Vaše povinnosti jako DBA (nebo DBCC CHECKDB . Můžete se tam dostat vytvořením jednoduchého plánu údržby pomocí „Úkolu kontroly integrity databáze“ – nicméně podle mého názoru je to pouze zaškrtnutí políčka.
Pokud se podíváte blíže, je velmi málo, co můžete udělat, abyste mohli ovládat, jak úkol funguje. Dokonce i poměrně rozsáhlý panel Vlastnosti odhaluje spoustu nastavení pro dílčí plán údržby, ale prakticky nic o DBCC příkazy bude spuštěn. Osobně si myslím, že byste měli zaujmout mnohem proaktivnější a kontrolovanější přístup k tomu, jak provádíte CHECKDB operace v produkčním prostředí, vytvářením vlastních zakázek a ruční ruční výrobou DBCC příkazy. Svůj rozvrh nebo samotné příkazy můžete přizpůsobit různým databázím – například členská databáze ASP.NET pravděpodobně není tak zásadní jako vaše prodejní databáze a mohla by tolerovat méně časté a/nebo méně důkladné kontroly.
Ale pro vaše klíčové databáze jsem si myslel, že dám dohromady příspěvek s podrobnostmi o některých věcech, které bych prošetřil, abych minimalizoval narušení DBCC příkazy mohou způsobit – a před jakými mýty a marketingovými humbuky byste se měli mít na pozoru. A chci poděkovat Paulovi „Mr. DBCC“ Randalovi (@PaulRandal) za poskytnutí cenného příspěvku – nejen k tomuto konkrétnímu příspěvku, ale také za nekonečné rady, které poskytuje na svém blogu #sqlhelp a při školení SQLskills Immersion.
Berte prosím všechny tyto nápady s rezervou a snažte se provést odpovídající testování ve vašem prostředí – ne všechny tyto návrhy povedou k lepšímu výkonu ve všech prostředích. Dlužíte však sobě, svým uživatelům a zainteresovaným stranám, abyste alespoň zvážili dopad, který vaše CHECKDB operace by mohly mít, a učiňte kroky ke zmírnění těchto účinků, kde je to proveditelné – bez zavedení zbytečného rizika tím, že nebudete kontrolovat správné věci.
Snižte hluk a spotřebujte všechny chyby
Bez ohledu na to, kde používáte CHECKDB , vždy použijte WITH NO_INFOMSGS volba. To jednoduše potlačí veškerý irelevantní výstup, který vám jen říká, kolik řádků je v každé tabulce; pokud vás tyto informace zajímají, můžete je získat z jednoduchých dotazů na DMV a ne během DBCC běží. Potlačením výstupu je mnohem méně pravděpodobné, že zmeškáte kritickou zprávu pohřbenou ve všem tom šťastném výstupu.
Podobně byste vždy měli používat WITH ALL_ERRORMSGS možnost, ale zejména pokud používáte SQL Server 2008 RTM nebo SQL Server 2005 (v těchto případech se může zobrazit seznam chyb pro jednotlivé objekty zkrácen na 200). Pro všechny CHECKDB jiné operace než rychlé ad-hoc kontroly, měli byste zvážit směrování výstupu do souboru. Management Studio je omezeno na 1000 řádků výstupu z DBCC CHECKDB , takže pokud toto číslo překročíte, můžete přijít o některé chyby.
I když se nejedná výhradně o problém s výkonem, použití těchto možností zabrání tomu, abyste museli proces spouštět znovu. To je zvláště důležité, pokud jste uprostřed obnovy po havárii.
Pokud je to možné, stáhněte logické kontroly
Ve většině případů CHECKDB tráví většinu času prováděním logických kontrol dat. Pokud máte možnost provést tyto kontroly na pravé kopii dat, můžete zaměřit své úsilí na fyzickou strukturu svých produkčních systémů a použít sekundární server ke zpracování všech logických kontrol a zmírnění zátěže z primárního. Prostřednictvím sekundárního serveru , mám na mysli pouze následující:
- Místo, kde testujete své úplné obnovení – protože testujete své obnovy, že?
Jiní lidé (zejména monstrózní marketingová síla, kterou je Microsoft) vás možná přesvědčili, že pro DBCC jsou vhodné jiné formy sekundárních serverů. kontroly. Například:
- sekundární čitelná skupina dostupnosti AlwaysOn;
- snímek zrcadlené databáze;
- protokol byl dodán jako sekundární;
- zrcadlení SAN;
- nebo jiné varianty…
Bohužel tomu tak není a žádný z těchto sekundárních není platným a spolehlivým místem, kde byste mohli provádět vaše kontroly jako alternativu k primárnímu. Jako věrná kopie může sloužit pouze záloha jedna za jednu; nic jiného, co se spoléhá na věci, jako je aplikace záloh protokolů, aby se dostal do konzistentního stavu, nebude spolehlivě odrážet problémy s integritou na primární.
Takže raději než se pokoušet přenést své logické kontroly na sekundární a nikdy je neprovádět na primární, navrhuji toto:
- Ujistěte se, že často testujete obnovení svých úplných záloh. A ne, to nezahrnuje
COPY_ONLYzálohy ze sekundárního AG ze stejných důvodů jako výše – to by bylo platné pouze v případě, kdy jste právě spustili sekundární s úplným obnovením. - Spusťte
DBCC CHECKDBčasto proti plné obnovit, než uděláte cokoliv jiného. Opět platí, že přehrání záznamů protokolu v tomto okamžiku zruší platnost této databáze jako pravé kopie zdroje. - Spusťte
DBCC CHECKDBproti vašemu primárnímu, možná rozděleni způsoby, které navrhuje Paul Randal, a/nebo méně často a/nebo pomocíPHYSICAL_ONLYčastěji než ne. To může záviset na tom, jak často a jak spolehlivě podáváte výkon (2). - Nikdy nepředpokládejte, že kontroly proti sekundárním jsou dostatečné. I v případě přesné repliky vaší primární databáze stále existují fyzické problémy, které se mohou vyskytnout na I/O subsystému vaší primární databáze a které se nikdy nepřenesou do sekundární.
- Vždy analyzujte
DBCCvýstup. Pouhé spuštění a ignorování, zaškrtnutí v nějakém seznamu, je stejně užitečné jako spouštění záloh a prohlašování úspěchu, aniž byste kdy testovali, zda skutečně můžete zálohu v případě potřeby obnovit.
Experiment s příznaky trasování 2549, 2562 a 2566
Provedl jsem nějaké důkladné testování dvou příznaků trasování (2549 a 2562) a zjistil jsem, že mohou přinést podstatná zlepšení výkonu, nicméně Lonny hlásí, že již nejsou nutné nebo užitečné. Pokud používáte rok 2016 nebo novější, přeskočte celou tuto sekci . Pokud používáte starší verzi, tyto dva příznaky trasování jsou popsány mnohem podrobněji v KB #2634571, ale v zásadě:
- Trace Flag 2549
- Toto optimalizuje proces checkdb tím, že každý jednotlivý databázový soubor považuje za umístěný na jedinečném základním disku. Toto je v pořádku použít, pokud má vaše databáze jeden datový soubor nebo pokud víte, že každý databázový soubor je ve skutečnosti na samostatné jednotce. Pokud má vaše databáze více souborů a ty sdílejí jedno, přímo připojené vřeteno, měli byste si dávat pozor na tento příznak trasování, protože může způsobit více škody než užitku.
DŮLEŽITÉ :sql.sasquatch hlásí regresi v tomto chování příznaku trasování v SQL Server 2014.
- Toto optimalizuje proces checkdb tím, že každý jednotlivý databázový soubor považuje za umístěný na jedinečném základním disku. Toto je v pořádku použít, pokud má vaše databáze jeden datový soubor nebo pokud víte, že každý databázový soubor je ve skutečnosti na samostatné jednotce. Pokud má vaše databáze více souborů a ty sdílejí jedno, přímo připojené vřeteno, měli byste si dávat pozor na tento příznak trasování, protože může způsobit více škody než užitku.
- Trace Flag 2562
- Tento příznak považuje celý proces checkdb za jednu dávku za cenu vyššího využití databáze tempdb (až 5 % velikosti databáze).
- Používá lepší algoritmus k určení, jak číst stránky z databáze, a snižuje tak spory o blokování (konkrétně pro
DBCC_MULTIOBJECT_SCANNER). Všimněte si, že toto konkrétní vylepšení je v cestě kódu SQL Server 2012, takže z něj budete mít prospěch i bez příznaku trasování. Můžete se tak vyhnout chybám, jako jsou:
Při čekání na blokování došlo k vypršení časového limitu:class 'DBCC_MULTIOBJECT_SCANNER'.
- Výše uvedené dva příznaky trasování jsou dostupné v následujících verzích:
- SQL Server 2008 Service Pack 2 Kumulativní aktualizace 9+
(10.00.4330 -> 10.00.5499)SQL Server 2008 Service Pack 3 Kumulativní aktualizace 4+
(10.00.5775+)SQL Server 2008 R2 RTM Kumulativní aktualizace 11+
(10.50.1809 -> 10.50.2424)SQL Server 2008 R2 Service Pack 1 kumulativní aktualizace 4+
(10.50.2796 -> 10.50.3999)SQL Server 2008 R2 Service Pack 2
(10 50 4000+)SQL Server 2012, všechny verze
(11.00.2100+) - Trace Flag 2566
- Pokud stále používáte SQL Server 2005, tento příznak trasování, představený v roce 2005 SP2 CU#9 (9.00.3282) (ačkoli není zdokumentován v článku znalostní báze této Kumulativní aktualizace, KB #953752), se pokouší napravit špatný výkon z
DATA_PURITYkontroluje systémy založené na x64. V jednu chvíli jste mohli vidět více podrobností v KB #945770, ale zdá se, že článek byl smazán jak z webu podpory Microsoftu, tak ze stroje WayBack. Tento příznak trasování by v modernějších verzích SQL Serveru neměl být nutný, protože problém v procesoru dotazů byl vyřešen.
- Pokud stále používáte SQL Server 2005, tento příznak trasování, představený v roce 2005 SP2 CU#9 (9.00.3282) (ačkoli není zdokumentován v článku znalostní báze této Kumulativní aktualizace, KB #953752), se pokouší napravit špatný výkon z
Pokud se chystáte použít některý z těchto příznaků trasování, velmi doporučuji je nastavit na úrovni relace pomocí DBCC TRACEON spíše než jako příznak trasování při spuštění. Nejen, že vám umožňuje vypnout je bez nutnosti přepínat SQL Server, ale také vám umožňuje implementovat je pouze při provádění určitých CHECKDB příkazy, na rozdíl od operací využívajících jakýkoli typ opravy.
Snížení dopadu I/O:optimalizace databáze tempdb
DBCC CHECKDB může intenzivně využívat tempdb, takže se ujistěte, že tam plánujete využití zdrojů. To je obvykle dobré udělat v každém případě. Pro CHECKDB budete chtít správně alokovat prostor pro tempdb; poslední věc, kterou chcete, je CHECKDB pokrok (a jakékoli další souběžné operace), aby musel čekat na autogrow. Představu o požadavcích můžete získat pomocí WITH ESTIMATEONLY , jak zde Pavel vysvětluje. Jen mějte na paměti, že odhad může být poměrně nízký kvůli chybě v SQL Server 2008 R2. Také pokud používáte příznak trasování 2562, ujistěte se, že se přizpůsobíte dodatečným požadavkům na prostor.
A samozřejmě všechny typické rady pro optimalizaci tempdb na téměř jakémkoli systému jsou vhodné i zde:ujistěte se, že tempdb je na své vlastní sadě rychlých vřetena, ujistěte se, že je dimenzován pro všechny ostatní souběžné aktivity, aniž byste museli růst, ujistěte se, že používáte optimální počet datových souborů atd. Několik dalších zdrojů, které byste mohli zvážit:
- Optimalizace výkonu databáze tempdb (MSDN)
- Plánování kapacity pro tempdb (MSDN)
- Mýtus SQL Server DBA denně:(12/30) tempdb by měl mít vždy jeden datový soubor na jádro procesoru
Snížení dopadu I/O:ovládejte snímek
Chcete-li spustit CHECKDB , moderní verze SQL Serveru se pokusí vytvořit skrytý snímek vaší databáze na stejném disku (nebo na všech discích, pokud vaše datové soubory zahrnují více jednotek). Tento mechanismus nemůžete ovládat, ale pokud chcete ovládat, kde CHECKDB funguje, vytvořte nejprve svůj vlastní snímek (vyžaduje Enterprise Edition) na libovolném disku a spusťte DBCC příkaz proti snímku. V obou případech budete chtít spustit tuto operaci během relativního výpadku, abyste minimalizovali aktivitu kopírování při zápisu, která bude procházet snímkem. A nebudete chtít, aby byl tento plán v konfliktu s nějakými náročnými operacemi zápisu, jako je údržba indexu nebo ETL.
Možná jste viděli návrhy na vynucení CHECKDB spustit v režimu offline pomocí WITH TABLOCK volba. Důrazně doporučuji proti tomuto přístupu. Pokud je vaše databáze aktivně využívána, výběr této možnosti bude uživatele pouze frustrovat. A pokud není databáze aktivně využívána, neušetříte žádné místo na disku tím, že se vyhnete snímku, protože nedojde k uložení žádné aktivity kopírování při zápisu.
Snížení dopadu I/O:vyhněte se chybám 665/1450/1452
V některých případech se může zobrazit jedna z následujících chyb:
Operační systém vrátil chybu 1450 (Neexistují dostatečné systémové prostředky k dokončení požadované služby.) na SQL Server během zápisu s posunem 0x[…] do souboru s popisovačem 0x[…]. Toto je obvykle dočasný stav a SQL Server bude operaci opakovat. Pokud stav přetrvává, je třeba okamžitě podniknout kroky k nápravě.
Operační systém vrátil chybu 665 (požadovanou operaci nebylo možné dokončit kvůli omezení systému souborů) na SQL Server během zápisu s posunem 0x[…] do souboru '[soubor]'
Zde je několik tipů, jak snížit riziko těchto chyb během CHECKDB operací a snížení jejich dopadu obecně – s několika dostupnými opravami v závislosti na vašem operačním systému a verzi SQL Server:
- Chyby řídkých souborů:1450 nebo 665 kvůli fragmentaci souboru:Opravy a zástupná řešení
- SQL Server hlásí chybu operačního systému 1450 nebo 1452 nebo 665 (opakování)
Snížení dopadu na procesor
DBCC CHECKDB je standardně vícevláknový (ale pouze v Enterprise Edition). Pokud je váš systém vázán na CPU nebo chcete jen CHECKDB Chcete-li používat méně CPU za cenu delšího provozu, můžete zvážit omezení paralelismu několika různými způsoby:
- Používejte Resource Governor v roce 2008 a výše, pokud používáte Enterprise Edition. Chcete-li zacílit pouze příkazy DBCC pro konkrétní fond zdrojů nebo skupinu pracovních zátěží, budete muset napsat funkci klasifikátoru, která dokáže identifikovat relace, které budou tuto práci provádět (např. konkrétní přihlášení nebo job_id).
- Pomocí příznaku trasování 2528 vypněte paralelismus pro
DBCC CHECKDB(stejně jakoCHECKFILEGROUPaCHECKTABLE). Příznak trasování 2528 je popsán zde. Samozřejmě to platí pouze v Enterprise Edition, protože navzdory tomu, co aktuálně říká Books Online, pravdou je, žeCHECKDBnejde paralelně ve standardní verzi. - Zatímco
DBCCsamotný příkaz nepodporujeMAXDOP(alespoň před SQL Server 2014 SP2), respektuje globální nastavenímax degree of parallelism. Pravděpodobně to není něco, co bych dělal ve výrobě, pokud bych neměl jiné možnosti, ale toto je jeden zastřešující způsob, jak ovládat určitéDBCCpříkazy, pokud je nemůžete zacílit explicitněji.
Žádali jsme o lepší kontrolu nad počtem CPU, které DBCC CHECKDB používá, ale byly opakovaně odepřeny až do SQL Server 2014 SP2. Nyní tedy můžete přidat WITH MAXDOP = n k příkazu.
Moje zjištění
Chtěl jsem předvést několik z těchto technik v prostředí, které jsem mohl ovládat. Nainstaloval jsem AdventureWorks2012 a poté jsem jej rozšířil pomocí skriptu zvětšovacího nástroje AW, který napsal Jonathan Kehayias (blog | @SQLPoolBoy), čímž se databáze rozrostla na přibližně 7 GB. Potom jsem spustil sérii CHECKDB příkazy proti tomu a načasoval je. Použil jsem obyčejnou vanilku DBCC CHECKDB samostatně, pak byly použity všechny ostatní příkazy WITH NO_INFOMSGS, ALL_ERRORMSGS . Pak čtyři testy s (a) bez příznaků trasování, (b) 2549, (c) 2562 a (d) jak 2549, tak 2562. Poté jsem tyto čtyři testy zopakoval, ale přidal jsem PHYSICAL_ONLY možnost, která obchází všechny logické kontroly. Výsledky (v průměru z 10 testovacích běhů) jsou vypovídající:
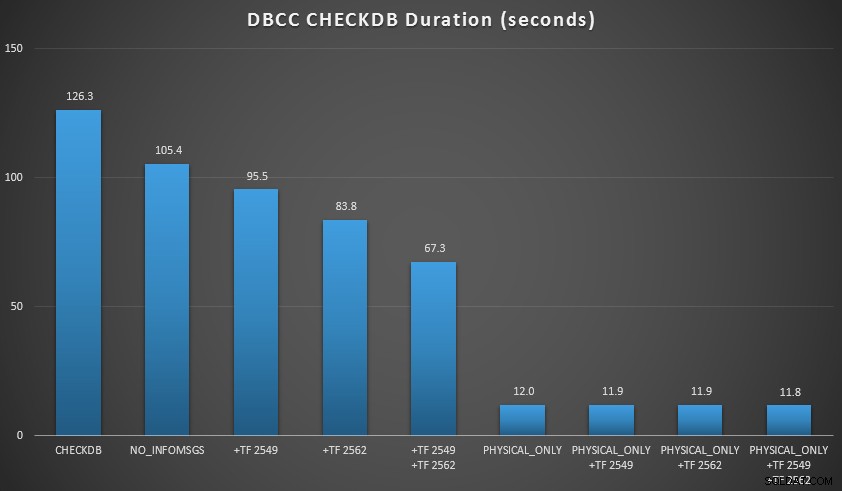
CHECKDB výsledky proti 7 GB databázi
Potom jsem databázi ještě rozšířil, udělal jsem mnoho kopií dvou zvětšených tabulek, což vedlo k velikosti databáze jen severně od 70 GB, a znovu jsem provedl testy. Výsledky, opět v průměru za 10 testovacích běhů:
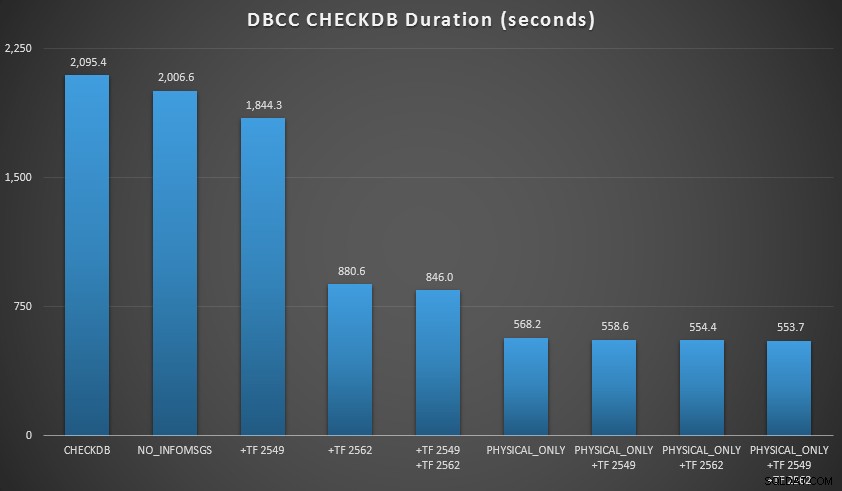
CHECKDB výsledky proti 70 GB databázi
V těchto dvou scénářích jsem se naučil následující (opět mějte na paměti, že váš počet najetých kilometrů se může lišit a že budete muset provést vlastní testy, abyste vyvodili nějaké smysluplné závěry):
- Když musím provést logické kontroly:
- Při malých velikostech databáze
NO_INFOMSGSTato možnost může výrazně zkrátit dobu zpracování při provádění kontrol v SSMS. U větších databází se však tato výhoda zmenšuje, protože čas a práce strávená předáváním informací se stávají tak nevýznamnou částí celkové doby trvání. 21 sekund ze 2 minut je podstatných; 88 sekund z 35 minut, ne tolik. - Dva příznaky trasování, které jsem testoval, měly významný dopad na výkon – představovaly snížení běhu o 40–60 %, když byly oba použity společně.
- Při malých velikostech databáze
- Když mohu odeslat logické kontroly na sekundární server (opět za předpokladu, že provádím logické kontroly jinde proti pravé kopii ):
- Mohu zkrátit dobu zpracování na své primární instanci o 70–90 % ve srovnání se standardní
CHECKDBvolání bez možnosti. - V mém scénáři měly příznaky trasování velmi malý dopad na trvání při provádění
PHYSICAL_ONLYkontroly.
- Mohu zkrátit dobu zpracování na své primární instanci o 70–90 % ve srovnání se standardní
Samozřejmě, a to nemohu dostatečně zdůraznit, jsou to relativně malé databáze a slouží pouze k tomu, abych mohl provádět opakované, měřené testy v rozumném čase. Tento server měl 80 logických CPU a 128 GB RAM a byl jsem jediným uživatelem. Trvání a interakce s jinými zátěžemi v systému mohou tyto výsledky dost zkreslit. Zde je rychlý pohled na typické využití CPU pomocí SQL Sentry během jednoho z CHECKDB operace (a žádná z možností skutečně nezměnila celkový dopad na CPU, pouze trvání):
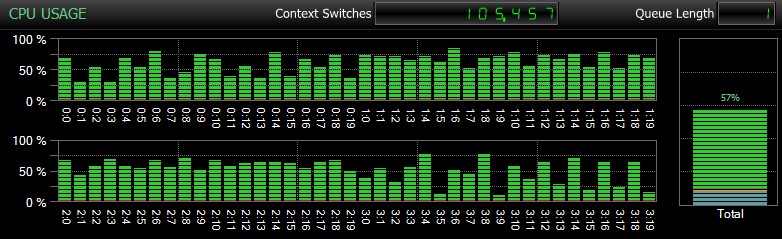
Vliv CPU během CHECKDB – ukázkový režim
A zde je další pohled, který ukazuje podobné profily CPU pro tři různé ukázkové CHECKDB operace v historickém režimu (překryl jsem popis tří testů vzorkovaných v tomto rozsahu):
Vliv CPU během CHECKDB – historický režim
Na ještě větších databázích, hostovaných na rušnějších serverech, můžete zaznamenat různé efekty a vaše kilometry se budou pravděpodobně lišit. Než se tedy rozhodnete, jak chcete přistupovat k CHECKDB, proveďte prosím náležitou péči a vyzkoušejte tyto možnosti a příznaky trasování během typické souběžné pracovní zátěže .
Závěr
DBCC CHECKDB je velmi důležitou, ale často podceňovanou součástí vaší odpovědnosti jako DBA nebo architekta a zásadní pro ochranu dat vaší společnosti. Neberte tuto odpovědnost na lehkou váhu a snažte se zajistit, abyste nic neobětovali v zájmu snížení dopadu na vaše produkční instance. A co je nejdůležitější:podívejte se za hranice marketingových datových listů, abyste se ujistili, že plně rozumíte, jak jsou tyto sliby platné a zda jste ochotni na ně vsadit údaje vaší společnosti. Ušetřete na některých kontrolách nebo je přemístěte na neplatná sekundární místa, může to být katastrofa, která čeká, až se stane.
Měli byste také zvážit přečtení těchto článků PSS:
- Rychlejší CHECKDB – část I
- Rychlejší CHECKDB – část II
- Rychlejší CHECKDB – část III
- Rychlejší CHECKDB – část IV (SQL CLR UDT)
A tento příspěvek od Brenta Ozara:
- 3 způsoby, jak rychleji spustit DBCC CHECKDB
A konečně, pokud máte nevyřešený dotaz ohledně DBCC CHECKDB , zveřejněte jej na #sqlhelp hash tag na twitteru. Paul tento štítek často kontroluje, a protože by se jeho obrázek měl objevit v hlavním článku Books Online, je pravděpodobné, že pokud na něj může někdo odpovědět, také ano. Pokud je to příliš složité na 140 znaků, můžete se zeptat zde (a já se ujistím, že to Paul někdy uvidí), nebo poslat příspěvek na fórum, jako je Database Administrators Stack Exchange.