Další analýza dotazu klíčové populace
V části 3 naší série trasování ODBC se podíváme na další vhled do klíčů správy Accessu pro propojené tabulky ODBC a jak třídí a seskupuje dotazy SELECT dohromady. V předchozím článku jsme se dozvěděli, že sada záznamů typu dynaset jsou ve skutečnosti 2 samostatné dotazy, přičemž první dotaz načte pouze klíče propojené tabulky ODBC, která se následně použije k naplnění dat. V tomto článku si prostudujeme trochu více o tom, jak Access spravuje klíče a jak z toho vyvozuje, jaký klíč je třeba použít pro propojenou tabulku ODBC, a to s důsledky, které má. Začneme s řazením.
Přidání řazení do dotazu
V předchozím článku jste viděli, že jsme začali jednoduchým SELECT bez zvláštního objednání. Také jste viděli, jak Access poprvé načetl CityID a použijte výsledek prvního dotazu k naplnění následných dotazů, aby se uživateli při otevírání velké sady záznamů zdálo, že je rychlý. Pokud jste někdy zažili situaci, kdy při přidávání řazení nebo seskupování do dotazu došlo k náhlému zpomalení, toto vysvětlí proč.
Pojďme přidat řazení na StateProvinceID v dotazu Access:
SELECT Cities.* FROM Cities ORDER BY Cities.StateProvinceID;Nyní, když sledujeme ODBC SQL, měli bychom vidět výstup:
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" ORDER BY "Application"."Cities"."StateProvinceID" SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)Pokud porovnáte s trasováním z předchozího článku, můžete vidět, že jsou stejné, s výjimkou prvního dotazu. Access vložil řazení do prvního dotazu, kde používá k získání klíčů. To dává smysl, protože vynucením třídění na klíčích, které používá k procházení záznamů, je zaručeno, že Access bude mít vzájemnou shodu mezi pořadovou pozicí záznamu a tím, jak by měl být řazen. Záznamy pak naplní přesně stejným způsobem. Jediný rozdíl je v posloupnosti klíčů, které používá k vyplnění ostatních dotazů.
Podívejme se, co se stane, když přidáme GROUP BY počítáním měst podle státu:
SELECT Cities.StateProvinceID ,Count(Cities.CityID) AS CountOfCityID FROM Cities GROUP BY Cities.StateProvinceID;Výstup trasování by měl být:
SQLExecDirect:
SELECT
"StateProvinceID"
,COUNT("CityID" )
FROM "Application"."Cities"
GROUP BY "StateProvinceID" Možná jste si také všimli, že se dotaz nyní otevírá pomalu, a přestože může být nastaven jako sada záznamů typu dynaset, Access se rozhodl toto ignorovat a v zásadě s ním nakládat jako se sadou záznamů typu snímek. To dává smysl, protože dotaz nelze aktualizovat a protože v dotazu, jako je tento, nemůžete skutečně přejít na libovolnou pozici. Než budete moci volně procházet, musíte počkat, až budou načteny všechny řádky. StateProvinceID nelze použít k nalezení záznamu, protože v Cities by bylo několik záznamů stůl. I když jsem použil GROUP BY v tomto příkladu to nemusí být seskupení, které způsobí, že Access místo toho použije sadu záznamů typu snímek. Pomocí DISTINCT například by to mělo stejný účinek. Užitečným pravidlem k předpovědi, zda bude Access používat sadu záznamů typu dynaset, je dotaz, zda daný řádek ve výsledné sadě záznamů mapuje přesně na jeden řádek ve zdroji dat ODBC. Pokud tomu tak není, Access použije chování snímku, i když měl dotaz používat dynaset. V důsledku toho právě proto, že výchozí je sada záznamů typu dynaset, nezaručuje, že se ve skutečnosti bude jednat o sadu záznamů typu dynaset. Je to pouze požadavek , nikoli požadavek.
Určení klíče pro výběr
Možná jste si všimli v předchozím sledovaném SQL v tomto i v předchozích článcích, Access používal CityID jako klíč. Tento sloupec byl načten v prvním dotazu a poté použit v následujících připravených dotazech. Jak ale Access ví, které sloupce propojené tabulky má použít? Prvním sklonem by bylo říci, že kontroluje primární klíč a používá jej. To by však bylo nesprávné. Databázový stroj Access bude ve skutečnosti využívat SQLStatistics ODBC funkce během propojování nebo opětovného propojování tabulky, abyste zjistili, jaké indexy jsou k dispozici. Tato funkce vrátí sadu výsledků s jedním řádkem pro každý sloupec účastnící se indexu pro všechny indexy. Tato sada výsledků je vždy řazena a podle konvence bude vždy řadit seskupené indexy, hashované indexy a poté další typy indexů. V rámci každého typu indexu budou indexy seřazeny podle názvu abecedně. Databázový stroj Access vybere první jedinečný index, který najde, i když to není skutečný primární klíč. Abychom to dokázali, vytvoříme hloupou tabulku s několika lichými indexy:
CREATE TABLE dbo.SillyTable ( ID int CONSTRAINT PK_SillyTable PRIMARY KEY NONCLUSTERED, OtherStuff int CONSTRAINT UQ_SillyTable_OtherStuff UNIQUE CLUSTERED, SomeValue nvarchar(255) );Pokud pak naplníme tabulku nějakými daty a propojíme je v Accessu a otevřeme zobrazení datového listu v propojené tabulce, uvidíme to v trasovaném ODBC SQL. Pro stručnost jsou zahrnuty pouze první 2 příkazy.
SQLExecDirect: SELECT "dbo"."SillyTable"."OtherStuff" FROM "dbo"."SillyTable" SQLPrepare: SELECT "ID" ,"OtherStuff" ,"SomeValue" FROM "dbo"."SillyTable" WHERE "OtherStuff" = ?Protože
OtherStuff podílí se na seskupeném indexu, přišel před skutečný primární klíč, a proto byl databázovým strojem Accessu vybrán k použití v sadě záznamů typu dynaset pro výběr jednotlivého řádku. A to i navzdory skutečnosti, že název jedinečného seskupeného indexu by následoval za názvem primárního indexu. Taktikou, jak přinutit databázový stroj Accessu k výběru konkrétního indexu pro tabulku, by bylo změnit její typ nebo přejmenovat název tak, aby se třídil podle abecedy v rámci skupiny typu indexu. V případě SQL Serveru jsou primární klíče obvykle seskupené a může existovat pouze jeden seskupený index, takže je šťastná náhoda, že se obvykle jedná o správný index pro použití databázového stroje Access. Pokud však databáze SQL Server obsahuje tabulky s neklastrovanými primárními klíči a existuje seskupený jedinečný index, nemusí to být optimální volba. V případech, kdy vůbec neexistují žádné seskupené indexy, můžete ovlivnit, které jedinečné indexy se použijí, pojmenováním indexu tak, aby se řadil před ostatními indexy. To může být užitečné u jiného softwaru RDBMS, kde vytvoření seskupeného indexu pro primární klíč není praktické nebo možné. Index na přístupové straně pro propojený SQL pohled nebo tabulku bez indexů
Při propojení s pohledem SQL nebo tabulkou SQL, která nemá definované žádné indexy nebo primární klíč, nebudou pro databázový stroj Accessu dostupné žádné indexy. Pokud jste použili správce propojených tabulek k propojení tabulky nebo zobrazení SQL bez indexů, možná se vám zobrazilo toto dialogové okno:
 Pokud vybereme
Pokud vybereme ID , dokončete propojení, otevřete propojenou tabulku v návrhovém zobrazení a poté dialogové okno indexy, měli bychom vidět toto:
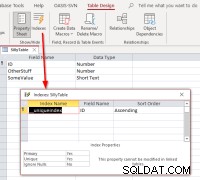 Ukazuje to, že tabulka má index s názvem
Ukazuje to, že tabulka má index s názvem __uniqueindex ale v původním zdroji dat neexistuje. Co se děje? Odpověď zní, že Access vytvořil Přístupovou stranu index pro jeho použití, aby pomohl identifikovat, které lze použít jako identifikátor záznamu pro takové tabulky nebo pohledy. Pokud se vám stane, že programově přepojíte tabulky namísto použití Správce propojených tabulek, zjistíte, že je nutné replikovat chování, aby bylo možné takové propojené tabulky aktualizovat. To lze provést spuštěním příkazu Access SQL:
CREATE UNIQUE INDEX [__uniqueindex] ON SillyTable (ID);Můžete použít například
CurrentDb.Execute k provedení Access SQL k vytvoření indexu na propojené tabulce. Neměli byste jej však spouštět jako předávací dotaz, protože index není ve skutečnosti vytvořen na serveru. Povolení aktualizace této propojené tabulky je pouze pro výhody aplikace Access. Stojí za zmínku, že Access povolí přesně jeden index pro takovou propojenou tabulku a pouze v případě, že již indexy nemá. Nicméně můžete vidět, že použití SQL pohledu může být žádoucí volbou pro případy, kdy vám návrh databáze neumožňuje používat seskupené indexy a nechcete si pohrávat s názvem indexu, abyste přesvědčili databázový stroj Access, aby tento index používal, ne ten index. Můžete explicitně ovládat index a sloupce, které by měl zahrnovat při propojování pohledu SQL.
Závěry
Z předchozího článku jsme viděli, že sada záznamů typu dynaset obvykle zadává 2 dotazy. První dotaz se obvykle zabývá vyplněním položky Podívali jsme se podrobněji na to, jak Access zpracovává populaci klíčů, kterou použije pro sadu záznamů typu dynaset. Viděli jsme, jak Access ve skutečnosti převede jakékoli řazení z původního dotazu Accessu a poté jej použije v dotazu klíčové populace. Viděli jsme, že řazení dotazu klíčové populace přímo ovlivňuje, jak budou data v sadě záznamů tříděna a prezentována uživateli. To umožňuje uživateli dělat věci, jako je skok na libovolný záznam na základě pořadové pozice seznamu.
Pak jsme viděli, že seskupování a další operace SQL, které brání mapování jedna jedna mezi vráceným řádkem a původním řádkem, způsobí, že Access bude s dotazem Accessu zacházet, jako by se jednalo o sadu záznamů typu snímek, a to navzdory požadavku na sadu záznamů typu dynaset.
Poté jsme se podívali na to, jak Access určuje klíč, který se má použít pro správu aktualizací pomocí propojené tabulky ODBC. Na rozdíl od toho, co bychom mohli očekávat, nezvolí nutně primární klíč tabulky, ale spíše první jedinečný index, který najde, v závislosti na typu indexu a názvu indexu. Probrali jsme strategie, jak zajistit, aby Access vybral správný jedinečný index. Podívali jsme se na pohled SQL, který normálně nemá žádné indexy, a probrali jsme metodu, jak informovat Access, jak klíčovat pohled SQL nebo tabulku, která nemá žádný primární klíč, což nám umožňuje větší kontrolu nad tím, jak Access zpracuje aktualizace pro tyto propojené tabulky ODBC.
V příštím článku se podíváme na to, jak Access skutečně provádí aktualizace dat, když uživatelé provádějí změny prostřednictvím dotazu Access nebo zdroje záznamů.
Naši odborníci na přístup jsou k dispozici, aby vám pomohli. Zavolejte nám na číslo 773-809-5456 nebo nám napište na adresu sales@itimpact.com.