Tento článek ukazuje, jak SQL Server kombinuje informace o hustotě z více statistik s jedním sloupcem, aby vytvořil odhad mohutnosti pro agregaci ve více sloupcích. Podrobnosti jsou snad samy o sobě zajímavé. Poskytují také vhled do některých obecných přístupů a algoritmů používaných estimátorem mohutnosti.
Zvažte následující vzorový databázový dotaz AdventureWorks, který uvádí počet položek inventáře produktů v každé přihrádce na každé polici ve skladu:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin;
Odhadovaný plán provádění ukazuje 1 069 čtených řádků z tabulky, seřazených do Shelf a Bin objednávka, poté agregována pomocí operátoru Stream Aggregate:
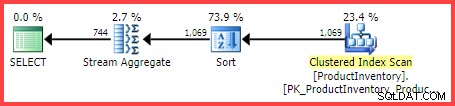
Odhadovaný plán provádění
Otázkou je, jak optimalizátor dotazů SQL Server dospěl ke konečnému odhadu 744 řádků?
Dostupné statistiky
Při sestavování výše uvedeného dotazu vytvoří optimalizátor dotazů na Shelf statistiku s jedním sloupcem. a Bin sloupců, pokud vhodné statistiky ještě neexistují. Tyto statistiky mimo jiné poskytují informace o počtu odlišných hodnot sloupců (ve vektoru hustoty):
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Shelf]
)
WITH DENSITY_VECTOR;
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Bin]
)
WITH DENSITY_VECTOR; Výsledky jsou shrnuty v tabulce níže (třetí sloupec je vypočítán z hustoty):
| Sloupec | Hustota | 1 / Hustota |
|---|---|---|
| Polička | 0,04761905 | 21 |
| Bin | 0,01612903 | 62 |
Vektorové informace o hustotě polic a přihrádek
Jak uvádí dokumentace, převrácená hodnota hustoty je počet odlišných hodnot ve sloupci. Z výše uvedených statistických informací SQL Server ví, že existovalo 21 různých Shelf hodnot a 62 různých Bin hodnoty v tabulce, kdy byly statistiky shromážděny.
Úkol odhadnout počet řádků vytvořených GROUP BY klauzule je triviální, když je zahrnut pouze jeden sloupec (za předpokladu, že žádné další predikáty). Je například snadné vidět, že GROUP BY Shelf vytvoří 21 řádků; GROUP BY Bin vyrobí 62.
Není však okamžitě jasné, jak může SQL Server odhadnout počet různých (Shelf, Bin) kombinace pro naši GROUP BY Shelf, Bin dotaz. Položenou otázku trochu jinak:Kolik unikátních kombinací polic a přihrádek bude při 21 policích a 62 přihrádkách? Pomineme-li fyzické aspekty a další lidské znalosti problémové domény, odpověď by mohla být kdekoli od max(21, 62) =62 do (21 * 62) =1 302. Bez dalších informací neexistuje žádný zřejmý způsob, jak zjistit, kde v tomto rozsahu odhadnout.
Přesto v našem příkladu dotazu SQL Server odhaduje 744,312 řádků (zaokrouhleno na 744 v zobrazení Průzkumník plánu), ale na jakém základě?
Rozšířená událost odhadu mohutnosti
Zdokumentovaný způsob, jak nahlédnout do procesu odhadu mohutnosti, je použít Extended Event query_optimizer_estimate_cardinality (přestože je v kanálu "ladění"). Zatímco relace shromažďující tuto událost běží, operátoři prováděcího plánu získají další vlastnost StatsCollectionId který spojuje odhady jednotlivých operátorů s výpočty, které je vytvořily. V našem příkladu dotazu je ID sběru statistik 2 propojeno s odhadem mohutnosti pro skupinu podle agregovaného operátora.
Relevantní výstup z Extended Event pro náš testovací dotaz je:
<data name="calculator">
<type name="xml" package="package0"></type>
<value>
<CalculatorList>
<DistinctCountCalculator CalculatorName="CDVCPlanLeaf" SingleColumnStat="Shelf,Bin" />
</CalculatorList>
</value>
</data>
<data name="stats_collection">
<type name="xml" package="package0"></type>
<value>
<StatsCollection Name="CStCollGroupBy" Id="2" Card="744.31">
<LoadedStats>
<StatsInfo DbId="6" ObjectId="258099960" StatsId="3" />
<StatsInfo DbId="6" ObjectId="258099960" StatsId="4" />
</LoadedStats>
</StatsCollection>
</value>
</data> Určitě tam jsou nějaké užitečné informace.
Vidíme, že třída kalkulačky různých hodnot plánu listů (CDVCPlanLeaf ) byla použita s použitím jednosloupcové statistiky na Shelf a Bin jako vstupy. Prvek shromažďování statistik odpovídá tomuto fragmentu k id (2) zobrazenému v plánu provádění, který ukazuje odhad mohutnosti 744,31 a další informace o použitých ID objektů statistiky.
Bohužel ve výstupu události není nic, co by přesně říkalo, jak kalkulačka dospěla ke konečnému číslu, což je věc, která nás skutečně zajímá.
Kombinace různých počtů
Pokud půjdeme méně zdokumentovanou cestou, můžeme požádat o odhadovaný plán pro dotaz s příznaky trasování 2363 a 3604 povoleno:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin
OPTION (QUERYTRACEON 3604, QUERYTRACEON 2363); Tím se vrátí informace o ladění na kartu Zprávy v SQL Server Management Studio. Zajímavá část je reprodukována níže:
Begin distinct values computation
Input tree:
LogOp_GbAgg OUT(QCOL: [INV].Shelf,QCOL: [INV].Bin,COL: Expr1001 ,) BY(QCOL: [INV].Shelf,QCOL: [INV].Bin,)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_AggFunc stopCountBig
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=0)
Plan for computation:
CDVCPlanLeaf
0 Multi-Column Stats, 2 Single-Column Stats, 0 Guesses
Loaded histogram for column QCOL: [INV].Shelf from stats with id 3
Loaded histogram for column QCOL: [INV].Bin from stats with id 4
Using ambient cardinality 1069 to combine distinct counts:
21
62
Combined distinct count: 744.312
Result of computation: 744.312
Stats collection generated:
CStCollGroupBy(ID=2, CARD=744.312)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
End distinct values computation To zobrazuje téměř stejné informace jako Extended Event v (pravděpodobně) snazším formátu:
- Vstupní relační operátor pro výpočet odhadu mohutnosti pro (
LogOp_GbAgg– logická skupina podle agregace) - Použitá kalkulačka (
CDVCPlanLeaf) a vstupní statistiky - Výsledné podrobnosti shromažďování statistik
Zajímavou novou informací je část o využití mohutnosti okolního prostředí ke kombinaci různých počtů .
To jasně ukazuje, že byly použity hodnoty 21, 62 a 1069, ale (frustrující) stále není přesně to, které výpočty byly provedeny, aby se dospělo k 744.312 výsledek.
Do Debuggeru!
Připojení ladicího programu a použití veřejných symbolů nám umožňuje podrobně prozkoumat cestu kódu, kterou jsme použili při kompilaci příkladu dotazu.
Snímek níže ukazuje horní část zásobníku volání v reprezentativním bodě procesu:
MSVCR120!log sqllang!OdblNHlogN sqllang!CCardUtilSQL12::ProbSampleWithoutReplacement sqllang!CCardUtilSQL12::CardDistinctMunged sqllang!CCardUtilSQL12::CardDistinctCombined sqllang!CStCollAbstractLeaf::CardDistinctImpl sqllang!IStatsCollection::CardDistinct sqllang!CCardUtilSQL12::CardGroupByHelperCore sqllang!CCardUtilSQL12::PstcollGroupByHelper sqllang!CLogOp_GbAgg::PstcollDeriveCardinality sqllang!CCardFrameworkSQL12::DeriveCardinalityProperties
Je zde několik zajímavých detailů. Při práci zdola nahoru vidíme, že mohutnost je odvozena pomocí aktualizovaného CE (CCardFrameworkSQL12 ) dostupné v SQL Server 2014 a novějších (původní CE je CCardFrameworkSQL7 ), pro skupinu podle agregovaného logického operátoru (CLogOp_GbAgg ).
Výpočet odlišné mohutnosti zahrnuje kombinování (mungování) více vstupů pomocí vzorkování bez náhrady.
Odkaz na H a (přirozený) logaritmus ve druhé metodě shora ukazuje použití Shannonovy entropie ve výpočtu:
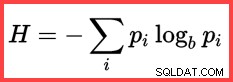
Shannonova entropie
Entropii lze použít k odhadu informační korelace (vzájemné informace) mezi dvěma statistikami:
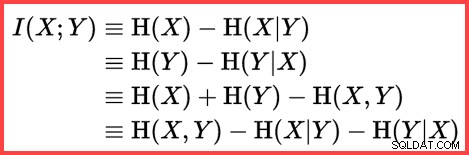
Vzájemné informace
Když to všechno dáme dohromady, můžeme sestavit výpočetní skript T-SQL odpovídající způsobu, jakým SQL Server používá vzorkování bez náhrady, Shannonova entropie a vzájemné informace k vytvoření konečného odhadu mohutnosti.
Začneme vstupními čísly (kardinalita okolí a počet odlišných hodnot v každém sloupci):
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62; frekvence v každém sloupci je průměrný počet řádků na odlišnou hodnotu:
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2; Vzorkování bez náhrady (SWR) je jednoduchá záležitost odečtení průměrného počtu řádků na odlišnou hodnotu (frekvenci) od celkového počtu řádků:
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2; Vypočítejte entropie (N log N) a vzájemné informace:
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Using logarithms allows us to express
-- multiplication as addition and division as subtraction
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4); Nyní jsme odhadli, jak korelované jsou tyto dvě sady statistik, můžeme vypočítat konečný odhad:
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2;
Výsledek výpočtu je 744,311823994677, což je 744,312 zaokrouhleno na tři desetinná místa.
Pro usnadnění je zde celý kód v jednom bloku:
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62;
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2;
-- Sample without replacement
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2;
-- Entropy
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Mutual information
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4);
-- Final estimate
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2; Poslední myšlenky
Konečný odhad je v tomto případě nedokonalý – příkladový dotaz ve skutečnosti vrací 441 řádky.
Abychom získali lepší odhad, mohli bychom optimalizátoru poskytnout lepší informace o hustotě Bin a Shelf sloupců pomocí vícesloupcové statistiky. Například:
CREATE STATISTICS stat_Shelf_Bin ON Production.ProductInventory (Shelf, Bin);
S touto statistikou (buď tak, jak je daná, nebo jako vedlejší účinek přidání podobného vícesloupcového indexu) je odhad mohutnosti pro příkladový dotaz přesně správný. Je však vzácné vypočítat tak jednoduchou agregaci. S dalšími predikáty může být vícesloupcová statistika méně účinná. Nicméně je důležité mít na paměti, že dodatečné informace o hustotě poskytované vícesloupcovými statistikami mohou být užitečné pro agregace (stejně jako pro srovnání rovnosti).
Bez vícesloupcové statistiky může být agregační dotaz s dalšími predikáty stále schopen používat základní logiku uvedenou v tomto článku. Například namísto použití vzorce na mohutnost tabulky jej lze použít na vstupní histogramy krok za krokem.
Související obsah:Odhad mohutnosti predikátu na výrazu COUNT