Po mém příspěvku z minulého týdne se objevilo mnoho komentářů o dělení strun. Myslím, že pointa článku nebyla tak zřejmá, jak by mohla být:že strávit spoustu času a úsilí snahou „zdokonalit“ přirozeně pomalou rozdělovací funkci založenou na T-SQL by nebylo přínosné. Od té doby jsem shromáždil nejnovější verzi funkce pro dělení řetězců Jeffa Modena a porovnal jsem ji s ostatními:
ALTER FUNCTION [dbo].[DelimitedSplitN4K]
(@pString NVARCHAR(4000), @pDelimiter NCHAR(1))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
cteTally(N) AS (SELECT TOP (ISNULL(DATALENGTH(@pString)/2,0))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4),
cteStart(N1) AS (SELECT 1 UNION ALL
SELECT t.N+1 FROM cteTally t WHERE SUBSTRING(@pString,t.N,1) = @pDelimiter
),
cteLen(N1,L1) AS(SELECT s.N1,
ISNULL(NULLIF(CHARINDEX(@pDelimiter,@pString,s.N1),0)-s.N1,4000)
FROM cteStart s
)
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY l.N1),
Item = SUBSTRING(@pString, l.N1, l.L1)
FROM cteLen l;
GO (Jediné změny, které jsem provedl:Naformátoval jsem jej pro zobrazení a odstranil jsem komentáře. Původní zdroj můžete získat zde.)
Musel jsem udělat pár úprav ve svých testech, abych věrně reprezentoval Jeffovu funkci. A co je nejdůležitější:musel jsem zahodit všechny vzorky, které zahrnovaly jakékoli řetězce> 4 000 znaků. Změnil jsem tedy řetězce 5 000 znaků v tabulce dbo.strings na 4 000 znaků a soustředil jsem se pouze na první tři scénáře bez MAX (u prvních dvou jsem ponechal předchozí výsledky a pro nový jsem znovu provedl třetí testy délka řetězce 4 000 znaků). Ze všech testů kromě jednoho jsem také vypustil tabulku Numbers, protože bylo jasné, že výkon tam byl vždy minimálně 10krát horší. Následující graf ukazuje výkon funkcí v každém ze čtyř testů, opět v průměru za 10 spuštění a vždy s chladnou mezipamětí a čistými vyrovnávací paměti.
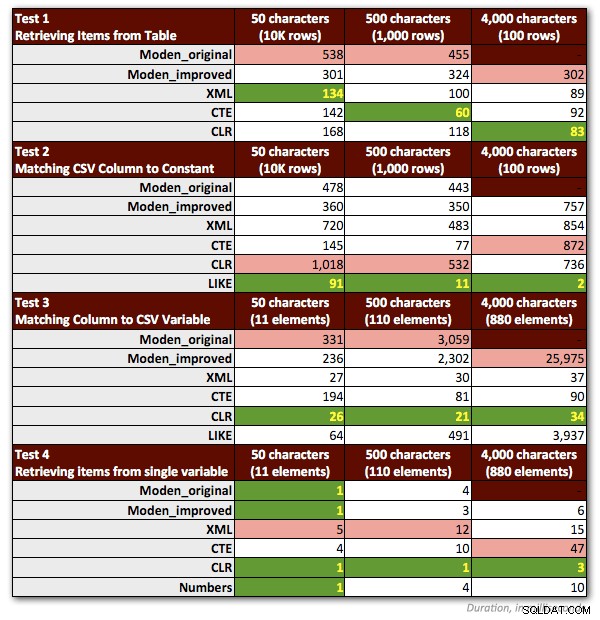
Zde jsou mé mírně upravené preferované metody pro každý typ úlohy:
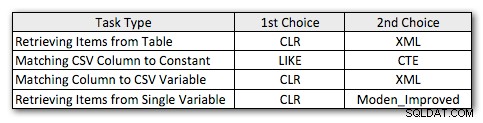
Všimnete si, že CLR zůstalo mou volbou, s výjimkou jednoho případu, kdy rozdělení nedává smysl. A v případech, kdy CLR není možností, jsou metody XML a CTE obecně efektivnější, s výjimkou případu rozdělení jedné proměnné, kde může být Jeffova funkce velmi dobře tou nejlepší volbou. Ale vzhledem k tomu, že možná budu potřebovat podporovat více než 4 000 znaků, může se řešení tabulky Numbers vrátit zpět do mého seznamu ve specifických situacích, kdy nesmím používat CLR.
Slibuji, že můj další příspěvek obsahující seznamy nebude vůbec hovořit o rozdělování prostřednictvím T-SQL nebo CLR a ukáže, jak tento problém zjednodušit bez ohledu na typ dat.
Mimochodem, všiml jsem si tohoto komentáře v jedné z verzí Jeffových funkcí, která byla zveřejněna v komentářích:Také děkuji tomu, kdo napsal první článek, který jsem kdy viděl, o „tabulkách čísel“, který se nachází na následující adrese URL, a Adamu Machanicovi za to, že mě k tomu před mnoha lety přivedl.https://web.archive.org/web/20150411042510/https://sqlserver2000.databases.aspfaq.com/why-should-i-consider-using-an -pomocná-tabulka-cisel.html
Ten článek jsem napsal v roce 2004. Takže kdo přidal komentář k funkci, není zač. :-)