Podpůrný index může potenciálně pomoci vyhnout se nutnosti explicitního třídění v plánu dotazů při optimalizaci dotazů T-SQL zahrnujících okenní funkce. Pomocí podporného indexu Mám na mysli jeden s prvky pro dělení a řazení oken jako indexový klíč a zbytek sloupců, které se objevují v dotazu jako sloupce včetně indexu. Takový vzor indexování často označuji jako POC index jako zkratka pro rozdělení , objednávka, a krytí . Pokud se prvek pro rozdělení nebo uspořádání ve funkci okna neobjeví, přirozeně tuto část z definice indexu vynecháte.
Ale co dotazy zahrnující více okenních funkcí s různými potřebami řazení? Podobně, co když další prvky v dotazu kromě okenních funkcí také vyžadují uspořádání vstupních dat podle pořadí v plánu, jako je například klauzule ORDER BY prezentace? To může vést k tomu, že různé části plánu budou muset zpracovat vstupní data v různém pořadí.
Za takových okolností obvykle připustíte, že explicitní řazení je v plánu nevyhnutelné. Možná zjistíte, že kolik může ovlivnit syntaktické uspořádání výrazů v dotazu explicitní operátory řazení, které získáte v plánu. Dodržováním několika základních tipů můžete někdy snížit počet explicitních operátorů řazení, což může mít samozřejmě velký dopad na výkon dotazu.
Prostředí pro ukázky
Ve svých příkladech použiji ukázkovou databázi PerformanceV5. Zde si můžete stáhnout zdrojový kód pro vytvoření a naplnění této databáze.
Všechny příklady jsem spustil na SQL Server 2019 Developer, kde je k dispozici dávkový režim na rowstore.
V tomto článku se chci zaměřit na tipy související s potenciálem výpočtu funkce okna v plánu spoléhat se na uspořádaná vstupní data, aniž by bylo nutné v plánu zvláštní explicitní třídicí aktivitu. To je důležité, když optimalizátor používá sériový nebo paralelní režim řádků s funkcemi okna a když používá operátor Window Aggregate v sériovém dávkovém režimu.
SQL Server v současné době nepodporuje účinnou kombinaci paralelního vstupu pro zachování objednávky před operátorem agregace oken v paralelním dávkovém režimu. Chcete-li tedy použít paralelní dávkový operátor Window Aggregate, musí optimalizátor vložit zprostředkující operátor paralelního řazení v dávkovém režimu, i když je vstup již předobjednán.
Pro jednoduchost můžete zabránit paralelismu ve všech příkladech uvedených v tomto článku. Chcete-li toho dosáhnout, aniž byste museli přidávat nápovědu ke všem dotazům a bez nastavení možnosti konfigurace na úrovni serveru, můžete nastavit možnost konfigurace v rozsahu databáze MAXDOP až 1 , asi takhle:
USE PerformanceV5; ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 1;
Po dokončení testování příkladů v tomto článku jej nezapomeňte nastavit zpět na 0. Připomenu vám to na konci.
Alternativně můžete zabránit paralelismu na úrovni relace pomocí nezdokumentovaného DBCC OPTIMIZER_WHATIF příkaz, třeba takto:
DBCC OPTIMIZER_WHATIF(CPUs, 1);
Chcete-li po dokončení tuto možnost resetovat, vyvolejte ji znovu s hodnotou 0 jako počet CPU.
Až dokončíte zkoušení všech příkladů v tomto článku se zakázaným paralelismem, doporučuji povolit paralelismus a znovu vyzkoušet všechny příklady, abyste viděli, co se změní.
Tipy 1 a 2
Než začnu s tipy, podívejme se nejprve na jednoduchý příklad s funkcí okna navrženou tak, aby těžila z supp class="border indent shadow orting index.
Zvažte následující dotaz, který budu označovat jako Dotaz 1:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1 FROM dbo.Orders;
Nebojte se toho, že příklad je vymyšlený. Neexistuje žádný dobrý obchodní důvod pro výpočet průběžného součtu ID objednávek – tato tabulka má slušnou velikost s řádky 1 MM a chtěl jsem ukázat jednoduchý příklad s běžnou funkcí okna, jako je ta, která používá průběžný celkový výpočet.
Podle schématu indexování POC vytvoříte následující index pro podporu dotazu:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_od_oid ON dbo.Orders(custid, orderdate, orderid);
Plán pro tento dotaz je znázorněn na obrázku 1.
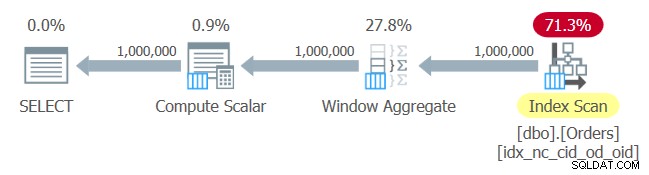 Obrázek 1:Plán pro dotaz 1
Obrázek 1:Plán pro dotaz 1
Tady žádné překvapení. Plán používá skenování pořadí indexu indexu, který jste právě vytvořili, a poskytuje data objednaná operátorovi Window Aggregate, aniž by bylo nutné explicitní řazení.
Dále zvažte následující dotaz, který zahrnuje více okenních funkcí s různými potřebami řazení a také klauzuli prezentace ORDER BY:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3 FROM dbo.Orders ORDER BY custid, orderid;
Tento dotaz budu označovat jako Dotaz 2. Plán tohoto dotazu je znázorněn na obrázku 2.
 Obrázek 2:Plán pro dotaz 2
Obrázek 2:Plán pro dotaz 2
Všimněte si, že v plánu jsou čtyři operátory řazení.
Pokud analyzujete různé funkce oken a potřeby uspořádání prezentací, zjistíte, že existují tři různé potřeby uspořádání:
- custid, orderdate, orderid
- orderid
- custid, orderid
Vzhledem k tomu, že jeden z nich (první ve výše uvedeném seznamu) může být podporován indexem, který jste vytvořili dříve, očekávali byste, že v plánu uvidíte pouze dva druhy. Proč má tedy plán čtyři druhy? Vypadá to, že SQL Server se nesnaží být příliš sofistikovaný s přeuspořádáním pořadí zpracování funkcí v plánu, aby se minimalizovalo řazení. Zpracuje funkce v plánu v pořadí, v jakém se objeví v dotazu. To je alespoň případ prvního výskytu každého jednotlivého požadavku na objednání, ale o tom se brzy rozepíšu.
Potřebu některých druhů v plánu můžete odstranit použitím následujících dvou jednoduchých postupů:
Tip 1:Pokud máte index podporující některé funkce okna v dotazu, zadejte je jako první.
Tip 2:Pokud dotaz zahrnuje funkce okna se stejnou potřebou řazení jako pořadí prezentace v dotazu, zadejte tyto funkce jako poslední.
Podle těchto tipů změníte pořadí vzhledu funkcí okna v dotazu takto:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders ORDER BY custid, orderid;
Tento dotaz budu označovat jako Dotaz 3. Plán tohoto dotazu je znázorněn na obrázku 3.
 Obrázek 3:Plán pro dotaz 3
Obrázek 3:Plán pro dotaz 3
Jak vidíte, plán má nyní pouze dva druhy.
Tip 3
SQL Server se nesnaží být příliš sofistikovaný v přeuspořádání pořadí zpracování okenních funkcí ve snaze minimalizovat řazení v plánu. Je však schopen určité jednoduché přestavby. Prohledává funkce okna na základě pořadí vzhledu v dotazu a pokaždé, když detekuje novou zřetelnou potřebu řazení, hledá dopředu další funkce okna se stejnou potřebou řazení, a pokud je najde, seskupuje je společně s prvním výskytem. V některých případech může dokonce použít stejný operátor k výpočtu více okenních funkcí.
Jako příklad zvažte následující dotaz:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2 FROM dbo.Orders ORDER BY custid, orderid;
Tento dotaz budu označovat jako Dotaz 4. Plán tohoto dotazu je znázorněn na obrázku 4.
 Obrázek 4:Plán pro dotaz 4
Obrázek 4:Plán pro dotaz 4
Funkce okna se stejnými potřebami řazení nejsou v dotazu seskupeny. V plánu jsou však stále jen dva druhy. Je to proto, že to, co se počítá z hlediska objednávky zpracování v plánu, je první výskyt každé jednotlivé potřeby objednávky. To mě přivádí ke třetímu tipu.
Tip 3:Ujistěte se, že dodržujete tipy 1 a 2 při prvním výskytu každé konkrétní potřeby objednávky. Následné výskyty stejné potřeby řazení, i když nesousedí, jsou identifikovány a seskupeny s prvním.
Tipy 4 a 5
Předpokládejme, že chcete ve výstupu vrátit sloupce vyplývající z výpočtů v okně v určitém pořadí zleva doprava. Ale co když objednávka není stejná jako objednávka, která minimalizuje řazení v plánu?
Předpokládejme například, že chcete stejný výsledek jako ten, který vytvořil Dotaz 2, pokud jde o pořadí sloupců zleva doprava ve výstupu (pořadí sloupců:ostatní sloupce, součet2, součet1, součet3), ale raději stejný plán jako ten, který jste získali pro Dotaz 3 (pořadí sloupců:ostatní sloupce, součet1, součet3, součet2), který má dva druhy místo čtyř.
To je dokonale proveditelné, pokud znáte čtvrtý tip.
Tip 4:Výše uvedená doporučení platí pro pořadí vzhledu funkcí okna v kódu, i když v rámci pojmenovaného tabulkového výrazu, jako je CTE nebo pohled, a i když vnější dotaz vrací sloupce v jiném pořadí než v pojmenovaný tabulkový výraz. Pokud tedy potřebujete ve výstupu vrátit sloupce v určitém pořadí, které se liší od optimálního pořadí z hlediska minimalizace řazení v plánu, postupujte podle tipů ohledně pořadí vzhledu v rámci pojmenovaného tabulkového výrazu a vraťte sloupce ve vnějším dotazu v požadovaném výstupním pořadí.
Následující dotaz, který budu označovat jako Dotaz 5, ilustruje tuto techniku:
WITH C AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Plán pro tento dotaz je znázorněn na obrázku 5.
 Obrázek 5:Plán pro dotaz 5
Obrázek 5:Plán pro dotaz 5
Stále máte v plánu pouze dva druhy, přestože pořadí sloupců ve výstupu je:other cols, sum2, sum1, sum3, jako v Query 2.
Jednou výhradou k tomuto triku s pojmenovaným tabulkovým výrazem je, že pokud na vaše sloupce v tabulkovém výrazu neodkazuje vnější dotaz, jsou vyloučeny z plánu, a proto se nepočítají.
Zvažte následující dotaz, který budu označovat jako Dotaz 6:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3,
max2, max1, max3,
avg2, avg1, avg3
FROM C
ORDER BY custid, orderid; Zde jsou všechny sloupce tabulkového výrazu odkazovány vnějším dotazem, takže optimalizace probíhá na základě prvního zřetelného výskytu každé potřeby řazení v rámci tabulkového výrazu:
- max1:custid, orderdate, orderid
- max3:orderid
- max2:custid, orderid
Výsledkem je plán s pouze dvěma druhy, jak je znázorněno na obrázku 6.
 Obrázek 6:Plán pro dotaz 6
Obrázek 6:Plán pro dotaz 6
Nyní změňte pouze vnější dotaz odstraněním odkazů na max2, max1, max3, avg2, avg1 a avg3, například takto:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Tento dotaz budu označovat jako Dotaz 7. Výpočty max1, max3, max2, avg1, avg3 a avg2 v tabulkovém výrazu jsou pro vnější dotaz irelevantní, takže jsou vyloučeny. Zbývající výpočty zahrnující funkce okna v tabulkovém výrazu, které jsou relevantní pro vnější dotaz, jsou výpočty sum2, sum1 a sum3. Bohužel se v tabulkovém výrazu neobjevují v optimálním pořadí z hlediska minimalizace řazení. Jak můžete vidět v plánu pro tento dotaz, jak je znázorněno na obrázku 7, existují čtyři druhy.
 Obrázek 7:Plán pro dotaz 7
Obrázek 7:Plán pro dotaz 7
Pokud si myslíte, že je nepravděpodobné, že budete mít ve vnitřním dotazu sloupce, na které se ve vnějším dotazu nebudete odkazovat, přemýšlejte o pohledech. Při každém dotazu na zobrazení vás může zajímat jiná podmnožina sloupců. S ohledem na tuto skutečnost by pátý tip mohl pomoci snížit počet druhů v plánu.
Tip 5:Ve vnitřním dotazu pojmenovaného tabulkového výrazu, jako je CTE nebo pohled, seskupte všechny funkce okna se stejnými potřebami řazení a postupujte podle tipů 1 a 2 v pořadí skupin funkcí.
Následující kód implementuje zobrazení založené na tomto doporučení:
CREATE OR ALTER VIEW dbo.MyView AS SELECT orderid, orderdate, custid, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2, SUM(orderid) OVER(PARTITION BY custid ORDER BY ordered ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders; GO
Nyní dotazujte pohled požadující pouze sloupce výsledků v okně sum2, sum1 a sum3 v tomto pořadí:
SELECT orderid, orderdate, custid, sum2, sum1, sum3 FROM dbo.MyView ORDER BY custid, orderid;
Tento dotaz budu označovat jako Dotaz 8. Získáte plán zobrazený na obrázku 8 pouze se dvěma druhy.
 Obrázek 8:Plán pro dotaz 8
Obrázek 8:Plán pro dotaz 8
Tip 6
Máte-li dotaz s více funkcemi oken s více odlišnými potřebami řazení, obecně platí, že můžete podpořit pouze jednu z nich s předobjednanými daty prostřednictvím indexu. To je případ, i když všechny funkce okna mají příslušné podpůrné indexy.
Dovolte mi to demonstrovat. Připomeňte si dříve, když jste vytvořili index idx_nc_cid_od_oid, který může podporovat funkce okna vyžadující data uspořádaná podle custid, orderdate, orderid, jako je například následující výraz:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING)
Předpokládejme, že kromě této funkce okna potřebujete ve stejném dotazu také následující funkci okna:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING)
Této funkci okna by prospěl následující index:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_oid ON dbo.Orders(custid, orderid);
Následující dotaz, který budu označovat jako Dotaz 9, vyvolá obě funkce okna:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders;
Plán pro tento dotaz je znázorněn na obrázku 9.
 Obrázek 9:Plán pro dotaz 9
Obrázek 9:Plán pro dotaz 9
Na svém počítači dostávám pro tento dotaz následující časové statistiky, přičemž výsledky jsou v SSMS zahozeny:
CPU time = 3234 ms, elapsed time = 3354 ms.
Jak bylo vysvětleno dříve, SQL Server prohledá výrazy v okně v pořadí, v jakém se objevily v dotazu, a zjistí, že může podporovat první pomocí uspořádaného skenování indexu idx_nc_cid_od_oid. Ale pak přidá do plánu operátor Sort, aby seřadil data, jako potřebuje funkce druhého okna. To znamená, že plán má N log N škálování. Neuvažuje o použití indexu idx_nc_cid_oid pro podporu funkce druhého okna. Pravděpodobně si říkáte, že to nejde, ale zkuste přemýšlet trochu mimo rámec. Nemohli byste vypočítat každou z funkcí okna na základě jejich příslušného pořadí indexů a pak spojit výsledky? Teoreticky můžete a v závislosti na velikosti dat, dostupnosti indexování a dalších dostupných zdrojích může být verze pro spojení někdy lepší. SQL Server tento přístup nezvažuje, ale určitě jej můžete implementovat tak, že sami napíšete spojení, například:
WITH C1 AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1
FROM dbo.Orders
),
C2 AS
(
SELECT orderid, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT C1.orderid, C1.orderdate, C1.custid, C1.sum1, C2.sum2
FROM C1
INNER JOIN C2
ON C1.orderid = C2.orderid; Tento dotaz budu označovat jako Dotaz 10. Plán tohoto dotazu je znázorněn na obrázku 10.
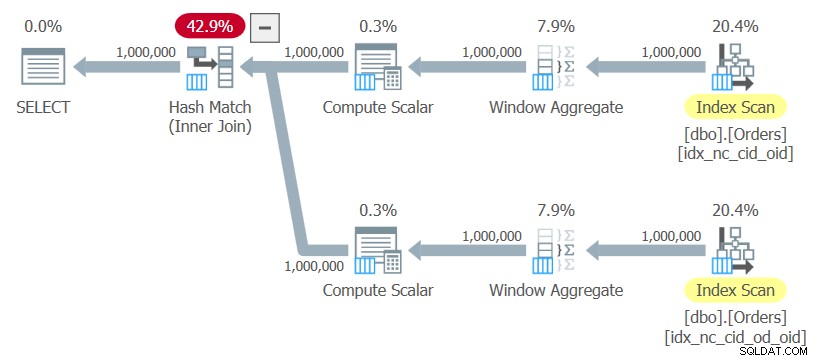 Obrázek 10:Plán pro dotaz 10
Obrázek 10:Plán pro dotaz 10
Plán používá uspořádané skenování dvou indexů bez jakéhokoli explicitního třídění, vypočítává funkce okna a ke spojení výsledků používá hašovací spojení. Tento plán se lineárně mění ve srovnání s předchozím, který má N log N měřítko.
Na svém počítači dostávám pro tento dotaz následující časové statistiky (opět s výsledky zahozenými v SSMS):
CPU time = 1000 ms, elapsed time = 1100 ms.
Abychom to shrnuli, zde je náš šestý tip.
Tip 6:Pokud máte více okenních funkcí s více odlišnými potřebami řazení a jste schopni všechny z nich podporovat pomocí indexů, vyzkoušejte verzi spojení a porovnejte její výkon s dotazem bez spojení.
Vyčištění
Pokud jste zakázali paralelismus nastavením možnosti konfigurace v rozsahu databáze MAXDOP na 1, znovu povolte paralelismus nastavením na 0:
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0;
Pokud jste použili volbu nedokumentované relace DBCC OPTIMIZER_WHATIF s volbou CPU nastavenou na 1, znovu povolte paralelismus nastavením na 0:
DBCC OPTIMIZER_WHATIF(CPUs, 0);
Pokud chcete, můžete znovu vyzkoušet všechny příklady s povoleným paralelismem.
K vyčištění nových indexů, které jste vytvořili, použijte následující kód:
DROP INDEX IF EXISTS idx_nc_cid_od_oid ON dbo.Orders; DROP INDEX IF EXISTS idx_nc_cid_oid ON dbo.Orders;
A následující kód pro odebrání zobrazení:
DROP VIEW IF EXISTS dbo.MyView;
Postupujte podle tipů pro minimalizaci počtu druhů
Funkce okna potřebují zpracovat objednaná vstupní data. Indexování může pomoci při eliminaci řazení v plánu, ale obvykle pouze pro jednu konkrétní potřebu uspořádání. Dotazy s potřebami více objednávek obvykle zahrnují některé druhy v jejich plánech. Dodržováním určitých tipů však můžete minimalizovat počet potřebných druhů. Zde je shrnutí tipů, které jsem zmínil v tomto článku:
- Tip 1: Pokud máte index pro podporu některých funkcí okna v dotazu, zadejte je jako první.
- Tip 2: Pokud dotaz zahrnuje funkce okna se stejnou potřebou řazení jako pořadí prezentace v dotazu, zadejte tyto funkce jako poslední.
- Tip 3: Ujistěte se, že dodržujete tipy 1 a 2 pro první výskyt každé konkrétní potřeby objednávky. Následující výskyty stejné potřeby řazení, i když nesousedí, jsou identifikovány a seskupeny společně s prvním.
- Tip 4: Výše uvedená doporučení platí pro pořadí vzhledu funkcí okna v kódu, i když v rámci pojmenovaného tabulkového výrazu, jako je CTE nebo pohled, a i když vnější dotaz vrací sloupce v jiném pořadí než ve výrazu pojmenované tabulky. Pokud tedy potřebujete ve výstupu vrátit sloupce v určitém pořadí, které se liší od optimálního pořadí z hlediska minimalizace řazení v plánu, postupujte podle tipů ohledně pořadí vzhledu v rámci pojmenovaného tabulkového výrazu a vraťte sloupce ve vnějším dotazu v požadovaném výstupním pořadí.
- Tip 5: Ve vnitřním dotazu výrazu pojmenované tabulky, jako je CTE nebo pohled, seskupte všechny funkce okna se stejnými potřebami řazení a postupujte podle tipů 1 a 2 v pořadí skupin funkcí.
- Tip 6: Pokud máte více okenních funkcí s více odlišnými potřebami řazení a jste schopni všechny z nich podporovat pomocí indexů, vyzkoušejte verzi spojení a porovnejte její výkon s dotazem bez spojení.