Pořádání dětských oslav není jednoduchá práce:vše musí být dokonale naplánováno a dodáno. Jinak nastává chaos. Je na dospělých – konkrétněji na organizátorech večírků –, aby se o všechno postarali a udělali to pořádně.
Existuje lepší způsob, jak to udělat, než organizovat vše v databázi? Nemyslíme si to!
Dětské oslavy se hodně liší. Některé jsou jednoduché, jako jsou narozeninové oslavy, které zahrnují pouze pozvánky, jídlo (svačiny, nápoje a dort) a možná klaun nebo kouzelník pro pobavení dětí. Jiné strany jsou mnohem složitější. Mohou vyžadovat výlet z města, přespání a mnoho dalších aktivit. Čím složitější večírek, tím menší prostor pro chyby. Zatímco klaun, který má 10 minut zpoždění, není nic moc, nikdo nechce čekat se skupinou znuděných dětí na autobus, který má dvě hodiny zpoždění!
Pojďme se podívat, co může datový model udělat, aby pomohl organizátorům večírků udržet si pořádek.
Co potřebujeme v našem datovém modelu?
Předpokládejme, že provozujeme firmu na plánování večírků. Budeme mít seznam služeb, které nabízíme zákazníkům. Tyto služby můžeme poskytovat my, nebo můžeme využít partnery (např. najmeme klauna).
Tyto služby kombinujeme a nabízíme zákazníkům jako party balíček. Každý balíček má počáteční a koncový bod nebo plán. To zahrnuje nejen samotný večírek, ale i uspořádání party a úklid po ní. Můžeme mít také několik míst (např. párty začíná pizzou v restauraci a poté se přesune na pláž za koupáním).
Budeme také muset spojit aktivity se zaměstnanci, sledovat pokrok stran a účtovat poplatky za naše služby. Podívejme se, jak se to dělá.
Datový model dětské párty
Náš datový model pro dětskou párty se skládá ze čtyř tematických oblastí:
Countries & citiesPartners & servicesEmployees & rolesParty
Každou tematickou oblast představíme ve stejném pořadí, v jakém jsou uvedeny.
Část 1:Země a města
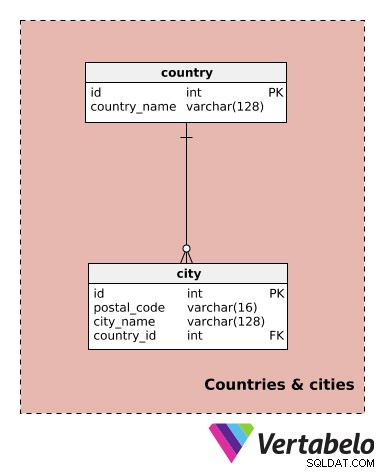
Tato oblast obsahuje pouze dvě tabulky. Nejsou specifické pro tento model, ale použijeme je v jiných předmětech.
Můžeme očekávat, že budeme působit ve více městech a možná i v několika zemích. Proto se budeme muset odkazovat na různá města. To nám pomůže sledovat, kde se strany nacházejí, a také jaké služby na jednotlivých místech nabízíme.
country slovník obsahuje pouze UNIKÁTNÍ country_name hodnota. Pro každé city , uložíme UNIKÁTNÍ kombinaci postal_code – city_name – country_id .
Část 2:Partneři a služby
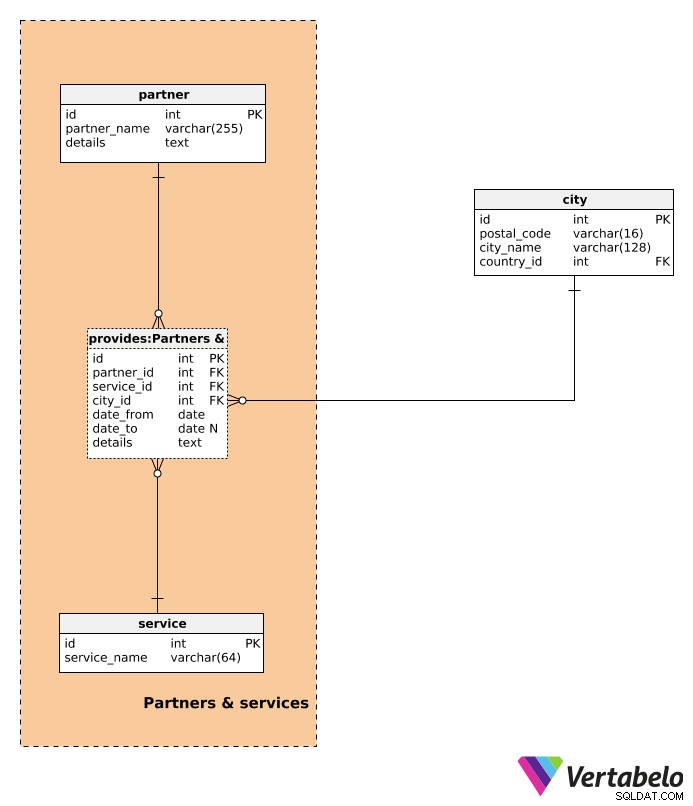
Dále si popíšeme služby, které našim klientům poskytneme.
Seznam všech možných služeb je uložen ve service slovník. Obsahuje pouze UNIKÁTNÍ service_name atribut.
V tomto datovém modelu jsou všechny služby poskytovány partnery. I když naše společnost službu skutečně poskytuje, budeme s ní zacházet jako s partner služby (a my jsme partnerem). Partnerský slovník bude ukládat všechny partnery, se kterými spolupracujeme, včetně nás. Pro každého partnera uložíme UNIKÁTNÍ partner_name . details atribut ukládá jakékoli další podrobnosti související s tímto partnerem pomocí nestrukturovaného nebo strukturovaného formátu (např. pomocí párů název-hodnota oddělených předdefinovaným oddělovačem).
provides tabulka je poslední a nejdůležitější tabulka v této sekci. Pro každý záznam uložíme:
partner_id–partnerkterá poskytuje službu.service_id–servicetento partner poskytuje.city_id– Odkazuje nacitykde tuto službu daný partner poskytuje.date_from– Datum, kdy partner začal tuto službu nabízet.date_to– Datum, kdy partner přestal nabízet tuto službu. Tato hodnota může být NULL, pokud tento vztah servisního partnera stále trvá.details– Všechny další podrobnosti související s touto službou, jako je popis služby, cena atd. Můžeme očekávat, že všechny podrobnosti budou ve strukturovaném textovém formátu s použitím párů klíč–hodnota.
Kombinace partner_id – service_id – city_id – datum_od tvoří UNIQUE klíč v této tabulce. Když zadáváme nový záznam, měli bychom zkontrolovat, zda se nepřekrývá s žádnými existujícími záznamy.
Část 3:Zaměstnanci a role
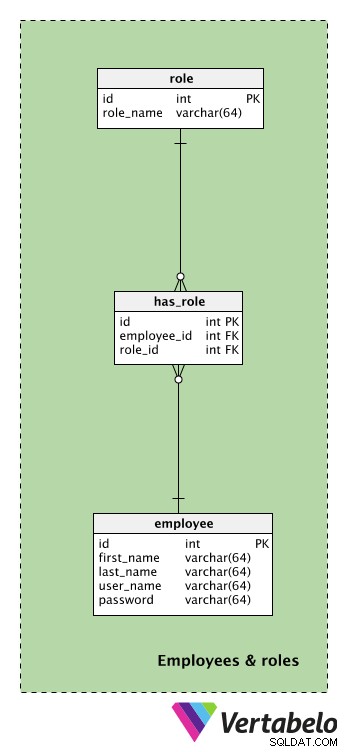
Než přejdeme k ústřední a nejdůležitější části našeho modelu, musíme se podívat na tabulky týkající se našich zaměstnanců a jejich rolí.
Centrální tabulka v této tematické oblasti je employee stůl. U každého zaměstnance uložíme jeho first_name , last_name , user_name a password . Tyto dva poslední atributy použijí pro přístup k naší aplikaci.
Seznam všech možných rolí je uložen v role slovník. Každá role je JEDNOZNAČNĚ definována svým role_name . Role souvisí s akcemi, které každý zaměstnanec provádí během večírku. Proto zde můžeme očekávat hodnoty jako „manažer strany“ nebo „asistent“.
Role lze zaměstnancům přidělit pomocí has_role stůl. employee_id – role_id pár bude označovat aktivní role každého zaměstnance v daném okamžiku.
Část 4:Večírek
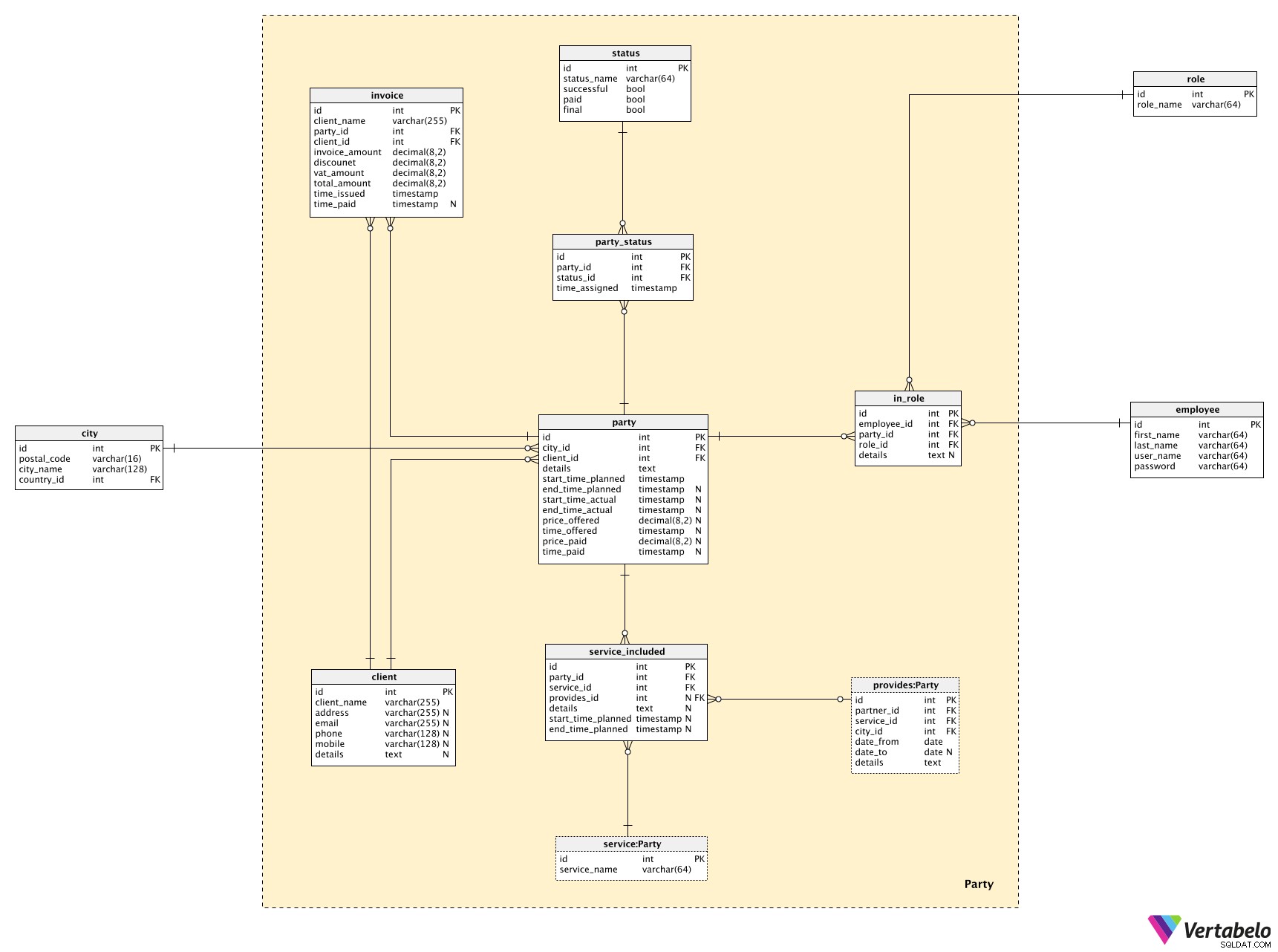
Party předmětová oblast je ústřední částí tohoto modelu. Použijeme ho ke spojení tabulek z jiných tematických oblastí a také zde budeme mít nějaké nové informace.
Ústředním stolem je zde party stůl. Pro každou párty uložíme:
city_id–citykde se bude večírek konat.client_id–clienttato párty je organizována pro.details– Podrobný textový popis večírku.start_time_plannedaend_time_planned– Čas, který jsme naplánovali na tuto párty, včetně nastavení a úklidu.start_time_actualaend_time_actual– Skutečné časy, kdy se večírek (a související služby) konal.price_offered– Cena, kterou jsme uvedli za uspořádání této párty pro tohoto klienta.time_offered– Kdy byla učiněna nabídka.price_paid– Skutečná částka, kterou klient zaplatil za tuto stranu.time_paid– Kdy byla platba provedena.
Každá strana je ve spojení s klientem. Již jsme odkazovali na client tabulky, ale teď uvidíme, co je tam uloženo. Vycházel jsem pouze se základními údaji:client_name , kontaktní údaje (address , email , phone , mobile ) a jakékoli další podrobnosti v textovém formátu.
Každá strana bude mít také seznam služeb s ní spojených. Tento seznam je uložen v service_included stůl. Pro každý záznam budeme potřebovat:
party_id– Odkazuje na souvisejícíparty.service_id– Odkazuje naservicesoučástí party.provides_id– Odkazuje naprovidertéto služby, jakož i služby samotné. Tento atribut může mít hodnotu NULL, protože jej aktualizujeme, když vybereme konkrétního poskytovatele.details– Jakékoli další textové podrobnosti související s touto službou v dané straně.start_time_plannedaend_time_planned– Plánované časy, kdy má být služba poskytována během večírku.
Budeme také muset sledovat pokrok každé strany. K tomu použijeme dvě tabulky.
status v tabulce budou uvedeny všechny možné stavy, které by mohly být straně přiřazeny. Pro každý záznam uložíme UNIKÁTNÍ status_name a tři příznaky:
successful– Šlo všechno dobře? Nebo se vyskytly problémy s našimi službami?paid– Byl večírek zaplacen?final– Je toto konečný stav této strany?
Službám budeme přidělovat stavy přidáním nových záznamů do party_status stůl. U každého záznamu uložíme odkazy na party a service tabulky a timestamp kdy byl tento stav přidělen.
Konečnou tabulkou v našem modelu je invoice stůl. Není to specifické pro tento model, ale potřebujeme základní strukturu pro ukládání faktur. U každé faktury zaznamenáme:
client_name– Jméno klienta v době vystavení faktury.party_id–partysouvisející s touto fakturou.client_id– IDclientfakturováno.invoice_amount,discount,vat_amount,total_amount– Finanční podrobnosti faktury.time_issued- Kdy byla tato faktura vystavena nebo přidána do databáze.time_paid– Kdy byla tato faktura zaplacena.
Co byste udělali s tímto datovým modelem?
Tento model je docela přímočarý, ale vidím několik způsobů, jak jej zlepšit. Jaké změny byste navrhoval? Je něco, co bychom mohli zorganizovat jinak? Možná budeme muset přidat nebo odebrat funkci. Řekněte nám to prosím v komentářích.