Vytváření vysoké dostupnosti, jeden krok za druhým
Pokud jde o databázovou infrastrukturu, všichni ji chceme. Všichni se snažíme vytvořit vysoce dostupné nastavení. Klíčem je redundance. Začneme implementovat redundanci na nejnižší úrovni a pokračujeme v zásobníku. Začíná to hardwarem – redundantní zdroje, redundantní chlazení, hot-swap disky. Síťová vrstva – více síťových karet spojených dohromady a připojených k různým přepínačům, které používají redundantní směrovače. Pro ukládání používáme disky zasazené v RAID, které poskytují lepší výkon, ale také redundanci. Na softwarové úrovni pak používáme technologie shlukování:více databázových uzlů spolupracujících na implementaci redundance:MySQL Cluster, Galera Cluster.
To vše není dobré, pokud máte vše v jednom datovém centru:když datové centrum vypadne, nebo část služeb (ale důležitých) přejde do režimu offline, nebo i když ztratíte připojení k datovému centru, vaše služba vypadne – bez ohledu na množství redundance v nižších úrovních. A ano, takové věci se stávají.
- Přerušení služby S3 způsobilo zmatek v regionu US-East-1 v únoru 2017
- Přerušení služeb EC2 a RDS v regionu USA-východ v dubnu 2011
- EC2, EBS a RDS byly přerušeny v regionu EU-West v srpnu 2011
- Výpadek proudu způsobil výpadek Rackspace Texas DC v červnu 2009
- Selhání UPS způsobilo, že stovky serverů přešly v lednu 2010 v Rackspace London DC do režimu offline
Toto v žádném případě není úplný seznam selhání, je to jen výsledek rychlého vyhledávání Google. Tyto slouží jako příklady toho, že se věci mohou a pokazí, pokud vložíte všechna vejce do stejného košíku. Dalším příkladem může být hurikán Sandy, který způsobil enormní exodus dat z USA-východ na americko-západní DC – v té době jste jen stěží mohli roztočit instance na americkou západu, protože všichni v očekávání spěchali přesunout svou infrastrukturu na druhé pobřeží. že Severní Virginie DC bude vážně ovlivněna počasím.
Pokud tedy chcete vytvořit prostředí s vysokou dostupností, nastavení více datových center je nutností. V tomto příspěvku na blogu probereme, jak takovou infrastrukturu vybudovat pomocí Galera Cluster for MySQL/MariaDB.
Koncepty Galera
Než se podíváme na konkrétní řešení, strávíme nějaký čas vysvětlením dvou pojmů, které jsou velmi důležité ve vysoce dostupných, multi-DC Galera sestavách.
Kvorum
Vysoká dostupnost vyžaduje zdroje – konkrétně potřebujete určitý počet uzlů v clusteru, aby byl vysoce dostupný. Klastr může tolerovat ztrátu některých svých členů, ale jen do určité míry. Za určitou mírou selhání se možná díváte na scénář rozděleného mozku.
Vezměme si příklad s nastavením 2 uzlů. Pokud jeden z uzlů selže, jak může druhý vědět, že jeho peer havaroval a nejedná se o selhání sítě? V takovém případě by mohl být druhý uzel v provozu a obsluhovat provoz. Neexistuje žádný dobrý způsob, jak takový případ zvládnout… To je důvod, proč odolnost proti chybám obvykle začíná od tří uzlů. Galera používá výpočet kvora k určení, zda je pro cluster bezpečné zpracovávat provoz nebo zda by měl ukončit provoz. Po selhání se všechny zbývající uzly pokusí vzájemně připojit a určit, kolik z nich je aktivních. Poté se porovná s předchozím stavem clusteru, a dokud bude aktivních více než 50 % uzlů, cluster může pokračovat v provozu.
Výsledkem je následující:
2 uzly cluster – žádná odolnost proti chybám
3 cluster uzlů – až 1 selhání
cluster 4 uzlů – až 1 selhání (pokud by došlo k selhání dvou uzlů, pouze 50 % z clusteru by bylo k dispozici, k přežití potřebujete více než 50 % uzlů)
Cluster 5 uzlů – až 2 selhání
Cluster 6 uzlů – až 2 selhání
Pravděpodobně vidíte vzorec – chcete, aby váš cluster měl lichý počet uzlů – z hlediska vysoké dostupnosti nemá smysl přecházet z 5 na 6 uzlů v clusteru. Pokud chcete lepší odolnost proti chybám, měli byste zvolit 7 uzlů.
Segmenty
V clusteru Galera se veškerá komunikace obvykle řídí vzorem všichni všem. Každý uzel komunikuje se všemi ostatními uzly v clusteru.
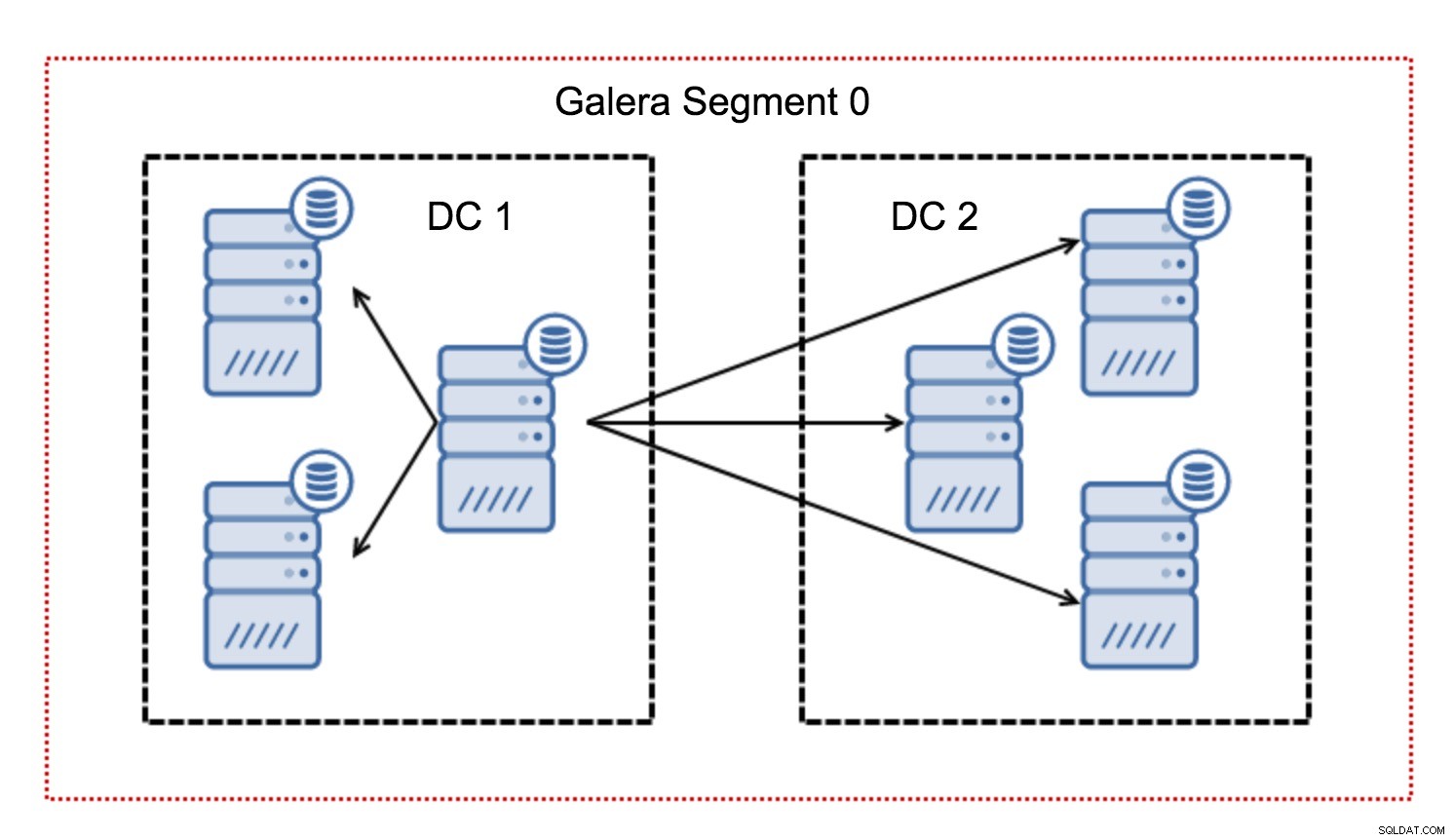
Jak možná víte, každá sada zápisů v Galeře musí být certifikována všemi uzly v clusteru – proto každý zápis, ke kterému došlo na uzlu, musí být přenesen do všech uzlů v clusteru. V prostředí s nízkou latencí to funguje dobře. Pokud ale mluvíme o multi-DC nastavení, musíme počítat s mnohem vyšší latencí než v lokální síti. Aby to bylo snesitelnější v klastrech přes Wide Area Networks, Galera zavedla segmenty.
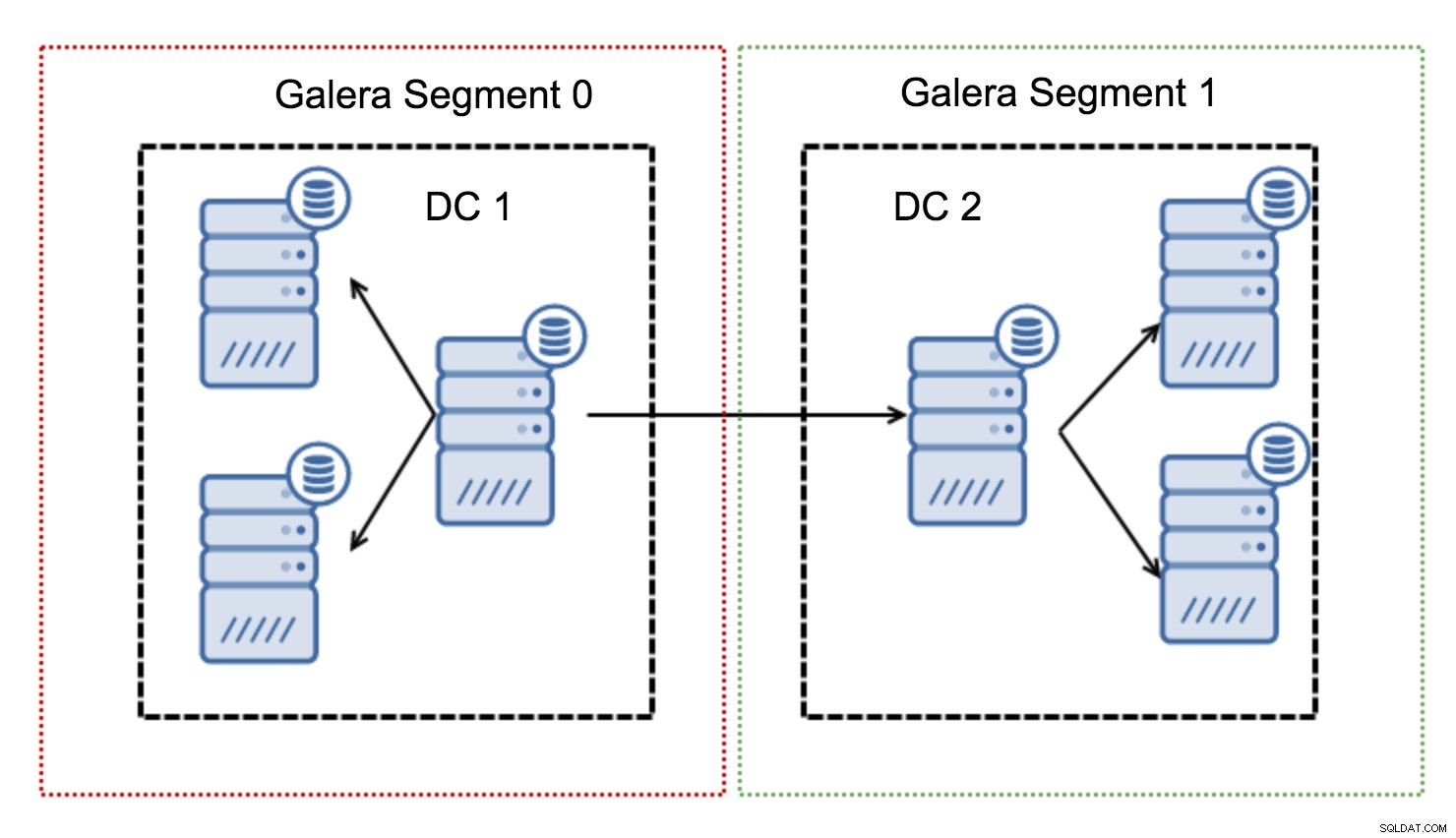
Fungují tak, že obsahují provoz Galery v rámci skupiny uzlů (segmentu). Všechny uzly v rámci jednoho segmentu se chovají, jako by byly v lokální síti – předpokládají jednu komunikaci. U provozu napříč segmenty jsou věci jiné – v každém ze segmentů je vybrán jeden „reléový“ uzel, veškerý provoz napříč segmenty prochází těmito uzly. Když přenosový uzel selže, zvolí se jiný uzel. To nesnižuje latenci o mnoho – koneckonců, latence WAN zůstane stejná bez ohledu na to, zda se připojíte k jednomu vzdálenému hostiteli nebo k více vzdáleným hostitelům, ale vzhledem k tomu, že WAN linky mají tendenci být omezeny v šířce pásma a mohou existovat poplatek za množství přenesených dat, tento přístup umožňuje omezit množství dat vyměňovaných mezi segmenty. Další možností šetřící čas a náklady je skutečnost, že v případě potřeby dárce jsou upřednostňovány uzly ve stejném segmentu - opět to omezuje množství dat přenášených přes WAN a s největší pravděpodobností zrychluje SST jako lokální síť téměř vždy bude rychlejší než připojení WAN.
Nyní, když máme některé z těchto konceptů z cesty, pojďme se podívat na některé další důležité aspekty nastavení multi-DC pro cluster Galera.
Problémy, kterým budete čelit
Při práci v prostředích zahrnujících WAN existuje několik problémů, které musíte vzít v úvahu při navrhování svého prostředí.
Výpočet kvora
V předchozí části jsme popsali, jak vypadá výpočet kvora v clusteru Galera – zkrátka chcete mít lichý počet uzlů, abyste maximalizovali schopnost přežití. To vše stále platí v multi-DC nastavení, ale do mixu jsou přidány některé další prvky. Nejprve se musíte rozhodnout, zda chcete, aby Galera automaticky řešila selhání datového centra. To určí, kolik datových center budete používat. Představme si dva DC – pokud rozdělíte své uzly na 50 % – 50 %, pokud jedno datové centrum selže, druhé nemá 50 %+1 uzlů k udržení svého „primárního“ stavu. Pokud své uzly rozdělíte nerovnoměrným způsobem a většinu z nich použijete v „hlavním“ datovém centru, když toto datové centrum vypadne, „záložní“ DC nebude mít 50 % + 1 uzly k vytvoření kvora. Uzlům můžete přiřadit různé váhy, ale výsledek bude naprosto stejný – neexistuje způsob, jak automaticky přepnout mezi dvěma DC bez ručního zásahu. K implementaci automatického převzetí služeb při selhání potřebujete více než dva DC. Opět ideálně lichý počet – tři datacentra jsou naprosto v pořádku nastavení. Další otázkou je - kolik uzlů musíte mít? Chcete je mít rovnoměrně rozmístěné napříč datovými centry. Zbytek je jen otázkou toho, kolik uzlů selhalo vaše nastavení.
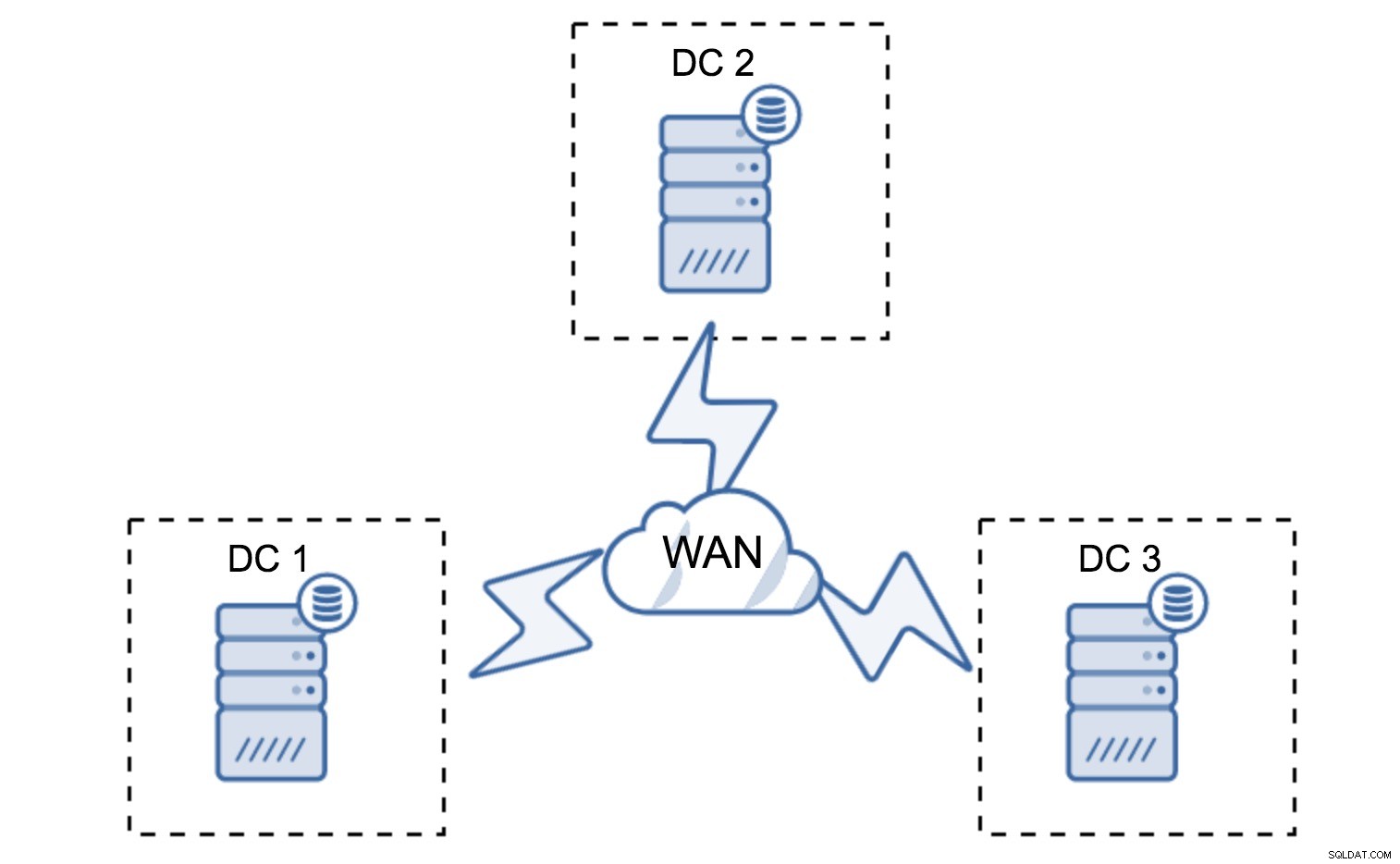
Minimální nastavení bude používat jeden uzel na datové centrum – má to však vážné nevýhody. Každý přenos stavu bude vyžadovat přesun dat přes WAN, což má za následek buď delší dobu potřebnou k dokončení SST, nebo vyšší náklady.
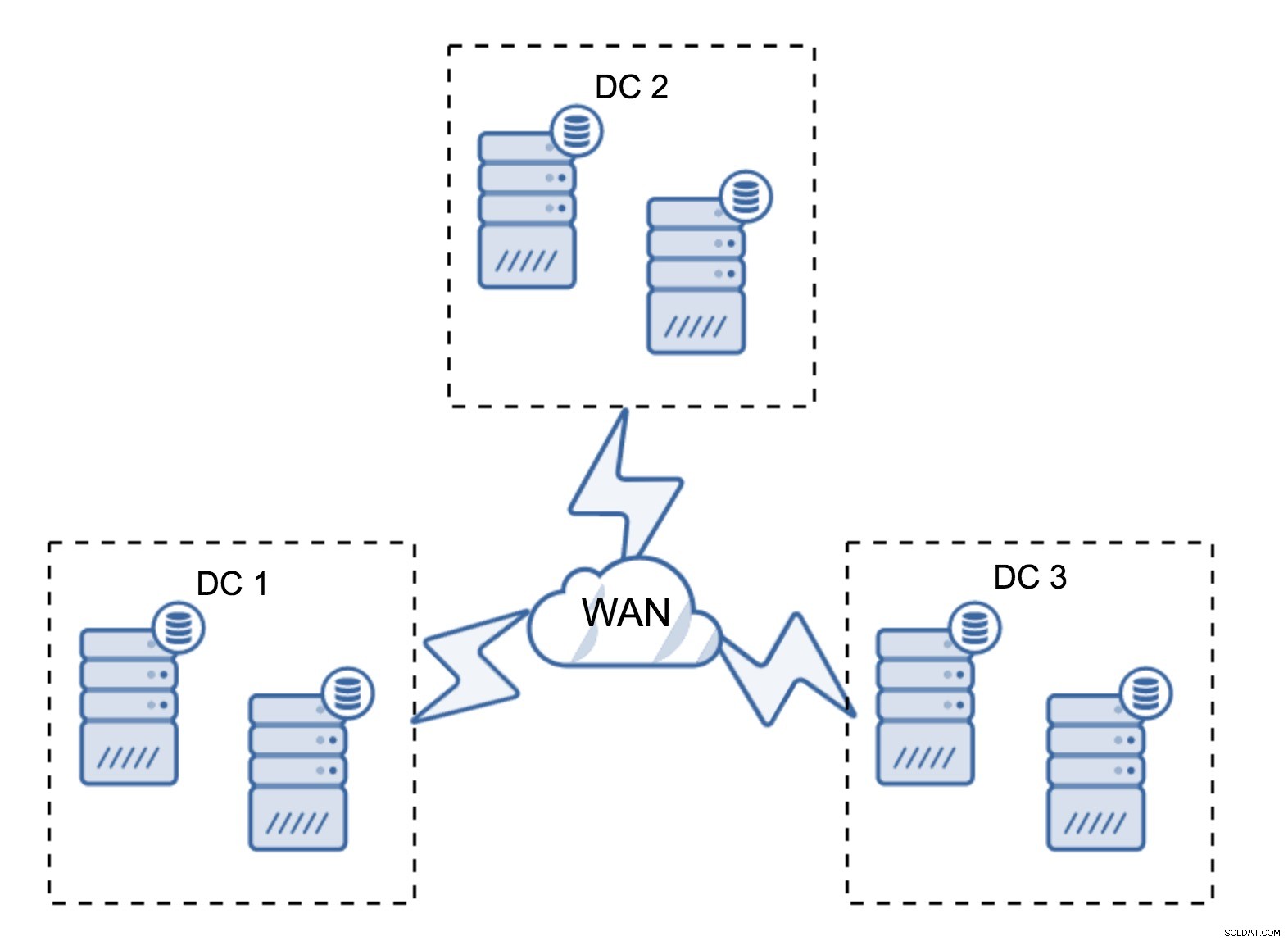
Zcela typické nastavení je mít šest uzlů, dva na datové centrum. Toto nastavení se zdá neočekávané, protože má sudý počet uzlů. Ale když se nad tím zamyslíte, nemusí to být tak velký problém:je docela nepravděpodobné, že by tři uzly selhaly najednou a takové nastavení přežije pád až dvou uzlů. Celé datové centrum může přejít do režimu offline a dvě zbývající DC budou pokračovat v provozu. Má to také obrovskou výhodu oproti minimálnímu nastavení – když uzel přejde do režimu offline, vždy je v datovém centru druhý uzel, který může sloužit jako dárce. Většinu času se WAN nebude používat pro SST.
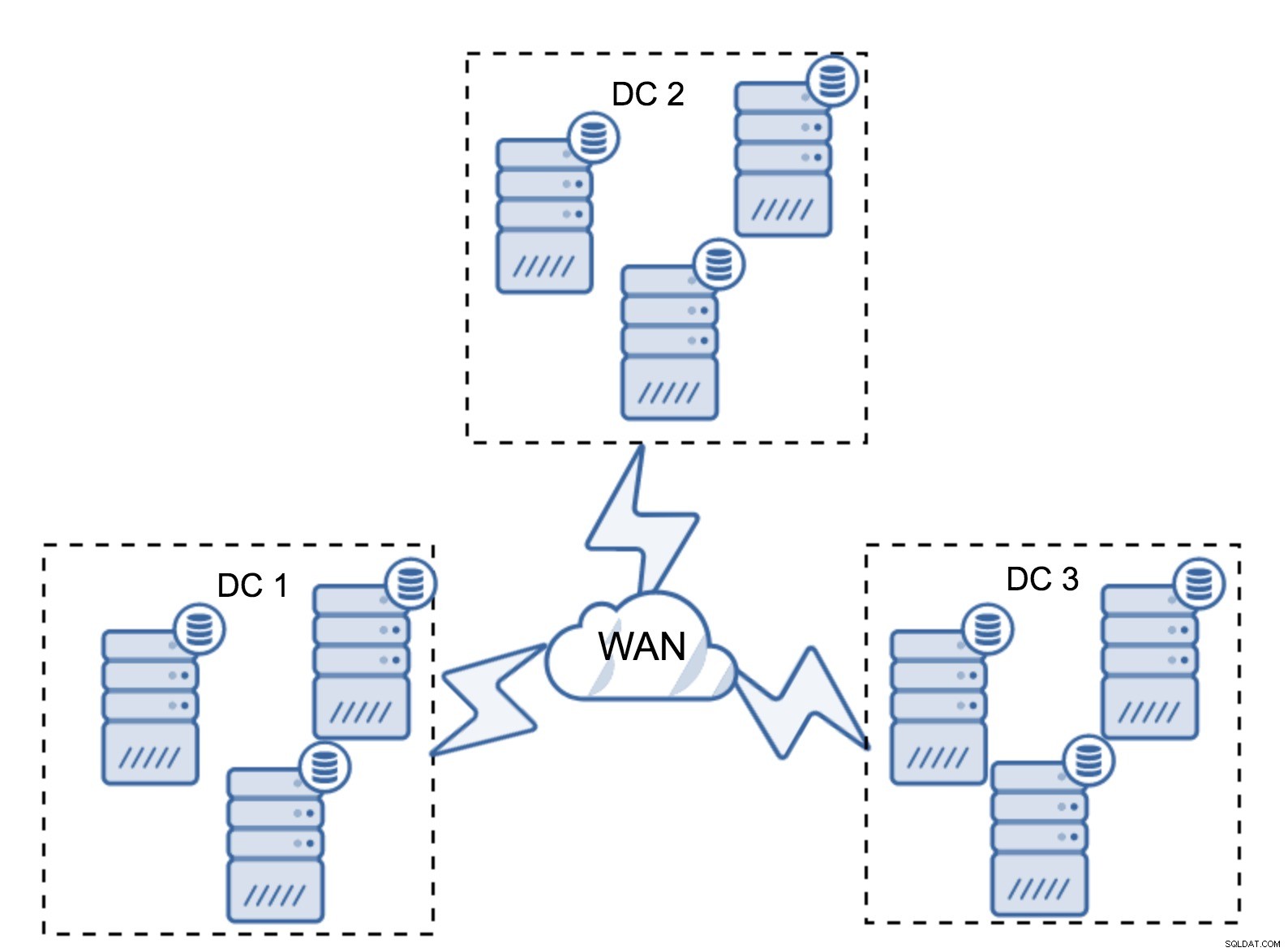
Samozřejmě můžete zvýšit počet uzlů na tři na cluster, celkem devět. To vám dává ještě lepší schopnost přežití:až čtyři uzly mohou havarovat a cluster stále přežije. Na druhou stranu musíte mít na paměti, že i při použití segmentů více uzlů znamená vyšší provozní náklady a cluster Galera můžete škálovat jen do určité míry.
Může se stát, že není potřeba třetí datové centrum, protože řekněme, že vaše aplikace se nachází pouze ve dvou z nich. Požadavek tří datových center je samozřejmě stále platný, takže ho neobejdete, ale je naprosto v pořádku použít Galera Arbitrator (garbd) místo plně načtených databázových serverů.
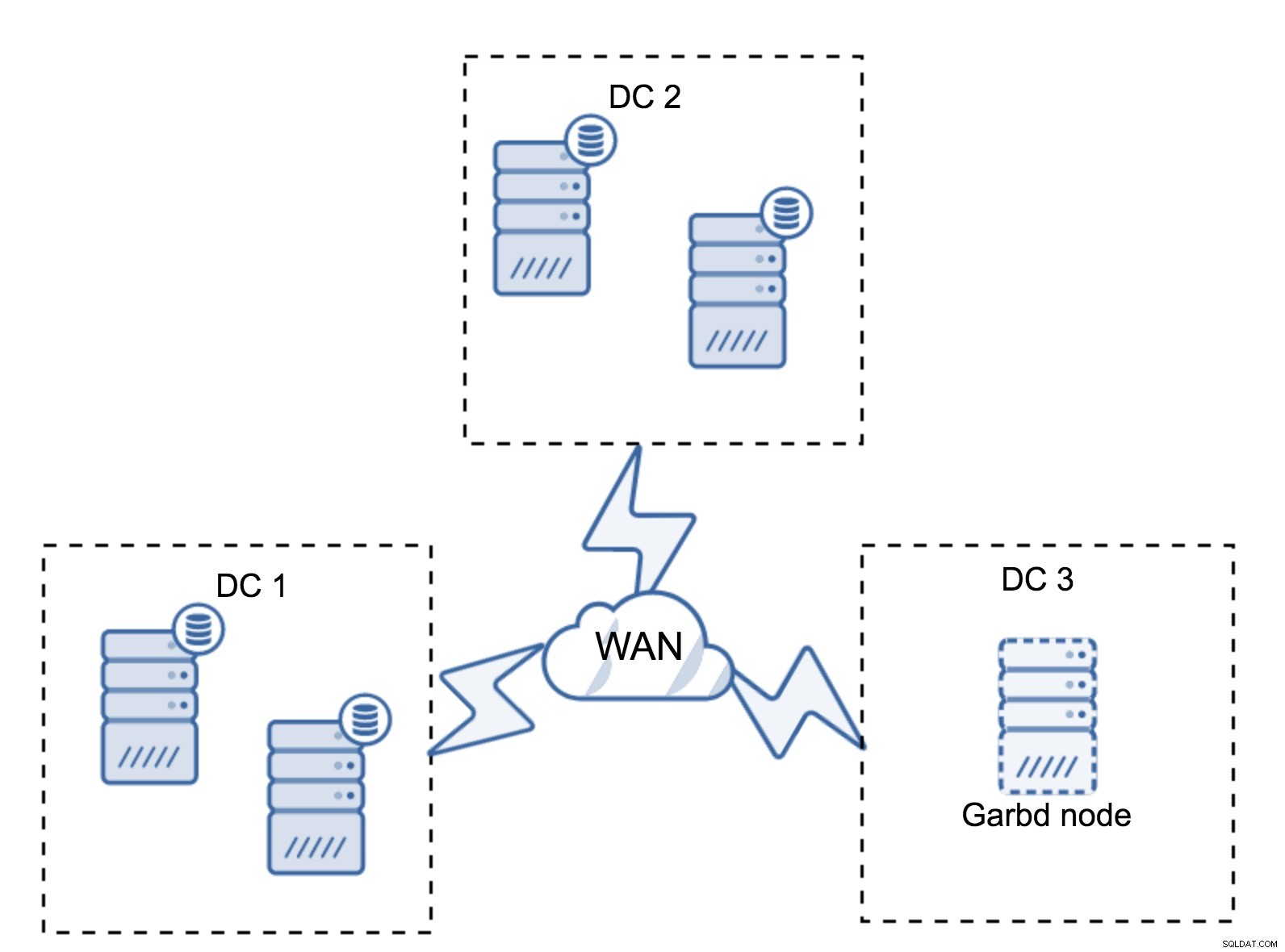
Garbd lze nainstalovat na menší uzly, dokonce i na virtuální servery. Nevyžaduje výkonný hardware, neukládá žádná data ani neaplikuje žádnou ze zápisových sad. Ale vidí veškerý provoz replikace a účastní se výpočtu kvora. Díky němu můžete nasadit setupy jako čtyři uzly, dva na DC + garbd ve třetím - celkem máte pět uzlů a takový cluster může akceptovat až dva výpadky. Znamená to tedy, že může akceptovat úplné vypnutí jednoho z datových center.
Která možnost je pro vás lepší? Neexistuje žádné nejlepší řešení pro všechny případy, vše závisí na vašich požadavcích na infrastrukturu. Naštěstí jsou na výběr různé možnosti:více či méně uzlů, plné 3 DC nebo 2 DC a garbd ve třetí – je docela pravděpodobné, že najdete něco vhodného pro vás.
Latence sítě
Při práci s multi-DC nastaveními musíte mít na paměti, že latence sítě bude výrazně vyšší, než byste očekávali od místního síťového prostředí. To může vážně snížit výkon clusteru Galera, když jej porovnáte se samostatnou instancí MySQL nebo nastavením replikace MySQL. Požadavek, že všechny uzly musí certifikovat sadu zápisů, znamená, že ji musí přijmout všechny uzly, bez ohledu na to, jak daleko jsou. S asynchronní replikací není třeba čekat před potvrzením. Replikace má samozřejmě další problémy a nevýhody, ale latence není tím hlavním. Problém je zvláště viditelný, když má vaše databáze aktivní místa – řádky, které jsou často aktualizovány (počítadla, fronty atd.). Tyto řádky nelze aktualizovat častěji než jednou za síť tam a zpět. U clusterů po celém světě to může snadno znamenat, že nebudete moci aktualizovat jeden řádek častěji než 2–3krát za sekundu. Pokud se to pro vás stane omezením, může to znamenat, že cluster Galera není vhodný pro vaši konkrétní pracovní zátěž.
Proxy vrstva v Multi-DC Galera Cluster
Nestačí mít cluster Galera pokrývající více datových center, stále potřebujete svou aplikaci, abyste k nim měli přístup. Jednou z populárních metod, jak skrýt složitost databázové vrstvy před aplikací, je použití proxy. Proxy se používají jako vstupní bod do databází, sledují stav databázových uzlů a měly by vždy směrovat provoz pouze do uzlů, které jsou dostupné. V této části se pokusíme navrhnout návrh proxy vrstvy, který by mohl být použit pro multi-DC Galera cluster. Použijeme ProxySQL, který vám poskytuje docela flexibilitu při práci s databázovými uzly, ale můžete použít jiný proxy, pokud dokáže sledovat stav uzlů Galera.
Kde najít proxy?
Stručně řečeno, existují zde dva běžné vzory:buď můžete nasadit ProxySQL na samostatné uzly, nebo je můžete nasadit na hostitele aplikace. Pojďme se podívat na výhody a nevýhody každého z těchto nastavení.
Vrstva proxy jako samostatná sada hostitelů
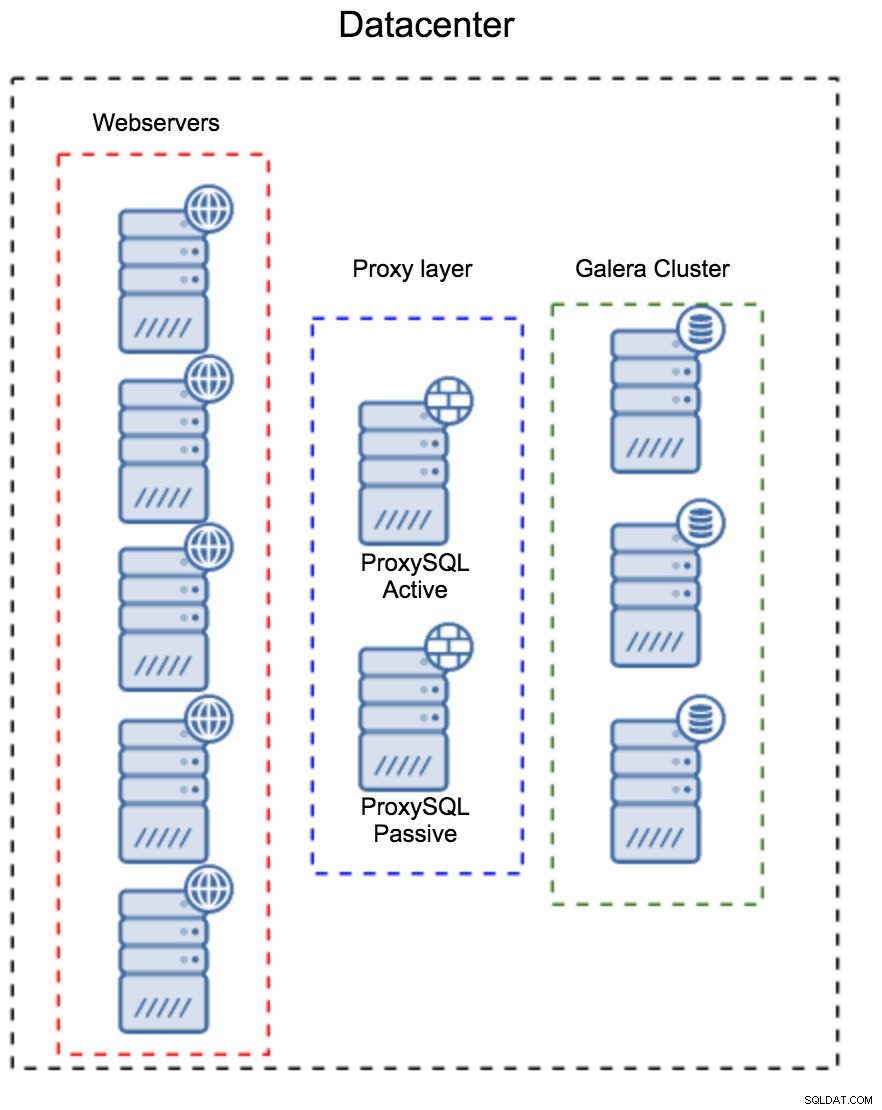
Prvním vzorem je vytvoření vrstvy proxy pomocí samostatných vyhrazených hostitelů. ProxySQL můžete nasadit na několik hostitelů a používat Virtual IP a keepalved pro udržení vysoké dostupnosti. Aplikace použije VIP pro připojení k databázi a VIP zajistí, že požadavky budou vždy směrovány do dostupného ProxySQL. Hlavním problémem tohoto nastavení je, že používáte maximálně jednu z instancí ProxySQL – všechny pohotovostní uzly se nepoužívají pro směrování provozu. To vás může donutit používat výkonnější hardware, než byste obvykle používali. Na druhou stranu je snazší udržovat nastavení - budete muset aplikovat konfigurační změny na všechny uzly ProxySQL, ale bude jich jen hrstka. Můžete také využít možnost ClusterControl k synchronizaci uzlů. Takové nastavení bude muset být duplikováno v každém datovém centru, které používáte.
Proxy nainstalovaný v instancích aplikace
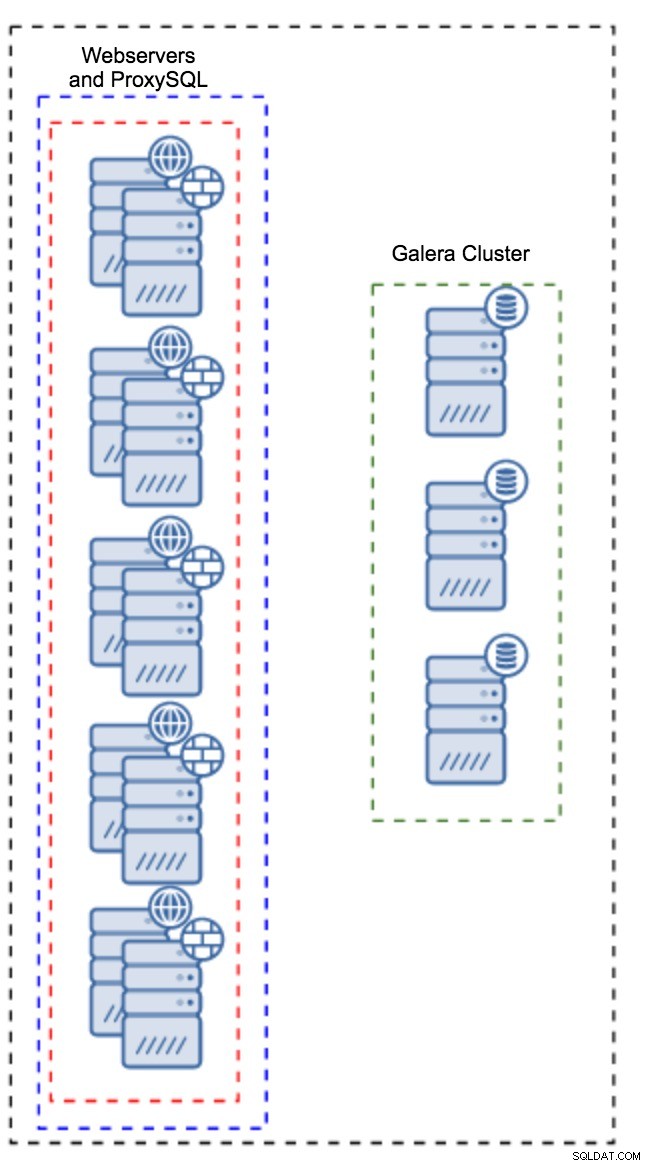
Namísto samostatné sady hostitelů lze ProxySQL nainstalovat také na hostitele aplikace. Aplikace se připojí přímo k ProxySQL na localhost, může dokonce použít unixový socket k minimalizaci režie TCP spojení. Hlavní výhodou takového nastavení je, že máte k dispozici velké množství ProxySQL instancí a zátěž je mezi ně rovnoměrně rozložena. Pokud dojde k výpadku jednoho, bude to ovlivněno pouze hostitelem aplikace. Zbývající uzly budou nadále fungovat. Nejzávažnějším problémem, kterému je třeba čelit, je správa konfigurace. S velkým počtem uzlů ProxySQL je klíčové přijít s automatizovanou metodou, jak udržovat jejich konfigurace v synchronizaci. Můžete použít ClusterControl nebo nástroj pro správu konfigurace, jako je Puppet.
Ladění Galery v prostředí WAN
Výchozí nastavení Galera jsou navržena pro místní síť a pokud ji chcete používat v prostředí WAN, je vyžadováno určité vyladění. Pojďme diskutovat o některých základních vylepšeních, které můžete provést. Mějte prosím na paměti, že přesné ladění vyžaduje produkční data a provoz – nemůžete jen provést nějaké změny a předpokládat, že jsou dobré, měli byste provést řádné srovnávání.
Konfigurace operačního systému
Začněme konfigurací operačního systému. Ne všechny zde navržené úpravy se týkají WAN, ale vždy je dobré si připomenout, co je dobrým výchozím bodem pro jakoukoli instalaci MySQL.
vm.swappiness = 1Swappiness řídí, jak agresivní bude operační systém používat swap. Nemělo by být nastaveno na nulu, protože v novějších jádrech to brání OS v používání swapu a může to způsobit vážné problémy s výkonem.
/sys/block/*/queue/scheduler = deadline/noopPlánovač pro blokové zařízení, které používá MySQL, by měl být nastaven buď na deadline nebo noop. Přesná volba závisí na benchmarcích, ale obě nastavení by měla poskytovat podobný výkon, lepší než výchozí plánovač, CFQ.
Pro MySQL byste měli zvážit použití EXT4 nebo XFS v závislosti na jádře (výkon těchto souborových systémů se mění z jedné verze jádra na druhou). Proveďte několik srovnávacích testů, abyste našli pro vás lepší možnost.
Kromě toho se možná budete chtít podívat do nastavení sítě sysctl. Nebudeme je podrobně rozebírat (dokumentaci najdete zde), ale obecnou myšlenkou je zvýšit vyrovnávací paměti, nevyřízené položky a časové limity, aby bylo snazší se vypořádat s blokováním a nestabilním připojením WAN.
net.core.optmem_max = 40960
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
net.core.netdev_max_backlog = 50000
net.ipv4.tcp_max_syn_backlog = 30000
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_mtu_probing = 1
net.ipv4.tcp_max_tw_buckets = 2000000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_slow_start_after_idle = 0Kromě ladění OS byste měli zvážit vyladění nastavení související se sítí Galera.
evs.suspect_timeout
evs.inactive_timeoutMožná budete chtít změnit výchozí hodnoty těchto proměnných. Oba časové limity určují, jak cluster vyřadí neúspěšné uzly. Podezřelý časový limit nastane, když všechny uzly nemohou dosáhnout neaktivního člena. Neaktivní časový limit definuje pevný limit, jak dlouho může uzel zůstat v clusteru, pokud neodpovídá. Obvykle zjistíte, že výchozí hodnoty fungují dobře. Ale v některých případech, zejména pokud provozujete cluster Galera přes WAN (například mezi oblastmi AWS), může zvýšení těchto proměnných vést ke stabilnějšímu výkonu. Doporučujeme nastavit oba na PT1M, aby bylo méně pravděpodobné, že nestabilita připojení WAN vyhodí uzel z clusteru.
evs.send_window
evs.user_send_windowTyto proměnné, evs.send_window a evs.user_send_window , definujte, kolik paketů lze odeslat prostřednictvím replikace současně (evs.send_window ) a kolik z nich může obsahovat data (evs.user_send_window ). U připojení s vysokou latencí může být vhodné tyto hodnoty výrazně zvýšit (například 512 nebo 1024).
evs.inactive_check_periodVýše uvedená proměnná může být také změněna. evs.inactive_check_period , ve výchozím nastavení je nastavena na jednu sekundu, což může být pro nastavení WAN příliš často. Doporučujeme jej nastavit na PT30S.
gcs.fc_factor
gcs.fc_limitZde chceme minimalizovat šance, že se spustí řízení toku, proto doporučujeme nastavit gcs.fc_factor na 1 a zvyšte gcs.fc_limit například na 260.
gcs.max_packet_sizeJelikož pracujeme s WAN linkou, kde je latence výrazně vyšší, chceme zvětšit velikost paketů. Dobrým výchozím bodem by bylo 2097152.
Jak jsme již zmínili, je prakticky nemožné poskytnout jednoduchý recept, jak tyto parametry nastavit, protože to závisí na příliš mnoha faktorech – budete si muset udělat vlastní benchmarky s použitím dat co nejblíže vašim výrobním datům, než budete můžete říci, že váš systém je vyladěn. Nicméně tato nastavení by vám měla poskytnout výchozí bod pro přesnější ladění.
To je pro tuto chvíli vše. Galera funguje docela dobře v prostředích WAN, tak to vyzkoušejte a dejte nám vědět, jak jste na tom.