Některé z těchto chyb jste pravděpodobně udělali, když jste začínali svou kariéru v oblasti návrhu databáze. Možná je stále vyrábíte, nebo nějaké vytvoříte v budoucnu. Nemůžeme se vrátit v čase a pomoci vám napravit vaše chyby, ale můžeme vás ušetřit od některých budoucích (nebo současných) bolestí hlavy.
Přečtení tohoto článku vám může ušetřit mnoho hodin strávených opravováním problémů s návrhem a kódem, takže se pojďme ponořit do toho. Rozdělil jsem seznam chyb do dvou hlavních skupin:ty netechnické v přírodě a ty, které jsou přísně technické . Obě tyto skupiny jsou důležitou součástí návrhu databáze.
Je zřejmé, že pokud nemáte technické dovednosti, nebudete vědět, jak něco udělat. Není divu, že tyto chyby jsou na seznamu. Ale netechnické dovednosti? Lidé na ně mohou zapomenout, ale tyto dovednosti jsou také velmi důležitou součástí procesu navrhování. Přidávají hodnotu vašemu kódu a spojují technologii s reálným problémem, který potřebujete vyřešit.
Začněme tedy nejprve netechnickými problémy a poté přejdeme k technickým.
Netechnické chyby návrhu databáze
#1 Špatné plánování
Toto je rozhodně netechnický problém, ale je to hlavní a běžný problém. Všichni jsme nadšení, když začne nový projekt, a když se do něj pustíme, všechno vypadá skvěle. Na začátku je projekt stále prázdnou stránkou a vy a váš klient jste rádi, že můžete začít pracovat na něčem, co vytvoří lepší budoucnost pro vás oba. To vše je skvělé a konečným výsledkem bude pravděpodobně skvělá budoucnost. Ale i tak se musíme soustředit. Toto je část projektu, kde můžeme udělat zásadní chyby.
Než se posadíte ke kreslení datového modelu, musíte si být jisti, že:
- Zcela víte, co váš klient dělá (tj. jeho obchodní plány související s tímto projektem a také jeho celkový obraz) a čeho chtějí, aby tento projekt nyní i v budoucnu dosáhl.
- Rozumíte obchodnímu procesu a v případě potřeby jste připraveni navrhnout jeho zjednodušení a zlepšení (např. zvýšit efektivitu a příjem, snížit náklady a pracovní dobu atd.).
- Rozumíte datovému toku ve společnosti klienta. V ideálním případě byste znali každý detail:kdo s daty pracuje, kdo provádí změny, jaké přehledy jsou potřeba, kdy a proč se to všechno děje.
- Můžete použít jazyk/terminologii, kterou váš klient používá. I když vy můžete nebo nemusíte být odborníkem v jejich oblasti, váš klient rozhodně je. Požádejte je, aby vysvětlili, čemu nerozumíte. A když klientovi vysvětlujete technické podrobnosti, používejte jazyk a terminologii, které rozumí.
- Víte, které technologie budete používat, od databázového stroje a programovacích jazyků až po další nástroje. To, co se rozhodnete použít, úzce souvisí s problémem, který budete řešit, ale je důležité zahrnout preference klienta a jeho současnou IT infrastrukturu.
Během fáze plánování byste měli získat odpovědi na tyto otázky:
- Které tabulky budou hlavními tabulkami ve vašem modelu? Pravděpodobně jich budete mít několik, zatímco ostatní tabulky budou některé z obvyklých (např. user_account, role). Nezapomeňte na slovníky a vztahy mezi tabulkami.
- Jaké názvy budou použity pro tabulky v modelu? Nezapomeňte zachovat terminologii podobnou té, co klient aktuálně používá.
- Jaká pravidla budou platit při pojmenovávání tabulek a dalších objektů? (Viz bod 4 o konvencích pojmenování.)
- Jak dlouho bude celý projekt trvat? To je důležité jak pro váš plán, tak pro časovou osu klienta.
Teprve až budete mít všechny tyto odpovědi, jste připraveni sdílet počáteční řešení problému. Toto řešení nemusí být úplná aplikace – možná krátký dokument nebo dokonce pár vět v jazyce podnikání klienta.
Dobré plánování není specifické pro datové modelování; je použitelný téměř pro jakýkoli IT (i ne IT) projekt. Přeskakování je pouze možností, pokud 1) máte opravdu malý projekt; 2) úkoly a cíle jsou jasné a 3) opravdu spěcháte. Historickým příkladem jsou odpalovací inženýři Sputniku 1, kteří dávají slovní pokyny technikům, kteří jej montovali. Projekt byl ve spěchu kvůli zprávám, že USA plánují brzy vypustit svůj vlastní satelit – ale myslím, že nebudete tak spěchat.
#2 Nedostatečná komunikace s klienty a vývojáři
Když začnete s procesem návrhu databáze, pravděpodobně pochopíte většinu hlavních požadavků. Některé jsou velmi běžné bez ohledu na podnikání, např. uživatelské role a stavy. Na druhou stranu některé tabulky ve vašem modelu budou zcela specifické. Pokud například vytváříte model pro taxikářskou společnost, budete mít tabulky pro vozidla, řidiče, klienty atd.
Na začátku projektu však nebude vše zřejmé. Možná nepochopíte některé požadavky, klient může přidat nějaké nové funkce, uvidíte něco, co by se dalo udělat jinak, proces se může změnit atd. To vše způsobuje změny v modelu. Většina změn vyžaduje přidání nových tabulek, ale někdy budete tabulky odstraňovat nebo upravovat. Pokud jste již začali psát kód, který používá tyto tabulky, budete muset tento kód také přepsat.
Chcete-li zkrátit čas strávený neočekávanými změnami, měli byste:
- Promluvte si s vývojáři a klienty a nebojte se klást zásadní obchodní otázky. Když si myslíte, že jste připraveni začít, zeptejte se sami sebe Je situace X pokryta v naší databázi? Klient aktuálně dělá Y tímto způsobem; očekáváme v blízké budoucnosti změnu? Jakmile se ujistíme, že náš model je schopen uložit vše, co potřebujeme, správným způsobem, můžeme začít kódovat.
- Pokud čelíte zásadní změně ve svém návrhu a již máte napsáno mnoho kódu, neměli byste se pokoušet o rychlou opravu. Udělejte to tak, jak to mělo být, bez ohledu na aktuální situaci. Rychlá oprava by teď mohla ušetřit čas a nějakou dobu by pravděpodobně fungovala dobře, ale později se může změnit ve skutečnou noční můru.
- Pokud si myslíte, že je nyní něco v pořádku, ale později by to mohl být problém, neignorujte to. Analyzujte tuto oblast a implementujte změny, pokud zlepší kvalitu a výkon systému. Bude to stát nějaký čas, ale dodáte lepší produkt a mnohem lépe se vyspíte.
Pokud se pokusíte vyhnout změnám ve svém datovém modelu, když uvidíte potenciální problém – nebo pokud se rozhodnete pro rychlou opravu místo toho, abyste to udělali správně – dříve nebo později za to zaplatíte.
Zůstaňte také v kontaktu se svým klientem a vývojáři během celého projektu. Vždy zkontrolujte a zjistěte, zda byly od vaší poslední diskuse provedeny nějaké změny.
#3 Špatná nebo chybějící dokumentace
Pro většinu z nás je dokumentace až na konci projektu. Pokud jsme dobře organizovaní, pravděpodobně jsme si věci zdokumentovali a budeme muset vše zabalit. Ale upřímně, většinou to tak není. Psaní dokumentace probíhá těsně před uzavřením projektu – a těsně poté, co jsme mentálně hotovi s tímto datovým modelem!
Cena zaplacená za špatně zdokumentovaný projekt může být pěkně vysoká, několikanásobně vyšší než cena, kterou platíme, abychom vše řádně zdokumentovali. Představte si, že najdete chybu několik měsíců po uzavření projektu. Protože jste řádně nezdokumentovali, nevíte, kde začít.
Při práci nezapomeňte psát komentáře. Vysvětlete vše, co potřebuje další vysvětlení, a v zásadě si zapište vše, co si myslíte, že se jednou bude hodit. Nikdy nevíte, zda a kdy tyto dodatečné informace budete potřebovat.
Technické chyby v návrhu databáze
#4 Nepoužívání konvence pojmenování
Nikdy s jistotou nevíte, jak dlouho projekt potrvá a zda na datovém modelu bude pracovat více lidí. Existuje bod, kdy jste opravdu blízko datovému modelu, ale ještě jste ho nezačali kreslit. Tehdy je rozumné rozhodnout se, jak budete pojmenovávat objekty ve svém modelu, v databázi a v obecné aplikaci. Před modelováním byste měli vědět:
- Jsou názvy tabulek jednotné nebo množné?
- Budeme seskupovat tabulky pomocí jmen? (Např. všechny tabulky související s klientem obsahují „client_“, všechny tabulky související s úkoly obsahují „task_“ atd.)
- Budeme používat velká a malá písmena, nebo jen malá?
- Jaký název použijeme pro sloupce ID? (S největší pravděpodobností to bude „id“.)
- Jak budeme pojmenovávat cizí klíče? (S největší pravděpodobností „id_“ a název odkazované tabulky.)
Porovnejte část modelu, která nepoužívá konvence pojmenování, se stejnou částí, která používá konvence pojmenování, jak je znázorněno níže:
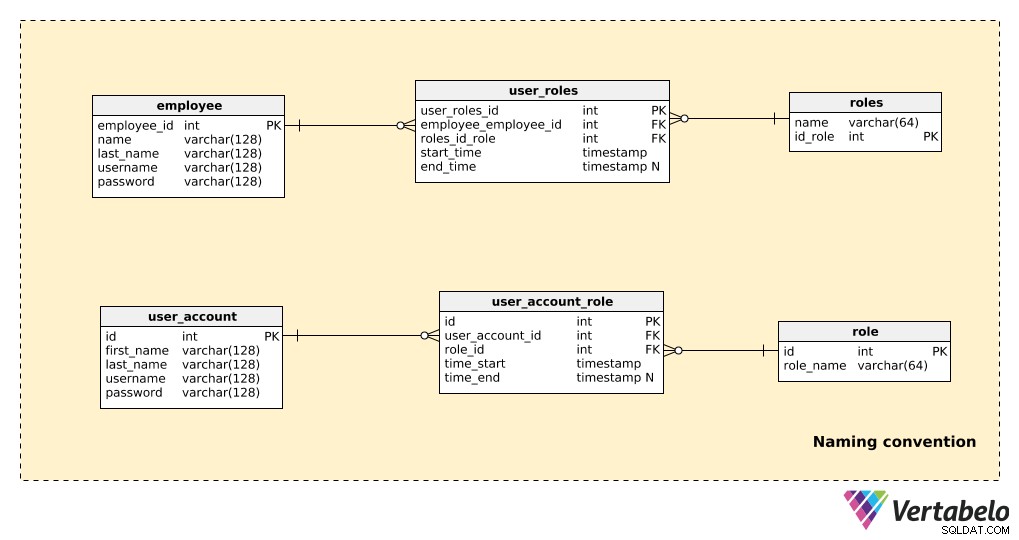
Je zde pouze několik tabulek, ale stále je docela zřejmé, který model je snáze čitelný. Všimněte si, že:
- Oba modely „fungují“, takže po technické stránce nejsou žádné problémy.
- V příkladu bez konvence pojmenování (horní tři tabulky) existuje několik věcí, které významně ovlivňují čitelnost:použití tvaru jednotného i množného čísla v názvech tabulek; nestandardizované názvy primárních klíčů (
employees_id,id_role); a atributy v různých tabulkách sdílejí stejný název (např. jméno se objevuje v obou „employee“ a „roles” tabulky).
Nyní si představte, jaký nepořádek bychom vytvořili, kdyby náš model obsahoval stovky tabulek. Možná bychom s takovým modelem mohli pracovat (kdybychom ho sami vytvořili), ale udělali bychom někomu velkou smůlu, kdyby na něm musel pracovat po nás.
Abyste předešli budoucím problémům s názvy, nepoužívejte v nich vyhrazená slova SQL, speciální znaky ani mezery.
Než tedy začnete vytvářet jakékoli názvy, vytvořte jednoduchý dokument (třeba jen několik stránek dlouhý), který popisuje konvenci pojmenování, kterou jste použili. To zvýší čitelnost celého modelu a zjednoduší budoucí práci.
Více o konvencích pojmenování si můžete přečíst v těchto dvou článcích:
- Konvence pojmenování v databázovém modelování
- Neemocionální logický pohled na konvence pojmenování SQL Server
#5 Problémy s normalizací
Normalizace je nezbytnou součástí návrhu databáze. Každá databáze by měla být normalizována alespoň na 3NF (primární klíče jsou definovány, sloupce jsou atomické a neexistují žádné opakující se skupiny, částečné závislosti nebo tranzitivní závislosti). To snižuje duplicitu dat a zajišťuje referenční integritu.
Více o normalizaci si můžete přečíst v tomto článku. Stručně řečeno, kdykoli mluvíme o modelu relační databáze, mluvíme o normalizované databázi. Pokud databáze není normalizovaná, narazíme na spoustu problémů souvisejících s integritou dat.
V některých případech můžeme chtít denormalizovat naši databázi. Pokud to uděláte, máte opravdu dobrý důvod. Více o denormalizaci databáze si můžete přečíst zde.
#6 Použití modelu Entity-Attribute-Value (EAV)
EAV je zkratka pro entity-attribute-value. Tuto strukturu lze použít k uložení dalších dat o čemkoli v našem modelu. Podívejme se na jeden příklad.
Předpokládejme, že chceme uložit nějaké další atributy zákazníka. „customer ” tabulka je naše entita, „attribute ” tabulka je samozřejmě náš atribut a “attribute_value ” obsahuje hodnotu tohoto atributu pro daného zákazníka.
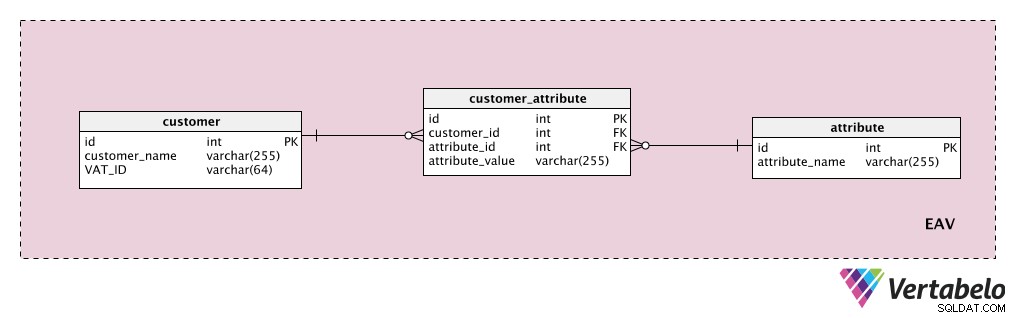
Nejprve přidáme slovník se seznamem všech možných vlastností, které bychom mohli zákazníkovi přiřadit. Toto je „attribute " stůl. Může obsahovat vlastnosti jako „hodnota zákazníka“, „kontaktní údaje“, „další informace“ atd. „customer_attribute ” obsahuje seznam všech atributů s hodnotami pro každého zákazníka. Pro každého zákazníka budeme mít záznamy pouze pro atributy, které má, a uložíme „attribute_value ” pro daný atribut.
To by se mohlo zdát opravdu skvělé. Umožnilo by nám to snadno přidávat nové vlastnosti (protože je přidáváme jako hodnoty v „customer_attribute " stůl). Vyhnuli bychom se tak provádění změn v databázi. Až příliš dobré, aby to byla pravda.
A je to příliš dobré. Model sice uchová data, která potřebujeme, ale práce s takovými daty je mnohem složitější. A to zahrnuje téměř vše, od psaní jednoduchých dotazů SELECT přes získávání všech hodnot souvisejících se zákazníky až po vkládání, aktualizaci nebo mazání hodnot.
Stručně řečeno, měli bychom se vyhnout struktuře EAV. Pokud ji musíte použít, použijte ji pouze tehdy, když jste si 100% jisti, že je skutečně potřeba.
#7 Použití GUID/UUID jako primárního klíče
GUID (Globally Unique Identifier) je 128bitové číslo generované podle pravidel definovaných v RFC 4122. Někdy jsou také známé jako UUID (Universally Unique Identifiers). Hlavní výhodou GUID je, že je jedinečný; šance, že dvakrát zasáhnete stejný GUID, je opravdu nepravděpodobná. Proto se GUID jeví jako skvělý kandidát na sloupec primárního klíče. Ale není tomu tak.
Obecným pravidlem pro primární klíče je, že používáme celočíselný sloupec s vlastností autoincrement nastavenou na „yes“. To přidá data v sekvenčním pořadí k primárnímu klíči a poskytne optimální výkon. Bez sekvenčního klíče nebo časového razítka neexistuje způsob, jak zjistit, která data byla vložena jako první. Tento problém také nastává, když používáme UNIKÁTNÍ skutečné hodnoty (např. DIČ). I když mají UNIKÁTNÍ hodnoty, nevytvářejí dobré primární klíče. Použijte je místo toho jako alternativní klíče.
Ještě jedna poznámka: Jako primární klíč dávám přednost použití automatických celočíselných atributů s jedním sloupcem. Je to rozhodně nejlepší praxe. Doporučuji vyhnout se používání složených primárních klíčů.
#8 Nedostatečná indexace
Indexy jsou velmi důležitou součástí práce s databázemi, ale jejich důkladná diskuse je mimo rozsah tohoto článku. Naštěstí již máme několik článků souvisejících s indexy, které si můžete přečíst a dozvědět se více:- Co je index databáze?
- Vše o indexech:Úplné základy
- Vše o indexech, část 2:Struktura a výkon indexu MySQL
Krátká verze je taková, že doporučuji přidat index všude tam, kde očekáváte, že to bude potřeba. Můžete je také přidat poté, co bude databáze ve výrobě, pokud zjistíte, že přidání indexu na určité místo zlepší výkon.
#9 Redundantní data
V žádném modelu by se obecně nemělo používat redundantní data. Nejenže zabírá další místo na disku, ale také výrazně zvyšuje pravděpodobnost problémů s integritou dat. Pokud musí být něco nadbytečné, měli bychom dbát na to, aby původní data a „kopie“ byly vždy v konzistentním stavu. Ve skutečnosti existují situace, kdy jsou redundantní data žádoucí:
- V některých případech musíme určité akci přiřadit prioritu – a abychom toho dosáhli, musíme provádět složité výpočty. Tyto výpočty by mohly používat mnoho tabulek a spotřebovávat mnoho zdrojů. V takových případech by bylo moudré provádět tyto výpočty v době volna (takže se vyhnete problémům s výkonem během pracovní doby). Pokud to uděláme tímto způsobem, mohli bychom uložit vypočítanou hodnotu a použít ji později, aniž bychom ji museli přepočítávat. Hodnota je samozřejmě nadbytečná; nicméně to, co získáme na výkonu, je podstatně více než to, co ztratíme (nějaké místo na pevném disku).
- Uvnitř databáze můžeme také uložit malou sadu dat přehledů. Na konci dne například uložíme počet hovorů, které jsme ten den uskutečnili, počet úspěšných prodejů atd. Údaje z přehledů by se měly tímto způsobem ukládat pouze v případě, že je potřebujeme často používat. Opět ztratíme trochu místa na pevném disku, ale vyhneme se přepočítávání dat nebo připojení k databázi přehledů (pokud ji máme).
Ve většině případů bychom neměli používat nadbytečná data, protože:
- Uložení stejných dat více než jednou v databázi může ovlivnit integritu dat. Pokud ukládáte jméno klienta na dvou různých místech, měli byste provést jakékoli změny (vložit/aktualizovat/smazat) na obou místech současně. To také komplikuje kód, který budete potřebovat, a to i pro ty nejjednodušší operace.
- I když bychom mohli uložit některá agregovaná čísla do naší provozní databáze, měli bychom to dělat pouze tehdy, když to skutečně potřebujeme. Provozní databáze není určena k ukládání dat sestav a míchání těchto dvou je obecně špatný postup. Každý, kdo vytváří zprávy, bude muset používat stejné zdroje jako uživatelé pracující na provozních úkolech; dotazy jsou obvykle složitější a mohou ovlivnit výkon. Proto byste měli oddělit svou provozní databázi a databázi výkazů.
Nyní je řada na vás
Doufám, že vám přečtení tohoto článku poskytlo nové poznatky a povzbudí vás, abyste se řídili osvědčenými postupy pro modelování dat. Ušetří vám čas!
Zažili jste některý z problémů uvedených v tomto článku? Myslíte si, že nám uniklo něco důležitého? Nebo si myslíte, že bychom měli něco z našeho seznamu odstranit? Řekněte nám to prosím v komentářích níže.