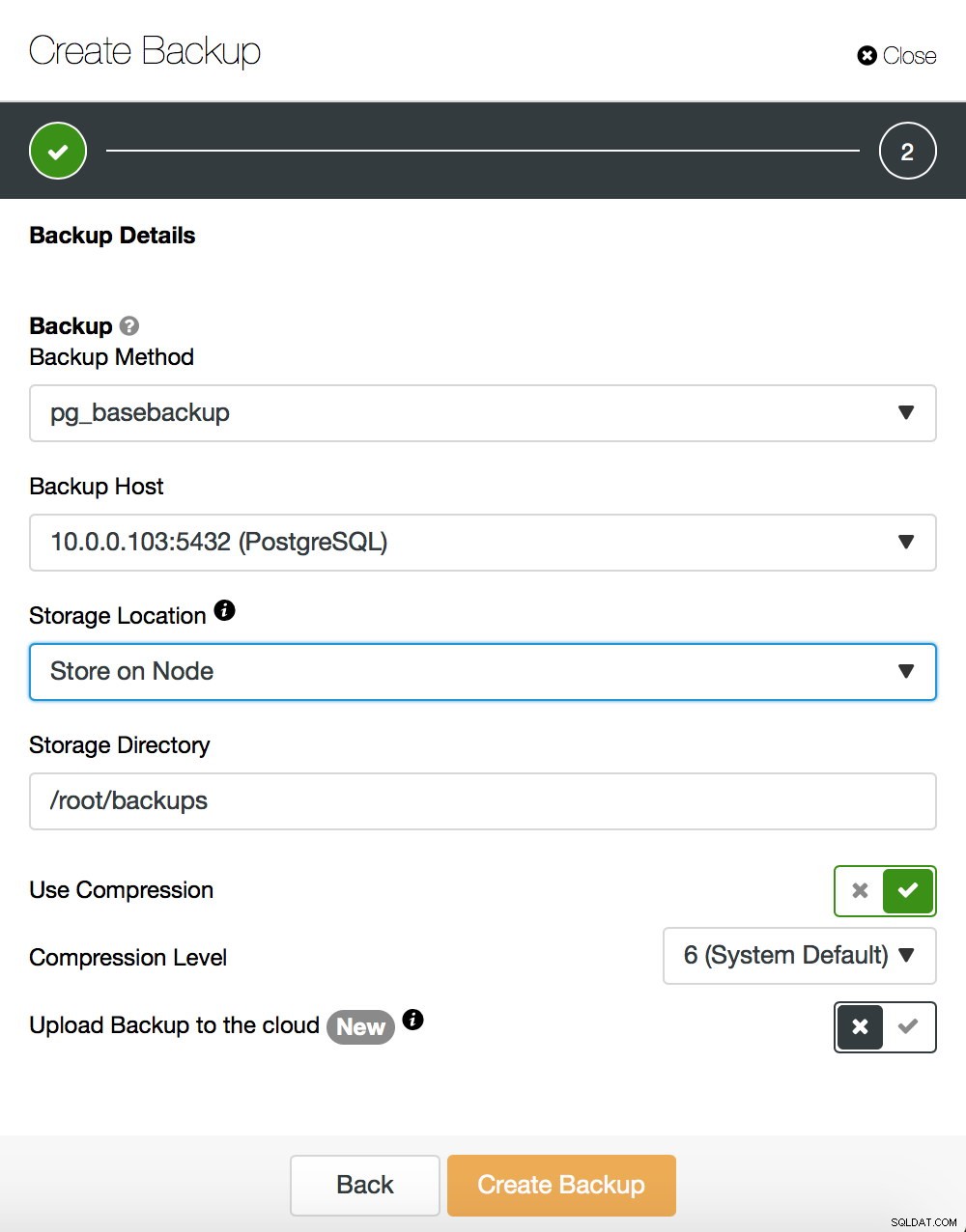
Na druhou stranu si řekněme pár slov o pg_rewind. Hlavní rozdíl mezi oběma metodami je v tom, že základní záloha vytváří úplnou kopii sady dat. Pokud mluvíme o malých datových sadách, může to být v pořádku, ale u datových sad o velikosti stovek gigabajtů (nebo dokonce větších) to může být rychle problém. Nakonec chcete, aby se vaše záložní servery rychle zprovoznily – abyste vytížili váš aktivní server a měli další pohotovostní režim, do kterého lze v případě potřeby přepnout. Pg_rewind funguje jinak - kopíruje pouze ty bloky, které byly změněny. Namísto kopírování všeho kopíruje pouze změny, čímž se proces poměrně výrazně urychluje. Předpokládejme, že váš nový master má IP 10.0.0.103. Takto můžete spustit pg_rewind. Vezměte prosím na vědomí, že musíte mít zastavený cílový server - PostgreSQL tam nemůže běžet.
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_rewind --source-server="user=myuser dbname=postgres host=10.0.0.103" --target-pgdata=/var/lib/postgresql/10/main --dry-run
servers diverged at WAL location 1/AA4F1160 on timeline 3
rewinding from last common checkpoint at 1/AA4F10F0 on timeline 3
Done!Tím se proběhne nasucho , testuje proces, ale neprovádí žádné změny. Pokud je vše v pořádku, vše, co musíte udělat, bude spustit jej znovu, tentokrát bez parametru ‚--dry-run‘. Po dokončení bude posledním zbývajícím krokem vytvoření souboru recovery.conf, který bude ukazovat na nový hlavní soubor. Může to vypadat takto:
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.103 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Nyní jste připraveni spustit svůj rezervní server a bude se replikovat z nového aktivního serveru.
Zřetězená replikace
Existuje mnoho důvodů, proč byste mohli chtít vytvořit zřetězenou replikaci, i když se to obvykle dělá za účelem snížení zatížení primárního serveru. Poskytování WAL záložním serverům přináší určitou režii. Není to velký problém, pokud máte pohotovostní režim nebo dva, ale pokud mluvíme o velkém počtu pohotovostních serverů, může to být problém. Můžeme například minimalizovat počet záložních serverů, které se replikují přímo z aktivních, vytvořením topologie, jak je uvedeno níže:
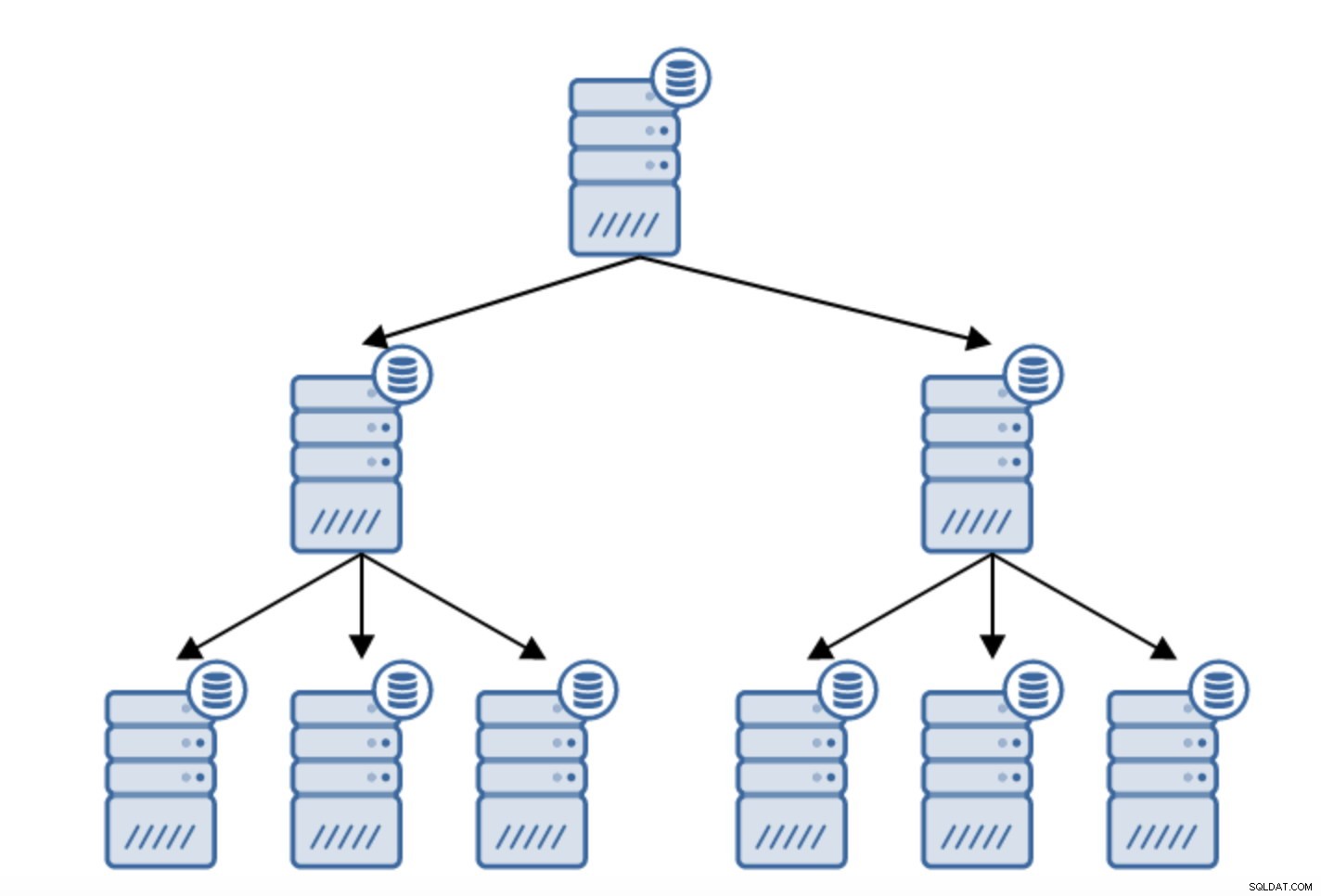
Přechod od topologie dvou záložních serverů k zřetězené replikaci je poměrně přímočarý.
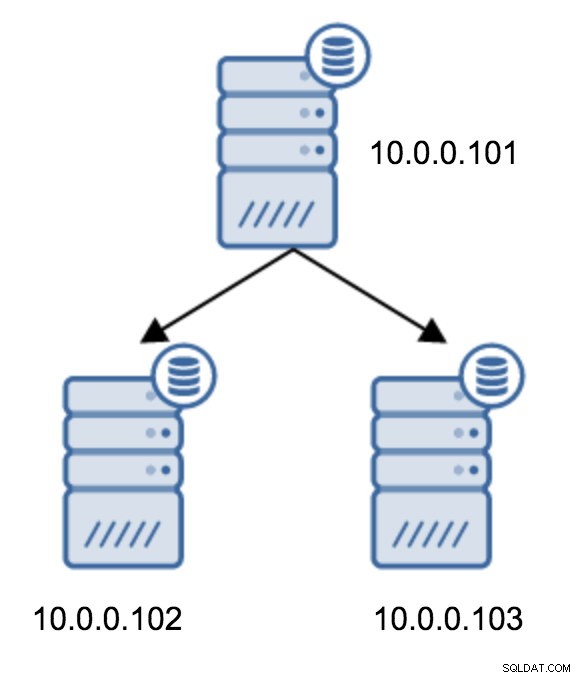
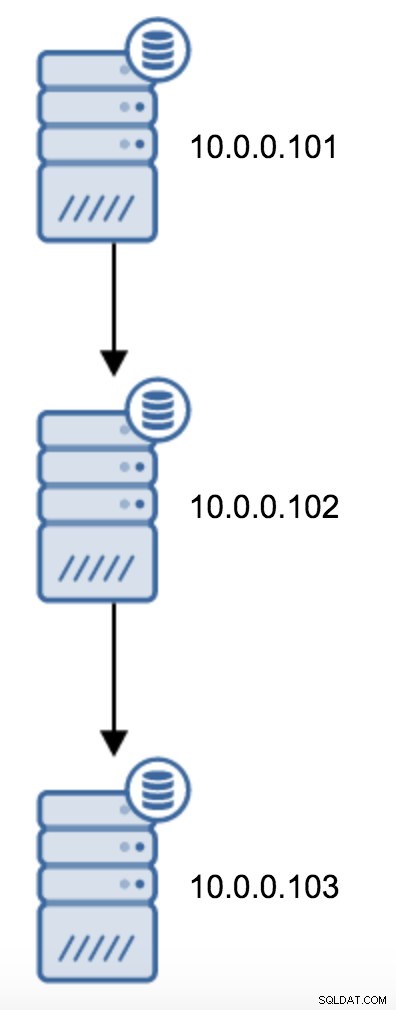
Budete muset upravit recovery.conf na 10.0.0.103, nasměrovat jej na 10.0.0.102 a poté restartovat PostgreSQL.
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.102 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Po restartu by 10.0.0.103 měla začít používat aktualizace WAL.
Toto jsou některé běžné případy změn topologie. Jedním tématem, o kterém se nemluvilo, ale které je stále důležité, je dopad těchto změn na aplikace. Tomu se budeme věnovat v samostatném příspěvku a také tomu, jak tyto změny topologie zprůhlednit pro aplikace.