Běžný scénář v mnoha aplikacích klient-server umožňuje koncovému uživateli diktovat pořadí řazení výsledků. Někteří lidé chtějí nejprve vidět položky s nejnižší cenou, někteří chtějí nejprve vidět nejnovější položky a někteří je chtějí vidět podle abecedy. To je složitá věc, kterou lze v Transact-SQL dosáhnout, protože nemůžete jen říct:
CREATE PROCEDURE dbo.SortOnSomeTable @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN ... ORDER BY @SortColumn; -- nebo ... ORDER BY @SortColumn @SortDirection;ENDGO
Je to proto, že T-SQL nepovoluje proměnné v těchto umístěních. Pokud pouze použijete @SortColumn, obdržíte:
Msg 1008, Level 16, State 1, Line xPoložka SELECT identifikovaná ORDER BY číslem 1 obsahuje proměnnou jako součást výrazu identifikujícího pozici sloupce. Proměnné jsou povoleny pouze při řazení pomocí výrazu odkazujícího na název sloupce.
(A když chybová zpráva říká „výraz odkazující na název sloupce“, může vám to připadat nejednoznačné a souhlasím. Mohu vás však ujistit, že to neznamená, že proměnná je vhodný výraz.)
Pokud se pokusíte připojit @SortDirection, chybová zpráva bude trochu neprůhlednější:
Zpráva 102, úroveň 15, stav 1, řádek xNesprávná syntaxe poblíž '@SortDirection'.
Existuje několik způsobů, jak to obejít, a vaším prvním instinktem může být použití dynamického SQL nebo zavedení výrazu CASE. Ale stejně jako u většiny věcí existují komplikace, které vás mohou donutit jít tou či onou cestou. Který byste tedy měli použít? Pojďme prozkoumat, jak by tato řešení mohla fungovat, a porovnat dopady na výkon u několika různých přístupů.
Ukázková data
Pomocí zobrazení katalogu, kterému pravděpodobně všichni rozumíme docela dobře, sys.all_objects, jsem vytvořil následující tabulku založenou na křížovém spojení, které omezuje tabulku na 100 000 řádků (chtěl jsem data, která zaplní mnoho stránek, ale dotazování nezabere příliš času a test):
VYTVOŘIT DATABÁZI OrderBy;GOUSE OrderBy;GO SELECT TOP (100000) key_col =ROW_NUMBER() OVER (ORDER BY s1.[object_id]), -- BIGINT s seskupeným indexem s1.[object_id], -- INT bez název indexu =s1.name -- NVARCHAR s podpůrným indexem COLLATE SQL_Latin1_General_CP1_CI_AS, type_desc =s1.type_desc -- NVARCHAR(60) bez indexu COLLATE SQL_Latin1_General_CP1_CI_AS, s1.modify_date -- datum a čas bez index_INTO dbo sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2ORDER BY s1.[object_id];
(Trik COLLATE spočívá v tom, že mnoho zobrazení katalogu má různé sloupce s různým řazením, což zajišťuje, že se tyto dva sloupce budou pro účely této ukázky shodovat.)
Pak jsem před optimalizací vytvořil typický klastrovaný/neshlukovaný indexový pár, který by mohl v takové tabulce existovat (pro klíč nemohu použít object_id, protože křížové spojení vytváří duplikáty):
VYTVOŘTE UNIKÁTNÍ CLUSTERED INDEX key_col ON dbo.sys_objects(key_col); CREATE INDEX name ON dbo.sys_objects(name);
Případy použití
Jak bylo zmíněno výše, uživatelé mohou chtít vidět tato data uspořádaná různými způsoby, takže si uvedeme některé typické případy použití, které chceme podpořit (a tím mám na mysli podporu, mám na mysli demonstraci):
- Seřazeno podle key_col ascending ** výchozí, pokud to uživatele nezajímá
- Seřazeno podle object_id (vzestupně/sestupně)
- Seřazeno podle názvu (vzestupně/sestupně)
- Seřazeno podle type_desc (vzestupně/sestupně)
- Seřazeno podle data úpravy (vzestupně/sestupně)
Uspořádání key_col ponecháme jako výchozí, protože by mělo být nejúčinnější, pokud uživatel nemá preference; protože key_col je libovolná náhrada, která by pro uživatele neměla nic znamenat (a nemusí jim být ani vystavena), není důvod povolit obrácené řazení v tomto sloupci.
Přístupy, které nefungují
Nejběžnějším přístupem, který vidím, když někdo poprvé začne tento problém řešit, je zavedení logiky řízení toku do dotazu. Očekávají, že budou schopni to udělat:
SELECT klíč_kol, [id_objektu], název, typ_desc, upravit_datumFROM dbo.sys_objectsORDER BY IF @SortColumn ='sloupec_klíče' key_colIF @SortColumn ='id_objektu' [id_objektu]IF @SortColumn =název 'název_směru...IF @SortDirection ='ASC' ASCELSE DESC;
Tohle evidentně nefunguje. Dále vidím, že CASE je zaveden nesprávně a používá podobnou syntaxi:
SELECT key_col, [object_id], name, type_desc,modify_dateFROM dbo.sys_objectsORDER BY CASE @SortColumn WHEN 'key_col' THEN key_col WHEN 'object_id' THEN [object_id] WHEN 'name' THEN name ... END CASE @HENS 'ASC' THEN ASC ELSE DESC END;
To je blíž, ale selhává ze dvou důvodů. Jedním z nich je, že CASE je výraz, který vrací přesně jednu hodnotu určitého datového typu; toto sloučí datové typy, které jsou nekompatibilní, a proto dojde k porušení výrazu CASE. Druhým je, že neexistuje způsob, jak podmíněně aplikovat směr řazení tímto způsobem bez použití dynamického SQL.
Přístupy, které fungují
Tři primární přístupy, které jsem viděl, jsou následující:
Seskupit kompatibilní typy a směry
Aby bylo možné použít CASE s ORDER BY, musí existovat odlišný výraz pro každou kombinaci kompatibilních typů a směrů. V tomto případě bychom museli použít něco takového:
CREATE PROCEDURE dbo.Sort_CaseExpanded @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN SET NOCOUNT ON; SELECT klíč_sloupec, [id_objektu], název, typ_desc, datum úpravy OD dbo.sys_objects ŘADIT PODLE VELIKOSTÍ, WHEN @SortDirection ='ASC' THEN CASE @SortColumn WHEN 'key_col' THEN key_col WHEN 'object_id' THEN [ENDHEN_id] SortDirection ='DESC' THEN CASE @SortColumn WHEN 'key_col' THEN key_col WHEN 'object_id' THEN [id_object] END END DESC, CASE WHEN @SortDirection ='ASC' THEN CASE @SortColumn' WHEN 'name' THEN' type_desc KONEC, CASE WHEN @SortDirection ='DESC' THEN CASE @SortColumn WHEN 'name' THEN name WHEN 'type_desc' THEN type_desc KONEC DESC, CASE WHEN @SortColumn ='modify_date' AND @SortDirection THE END =upravit , CASE WHEN @SortColumn ='modify_date' AND @SortDirection ='DESC' THEN Modify_date END DESC;END
Možná si řeknete, wow, to je ošklivý kousek kódu, a já bych s vámi souhlasil. Myslím, že to je důvod, proč mnoho lidí ukládá svá data do mezipaměti na frontendu a nechá prezentační vrstvu, aby se s tím žonglovala v různých pořadích. :-)
Tuto logiku můžete sbalit o něco dále převedením všech neřetězcových typů na řetězce, které budou správně řadit, např.
CREATE PROCEDURE dbo.Sort_CaseCollapsed @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN SET NOCOUNT ON; SELECT klíč_sloupec, [id_objektu], název, typ_desc, datum_změny Z dbo.sys_objects ŘADIT PODLE VELIKOSTÍ, WHEN @SortDirection ='ASC' THEN CASE @SortColumn WHEN 'key_col' THEN RIGHT('000000000000' + WHENM_col) object_id' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM([id_objektu]),1),'-'),'0') + REPLICATE('0', 23) + RTRIM([id_objektu]), 24) WHEN 'name' THEN name WHEN 'type_desc' THEN type_desc WHEN 'modify_date' THEN CONVERT(CHAR(19), Modify_date, 120) END END, CASE WHEN @SortDirection ='DESC' THEN CASE @SortColumn WHEN 'Rkey_col'' 000000000000' + RTRIM(sloupec_klíče), 12) WHEN 'id_objektu' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM([id_objektu]),1),'-'),'0') + REPLICATE('0', 23 ) + RTRIM([id_objektu]), 24) WHEN 'name' THEN name WHEN 'type_desc' THEN type_desc WHEN 'modify_date' THEN CONVERT(CHAR(19), datum_změny, 120) END END DESC;END Přesto je to docela ošklivý nepořádek a výrazy musíte opakovat dvakrát, abyste se vypořádali s různými směry řazení. Také bych se domníval, že použití OPTION RECOMPILE na tento dotaz by zabránilo tomu, aby vás štípalo sniffování parametrů. S výjimkou výchozího případu to není tak, že by většina práce, kterou zde děláme, byla kompilací.
Použití hodnocení pomocí funkcí okna
Objevil jsem tento úhledný trik od AndriyM, i když je nejužitečnější v případech, kdy všechny potenciální sloupce řazení jsou kompatibilního typu, jinak je výraz použitý pro ROW_NUMBER() stejně složitý. Nejchytřejší na tom je, že abychom mohli přepínat mezi vzestupným a sestupným pořadím, jednoduše vynásobíme ROW_NUMBER() 1 nebo -1. V této situaci jej můžeme použít následovně:
CREATE PROCEDURE dbo.Sort_RowNumber @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN SET NOCOUNT ON;;WITH x AS ( SELECT klíč_sloupec, [id_objektu], název, typ_desc, datum úpravy, rn =ŘÁDEK_ČÍSLO() PŘES ( ORDER BY CASE @SortColumn WHEN 'key_col' THEN RIGHT('000000000000' + RTRIM(key_col), 12) object_id' THEN RIGHT(COALESCE(NULLIF(LEFT(RTRIM([id_objektu]),1),'-'),'0') + REPLICATE('0', 23) + RTRIM([id_objektu]), 24) WHEN 'name' THEN name, KDYŽ 'type_desc' THEN type_desc KDYŽ 'modify_date' THEN CONVERT(CHAR(19), upravit_datum, 120) END ) * CASE @SortDirection KDYŽ 'ASC' THEN 1 ELSE -1 END FROM dbo.sys_ob key , [id_objektu], název, typ_desc, datum úpravy FROM x ORDER BY rn;ENDGO Opět zde může pomoci OPTION RECOMPILE. V některých z těchto případů si také můžete všimnout, že s vazbami zacházejí různé plány odlišně – například při objednávání podle jména obvykle uvidíte, že key_col bude v každé sadě duplicitních jmen procházet vzestupně, ale můžete také vidět hodnoty se promíchaly. Chcete-li zajistit předvídatelnější chování v případě remíz, můžete vždy přidat další klauzuli ORDER BY. Všimněte si, že pokud byste do prvního příkladu přidali key_col, budete z něj muset udělat výraz, aby key_col nebyl uveden v ORDER BY dvakrát (můžete to udělat například pomocí key_col + 0).
Dynamické SQL
Spousta lidí má k dynamickému SQL výhrady – nedá se číst, je to živná půda pro SQL injection, vede k nafouknutí mezipaměti plánů, maří účel použití uložených procedur… Některé z nich jsou prostě nepravdivé a některé z nich lze snadno zmírnit. Přidal jsem sem nějaké ověření, které lze stejně snadno přidat ke kterémukoli z výše uvedených postupů:
CREATE PROCEDURE dbo.Sort_DynamicSQL @SortColumn NVARCHAR(128) =N'key_col', @SortDirection VARCHAR(4) ='ASC'ASBEGIN SET NOCOUNT ON; -- odmítněte všechny neplatné směry řazení:IF UPPER(@SortDirection) NOT IN ('ASC','DESC') BEGIN RAISERROR('Neplatný parametr pro @SortDirection:%s', 11, 1, @SortDirection); NÁVRAT -1; END -- odmítněte všechny neočekávané názvy sloupců:IF LOWER(@SortColumn) NOT IN (N'key_col', N'object_id', N'name', N'type_desc', N'modify_date') BEGIN RAISERROR('Neplatný parametr pro @SortColumn:%s', 11, 1, @SortColumn); NÁVRAT -1; END SET @SortColumn =QUOTENAME(@SortColumn); DECLARE @sql NVARCHAR(MAX); SET @sql =N'SELECT sloupec_klíče, [id_objektu], název, typ_desc, datum úpravy FROM dbo.sys_objects ORDER BY ' + @SortColumn + ' ' + @SortDirection + ';'; EXEC sp_executesql @sql;END Porovnání výkonu
Vytvořil jsem uloženou proceduru wrapper pro každý postup výše, abych mohl snadno otestovat všechny scénáře. Čtyři procedury wrapperu vypadají takto, přičemž název procedury se samozřejmě liší:
CREATE PROCEDURE dbo.Test_Sort_CaseExpandedASBEGIN SET NOCOUNT ON; EXEC dbo.Sort_CaseExpanded; -- výchozí EXEC dbo.Sort_CaseExpanded N'name', 'ASC'; EXEC dbo.Sort_CaseExpanded N'name', 'DESC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'ASC'; EXEC dbo.Sort_CaseExpanded N'object_id', 'DESC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'ASC'; EXEC dbo.Sort_CaseExpanded N'type_desc', 'DESC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'ASC'; EXEC dbo.Sort_CaseExpanded N'modify_date', 'DESC';END
A pak pomocí SQL Sentry Plan Explorer jsem vygeneroval skutečné plány provádění (a související metriky) s následujícími dotazy a opakoval jsem proces 10krát, abych sečetl celkovou dobu trvání:
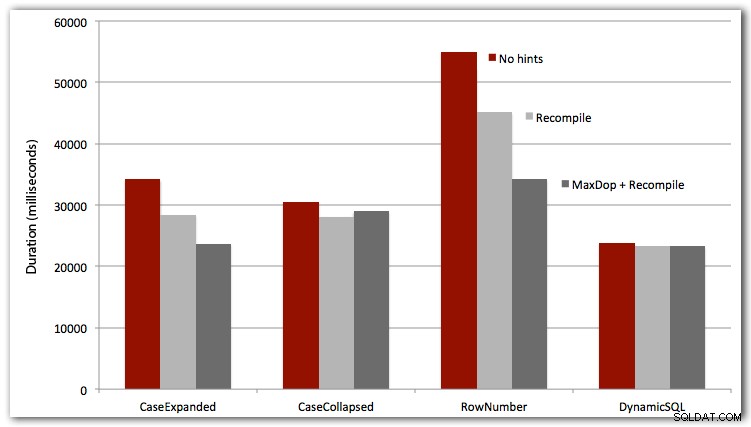
DBCC DROPCLEANBUFFERS;DBCC FREEPROCCACHE;EXEC dbo.Test_Sort_CaseExpanded;--EXEC dbo.Test_Sort_CaseCollapsed;--EXEC dbo.Test_Sort_RowNumber;--EXEC dbo.TestynaGO10Také jsem testoval první tři případy s OPTION RECOMPILE (nedává moc smysl pro dynamický případ SQL, protože víme, že to bude pokaždé nový plán) a všechny čtyři případy s MAXDOP 1, abych eliminoval interferenci paralelismu. Zde jsou výsledky:
Závěr
Pokud jde o přímý výkon, dynamické SQL pokaždé vítězí (i když v této sadě dat jen s malým náskokem). Přístup ROW_NUMBER() byl sice chytrý, ale v každém testu prohrál (promiň AndriyM).
Je to ještě zábavnější, když chcete zavést klauzuli WHERE, bez ohledu na stránkování. Tyto tři jsou jako dokonalá bouře pro zavedení složitosti do toho, co začíná jako jednoduchý vyhledávací dotaz. Čím více permutací má váš dotaz, tím je pravděpodobnější, že budete chtít vyhodit čitelnost z okna a použít dynamické SQL v kombinaci s nastavením „optimalizovat pro zátěže ad hoc“, abyste minimalizovali dopad plánů na jedno použití v mezipaměti plánu.