Funkce OVER a PARTITION BY jsou obě funkce používané k rozdělení sady výsledků podle zadaných kritérií.
Tento článek vysvětluje, jak lze tyto dvě funkce použít ve spojení k načtení rozdělených dat velmi specifickými způsoby.
Příprava některých ukázkových dat
Chcete-li provést naše ukázkové dotazy, nejprve vytvořte databázi s názvem „studentdb“.
V okně dotazu spusťte následující příkaz:
CREATE DATABASE schooldb;
Dále musíme vytvořit tabulku „student“ v databázi „studentdb“. Tabulka studentů bude mít pět sloupců:id, jméno, věk, pohlaví a celkové_skóre.
Jako vždy se před experimentováním s novým kódem ujistěte, že máte dobrou zálohu. Pokud si nejste jisti, přečtěte si tento článek o zálohování databází SQL Server.
Provedením následujícího dotazu vytvořte tabulku studentů.
USE schooldbCREATE TABLE student( id INT PRIMÁRNÍ KLÍČ IDENTITA, jméno VARCHAR(50) NOT NULL, pohlaví VARCHAR(50) NOT NULL, věk INT NOT NULL, total_score INT NOT NULL, )
Nakonec musíme do databáze vložit nějaká fiktivní data, se kterými budeme pracovat.
POUŽÍVEJTE schooldbINSERT INTO student VALUES ('Jolly', 'Žena', 20, 500), ('Jon', 'Muž', 22, 545), ('Sara', 'Žena', 25, 600), ('Laura', 'Žena', 18, 400), ('Alan', 'Muž', 20, 500), ('Kate', 'Žena', 22, 500), ('Joseph', 'Muž' , 18, 643), ('Myši', 'Muž', 23, 543), ('Moudrý', 'Muž', 21, 499), ('Elis', 'Žena', 27, 400);
Nyní jsme připraveni pracovat na problému a zjistit, koho můžeme použít Over a Partition By k jeho vyřešení.
Problém
V tabulce studentů máme 10 záznamů a chceme zobrazit jméno, id a pohlaví pro všechny studenty a navíc chceme zobrazit celkový počet studentů, kteří patří ke každému pohlaví, průměrný věk studentů každého pohlaví a součet hodnot ve sloupci total_score pro každé pohlaví.
Výsledná sada, kterou hledáme, je následující:
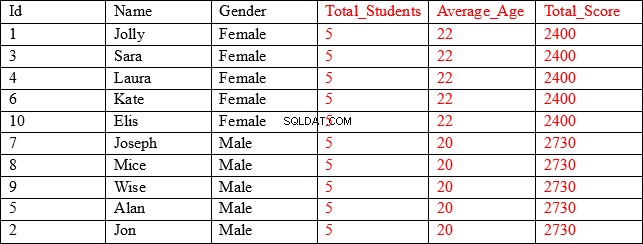
Jak vidíte, první tři sloupce (zobrazené černě) obsahují jednotlivé hodnoty pro každý záznam, zatímco poslední tři sloupce (zobrazené červeně) obsahují agregované hodnoty seskupené podle sloupce pohlaví. Například ve sloupci Průměrný_věk je na prvních pěti řádcích uveden průměrný věk a celkové skóre všech záznamů, kde pohlaví je Žena.
Naše sada výsledků obsahuje agregované výsledky spojené s neagregovanými sloupci.
K načtení agregovaných výsledků seskupených podle konkrétního sloupce můžeme jako obvykle použít klauzuli GROUP BY.
USE schooldbSELECT gender, count(gender) AS Total_Students, AVG(age) as Average_Age, SUM(total_score) as Total_ScoreFROM studentGROUP BY gender
Pojďme se podívat, jak můžeme získat Total_Students, Average_Age a Total_Score studentů seskupených podle pohlaví.
Uvidíte následující výsledky:

Nyní to rozšíříme a přidáme ‚id‘ a ‚name‘ (neagregované sloupce v příkazu SELECT) a uvidíme, zda můžeme dosáhnout požadovaného výsledku.
USE schooldbSELECT id, name, gender, count(gender) AS total_students, AVG(age) as Average_Age, SUM(total_score) as Total_ScoreFROM studentGROUP BY gender
Když spustíte výše uvedený dotaz, zobrazí se chyba:

Chyba říká, že sloupec id tabulky studentů je v příkazu SELECT neplatný, protože v dotazu používáme klauzuli GROUP BY.
To znamená, že budeme muset použít agregační funkci na sloupec id nebo ji budeme muset použít v klauzuli GROUP BY. Stručně řečeno, toto schéma náš problém neřeší.
Řešení pomocí příkazu JOIN
Jedním z řešení by bylo použití příkazu JOIN ke spojení sloupců s agregovanými výsledky se sloupci obsahujícími neagregované výsledky.
K tomu potřebujete dílčí dotaz, který načte pohlaví, celkem_studentů, průměr_věku a celkové_skóre studentů seskupených podle pohlaví. Tyto výsledky lze poté připojit k výsledkům získaným z dílčího dotazu pomocí vnějšího příkazu SELECT. To se použije na sloupec pohlaví dílčího dotazu obsahujícího agregovaný výsledek a sloupec pohlaví tabulky student. Vnější příkaz SELECT by obsahoval neagregované sloupce, tj. 'id' a 'name', jak je uvedeno níže.
USE schooldbSELECT id, name, Aggregation.gender, Agregation.Total_students, Agregation.Average_Age, Agregation.Total_ScoreFROM studentINNER JOIN(SELECT gender, count(gender) AS Total_students, AVG(age) AS Average_Age, SUM(total_ScoreFROM) AS studentGROUP BY gender) AS Aggregationon Aggregation.gender =student.gender
Výše uvedený dotaz vám poskytne požadovaný výsledek, ale není optimálním řešením. Museli jsme použít příkaz JOIN a dílčí dotaz, který zvyšuje složitost skriptu. Toto není elegantní ani efektivní řešení.
Lepším přístupem je použití klauzulí OVER a PARTITION BY ve spojení.
Řešení pomocí OVER a PARTITION BY
Chcete-li použít klauzule OVER a PARTITION BY, stačí zadat sloupec, podle kterého chcete rozdělit agregované výsledky. To je nejlépe vysvětleno na příkladu.
Pojďme se podívat na dosažení našeho výsledku pomocí OVER a PARTITION BY.
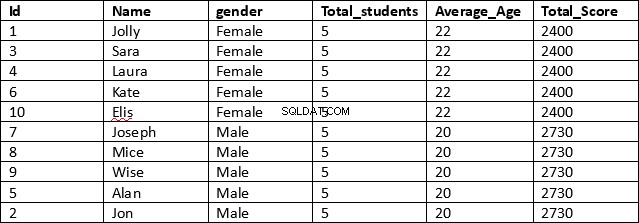
USE schooldbSELECT id, name, gender,COUNT(gender) OVER (PARTITION BY gender) AS Total_students,AVG(age) OVER (PARTITION BY gender) AS Average_Age,SUM(total_score) OVER (PARTITION BY gender) AS Total_ScoreFROM student
To je mnohem efektivnější výsledek. V prvním řádku skriptu jsou načteny sloupce id, name a gender. Tyto sloupce neobsahují žádné agregované výsledky.
Dále pro sloupce, které obsahují agregované výsledky, jednoduše zadáme agregovanou funkci, za ní následuje klauzule OVER a poté v závorce uvedeme klauzuli PARTITION BY následovanou názvem sloupce, ve kterém chceme, aby byly naše výsledky rozděleny, jak je znázorněno. níže.
Odkazy
- Microsoft – Pochopení klauzule OVER
- Půlnoční DBA – Úvod do OVER a PARTITION BY
- StackOverflow – rozdíl mezi PARTITION BY a GROUP BY