Data můžete importovat ze souboru CSV (Comma Separated Values) do databáze Neo4j. Chcete-li to provést, použijte LOAD CSV doložka.
Možnost načíst soubory CSV do Neo4j usnadňuje import dat z jiného databázového modelu (například relační databáze).
Pomocí Neo4j můžete načíst soubory CSV z místní nebo vzdálené adresy URL.
Pro přístup k souboru uloženému lokálně (na databázovém serveru) použijte file:/// URL. Jinak můžete importovat vzdálené soubory pomocí kteréhokoli z protokolů HTTPS, HTTP a FTP.
Načíst soubor CSV
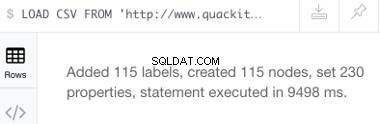
Načteme soubor CSV s názvem genres.csv pomocí protokolu HTTP. Není to velký soubor — obsahuje seznam 115 hudebních žánrů, takže vytvoří 115 uzlů (a 230 vlastností).
Tento soubor je uložen na Quackit.com, takže tento kód můžete spustit z vašeho prohlížeče Neo4j a měl by se importovat přímo do vaší databáze (za předpokladu, že jste připojeni k internetu).
Soubor si také můžete stáhnout zde:žánry.csv
LOAD CSV FROM 'https://www.quackit.com/neo4j/tutorial/genres.csv' AS line
CREATE (:Genre { GenreId: line[0], Name: line[1]})
V případě potřeby můžete některá pole ze souboru CSV vynechat. Pokud například nechcete, aby bylo první pole importováno do databáze, můžete jednoduše vynechat GenreId: line[0], z výše uvedeného kódu.
Spuštěním výše uvedeného příkazu by měla vzniknout následující zpráva o úspěchu:
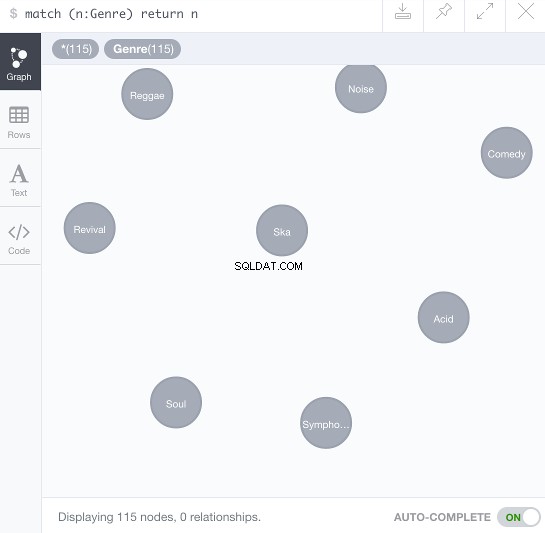
Na to můžete navázat dotazem a zobrazit nově vytvořené uzly:
MATCH (n:Genre) RETURN n
Výsledkem by měly být uzly rozptýlené kolem rámce vizualizace dat:
Importujte soubor CSV obsahující záhlaví
Předchozí soubor CSV neobsahoval žádná záhlaví. Pokud soubor CSV obsahuje záhlaví, můžete použít WITH HEADERS .
Použití této metody vám také umožňuje odkazovat na každé pole podle názvu sloupce/záhlaví.
Máme tu další CSV soubor, tentokrát s hlavičkami. Tento soubor obsahuje seznam skladeb alba.
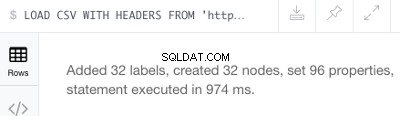
Opět se nejedná o velký soubor — obsahuje seznam 32 stop, takže vytvoří 32 uzlů (a 96 vlastností).
Tento soubor je také uložen na Quackit.com, takže tento kód můžete spustit z vašeho prohlížeče Neo4j a měl by se importovat přímo do vaší databáze (za předpokladu, že jste připojeni k internetu).
Soubor si také můžete stáhnout zde:tracks.csv
LOAD CSV WITH HEADERS FROM 'https://www.quackit.com/neo4j/tutorial/tracks.csv' AS line
CREATE (:Track { TrackId: line.Id, Name: line.Track, Length: line.Length}) To by mělo vytvořit následující zprávu o úspěchu:
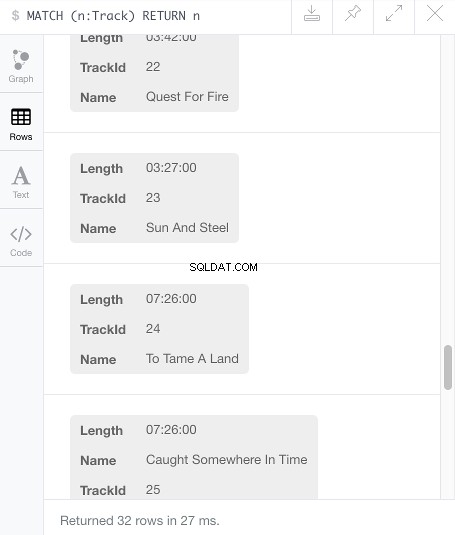
Následuje dotaz na zobrazení nově vytvořených uzlů:
MATCH (n:Track) RETURN n
Výsledkem by měly být nové uzly rozptýlené kolem rámce vizualizace dat.
Klikněte na Řádky zobrazíte každý uzel a jeho tři vlastnosti:
Vlastní oddělovač pole
V případě potřeby můžete zadat vlastní oddělovač pole. Můžete například zadat středník namísto čárky, pokud je soubor CSV formátován tímto způsobem.
Chcete-li to provést, jednoduše přidejte FIELDTERMINATOR doložka k prohlášení. Takhle:
LOAD CSV WITH HEADERS FROM 'https://www.quackit.com/neo4j/tutorial/tracks.csv' AS line FIELDTERMINATOR ';'
CREATE (:Track { TrackId: line.Id, Name: line.Track, Length: line.Length}) Import velkých souborů
Pokud se chystáte importovat soubor s velkým množstvím dat, PERODIC COMMIT klauzule může být užitečná.
Pomocí PERIODIC COMMIT přikáže Neo4j, aby potvrdil data po určitém počtu řádků. To snižuje režii paměti stavu transakce.
Výchozí hodnota je 1000 řádků, takže data budou potvrzena každých tisíc řádků.
Chcete-li použít PERIODIC COMMIT stačí vložit USING PERIODIC COMMIT na začátku příkazu (před LOAD CSV )
Zde je příklad:
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM 'https://www.quackit.com/neo4j/tutorial/tracks.csv' AS line
CREATE (:Track { TrackId: line.Id, Name: line.Track, Length: line.Length}) Nastavení míry pravidelných závazků
Můžete také změnit sazbu z výchozích 1000 řádků na jiné číslo. Jednoduše přidejte číslo za USING PERIODIC COMMIT :
Takhle:
USING PERIODIC COMMIT 800
LOAD CSV WITH HEADERS FROM 'https://www.quackit.com/neo4j/tutorial/tracks.csv' AS line
CREATE (:Track { TrackId: line.Id, Name: line.Track, Length: line.Length}) Formát/Požadavky CSV
Zde je několik informací o tom, jak by měl být formátován soubor CSV při použití LOAD CSV :
- Kódování znaků musí být UTF-8.
- Ukončení koncové linky je závislé na systému, například
\nv systému Unix nebo\r\nv systému Windows. - Zakončovací znak musí být čárka
,pokud není uvedeno jinak pomocíFIELDTERMINATORmožnost. - Znakem pro citaci řetězce jsou dvojité uvozovky
"(tyto položky jsou odstraněny při načítání dat). - Všechny znaky, které je třeba zakódovat, lze zakódovat zpětným lomítkem
\charakter. LOAD CSVpodporuje zdroje komprimované pomocí gzip, Deflate a také ZIP archivy.