Relační model správy dat byl poprvé vyvinut Dr. Edgarem F. Coddem v roce 1969. Moderní systémy správy relačních databází (RDBMS) jsou v souladu s paradigmatem. Klíčová struktura identifikovaná s RDBMS je logická struktura nazývaná „tabulka“. Tabulky se primárně skládají z řádků a sloupců (nazývaných také záznamy a atributy nebo n-tice a pole). V přísném matematickém smyslu termín tabulka je ve skutečnosti označován jako vztah a odpovídá pojmu „relační model“. V matematice je relace reprezentace množiny.
Atribut expression poskytuje dobrý popis účelu sloupce – charakterizuje sadu řádků, které jsou k němu přiřazeny. Každý sloupec musí být určitého datového typu a každý řádek musí mít nějaké jedinečné identifikační charakteristiky nazývané „klíče“. Změna dat je obvykle efektivnější, když se provádí pomocí relačního modelu, zatímco získávání dat může být rychlejší se starším hierarchickým modelem, který byl předefinován v modelových systémech NoSQL.
Normalizace dat je matematický proces modelování obchodních dat do formy, která zajišťuje, že každá entita je reprezentována jediným vztahem (tabulkou). První zastánci relačního modelu navrhli koncept normálních forem. Edgar Codd definoval první, druhou a třetí normální formu. Poté se k němu připojil Raymond F. Boyce. Společně definovali normální formu Boyce-Codda. Nyní je teoreticky definováno šest normálních forem, ale ve většině praktických aplikací obvykle normalizaci rozšiřujeme až na třetí normální formu. Každý normální formulář se snaží vyhnout anomáliím během úpravy dat, snížit redundanci a závislost dat v tabulce. Každá úroveň normalizace má tendenci zavádět více tabulek, snížit redundanci, zvýšit jednoduchost každé tabulky, ale také zvýšit složitost celého systému správy relačních databází. Takže strukturálně RDBM systémy mají tendenci být složitější než hierarchické systémy.
Proč normalizace databáze:čtyři anomálie
Ukládání dat bez normalizace způsobuje řadu problémů se spotřebou dat. Zastánci normalizace nazývali takové problémy anomáliemi. Abychom tyto anomálie popsali, podívejme se na data uvedená na obr. 1.

>Obr. 1 tabulka zaměstnanců
Výpis 1. Základní tabulka pro demonstraci normalizace databáze.
1.1. Vytvořit tabulku
use privatework go create table staffers ( staffID int identity (1,1) ,StaffName varchar(50) ,Role varchar(50) ,Department varchar (100) ,Manager varchar (50) ,Gender char(1) ,DateofBirth datetime2 )
1.2. Vložit řádky
insert into staffers values ('John Doe','Engineering','Kweku Amarh','M','06-Oct-1965');
insert into staffers values ('Henry Ofori','Engineering','Kweku Amarh','M','06-Mar-1982');
insert into staffers values ('Jessica Yuiah','Engineering','Kweku Amarh','F','06-Oct-1965');
insert into staffers values ('Ahmed Assah','Engineering','Kweku Amarh','M','06-Oct-1965'); 1.3. Dotaz na tabulku
select * from staffers;
Tato tabulka v podstatě představuje dvě sady dat, které byly neúmyslně zkombinovány:jména zaměstnanců a oddělení. Všimněte si, že všichni zaměstnanci jsou ze stejného oddělení:inženýrství. To bylo provedeno pro jednoduchost a za účelem demonstrování normalizace. S manipulací s touto strukturou jsou spojeny tři hlavní problémy:
Anomálie vkládání
Abychom mohli vložit nový záznam, musíme neustále opakovat jména oddělení a manažerů.
Anomálie mazání
Chceme-li smazat záznam zaměstnance, musíme také smazat přidruženého manažera a oddělení. Pokud je potřeba odstranit záznamy VŠECH zaměstnanců, musíme také odstranit všechna oddělení a všechny manažery.
Anomálie aktualizace
Pokud je potřeba změnit manažera jakéhokoli oddělení, musíme provést změnu v každém jednotlivém řádku této tabulky, protože hodnoty jsou duplikovány pro každého zaměstnance.
Databáze normálních formulářů
V následujících částech článku se pokusíme popsat 1., 2. a 3. normální formu, které jsou mnohem pravděpodobněji pozorovány ve skutečných systémech RDBM. Existují další rozšíření teorie, jako je čtvrtá, pátá a normální formy Boyce-Codda, ale v tomto článku se omezíme na tři normální formy.
První normální formulář
První normální formulář je definován čtyřmi pravidly:
Každý sloupec musí obsahovat hodnoty stejného datového typu.
Tabulka Zaměstnanci již toto pravidlo splňuje.
Každý sloupec v tabulce musí být atomický.
To v podstatě znamená, že byste měli dělit obsah sloupce, dokud jej již nelze dělit. Všimněte si, že Role ve sloupci Zaměstnanci tabulka porušuje pravidlo 2 pro řádek s StaffID=3.
Každý řádek v tabulce musí být jedinečný.
Unikátnosti v normalizovaných tabulkách se obvykle dosahuje pomocí primárních klíčů. Primární klíč jednoznačně definuje každý řádek v tabulce. Primární klíč je většinou definován pouze jedním sloupcem. Primární klíč složený z více než jednoho sloupce se nazývá složený klíč.
Na pořadí, ve kterém jsou záznamy uloženy, nezáleží.
Zarovnání dat v Zaměstnanci tabulku s principy První normální formy potřebujeme rozdělit tabulku, jak je znázorněno na obrázcích 2, 3 a 4.
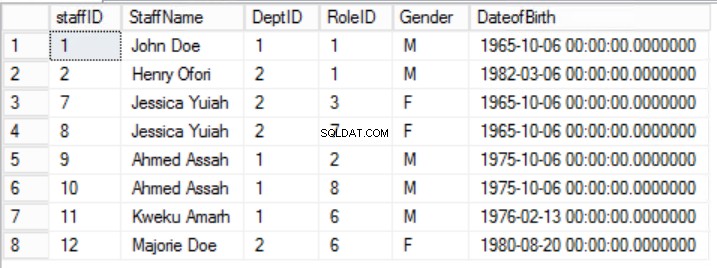
>Obr. 2 Stůl zaměstnanců
Zúžili jsme údaje v Zaměstnanci a implementoval složený primární klíč, aby byla zaručena jedinečnost. Vytvořili jsme také dvě další tabulky Role a Oddělení které mají vztahy s hlavními zaměstnanci tabulka implementovaná pomocí cizích klíčů. Zkontrolujte DDL ve výpisu 2.
Výpis 2. DDL nových zaměstnanců Tabulka pro první normální formulář.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID] [int] NOT NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC, [RoleID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([RoleID]) REFERENCES [dbo].[Roles] ([RoleID]) GO
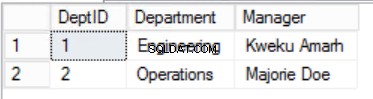
>Obr. Tabulka 3 oddělení
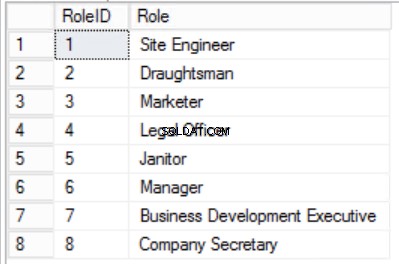
>Obr. Tabulka 4 rolí
Druhý normální formulář
První normální formulář již musí být na svém místě.
Každý neklíčový sloupec nesmí mít částečnou závislost na primárním klíči.
Podstatou druhého pravidla je, že všechny sloupce tabulky musí záviset na všech sloupcích, které dohromady tvoří primární klíč. Když se podíváme zpět na tabulky na obrázcích 2, 3 a 4, zjistíme, že jsme splnili všechny požadavky První normální formy. Splnili jsme také požadavky druhého normálního formuláře pro dvě tabulky Role a Oddělení . Nicméně v případě Zaměstnanci stůl, stále máme problém. Náš primární klíč se skládá ze sloupců StaffID a RoleID.
Pravidlo 2 druhého normálního formuláře je zde porušeno skutečností, že pohlaví a datum narození zaměstnanců nezávisí na RoleID. Existuje částečná závislost.
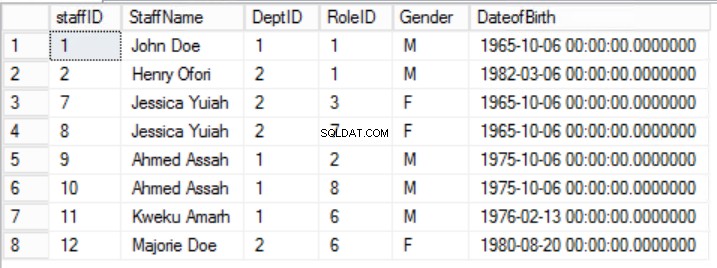
>Obr. 5 Staffers pro první normální formu
V uvedeném příkladu se to můžeme pokusit opravit odstraněním RoleID z primárního klíče, ale pokud to uděláme, porušíme další pravidlo:roli jedinečnosti uvedenou v První normální formě. Musíme zvolit jiný přístup. Upravíme Zaměstnanci stůl s tím, že zaměstnanec může hrát více než jednu roli. Viz obr. 6.
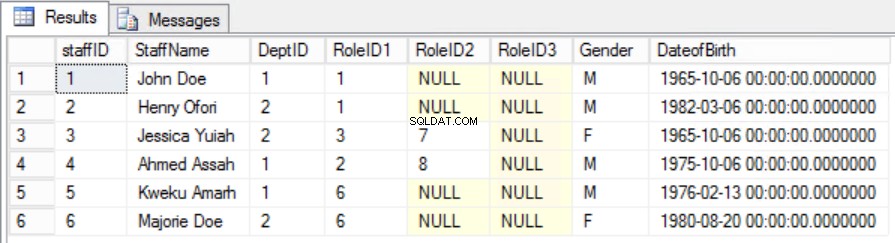
>Obr. Tabulka 6 zaměstnanců pro druhou normální formu
Podařilo se nám zachovat jedinečnost a také odstranit částečnou závislost.
Výpis 3. DDL tabulky nových zaměstnanců pro druhý normální formulář.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers2NF]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID1] [int] NOT NULL, [RoleID2] [int] NULL, [RoleID3] [int] NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID1]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID2]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID3]) REFERENCES [dbo].[Roles] ([RoleID]) GO
Třetí normální formulář
Druhý normální formulář již musí být na svém místě.
Každý neklíčový sloupec nesmí mít přechodnou závislost na primárním klíči.
Třetí normální forma spočívá v tom, že nesmí existovat žádné sloupce závislé na neklíčových sloupcích, i když tyto neklíčové sloupce již závisí na primárním klíči.
Předpokládejme například, že jsme se rozhodli přidat další sloupec do Zaměstnanci tabulka, jak je znázorněno na obr. 7, abyste jasně viděli vedoucího zaměstnance. Tím bychom porušili druhé pravidlo třetího normálního formuláře, protože jméno manažera závisí na DeptID a DeptID zase závisí na StaffID. Toto je tranzitivní závislost.
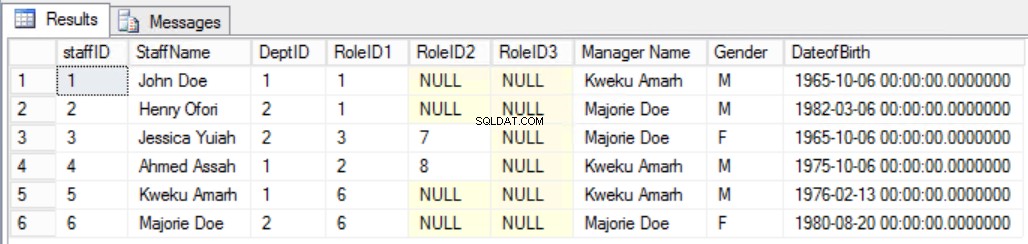
>Obr. Tabulka 7 zaměstnanců pro třetí normální formulář (Broken Rule)
Bylo by lepší zachovat starý formulář a zobrazit požadované informace pomocí spojení mezi tabulkou Zaměstnanci a tabulkou Oddělení.
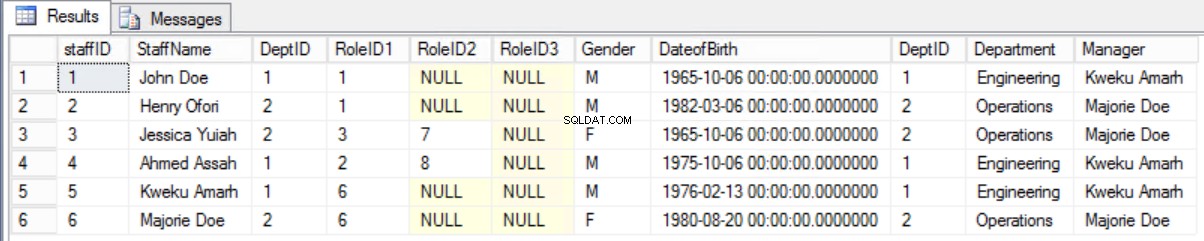
>Obr. 8 Připojte se mezi zaměstnance a oddělení
Výpis 4. Dotaz na zobrazení zaměstnanců a manažerů.
select * from staffers2NF s join Department d on s.DeptID=d.DeptID;
Praktická aplikace
Většina vyspělých aplikací implementuje pravidla normalizace v rozumné míře. Vidíme, že implementace normalizace dat vede k použití omezení primárního klíče a omezení cizího klíče. Kromě toho se také problémy, jako je indexování cizích klíčů, objevují, když se do tématu ponoříme hlouběji. Již dříve jsme zmínili, jak může nedostatek normalizace ovlivnit hladkou manipulaci s daty, jak je popsáno v části Anomálie vkládání, mazání a aktualizace. Nedostatek správné normalizace může také nepřímo ovlivnit výkon dotazu.
Nedávno jsem narazil na tabulku ve tvaru uvedeném v tabulce 1, kterou budeme nazývat Customer_Accounts.
S/Ne | Jméno | Číslo_účtu | Telefonní_číslo |
1 | Kenneth Igiri | 9922344592 | 2348039988456, 2348039988456, 2348039988456 |
2 | Ernest Doe | 6677554897 | 2348022887546, 2348039988456 |
Tabulka 1 Zákaznické_účty
Hlavním problémem této tabulky je, že porušuje druhé pravidlo prvního normálního formuláře. Výsledkem v našem případě bylo, že vyhledávání zákazníků na základě jejich telefonních čísel vyžadovalo použití LIKE v klauzuli WHERE a úvodní %.
Select account_no from Customer_Accounts where Phone_No like ‘%2348039988456%’;
Výše uvedená konstrukce měla dopad na to, že optimalizátor nikdy nepoužil index, což představovalo obrovský problém s výkonem.
Závěr
Normalizace dat leží v oblasti návrhu databáze a jak vývojáři, tak správci databází by měli věnovat pozornost pravidlům uvedeným v tomto článku. Vždy je lepší provést normalizaci předtím, než se databáze dostane do výroby. Výhody správně navrženého systému správy relačních databází prostě stojí za námahu.