Baví vás parsování řetězců? Pokud ano, jednou z nezbytných řetězcových funkcí je SQL SUBSTRING. Je to jedna z dovedností, které by vývojář měl mít pro jakýkoli jazyk.
Tak, jak to uděláte?
Důležité body v analýze řetězců
Předpokládejme, že jste v analýze nováčky. Jaké důležité body si musíte zapamatovat?
- Vědět, jaké informace jsou v řetězci vloženy.
- Získejte přesnou polohu každé informace v řetězci. Možná budete muset spočítat všechny znaky v řetězci.
- Znáte velikost nebo délku každé informace v řetězci.
- Použijte funkci správného řetězce, která dokáže snadno extrahovat každou část informace v řetězci.
Znalost všech těchto faktorů vás připraví na použití SQL SUBSTRING() a předávání argumentů.
Syntaxe SQL SUBSTRING

Syntaxe SQL SUBSTRING je následující:
SUBSTRING(řetězcový výraz, začátek, délka)
- řetězcový výraz – a doslovný řetězec nebo výraz SQL, který vrací řetězec.
- start – číslo, od kterého se spustí extrakce. Je také založen na 1 – první znak v argumentu řetězcového výrazu musí začínat 1, nikoli 0. Na SQL Serveru je to vždy kladné číslo. V MySQL nebo Oracle však může být pozitivní nebo negativní. Pokud je negativní, skenování začíná od konce řetězce.
- délka – délka znaků k extrakci. SQL Server to vyžaduje. V MySQL nebo Oracle je volitelné.
4 příklady SQL SUBSTRING
1. Použití SQL SUBSTRING k extrakci z doslovného řetězce
Začněme jednoduchým příkladem pomocí doslovného řetězce. Používáme název slavné korejské dívčí skupiny BlackPink a obrázek 1 ilustruje, jak bude SUBSTRING fungovat:

Níže uvedený kód ukazuje, jak jej extrahujeme:
-- extract 'black' from BlackPink (English)
SELECT SUBSTRING('BlackPink',1,5) AS result
Nyní se také podívejme na sadu výsledků na obrázku 2:
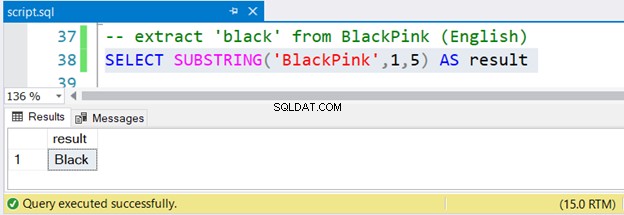
Není to snadné?
Chcete-li extrahovat černou od BlackPink , začínáte na pozici 1 a končíte na pozici 5. Od BlackPink je korejština, pojďme zjistit, zda SUBSTRING funguje na korejských znacích Unicode.
(ODPOVĚDNOST :Neumím mluvit, číst ani psát korejsky, takže korejský překlad jsem získal z Wikipedie. Použil jsem také Překladač Google, abych zjistil, které znaky odpovídají černé a Růžová . Prosím, odpusťte mi, pokud je to špatně. Přesto doufám, že přijde bod, který se snažím objasnit і napříč)
Pojďme mít řetězec v korejštině (viz obrázek 3). Použité korejské znaky se překládají do BlackPink:

Nyní se podívejte na kód níže. Extrahujeme dva znaky odpovídající černé .
-- extract 'black' from BlackPink (Korean)
SELECT SUBSTRING(N'블랙핑크',1,2) AS result
Všimli jste si korejského řetězce, kterému předchází N ? Používá znaky Unicode a SQL Server předpokládá NVARCHAR a mělo by mu předcházet N . To je jediný rozdíl v anglické verzi. Ale půjde to dobře? Viz obrázek 4:
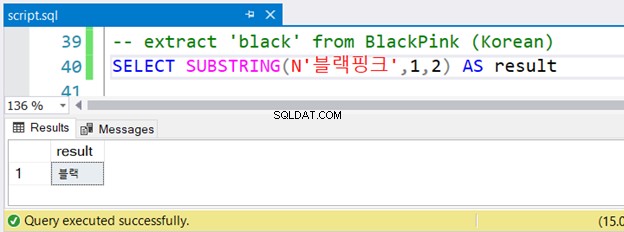
Běželo to bez chyb.
2. Použití SQL SUBSTRING v MySQL se záporným počátečním argumentem
Negativní počáteční argument nebude na SQL Server fungovat. Ale můžeme mít příklad pomocí MySQL. Tentokrát vyjmeme růžovou od BlackPink . Zde je kód:
-- Extract 'Pink' from BlackPink using MySQL Substring (English)
select substring('BlackPink',-4,4) as result;
Nyní mějme výsledek na obrázku 5:
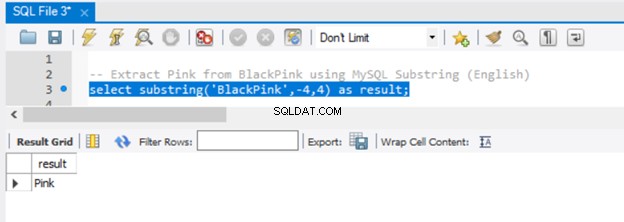
Protože jsme do parametru start předali -4, extrakce začala od konce řetězce, jdouce o 4 znaky zpět. Chcete-li dosáhnout stejného výsledku na serveru SQL Server, použijte funkci RIGHT().
Znaky Unicode také fungují s MySQL SUBSTRING, jak můžete vidět na obrázku 6:
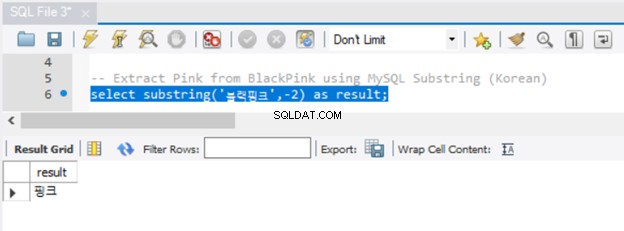
Fungovalo to dobře. Všimli jste si ale, že jsme nemuseli před řetězec uvádět N? Všimněte si také, že existuje několik způsobů, jak získat podřetězec v MySQL. SUBSTRING jste již viděli. Ekvivalentní funkce v MySQL jsou SUBSTR() a MID().
3. Analýza podřetězců s argumenty proměnného začátku a délky
Bohužel ne všechny extrakce řetězců používají argumenty s pevným začátkem a délkou. V takovém případě potřebujete CHARINDEX, abyste získali pozici řetězce, na který cílíte. Uveďme příklad:
DECLARE @lineString NVARCHAR(30) = N'김제니 01/16/example@sqldat.com'
DECLARE @name NVARCHAR(5)
DECLARE @bday DATE
DECLARE @instagram VARCHAR(20)
SET @name = SUBSTRING(@lineString,1,CHARINDEX('@',@lineString)-11)
SET @bday = SUBSTRING(@lineString,CHARINDEX('@',@lineString)-10,10)
SET @instagram = SUBSTRING(@lineString,CHARINDEX('@',@lineString),30)
SELECT @name AS [Name], @bday AS [BirthDate], @instagram AS [InstagramAccount]
Ve výše uvedeném kódu musíte extrahovat jméno v korejštině, datum narození a účet Instagram.
Začneme definováním tří proměnných, které tyto informace uchovávají. Poté můžeme analyzovat řetězec a přiřadit výsledky každé proměnné.
Možná si myslíte, že mít pevné začátky a délky je jednodušší. Kromě toho to můžeme určit ručním počítáním znaků. Ale co když jich máte na stole hodně?
Zde je naše analýza:
- Jediná pevná položka v řetězci je @ postava na instagramovém účtu. Jeho pozici v řetězci můžeme získat pomocí CHARINDEX. Potom tuto pozici použijeme k získání začátku a délky zbytku.
- Datum narození je v pevném formátu MM/dd/rrrr s 10 znaky.
- Chceme-li získat jméno, začneme na 1. Protože datum narození má 10 znaků plus @ znak, můžete se dostat na koncový znak jména v řetězci. Z pozice @ znak, vrátíme se o 11 znaků zpět. SUBSTRING(@lineString,1,CHARINDEX(‘@’,@lineString)-11) je správná cesta.
- Abychom získali datum narození, použijeme stejnou logiku. Získejte pozici @ znak a posunutím o 10 znaků zpět získáte počáteční hodnotu data narození. 10 je pevná délka. SUBSTRING(@lineString,CHARINDEX(‘@’,@lineString)-10,10) jak zjistit datum narození.
- Konečně je získání účtu na Instagramu jednoduché. Začněte z pozice @ znak pomocí CHARINDEX. Poznámka:30 je limit uživatelských jmen pro Instagram.
Podívejte se na výsledky na obrázku 7:
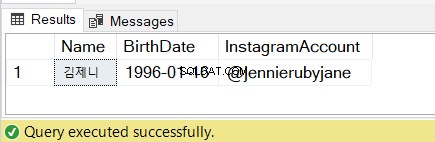
4. Použití SQL SUBSTRING v příkazu SELECT
Můžete také použít SUBSTRING v příkazu SELECT, ale nejprve musíme mít funkční data. Zde je kód:
SELECT
CAST(P.LastName AS CHAR(50))
+ CAST(P.FirstName AS CHAR(50))
+ CAST(ISNULL(P.MiddleName,'') AS CHAR(50))
+ CAST(ea.EmailAddress AS CHAR(50))
+ CAST(a.City AS CHAR(30))
+ CAST(a.PostalCode AS CHAR(15)) AS line
INTO PersonContacts
FROM Person.Person p
INNER JOIN Person.EmailAddress ea
ON P.BusinessEntityID = ea.BusinessEntityID
INNER JOIN Person.BusinessEntityAddress bea
ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Person.Address a
ON bea.AddressID = a.AddressID
Výše uvedený kód tvoří dlouhý řetězec obsahující jméno, e-mailovou adresu, město a PSČ. Chceme to také uložit do Kontaktů osob tabulka.
Nyní máme kód pro zpětnou analýzu pomocí SUBSTRING:
SELECT
TRIM(SUBSTRING(line,1,50)) AS [LastName]
,TRIM(SUBSTRING(line,51,50)) AS [FirstName]
,TRIM(SUBSTRING(line,101,50)) AS [MiddleName]
,TRIM(SUBSTRING(line,151,50)) AS [EmailAddress]
,TRIM(SUBSTRING(line,201,30)) AS [City]
,TRIM(SUBSTRING(line,231,15)) AS [PostalCode]
FROM PersonContacts pc
ORDER BY LastName, FirstName
Protože jsme použili sloupce s pevnou velikostí, není potřeba používat CHARINDEX.
Použití SQL SUBSTRING v klauzuli WHERE – výkonnostní past?
To je pravda. Nikdo vám nemůže zabránit v používání SUBSTRING v klauzuli WHERE. Je to platná syntaxe. Ale co když to způsobuje problémy s výkonem?
Proto to dokazujeme na příkladu a poté diskutujeme o tom, jak tento problém vyřešit. Nejprve si ale připravme data:
USE AdventureWorks
GO
SELECT * INTO SalesOrders FROM Sales.SalesOrderHeader soh
Nemohu pokazit SalesOrderHeader stůl, tak jsem to hodil na jiný stůl. Poté jsem vytvořil SalesOrderID v nových SalesOrders tabulka primární klíč.
Nyní jsme připraveni na dotaz. Používám dbForge Studio pro SQL Server se ZAPNUTÝM režimem profilování dotazů k analýze dotazů.
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE SUBSTRING(so.AccountNumber,4,4) = '4030'
Jak vidíte, výše uvedený dotaz běží dobře. Nyní se podívejte na diagram plánu profilu dotazu na obrázku 8:
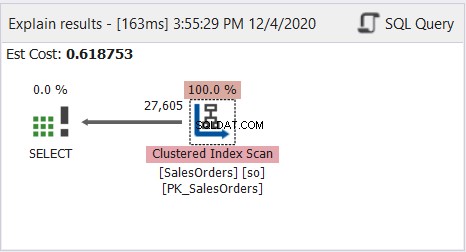
Schéma plánu vypadá jednoduše, ale podívejme se na vlastnosti uzlu Clustered Index Scan. Konkrétně potřebujeme Runtime Information:
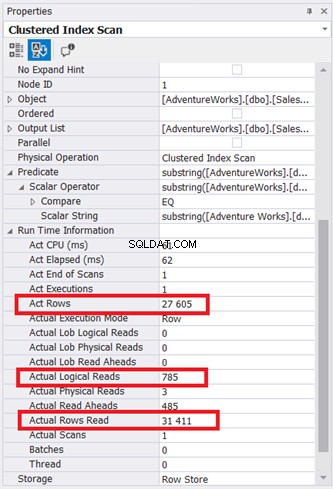
Obrázek 9 ukazuje stránky o velikosti 785 * 8 kB načtené databázovým strojem. Všimněte si také, že skutečné přečtení řádků je 31 411. Je to celkový počet řádků v tabulce. Dotaz však vrátil pouze 27 605 skutečných řádků.
Celá tabulka byla přečtena pomocí seskupeného indexu jako reference.
Proč?
Jde o to, že SQL Server potřebuje vědět, zda 4030 je podřetězec čísla účtu. Musí číst a vyhodnocovat každý záznam. Vyhoďte řádky, které nejsou stejné, a vraťte řádky, které potřebujeme. Dokončí práci, ale ne dostatečně rychle.
Co můžeme udělat, aby to běželo rychleji?
Vyhněte se SUBSTRING v klauzuli WHERE a dosáhněte stejného výsledku rychleji
Nyní chceme získat stejný výsledek bez použití SUBSTRING v klauzuli WHERE. Postupujte podle následujících kroků:
- Tabulku upravte přidáním vypočítaného sloupce s SUBSTRING(číslo účtu, 4,4) vzorec. Pojmenujme to AccountCategory pro nedostatek lepšího termínu.
- Vytvořte neshlukovaný index pro novou AccountCategory sloupec. Zahrňte Datum objednávky , Číslo účtu a CustomerID sloupce.
To je ono.
Změnili jsme klauzuli WHERE dotazu, abychom přizpůsobili novou Kategorii účtu sloupec:
SET STATISTICS IO ON
SELECT
so.SalesOrderID
,so.OrderDate
,so.CustomerID
,so.AccountNumber
FROM SalesOrders so
WHERE so.AccountCategory = '4030'
SET STATISTICS IO OFF
V klauzuli WHERE není žádný SUBSTRING. Nyní se podívejme na plán plánu:
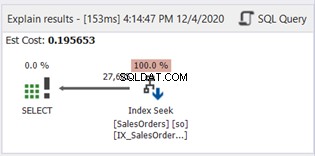
Index Scan byl nahrazen Index Seek. Všimněte si také, že SQL Server použil nový index ve vypočítaném sloupci. Dochází také ke změnám v logických čteních a skutečných čteních řádků? Viz obrázek 11:
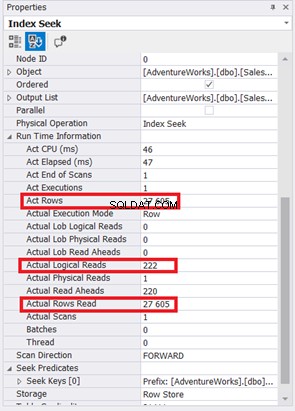
Snížení ze 785 na 222 logických čtení je velkým zlepšením, více než třikrát méně než původní logická čtení. Také to minimalizovalo Skutečné řádky Čtení pouze na ty řádky, které potřebujeme.
Použití SUBSTRING v klauzuli WHERE tedy není dobré pro výkon a hodí se pro jakoukoli jinou skalární funkci použitou v klauzuli WHERE.
Závěr
- Vývojáři se nemohou vyhnout analýze řetězců. Potřeba toho vznikne tak či onak.
- Při analýze řetězců je důležité znát informace v řetězci, pozice jednotlivých informací a jejich velikosti nebo délky.
- Jednou z funkcí analýzy je SQL SUBSTRING. Potřebuje pouze řetězec k analýze, pozici pro zahájení extrakce a délku řetězce k extrahování.
- SUBSTRING může mít různé chování mezi variantami SQL, jako je SQL Server, MySQL a Oracle.
- Můžete použít SUBSTRING s doslovnými řetězci a řetězci ve sloupcích tabulky.
- Použili jsme také SUBSTRING se znaky Unicode.
- Použití SUBSTRING nebo jakékoli skalární funkce v klauzuli WHERE může snížit výkon dotazů. Opravte to pomocí indexovaného vypočítaného sloupce.
Pokud považujete tento příspěvek za užitečný, sdílejte jej na svých preferovaných platformách sociálních médií nebo sdílejte svůj komentář níže?