Někdy aplikační dotazy do databáze vracejí velký počet řádků. Ačkoli jsou načtená data uložena v mezipaměti v rámci ResultSet objekt, je často příliš velký na to, aby se s nimi dalo pracovat. V důsledku toho je musíme být schopni filtrovat v různých sadách dat, abychom omezili viditelné řádky. Tento článek se ponoří do popisu aspektu filtrování JDBC RowSet s vhodnými příklady.
Přehled RowSet
Sada řádků je rozhraní, které doplňuje model komponent JDBC API for JavaBeans. Poskytuje sadu vlastností, které umožňují konfigurovat její instanci pro připojení ke zdroji dat JDBC. Sada řádků instance se primárně používá k načítání dat ze zdroje dat. Metody setter tohoto rozhraní se používají k naplnění parametrů vlastnosti command dotazu SQL, který se pak používá k načítání záznamů z relační databáze. Protože RowSet dodržuje model komponent JavaBean, podporuje události JavaBean. Tyto události se používají k upozornění ostatních komponent na události, jako je například změna hodnoty v sadě řádků. Protože RowSet rozhraní je navrženo jako vrstva nad ovladačem JDBC, je otevřené pro vlastní implementaci. Tato svoboda umožňuje prodejci vyrobit si vlastní jemně vyladěný efekt a odeslat jej s produktem JDBC.
FilteredRowSet
FilteredRowSet je rozšířením rozhraní RowSet rodina. Existuje referenční implementace tohoto rozhraní nazvaná FilteredRowSetImpl třída. Poskytnout vlastní implementaci FilteredRowSet rozhraní, lze buď rozšířit FilteredRowSetImpl třídy nebo použijte FilteredRowSet rozhraní podle vašeho požadavku. V některých případech potřebujeme použít nějakou formu filtrování obsahu, který RowSet aporty. Jednoduchým možným řešením je poskytnout dotazovací jazyk pro všechny RowSet implementací. Ale pak to není životaschopný přístup, protože RowSet je postaven s myšlenkou odpojené lehké součásti. Tím by byl objekt těžký a odporovalo by to principu jeho designu. Potřebujeme přístup, který tuto potřebu řeší, ale zároveň nezahrnuje těžký dotazovací jazyk spolu s logikou zpracování filtrování. JDBC FilteredRowSet standardní implementace rozšiřuje RowSet prostřednictvím dílčích rozhraní, jako je CachedRowSet a WebRowSet resp. FilteredRowSet může manipulovat s kurzorem pomocí sady chráněných metod manipulace s kurzorem, které poskytuje CachedRowSet rozhraní. Tyto metody lze přepsat podle požadavků a pomoci při filtrování Sada řádků obsah.
Rychlý příklad
Zde je příklad pro ilustraci FilteredRowSet se používá k uložení obsahu vráceného dotazem spuštěným do databáze. Výsledek dotazu je filtrován podle konfigurace použité pro FilteredRowset implementace. To definuje viditelný obsah nebo řádky, které nás zajímají z výsledku vráceného dotazem. V následujícím příkladu jsme vytvořili třídu filtru s názvem SimpleFilter . Tato třída v našem případě definuje vlastní implementaci FilteredRowSet . Tento filtr jsme pak použili na výsledek vrácený z databázového dotazu. Filtrování znamená omezení počtu řádků, které budou viditelné. Proto zde omezíme počet záznamů informací o knize podle zadaného jména vybraného autora.
Pro praktické použití jsou následující tabulky databáze používané s nadcházejícím kódem Java.
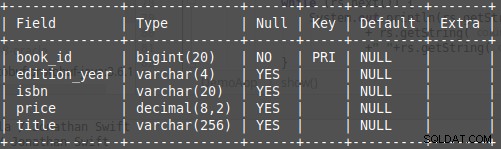
Obrázek 1: Tabulka databáze, kniha
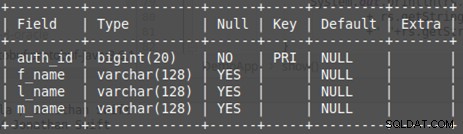
Obrázek 2: Tabulka databáze, autor
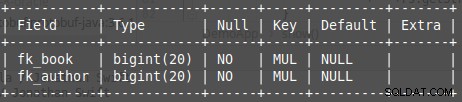
Obrázek 3: Tabulka databáze, autor_knihy
SimpleFilter třída implementuje Predikát s vyhodnocovacími metodami k implementaci našeho vlastního filtru.
package org.mano.example;
import javax.sql.RowSet;
import javax.sql.rowset.Predicate;
import java.sql.SQLException;
public class SimpleFilter implements Predicate {
private String[] authors;
private String colname = null;
private int colno = -1;
public SimpleFilter(String[] authors, String colname) {
this.authors = authors;
this.colno = -1;
this.colname = colname;
}
public SimpleFilter(String[] authors, int colno) {
this.authors = authors;
this.colno = colno;
this.colname = null;
}
@Override
public Boolean evaluate(Object value, String colName) {
if (colName.equalsIgnoreCase(this.colname)) {
for (String author : this.authors) {
if (author.equalsIgnoreCase((String)value)) {
return true;
}
}
}
return false;
}
@Override
public Boolean evaluate(Object value, int colNumber) {
if (colNumber == this.colno) {
for (String author : this.authors)
if (author.equalsIgnoreCase((String)value)) {
return true;
}
}
}
return false
}
@Override
public Boolean evaluate(RowSet rs) {
if (rs == null) return false;
try {
for (int i=0;i<authors.length;i++) {
String al = null;
if (this.colno> 0) {
al = (String)rs.getObject(this.colno);
} else if (this.colname != null) {
al = (String)rs.getObject(this.colname);
} else {
return false;
}
if (al.equalsIgnoreCase(authors[i])) {
return true;
}
}
} catch (SQLException e) {
return false;
}
return false;
}
}
Tato třída se používá ke spuštění SimpleRowSet třída filtru. Všimněte si, jak jsme použili FilteredRowSet k filtrování dat v aplikaci. Ke zpracování dochází spíše na úrovni aplikace než na úrovni databáze SQL. V důsledku toho můžeme implementovat řadu filtrů a aplikovat je na stejnou sadu výsledků, abychom získali požadovaný výsledek. To zvyšuje výkon, protože nemusíme vyvolávat více dotazů do databáze, abychom získali upravený výsledek. Místo toho můžeme použít vícenásobné filtrování na výsledek dotazu spuštěný jednou do databáze. Aplikace má dvě důležité fáze:
- Vytváříme filtr, který stanoví kritéria pro filtrování dat. To se provádí implementací Predikátu rozhraní. Může existovat více konstruktorů přijímajících různé sady argumentů. Filtr může také obsahovat pole evaluate() metody také přijímající různé sady argumentů s vlastní odlišnou sadou implementace.
- FilteredRowSet třída musí být vytvořena, aby se dosáhlo požadovaného efektu, což jsme zde provedli pomocí applyFilter() metoda. FilteredRowSet používá vlastní třídu filtru, kterou jsme dodali, k určení záznamů, které mají být zobrazeny.
package org.mano.example;
import com.sun.rowset.FilteredRowSetImpl;
import javax.sql.RowSet;
import javax.sql.rowset.FilteredRowSet;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class DemoApp {
private static final String DB_URL =
"jdbc:mysql://localhost:3306/my_lib";
private static final String DB_DRIVER =
"com.mysql.cj.jdbc.Driver";
private static final String DB_USERNAME =
"root";
private static final String DB_PASSWORD =
"secret";
public static Connection conn = null;
public static FilteredRowSet filteredRowSet = null;
public static void main(String[] args) {
try {
Class.forName(DB_DRIVER);
conn = DriverManager.getConnection(DB_URL,
DB_USERNAME,DB_PASSWORD);
System.out.println("Database connection
successful.");
applyFilter();
} catch (SQLException | ClassNotFoundException ex) {
System.out.println(ex);
} finally {
if (conn != null) {
try {
conn.close();
catch (SQLException ex) {
ex.printStackTrace();
}
}
if (filteredRowSet != null) {
try {
filteredRowSet.close();
} catch (SQLException ex) {
ex.printStackTrace();
}
}
}
}
public static void applyFilter() {
String[] arr = {"Donne", "Milton"};
SimpleFilter aFilter = new SimpleFilter(arr, 3);
try {
filteredRowSet = new FilteredRowSetImpl();
filteredRowSet.setCommand("SELECT title, f_name, l_name "
+ "FROM book_author BA, "
+ "author A, "
+ "book B "
+ "WHERE A.auth_id = BA.fk_author "
+ "AND B.book_id = BA.fk_book");
filteredRowSet.execute(conn);
System.out.println
("--------------------------------------------");
System.out.println("Before applying any
filter:");
System.out.println
("--------------------------------------------");
show(filteredRowSet);
System.out.println
("--------------------------------------------");
System.out.println("After applying
filter :");
System.out.println
("--------------------------------------------");
filteredRowSet.beforeFirst();
filteredRowSet.setFilter(aFilter);
show(filteredRowSet);
} catch (SQLException e) {
e.printStackTrace();
}
}
public static void show(RowSet rs) {
try {
while (rs.next()) {
System.out.println(rs.getString(1) + " / "
+ rs.getString(2)
+ " "+rs.getString(3));
}
} catch (SQLException ex) {
ex.printStackTrace();
}
}
}
Výstup
Database connection successful. -------------------------------------------- Before applying any filter: -------------------------------------------- Gulliver's Travels / Jonathan Swift ... Ill Pensoroso / John Milton Areopagitica / John Milton -------------------------------------------- After applying filter: -------------------------------------------- The Flea / John Donne Holy Sonnet / John Donne Paradise Lost / John Milton Paradise Regained / John Milton Ill Pensoroso / John Milton Areopagitica / John Milton
Závěr
Práce s velkým počtem řádků vrácených z dotazu má mnoho problémů. Za prvé, načtená data zabírají paměť.
Vždy pomůže jejich omezení podle potřeby a relevance. S Sada řádků , můžeme je filtrovat podle kritéria bez dalších požadavků na databázi. To usnadňuje práci s databázovými řádky a využívá efektivitu kódu.