Vytváření a správa stoplistů slouží jako jedna z hlavních komponent zodpovědných za zlepšení výkonu fulltextového vyhledávání spolu se snížením velikosti indexu. Tento článek si klade za cíl pomoci vám zvládnout práci do hloubky a implementovat různé strategie k vytvoření stoplistů na jednoduchých, ale zajímavých příkladech.
Zdůrazníme také důležitost různých metod pro vytváření stoplistů a objasníme, jak vybrat nejvhodnější metodu.
Proč zvládnout stoplisty
Když mluvíme o používání stoplistů týkajících se fulltextového vyhledávání, první otázkou je, proč se o těchto stoplistech tolik dozvídáme. Odpověď spočívá ve zjevných i skrytých výhodách používání stoplistů s fulltextovým vyhledáváním. Existují také dlouhodobé zisky, které mohou přinést, jakmile budou úspěšně implementovány.
Význam stoplistů
Stoplist je jazykově specifická komponenta fulltextového vyhledávání obsahující uživatelem definovaná nebo systémem poskytovaná ignorovaná slova. Musí vyloučit taková slova z toho, aby se stala součástí fulltextového vyhledávání.
Design fulltextového vyhledávání bez stoplistu není optimálním využitím komponent specifických pro jazyk, které by měly zlepšit efektivitu fulltextového vyhledávání a dobu odezvy.
Předpoklady
- Můžete psát a spouštět skripty T-SQL.
- Fulltext Search musí být nainstalován do vaší instance SQL Server.
- Znáte základní koncepty a implementaci fulltextového vyhledávání.
- Máte základní znalosti ignorovaných slov a stoplistů.
V případě, že vám chybí informace k zajištění výše uvedených požadavků, podívejte se na níže uvedené články:
- Implementace fulltextového vyhledávání v SQL Server 2016 pro začátečníky
- Implementace fulltextového vyhledávání v SQL Server 2016 pro pokročilé uživatele
- Jak používat ignorovaná slova a stoplist ke zlepšení SQL Server Full-Text Search (FTS)
Několik strategií vytváření stoplistů
Existuje mnoho různých metod nebo strategií, ale některé z nich jsou mnohem lepší než jiné. Každý vývojář databází s implementačními dovednostmi Full-Text Search by měl být obeznámen se všemi metodami, aby v případě potřeby vybral tu nejlepší.
Nejúčinnějším způsobem, jak porozumět těmto různým strategiím, je aplikovat je na vzorovou databázi.
Nastavení ukázkové databáze
Prvním krokem je nastavení databáze pro spouštění fulltextových dotazů. Vytvořte ukázkovou databázi s názvem WatchReviewsMasterStoplist :
-- Create WatchReviewsMasterStoplist database
CREATE DATABASE WatchReviewsMasterStoplist;
GO
-- Connect to the sample database
USE WatchReviewsMasterStoplist
-- (2) Create WatchReview table
CREATE TABLE [dbo].[WatchReview]
(
[ReviewId] INT NOT NULL IDENTITY ,
[Date] DATETIME2 NULL,
[Person] VARCHAR(50) NULL,
[Details] VARCHAR(1000) NULL,
CONSTRAINT [PK_WatchReview] PRIMARY KEY (ReviewId)
)
-- (3) Populate WatchReview table
SET IDENTITY_INSERT [dbo].[WatchReview] ON
INSERT INTO [dbo].[WatchReview] ([ReviewId], [Date], [Person], [Details]) VALUES (1, N'2020-06-01 00:00:00', N'Asif', N'Hi, I have just bought this Casio black digital watch which is excellent and has date, alarm, stopwatch and timer as well.')
INSERT INTO [dbo].[WatchReview] ([ReviewId], [Date], [Person], [Details]) VALUES (2, N'2020-07-02 00:00:00', N'Asim', N'Hi, I have just bought this Casio black analog watch which is average and slightly discomforting and just got date and time.')
INSERT INTO [dbo].[WatchReview] ([ReviewId], [Date], [Person], [Details]) VALUES (3, N'2020-08-03 00:00:00', N'Martin', N'Hi, I have just purchased this Casio black digital watch which is excellent and has features like an alarm, stopwatch, date, and timer. ')
INSERT INTO [dbo].[WatchReview] ([ReviewId], [Date], [Person], [Details]) VALUES (4, N'2020-09-10 00:00:00', N'Brian ', N'Hi, I have just ordered this Seiko black digital watch which is excellent and has date, alarm and timer.')
INSERT INTO [dbo].[WatchReview] ([ReviewId], [Date], [Person], [Details]) VALUES (5, N'2020-10-11 00:00:00', N'Peter', N'Hi, I have just ordered this Seiko white analog watch which is average and has alarm, date and timer.')
SET IDENTITY_INSERT [dbo].[WatchReview] OFFPřehled strategií více stoplistů
Můžete použít následující tři způsoby/strategie k vytvoření stoplistu a zabránit tomu, aby se šumová slova stala součástí vašich dotazů fulltextového vyhledávání:
- Vytvořte si vlastní seznam stop
- Vytvořte stoplist systému
- Vytvořte stoplist z vlastního (nebo systémového) stoplistu
Předpoklady na stoplist
Pamatujte, že před vytvořením stoplistu musíte udělat následující:
- Pokud není k dispozici žádný klíčový sloupec (primární klíč), vytvořte v jednom ze sloupců tabulky jedinečný index.
- Vytvořte fulltextový katalog.
- Vytvořte fulltextový index.
Vytvořit vlastní stoplist
Předpokládejme, že je k dispozici jedinečný index nebo sloupec primárního klíče (jako v naší vzorové databázi). Vlastní stoplist vytvoříme následovně:
- Vytvořte fulltextový katalog.
- Vytvořte prázdný vlastní seznam stop.
- Vytvořte fulltextový index s vlastním stoplistem vytvořeným v kroku 2.
Podrobné informace naleznete v článku Jak používat ignorovaná slova a stoplist ke zlepšení SQL Server Full-Text Search (FTS)
Pro a proti vlastních stoplistů
Největší výhodou vytvoření vlastního stoplistu je, že nad ním můžete mít plnou kontrolu a sledovat jej přidáváním a odebíráním slov, o kterých si myslíte, že jsou šumová slova.
Použití tohoto přístupu má však své nevýhody. Stoplist je velmi omezený a nebude obsahovat systémem doporučená ignorovaná slova pro další zlepšení výkonu fulltextových dotazů.
Vytvoření seznamu stop systému
Vytvořte stoplist systému (pokud je uveden sloupec primárního klíče nebo jedinečný index) takto:
- Vytvořte fulltextový katalog.
- Vytvořte fulltextový index pomocí systémového stoplistu.
Připravujeme se na použití systémového stoplistu tak, že nejprve vytvoříme Full-Text Catalog:
-- Create Full-Text catalog
CREATE FULLTEXT CATALOG [WatchReviewCatalog] AS DEFAULT;
GOVytvořte fulltextový index ve sloupci recenzí (Podrobnosti) v tabulce WatchReview se stoplistem systému. Použijte následující skript T-SQL:
-- Create Full-Text index with System Stoplist
CREATE FULLTEXT INDEX ON dbo.WatchReview(Details LANGUAGE [British English])
KEY INDEX PK_WatchReview
WITH STOPLIST = System;
GO Zobrazit seznam stop systému v angličtině
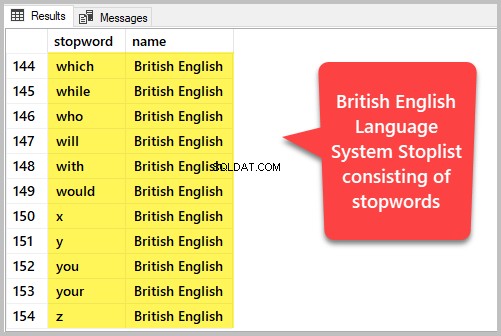
Můžete si prohlédnout seznam ignorovaných slov obsažených v systémovém stoplistu britské angličtiny. Spusťte následující dotaz SQL:
-- View system stoplist of English language
SELECT name,stopword FROM sys.fulltext_system_stopwords sw
INNER JOIN sys.fulltext_languages fl
on sw.language_id=fl.lcid
where name='British English'Výstup je následující:
Zobrazit 3 nejnovější recenze
Spusťte rychlou kontrolu s nově vytvořenou ukázkovou databází. Udělejte to tak, že získáte 3 nejnovější recenze sledování z WatchReview tabulka:
-- Top 3 most recent watch reviews
SELECT TOP 3 wr.Person,FORMAT(wr.Date,'dd-MMM-yyyy') as ReviewDate,wr.Details FROM dbo.WatchReview wr
ORDER BY wr.Date DESCVýstup je následující:

Kontrola ignorovaných slov spuštěním fulltextových dotazů
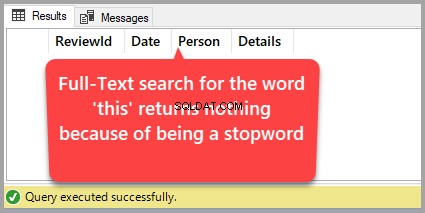
Proti nominované tabulce můžeme spouštět Fulltextové dotazy. Nebuďte překvapeni, když se ve fulltextových dotazech neobjeví mnoho šumových slov (zahrnutých do stoplistu systému pro zlepšení výkonu). Znamená to, že náš systémový stoplist dělá svou práci správně.
Jak vidíme, slovo „toto“ je přítomen mezi 3 nejlepšími recenzemi. Nicméně je to šumové slovo samo rozpoznáno stoplistem systému.
Pojďme zkontrolovat, zda fulltextové vyhledávání vrací šumové slovo „toto“ zahrnuto v systémovém stoplistu:
--Run Full-Text query to Search for Noise word 'this'
SELECT * FROM dbo.WatchReview
WHERE CONTAINS(Details,'this')Sada výsledků je níže:
Nyní můžeme spustit fulltextový dotaz a vyhledat slovo ‘je‘ což je další šumové slovo:
--Run Full-Text query to Search for Noise word 'is'
SELECT * FROM dbo.WatchReview
WHERE CONTAINS(Details,'is')Výstup dotazu je níže:
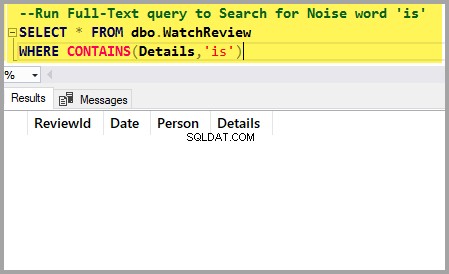
Vidíme, že slovo „je“ bylo také úspěšně zabráněno tomu, aby se stal součástí výsledku fulltextového dotazu tím, že šetřil cenné zdroje.
Plnotextový dotaz k vyhledání slova „Ahoj“
Spustíme fulltextový dotaz k vyhledání slova ‚Ahoj.‘ Není součástí stoplistu systému. Dotaz jej tedy musí vrátit.
--Search Noise word 'Hi'
SELECT * FROM dbo.WatchReview
WHERE CONTAINS(Details,'Hi')Výstup je následující:

Máme všechny záznamy obsahující slovo ‚Ahoj.‘ Rádi bychom jej však vyloučili, protože se jedná o šumové slovo. Pokud v naší textové analýze použijeme fulltextové vyhledávání, může nás toto slovo odvést od cíle.
To nás vede ke třetí metodě:vytvoření stoplistu z vlastního nebo systémového stoplistu.
Vytvoření vlastního stoplistu ze systémového stoplistu
Vytvořte si vlastní stoplist s názvem WatchMasterStoplist ze stoplistu systému pomocí následujícího skriptu T-SQL:
--Creating a custom stoplist WatchMasterStoplist from system stoplist
CREATE FULLTEXT STOPLIST [WatchMasterStoplist] FROM SYSTEM STOPLIST;
GOPřidružení nového vlastního stoplistu k fulltextovému indexu
Přiřaďte nově vytvořený vlastní stoplist k fulltextovému indexu následovně:
USE [WatchReviewsMasterStoplist]
GO
-- Associating new custom stoplist with Full-Text index
ALTER FULLTEXT INDEX ON [dbo].[WatchReview] SET STOPLIST = [WatchMasterStoplist]Zkontrolujte vlastní stoplist vyhledáním slova „toto“
Můžete rychle zkontrolovat, zda váš vlastní stoplist obsahuje všechna šumová slova ze systémového stoplistu. Spusťte stejný kód, který jsme použili dříve k vyhledání slova „toto“.
--Run Full-Text query to Search for Noise word 'this'
SELECT * FROM dbo.WatchReview
WHERE CONTAINS(Details,'this')Tento výstup musí být prázdný.
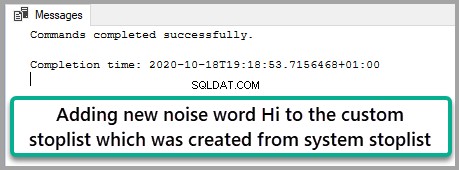
Přidání nového šumového slova „Ahoj“ do vlastního seznamu stop
Musíme přidat šumové slovo „Ahoj“ na nově vytvořenou vlastní stoplist. Spusťte následující skript:
--Alter customer stoplist to add Hi noise word
ALTER FULLTEXT STOPLIST WatchMasterStoplist
ADD 'Hi' LANGUAGE 'British English'; Sada výsledků je níže:
Závěrečná kontrola
Nyní spustíme závěrečnou kontrolu fulltextového dotazu na některá šumová slova – porovnáme ji s původní sadou výsledků obsahující tato šumová slova.
Pokud se například zaměříme na čtvrtou recenzi (seřazenou podle ReviewId ), která obsahuje nějaká šumová slova, a poté porovnejte výsledky s výsledky fulltextového dotazu, neměli bychom vidět žádná šumová slova.
Spusťte následující skript a proveďte závěrečnou kontrolu s ukázkovou databází:
USE WatchReviewsMasterStoplist
-- View the record which contains fourth review
SELECT ReviewId
,[Date]
,Person
,Details
FROM dbo.WatchReview
where ReviewId=4
--Run Full-Text query to Search for Noise words in the fourth review
SELECT * FROM dbo.WatchReview
WHERE CONTAINS(Details,'"Hi" OR "this" OR "I" OR "is" OR "and"')
and ReviewId=4Výstup je následující:
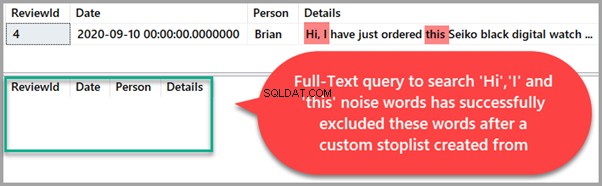
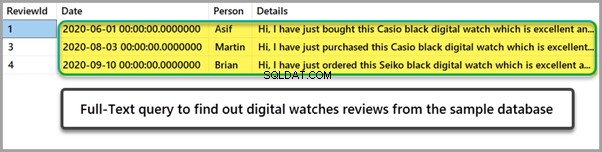
Úplný textový dotaz k vyhledání recenzí digitálních hodinek
Nyní můžeme spouštět naše fulltextové vyhledávací dotazy se stoplistem na místě. Následující T-SQL skript nás bude informovat o recenzích digitálních hodinek (ukázka):
USE WatchReviewsMasterStoplist
--Run Full-Text query to Search for digital watch reviews sample
SELECT * FROM dbo.WatchReview WHERE CONTAINS(Details,'digital')Výsledky jsou níže:
Gratulujeme! Úspěšně jsme implementovali všechny tři způsoby vytváření a sdružování stoplistů. Zkoumali jsme také přidávání nových slov do stoplistů a kontrolu výkonu.
Přesto důrazně doporučuji třetí metodu. Vytvořte si vlastní stoplist ze systémového stoplistu a poté přidejte šumová slova, abyste zlepšili své Fulltextové vyhledávání.
Co dělat
Nyní, když jste si dobře vědomi tří metod vytváření stoplistů, můžete provést některá cvičení ke zlepšení svých dovedností v oblasti textové analýzy, například následující:
- Přidejte vlastní stoplist ze systémového stoplistu proti vzorové databázi, jako v tomto článku.
- Vytvořte vlastní stoplist ze systémového stoplistu proti vzorové databázi, jako v tomto článku.
- Po seznámení s tímto článkem spusťte dotaz T-SQL a zobrazte přidaná ignorovaná slova.