Existují dvě doplňkové dovednosti, které jsou velmi užitečné při ladění dotazů. Jedním z nich je schopnost číst a interpretovat prováděcí plány. Druhým je vědět trochu o tom, jak optimalizátor dotazů pracuje při překladu textu SQL do prováděcího plánu. Spojení těchto dvou věcí nám může pomoci odhalit chvíle, kdy nebyla použita očekávaná optimalizace, což má za následek plán realizace, který není tak efektivní, jak by mohl být. Nedostatek dokumentace přesně o tom, jaké optimalizace může SQL Server použít (a za jakých okolností) však znamená, že mnohé z toho závisí na zkušenostech.
Příklad
Ukázkový dotaz pro tento článek je založen na otázce, kterou před několika měsíci položil SQL Server MVP Fabiano Amorim na základě skutečného problému, na který narazil. Níže uvedené schéma a testovací dotaz je zjednodušením skutečné situace, ale zachovává všechny důležité funkce.
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Test 1 – 10 000 řádků, SQL Server 2005+
Na konkrétních tabulkových datech pro tyto testy opravdu nezáleží. Následující dotazy jednoduše načtou 10 000 řádků z číselné tabulky do každé ze tří testovacích tabulek:
INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 10000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1;
Po načtení dat je prováděcí plán vytvořený pro testovací dotaz:
SELECT MAX(c1) FROM dbo.V1;
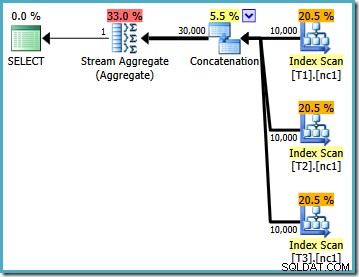
Tento plán provádění je docela přímou implementací logického dotazu SQL (po rozbalení odkazu na zobrazení V1). Optimalizátor vidí dotaz po rozšíření zobrazení, téměř jako by byl dotaz zapsán celý:
SELECT MAX(c1)
FROM
(
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3
) AS V1;
Při porovnání rozšířeného textu s plánem provádění je jasná přímost implementace optimalizátoru dotazů. Pro každé čtení základních tabulek existuje indexové skenování, operátor Concatenation pro implementaci UNION ALL a Agregát streamů pro konečný MAX agregát.
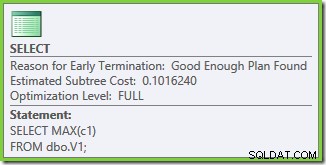
Vlastnosti prováděcího plánu ukazují, že byla zahájena nákladová optimalizace (úroveň optimalizace je FULL ), ale že byl předčasně ukončen, protože byl nalezen „dost dobrý“ plán. Odhadovaná cena vybraného plánu je 0,1016240 jednotky pro optimalizaci magie.
Test 2 – 50 000 řádků, SQL Server 2008 a 2008 R2
Spuštěním následujícího skriptu resetujte testovací prostředí na spuštění s 50 000 řádky:
TRUNCATE TABLE dbo.T1; TRUNCATE TABLE dbo.T2; TRUNCATE TABLE dbo.T3; INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 50000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1; SELECT MAX(c1) FROM dbo.V1;
Plán provádění tohoto testu závisí na verzi serveru SQL, který používáte. V SQL Server 2008 a 2008 R2 dostáváme následující plán:
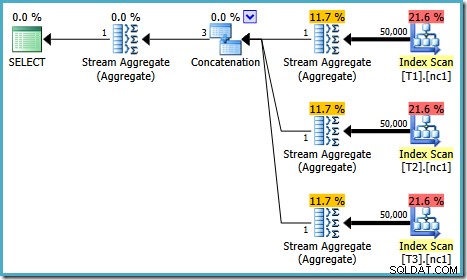
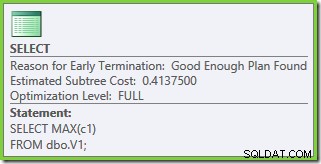
Vlastnosti plánu ukazují, že optimalizace založená na nákladech stále skončila předčasně ze stejného důvodu jako dříve. Odhadovaná cena je vyšší než dříve na 0,41375 jednotek, ale to se očekává kvůli vyšší mohutnosti základních tabulek.
Test 3 – 50 000 řádků, SQL Server 2005 a 2012
Stejný dotaz spuštěný v roce 2005 nebo 2012 vytvoří jiný plán provádění:
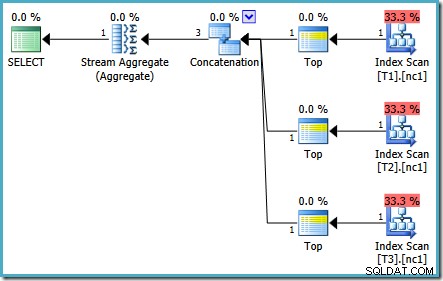
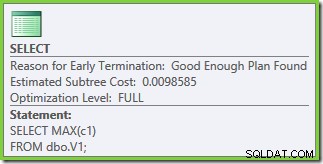
Optimalizace skončila znovu předčasně, ale odhadované náklady plánu na 50 000 řádků na základní tabulku jsou 0,0098585 (od 0,41375 na SQL Server 2008 a 2008 R2).
Vysvětlení
Jak možná víte, optimalizátor dotazů SQL Server rozděluje optimalizační úsilí do několika fází, přičemž pozdější fáze přidávají další optimalizační techniky a poskytují více času. Fáze optimalizace jsou:
- triviální plán
- Nákladově orientovaná optimalizace
- Zpracování transakce (hledání 0)
- Rychlý plán (hledání 1)
- Rychlý plán s povoleným paralelismem
- Plná optimalizace (hledání 2)
Žádný ze zde provedených testů nesplňuje podmínky pro triviální plán, protože agregace a svazy mají více možností implementace, což vyžaduje rozhodnutí na základě nákladů.
Zpracování transakce
Fáze zpracování transakcí (TP) vyžaduje, aby dotaz obsahoval alespoň tři odkazy na tabulky, jinak optimalizace založená na nákladech tuto fázi přeskočí a přejde rovnou k rychlému plánu. Fáze TP je zaměřena na nízkonákladové navigační dotazy typické pro pracovní zátěže OLTP. Zkouší omezený počet optimalizačních technik a omezuje se na hledání plánů pomocí spojení Nested Loop Joins (pokud není k vygenerování platného plánu nutné spojení hash).
V některých ohledech je překvapivé, že se testovací dotaz kvalifikuje do fáze zaměřené na nalezení plánů OLTP. Přestože dotaz obsahuje požadované tři odkazy na tabulky, neobsahuje žádné spojení. Požadavek na tři tabulky je pouze heuristika, takže se tím nebudu zabývat.
Které fáze Optimalizátoru byly spuštěny?
Existuje řada metod, zdokumentovaná je pro porovnání obsahu sys.dm_exec_query_optimizer_info před a po kompilaci. To je v pořádku, ale zaznamenává informace o celé instanci, takže si musíte dávat pozor, aby vaše kompilace byla jedinou kompilací dotazu, ke které dochází mezi snímky.
Nezdokumentovanou (ale přiměřeně známou) alternativou, která funguje na všech aktuálně podporovaných verzích SQL Server, je povolit příznaky trasování 8675 a 3604 při kompilaci dotazu.
Test 1
Tento test vytváří výstup příznaku trasování 8675 podobný následujícímu:

Odhadovaná cena 0,101624 po fázi TP je dostatečně nízká, aby optimalizátor nehledal levnější plány. Jednoduchý plán, se kterým jsme skončili, je docela rozumný vzhledem k relativně nízké mohutnosti základních tabulek, i když není skutečně optimální.
Test 2
S 50 000 řádky v každé základní tabulce odhaluje příznak trasování různé informace:

Tentokrát jsou odhadované náklady po fázi TP 0,428735 (více řádků =vyšší cena). To stačí k povzbuzení optimalizátoru do fáze rychlého plánu. S více dostupnými optimalizačními technikami tato fáze najde plán s cenou 0,41375 . Nepředstavuje to velké zlepšení oproti plánu testu 1, ale je to nižší než výchozí prahová hodnota nákladů pro paralelismus a nestačí to na vstup do úplné optimalizace, takže optimalizace opět končí brzy.
Test 3
Pro spuštění SQL Server 2005 a 2012 je výstup příznaku trasování:

Mezi verzemi existují drobné rozdíly v počtu spuštěných úloh, ale důležitým rozdílem je, že na SQL Server 2005 a 2012 je ve fázi Rychlý plán plán, který stojí pouze 0,0098543 Jednotky. Toto je plán, který obsahuje Top operátory namísto tří Stream Aggregates pod operátorem Concatenation, který je vidět v plánech SQL Server 2008 a 2008 R2.
Chyby a nezdokumentované opravy
SQL Server 2008 a 2008 R2 obsahují chybu regrese (ve srovnání s rokem 2005), která byla opravena pod příznakem trasování 4199, ale pokud vím, není zdokumentována. Existuje dokumentace pro TF 4199, která uvádí opravy dostupné pod samostatnými příznaky trasování, než budou pokryty 4199, ale jak říká článek znalostní báze:
Tento jeden příznak trasování lze použít k povolení všech oprav, které byly dříve provedeny pro procesor dotazů pod mnoha příznaky trasování. Všechny budoucí opravy procesoru dotazů budou navíc řízeny pomocí tohoto příznaku trasování.
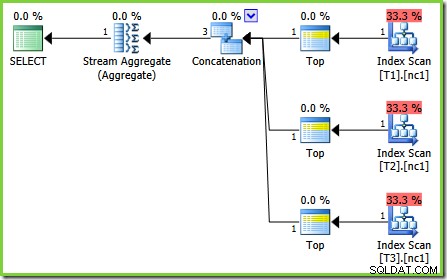
Chyba je v tomto případě jednou z těch „budoucích oprav procesoru dotazů“. Konkrétní pravidlo optimalizace, ScalarGbAggToTop , se neaplikuje na nové agregáty uvedené v plánu testu 2. S povoleným příznakem trasování 4199 na vhodných sestaveních SQL Server 2008 a 2008 R2 je chyba opravena a je získán optimální plán z testu 3:
-- Trace flag 4199 required for 2008 and 2008 R2 SELECT MAX(c1) FROM dbo.V1 OPTION (QUERYTRACEON 4199);
Závěr
Jakmile víte, že optimalizátor dokáže transformovat skalární MIN nebo MAX agregovat do TOP (1) na uspořádaném proudu se plán zobrazený v testu 2 zdá podivný. Skalární agregáty nad indexovým skenem (který může poskytnout řád, pokud je o to požádán) vyčnívají jako zmeškaná optimalizace, která by se normálně použila.
To je bod, o kterém jsem hovořil v úvodu:jakmile se seznámíte s druhy věcí, které optimalizátor dokáže, může vám pomoci rozpoznat případy, kdy se něco pokazilo.
Odpověď nebude vždy povolit příznak trasování 4199, protože můžete narazit na problémy, které ještě nebyly opraveny. Možná také nebudete chtít, aby se v konkrétním případě uplatňovaly ostatní opravy QP, na které se vztahuje příznak trasování – opravy optimalizátoru ne vždy věci vylepší. Pokud by to udělali, nebylo by potřeba chránit se před nešťastnými regresemi plánu pomocí tohoto příznaku.
Řešením v jiných případech může být formulování dotazu SQL pomocí jiné syntaxe, rozdělení dotazu na části, které jsou pro optimalizaci přívětivější, nebo něco úplně jiného. Ať už je odpověď jakákoliv, stále se vyplatí vědět něco o vnitřních částech optimalizátoru, abyste poznali, že v první řadě došlo k problému :)