Hodně se diskutovalo o In-Memory OLTP (funkce dříve známá jako „Hekaton“) a o tom, jak může pomoci velmi specifickým, velkoobjemovým úlohám. Uprostřed jiné konverzace jsem si náhodou všiml něčeho v CREATE TYPE dokumentaci pro SQL Server 2014, díky které jsem si myslel, že by mohl existovat obecnější případ použití:

Relativně tiché a neohlášené doplňky k dokumentaci CREATE TYPE
Na základě syntaktického diagramu se zdá, že parametry s hodnotou tabulky (TVP) lze optimalizovat pro paměť, stejně jako to umí trvalé tabulky. A s tím se kola okamžitě začala otáčet.
Jedna věc, pro kterou jsem používal TVP, je pomoci zákazníkům odstranit drahé metody dělení řetězců v T-SQL nebo CLR (viz pozadí v předchozích příspěvcích zde, zde a zde). V mých testech použití běžného TVP překonalo ekvivalentní vzory používající rozdělovací funkce CLR nebo T-SQL o významnou rezervu (25-50%). Logicky mě napadlo:Došlo by k nějakému zvýšení výkonu z TVP s optimalizovanou pamětí?
Obecně existují určité obavy ohledně In-Memory OLTP, protože existuje mnoho omezení a mezer ve funkcích, potřebujete samostatnou skupinu souborů pro data optimalizovaná pro paměť, musíte přesunout celé tabulky do optimalizované paměti a nejlepší výhodou je obvykle dosaženo také vytvořením nativně kompilovaných uložených procedur (které mají vlastní sadu omezení). Jak ukážu, za předpokladu, že váš typ tabulky obsahuje jednoduché datové struktury (např. představující sadu celých čísel nebo řetězců), použití této technologie pouze pro TVP eliminuje některé těchto problémů.
Test
Stále budete potřebovat skupinu souborů optimalizovanou pro paměť, i když nebudete vytvářet trvalé tabulky optimalizované pro paměť. Vytvořme tedy novou databázi s příslušnou strukturou:
CREATE DATABASE xtp; GO ALTER DATABASE xtp ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE xtp ADD FILE (name='xtpmod', filename='c:\...\xtp.mod') TO FILEGROUP xtp; GO ALTER DATABASE xtp SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT = ON; GO
Nyní můžeme vytvořit běžný typ tabulky, jako bychom to udělali dnes, a typ tabulky optimalizovaný pro paměť s neshlukovaným hash indexem a počtem segmentů, které jsem stáhl ze vzduchu (další informace o výpočtu požadavků na paměť a počtu segmentů skutečný svět zde):
USE xtp; GO CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Pokud to zkusíte v databázi, která nemá skupinu souborů s optimalizovanou pamětí, zobrazí se tato chybová zpráva, stejně jako byste se pokusili vytvořit normální tabulku s optimalizovanou pamětí:
Zpráva 41337, úroveň 16, stav 0, řádek 9Skupina souborů MEMORY_OPTIMIZED_DATA neexistuje nebo je prázdná. Tabulky optimalizované pro paměť nelze vytvořit pro databázi, dokud nemá jednu skupinu souborů MEMORY_OPTIMIZED_DATA, která není prázdná.
Abych otestoval dotaz proti běžné tabulce, která není optimalizována pro paměť, jednoduše jsem natáhl některá data do nové tabulky ze vzorové databáze AdventureWorks2012 pomocí SELECT INTO ignorovat všechna ta otravná omezení, indexy a rozšířené vlastnosti, pak jsem vytvořil seskupený index ve sloupci, o kterém jsem věděl, že budu hledat (ProductID ):
SELECT * INTO dbo.Products FROM AdventureWorks2012.Production.Product; -- 504 rows CREATE UNIQUE CLUSTERED INDEX p ON dbo.Products(ProductID);
Dále jsem vytvořil čtyři uložené procedury:dvě pro každý typ tabulky; každý pomocí EXISTS a JOIN přístupy (obvykle rád zkoumám oba, i když preferuji EXISTS; později uvidíte, proč jsem nechtěl omezit své testování pouze na EXISTS ). V tomto případě pouze přiřadím libovolný řádek proměnné, abych mohl pozorovat vysoký počet provedení, aniž bych se zabýval sadami výsledků a dalším výstupem a režií:
-- Old-school TVP using EXISTS:
CREATE PROCEDURE dbo.ClassicTVP_Exists
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @Classic AS t
WHERE t.Item = p.ProductID
);
END
GO
-- In-Memory TVP using EXISTS:
CREATE PROCEDURE dbo.InMemoryTVP_Exists
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
WHERE EXISTS
(
SELECT 1 FROM @InMemory AS t
WHERE t.Item = p.ProductID
);
END
GO
-- Old-school TVP using a JOIN:
CREATE PROCEDURE dbo.ClassicTVP_Join
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @Classic AS t
ON t.Item = p.ProductID;
END
GO
-- In-Memory TVP using a JOIN:
CREATE PROCEDURE dbo.InMemoryTVP_Join
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @name NVARCHAR(50);
SELECT @name = p.Name
FROM dbo.Products AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO
Dále jsem potřeboval simulovat druh dotazu, který se obvykle vyskytuje u tohoto typu tabulky a vyžaduje na prvním místě TVP nebo podobný vzor. Představte si formulář s rozevíracím seznamem nebo sadou zaškrtávacích políček obsahujících seznam produktů a uživatel si může vybrat 20 nebo 50 nebo 200, které chce porovnat, vypsat, co máte. Hodnoty nebudou v pěkné souvislé množině; obvykle budou rozptýleny všude (pokud by šlo o předvídatelně souvislý rozsah, dotaz by byl mnohem jednodušší:počáteční a koncové hodnoty). Vybral jsem tedy z tabulky libovolných 20 hodnot (ve snaze zůstat pod, řekněme, 5 % velikosti tabulky), seřazených náhodně. Snadný způsob, jak vytvořit opakovaně použitelné VALUES taková klauzule je následující:
DECLARE @x VARCHAR(4000) = '';
SELECT TOP (20) @x += '(' + RTRIM(ProductID) + '),'
FROM dbo.Products ORDER BY NEWID();
SELECT @x; Výsledky (vaše se budou téměř jistě lišit):
(725),(524),(357),(405),(477),(821),(323),(526),(952),(473),(442),(450),(735) ),(441),(409),(454),(780),(966),(988),(512),
Na rozdíl od přímého INSERT...SELECT , takže je docela snadné manipulovat s tímto výstupem do znovu použitelného příkazu, aby se naše TVP opakovaně naplnily stejnými hodnotami a během několika iterací testování:
SET NOCOUNT ON; DECLARE @ClassicTVP dbo.ClassicTVP; DECLARE @InMemoryTVP dbo.InMemoryTVP; INSERT @ClassicTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); INSERT @InMemoryTVP(Item) VALUES (725),(524),(357),(405),(477),(821),(323),(526),(952),(473), (442),(450),(735),(441),(409),(454),(780),(966),(988),(512); EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP; EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP; EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;InMemoryTV
Pokud tuto dávku spustíme pomocí SQL Sentry Plan Explorer, výsledné plány ukazují velký rozdíl:TVP v paměti je schopen použít spojení vnořených smyček a 20 jednořádkových klastrovaných indexových hledání, oproti slučovacímu spojení napájenému 502 řádky clusterovaný index skenování pro klasický TVP. A v tomto případě EXISTS a JOIN přinesly totožné plány. To může tipovat mnohem vyšší počet hodnot, ale pokračujme s předpokladem, že počet hodnot bude menší než 5 % velikosti tabulky:
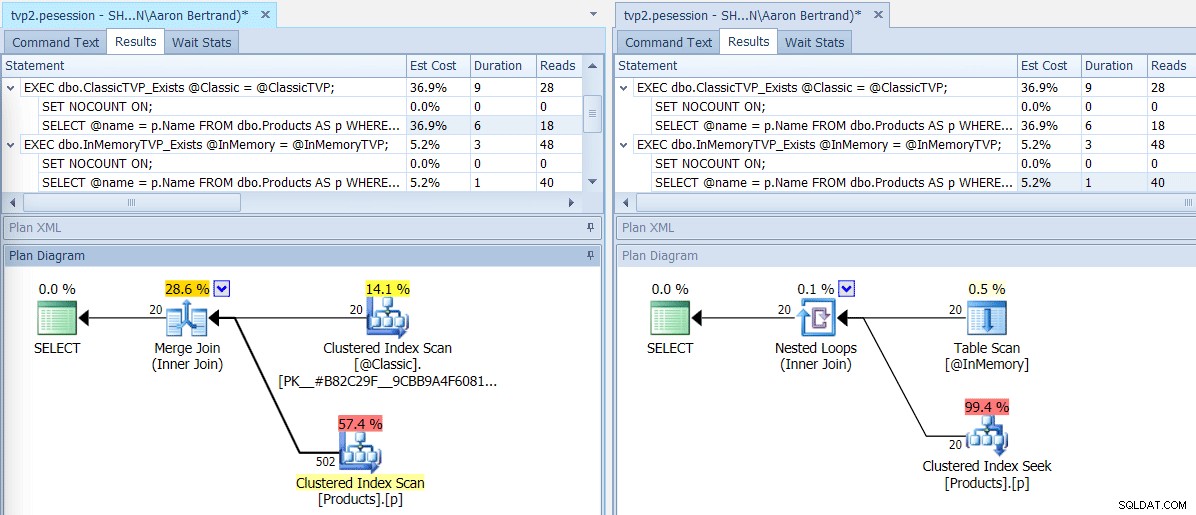 Plány pro klasické TVP a TVP v paměti
Plány pro klasické TVP a TVP v paměti
 Popisky pro operátory skenování/hledání, zdůrazňující hlavní rozdíly – Klasické vlevo, In- Paměť vpravo
Popisky pro operátory skenování/hledání, zdůrazňující hlavní rozdíly – Klasické vlevo, In- Paměť vpravo
Co to tedy znamená v měřítku? Pojďme vypnout jakoukoli sbírku showplanu a mírně změňte testovací skript, aby každou proceduru spustil 100 000krát a ručně zachytil kumulativní běh:
DECLARE @i TINYINT = 1, @j INT = 1;
WHILE @i <= 4
BEGIN
SELECT SYSDATETIME();
WHILE @j <= 100000
BEGIN
IF @i = 1
BEGIN
EXEC dbo.ClassicTVP_Exists @Classic = @ClassicTVP;
END
IF @i = 2
BEGIN
EXEC dbo.InMemoryTVP_Exists @InMemory = @InMemoryTVP;
END
IF @i = 3
BEGIN
EXEC dbo.ClassicTVP_Join @Classic = @ClassicTVP;
END
IF @i = 4
BEGIN
EXEC dbo.InMemoryTVP_Join @InMemory = @InMemoryTVP;
END
SET @j += 1;
END
SELECT @i += 1, @j = 1;
END
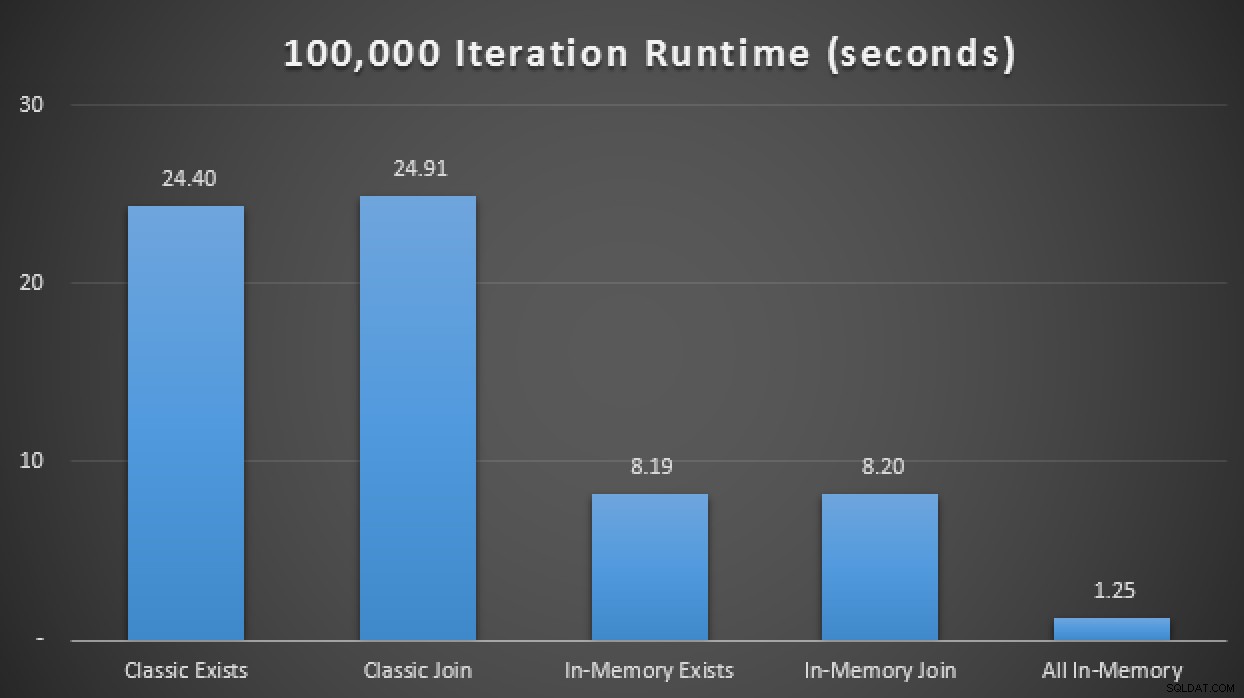
SELECT SYSDATETIME(); Ve výsledcích, v průměru za 10 spuštění, vidíme, že alespoň v tomto omezeném testovacím případě použití typu tabulky optimalizované pro paměť přineslo zhruba trojnásobné zlepšení pravděpodobně nejkritičtější metriky výkonu v OLTP (doba běhu):
Výsledky za běhu ukazují 3x zlepšení s in-Memory TVP
In-Memory + In-Memory + In-Memory:Počátek v paměti
Nyní, když jsme viděli, co můžeme udělat jednoduchou změnou našeho běžného typu tabulky na typ tabulky optimalizované pro paměť, podívejme se, zda dokážeme ze stejného vzoru dotazu vymáčknout další výkon, když použijeme trifecta:in-memory tabulky pomocí nativně zkompilované uložené procedury optimalizované pro paměť, která akceptuje tabulku tabulky v paměti jako parametr s hodnotou tabulky.
Nejprve musíme vytvořit novou kopii tabulky a naplnit ji z místní tabulky, kterou jsme již vytvořili:
CREATE TABLE dbo.Products_InMemory ( ProductID INT NOT NULL, Name NVARCHAR(50) NOT NULL, ProductNumber NVARCHAR(25) NOT NULL, MakeFlag BIT NOT NULL, FinishedGoodsFlag BIT NULL, Color NVARCHAR(15) NULL, SafetyStockLevel SMALLINT NOT NULL, ReorderPoint SMALLINT NOT NULL, StandardCost MONEY NOT NULL, ListPrice MONEY NOT NULL, [Size] NVARCHAR(5) NULL, SizeUnitMeasureCode NCHAR(3) NULL, WeightUnitMeasureCode NCHAR(3) NULL, [Weight] DECIMAL(8, 2) NULL, DaysToManufacture INT NOT NULL, ProductLine NCHAR(2) NULL, [Class] NCHAR(2) NULL, Style NCHAR(2) NULL, ProductSubcategoryID INT NULL, ProductModelID INT NULL, SellStartDate DATETIME NOT NULL, SellEndDate DATETIME NULL, DiscontinuedDate DATETIME NULL, rowguid UNIQUEIDENTIFIER NULL, ModifiedDate DATETIME NULL, PRIMARY KEY NONCLUSTERED HASH (ProductID) WITH (BUCKET_COUNT = 256) ) WITH ( MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA ); INSERT dbo.Products_InMemory SELECT * FROM dbo.Products;
Dále vytvoříme nativně zkompilovanou uloženou proceduru, která vezme náš stávající typ tabulky optimalizované pro paměť jako TVP:
CREATE PROCEDURE dbo.InMemoryProcedure
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @Name NVARCHAR(50);
SELECT @Name = Name
FROM dbo.Products_InMemory AS p
INNER JOIN @InMemory AS t
ON t.Item = p.ProductID;
END
GO Pár upozornění. Nemůžeme použít běžný typ tabulky, který není optimalizován pro paměť, jako parametr nativně kompilované uložené procedury. Pokud to zkusíme, dostaneme:
Msg 41323, Level 16, State 1, Procedure InMemoryProcedureTyp tabulky 'dbo.ClassicTVP' není typ tabulky optimalizované pro paměť a nelze jej použít v nativně kompilované uložené proceduře.
Také nemůžeme použít EXISTS vzor i zde; když to zkusíme, dostaneme:
Poddotazy (dotazy vnořené do jiného dotazu) nejsou podporovány nativně kompilovanými uloženými procedurami.
S In-Memory OLTP a nativně kompilovanými uloženými procedurami existuje mnoho dalších upozornění a omezení, jen jsem se chtěl podělit o pár věcí, které by se mohly zdát, že v testování evidentně chybí.
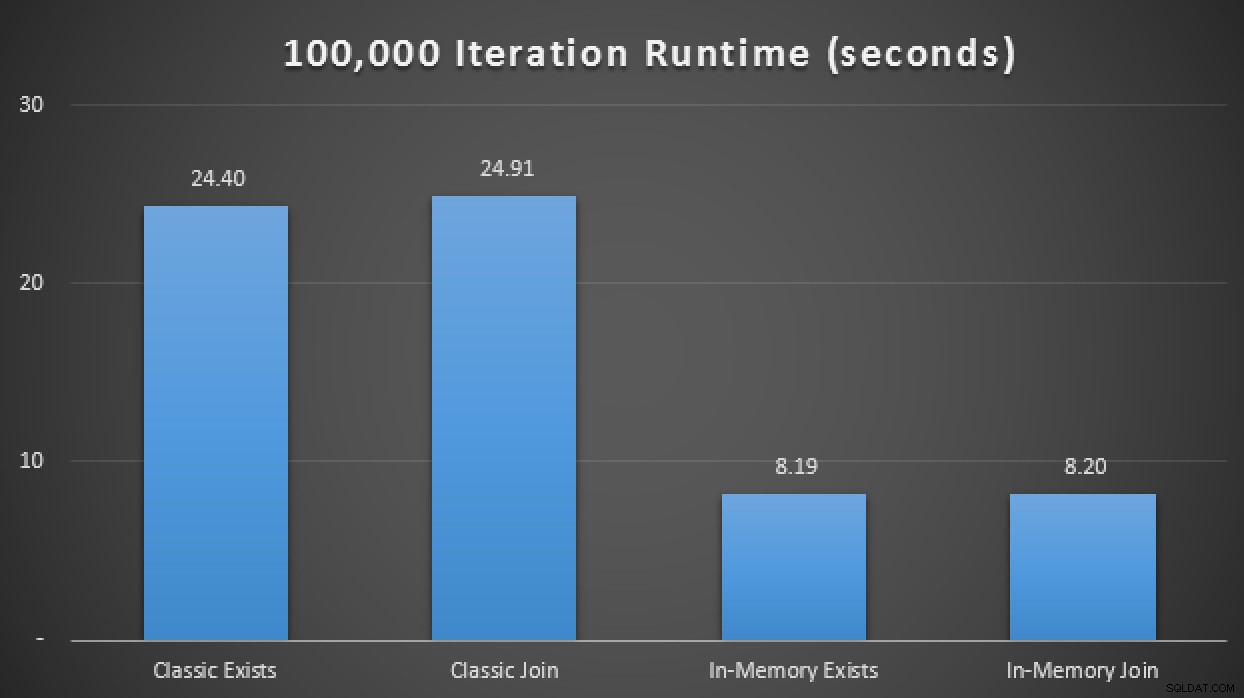
Takže přidáním této nové nativně zkompilované uložené procedury do výše uvedené testovací matice jsem zjistil, že – opět v průměru za 10 běhů – provedla 100 000 iterací za pouhých 1,25 sekundy. To představuje zhruba 20násobné zlepšení oproti běžným TVP a 6-7násobné zlepšení oproti TVP v paměti pomocí tradičních tabulek a postupů:
Výsledky běhu ukazující až 20násobné zlepšení díky In-Memory všude kolem
Závěr
Pokud nyní používáte TVP nebo používáte vzory, které by mohly být nahrazeny TVP, musíte bezpodmínečně zvážit přidání paměťově optimalizovaných TVP do vašich plánů testování, ale mějte na paměti, že ve vašem scénáři možná nezaznamenáte stejná vylepšení. (A samozřejmě je třeba mít na paměti, že TVP obecně mají mnoho výhrad a omezení a také nejsou vhodné pro všechny scénáře. Erland Sommarskog má skvělý článek o dnešních TVP zde.)
Ve skutečnosti můžete vidět, že na spodní hranici hlasitosti a souběžnosti není žádný rozdíl – ale prosím otestujte v reálném měřítku. Jednalo se o velmi jednoduchý a vykonstruovaný test na moderním notebooku s jedním SSD, ale když mluvíte o skutečném objemu a/nebo rotujících mechanických discích, tyto výkonnostní charakteristiky mohou mít mnohem větší váhu. Následuje pokračování s ukázkami větších datových velikostí.