Minulý týden jsem měl to potěšení zúčastnit se PGDay UK – velmi pěkná akce, doufám, že budu mít příležitost se příští rok vrátit. Bylo tam spousta zajímavých přednášek, ale mě zaujala zejména Performace pro dotazy se seskupením od Alexeje Bashtanova.
V minulosti jsem měl mnoho podobných přednášek zaměřených na výkon, takže vím, jak těžké je prezentovat výsledky benchmarků srozumitelným a zajímavým způsobem, a myslím, že Alexey odvedl docela dobrou práci. Pokud se tedy zabýváte agregací dat (tj. BI, analytiky nebo podobnými zátěžemi), doporučuji projít si snímky a pokud budete mít možnost zúčastnit se přednášky na nějaké jiné konferenci, vřele to doporučuji.
Ale je tu jeden bod, ve kterém s řečí nesouhlasím. Na mnoha místech řeč naznačovala, že byste měli obecně preferovat HashAggregate, protože řazení je pomalé.
Považuji to za trochu zavádějící, protože alternativou k HashAggregate je GroupAggregate, nikoli Sort. Doporučení tedy předpokládá, že každý GroupAggregate má vnořené řazení, ale to není tak docela pravda. GroupAggregate vyžaduje tříděný vstup a explicitní třídění není jediný způsob, jak toho dosáhnout – máme také uzly IndexScan a IndexOnlyScan, které eliminují náklady na třídění a zachovávají další výhody spojené s tříděnými cestami (zejména IndexOnlyScan).
Dovolte mi ukázat, jak si (IndexOnlyScan+GroupAggregate) vede ve srovnání s HashAggregate a (Sort+GroupAggregate) – skript, který jsem použil pro měření, je zde. Vytváří čtyři jednoduché tabulky, každou se 100 miliony řádků a různým počtem skupin ve sloupci „id_větve“ (určující velikost hashovací tabulky). Nejmenší má 10k skupin
-- tabulka s 10k groupcreate table t_10000 (branch_id bigint, number numeric);vložit do t_10000 select mod(i, 10000), random() from generation_series(1,100000000) s(i);
a tři další tabulky mají skupiny 100k, 1M a 5M. Spusťte tento jednoduchý dotaz agregující data:
SELECT branch_id, SUM(částka) FROM t_10000 GROUP BY 1
a poté přesvědčte databázi, aby použila tři různé plány:
1) HashAggregate
SET enable_sort =off;SET enable_hashagg =on;EXPLAIN SELECT branch_id, SUM(částka) FROM t_10000 GROUP BY 1; PLÁN DOTAZU------------------------------------------------ ---------------------------- HashAggregate (cena=2136943.00..2137067.99 řádků=9999 šířka=40) Klíč skupiny:branch_id -> Seq Skenujte na t_10000 (cena=0,00...1636943,00 řádků=100000000 šířka=19)(3 řádky)
2) GroupAggregate (s řazením)
SET enable_sort =on;SET enable_hashagg =off;EXPLAIN SELECT branch_id, SUM(částka) FROM t_10000 GROUP BY 1; PLÁN DOTAZU------------------------------------------------ ------------------------------ GroupAggregate (cena=16975438.38..17725563.37 řádků=9999 šířka=40) Klíč skupiny:branch_id -> Řadit (cena=16975438.38..17225438.38 řádků=100000000 šířka=19) Klíč řazení:branch_id -> Seq Scan on t_10000 (cena=0.00..1636943.00 řádků)0000 řádků00003) GroupAggregate (s IndexOnlyScan)
SET enable_sort =on;SET enable_hashagg =off;CREATE INDEX ON t_10000 (id_větve, částka);EXPLAIN SELECT id_větve, SUM(částka) FROM t_10000 GROUP BY 1; PLÁN DOTAZU------------------------------------------------ -------------------------- GroupAggregate (cena=0,57..3983129,56 řádků=9999 šířka=40) Klíč skupiny:branch_id -> Index Only Scan pomocí t_10000_branch_id_amount_idx na t_10000 (cena=0,57..3483004,57 řádků=100000000 šířka=19)(3 řádky)Výsledky
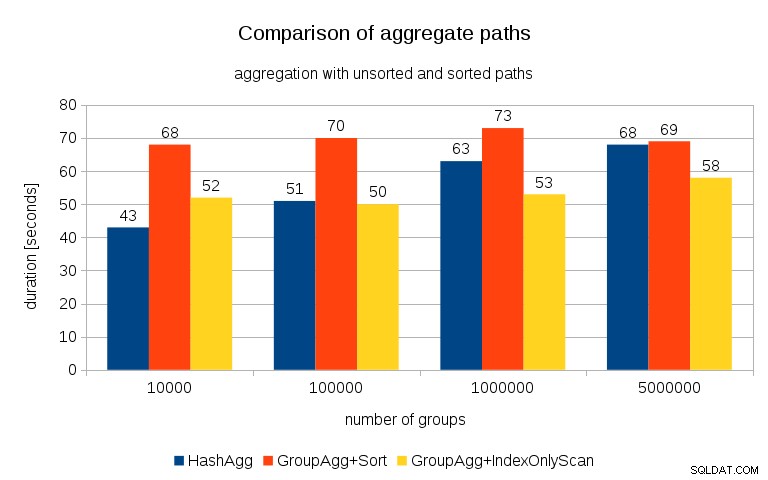
Po změření časování pro každý plán na všech tabulkách vypadají výsledky takto:
U malých hashovacích tabulek (vejdoucích se do L3 cache, která je v tomto případě 16MB) je cesta HashAggregate jednoznačně rychlejší než obě tříděné cesty. Ale brzy bude GroupAgg+IndexOnlyScan stejně rychlý nebo dokonce rychlejší – je to kvůli efektivitě mezipaměti, hlavní výhodě GroupAggregate. Zatímco HashAggregate potřebuje uchovávat celou hashovací tabulku v paměti najednou, GroupAggregate potřebuje pouze poslední skupinu. A čím méně paměti používáte, tím je pravděpodobnější, že se vejde do mezipaměti L3, která je zhruba o řád rychlejší ve srovnání s běžnou RAM (u mezipamětí L1/L2 je rozdíl ještě větší).
Takže ačkoli je s IndexOnlyScan spojena značná režie (v případě 10 000 je to asi o 20 % pomalejší než cesta HashAggregate), jak roste hashovací tabulka, poměr zásahů do mezipaměti L3 rychle klesá a rozdíl nakonec zrychluje GroupAggregate. A nakonec se dokonce i GroupAggregate+Sort dostane na stejnou úroveň jako cesta HashAggregate.
Můžete namítnout, že vaše data mají obecně poměrně nízký počet skupin, a proto se hashovací tabulka vždy vejde do mezipaměti L3. Ale zvažte, že mezipaměť L3 je sdílena všemi procesy běžícími na CPU a také všemi částmi plánu dotazů. Takže i když v současné době máme ~20 MB L3 cache na soket, váš dotaz dostane pouze část z toho a tento bit bude sdílen všemi uzly ve vašem (možná docela složitém) dotazu.
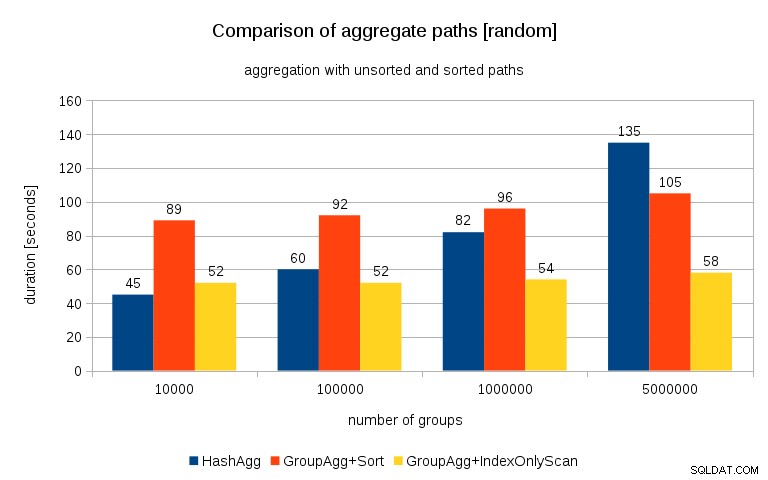
Aktualizace 26. 7. 2016 :Jak zdůraznil v komentářích Peter Geoghegan, způsob, jakým byla data generována, pravděpodobně vede ke korelaci – nikoli hodnoty (nebo spíše hashe hodnot), ale alokace paměti. Opakoval jsem dotazy se správně náhodně vybranými daty, tj. dělám
vložit do t_10000 select (10000*random())::bigint, random() from generation_series(1,100000000) s(i);místo
vložit do t_10000 select mod(i, 10000), random() from generation_series(1,100000000) s(i);a výsledky vypadají takto:
Když to porovnám s předchozím grafem, myslím, že je docela jasné, že výsledky jsou ještě více ve prospěch seřazených cest, zejména u souboru dat s 5M skupinami. 5M datový soubor také ukazuje, že GroupAgg s explicitním řazením může být rychlejší než HashAgg.
Shrnutí
Zatímco HashAggregate je pravděpodobně rychlejší než GroupAggregate s explicitním řazením (váhám říci, že je to tak vždy), rychlejší použití GroupAggregate s IndexOnlyScan může snadno urychlit mnohem rychleji než HashAggregate.
Samozřejmě si nemůžete vybrat přesný plán přímo – plánovač by to měl udělat za vás. Proces výběru však ovlivňujete (a) vytvořením indexů a (b) nastavením
work_mem. To je důvod, proč někdy nižšíwork_mem(amaintenance_work_mem) hodnoty vedou k lepšímu výkonu.Další indexy však nejsou zdarma – stojí jak čas CPU (při vkládání nových dat), tak místo na disku. Pro IndexOnlyScan mohou být požadavky na místo na disku poměrně významné, protože index musí zahrnovat všechny sloupce, na které se dotaz odkazuje, a běžný IndexScan by vám neposkytoval stejný výkon, protože generuje mnoho náhodných I/O proti tabulce (eliminuje všechny potenciální zisky).
Další příjemnou funkcí je stabilita výkonu – všimněte si, jak šance na časování HashAggregate závisí na počtu skupin, zatímco cesty GroupAggregate fungují většinou stejně.