Prováděcí plány poskytují bohatý zdroj informací, které nám mohou pomoci identifikovat způsoby, jak zlepšit výkon důležitých dotazů. Lidé často hledají věci, jako jsou velké skenování a vyhledávání, jako způsob, jak identifikovat potenciální optimalizace cesty přístupu k datům. Tyto problémy lze často rychle vyřešit vytvořením nového indexu nebo rozšířením stávajícího o více zahrnutých sloupců.
Můžeme také použít plány po provedení k porovnání skutečného a očekávaného počtu řádků mezi operátory plánu. Tam, kde se zjistí, že se významně liší, můžeme se pokusit poskytnout optimalizátoru lepší statistické informace aktualizací stávajících statistik, vytvořením nových statistických objektů, využitím statistik na vypočítaných sloupcích nebo možná rozdělením složitého dotazu na méně složitou komponentu. části.
Kromě toho se můžeme také podívat na drahé operace v plánu, zejména ty náročné na paměť, jako je třídění a hašování. Řazení se někdy lze vyhnout pomocí změn indexování. Jindy možná budeme muset upravit dotaz pomocí syntaxe, která upřednostňuje plán, který zachovává konkrétní požadované uspořádání.
Někdy nebude výkon stále dost dobrý ani po použití všech těchto technik ladění výkonu. Dalším možným krokem je trochu více přemýšlet o plánu jako celku . To znamená udělat krok zpět, pokusit se porozumět celkové strategii zvolené optimalizátorem dotazů, abychom zjistili, zda dokážeme identifikovat vylepšení algoritmu.
Tento článek zkoumá tento druhý typ analýzy pomocí jednoduchého příkladu problému hledání jedinečných hodnot sloupců ve středně velké sadě dat. Jak je to často v analogických problémech v reálném světě, sloupec zájmu bude mít relativně málo jedinečných hodnot ve srovnání s počtem řádků v tabulce. Tato analýza se skládá ze dvou částí:vytvoření ukázkových dat a napsání samotného dotazu na odlišné hodnoty.
Vytvoření ukázkových dat
Abychom uvedli nejjednodušší možný příklad, naše testovací tabulka má pouze jeden sloupec se seskupeným indexem (tento sloupec bude obsahovat duplicitní hodnoty, takže index nemůže být deklarován jako jedinečný):
CREATE TABLE dbo.Test
(
data integer NOT NULL,
);
GO
CREATE CLUSTERED INDEX cx
ON dbo.Test (data);
Abychom vybrali některá čísla ze vzduchu, zvolíme načtení deset milionů řádků celkem s rovnoměrným rozložením na tisíc různých hodnot . Běžnou technikou generování dat jako je tato je křížové spojení některých systémových tabulek a použití ROW_NUMBER funkce. Operátor modulo také použijeme k omezení generovaných čísel na požadované odlišné hodnoty:
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
(ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000) + 1
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED); Odhadovaný plán provádění tohoto dotazu je následující (kliknutím na obrázek jej v případě potřeby zvětšíte):

To trvá přibližně 30 sekund vytvořit ukázková data na mém notebooku. To v žádném případě není enormně dlouhá doba, ale přesto je zajímavé zvážit, co bychom mohli udělat, abychom tento proces zefektivnili…
Analýza plánu
Začneme tím, že pochopíme, k čemu jsou jednotlivé operace v plánu určeny.
Část prováděcího plánu napravo od operátora segmentu se týká výrobních řádků systémových tabulek křížového spojování:

Operátor Segment je k dispozici v případě, že funkce okna měla PARTITION BY doložka. V tomto případě tomu tak není, ale i tak je součástí plánu dotazů. Operátor sekvenčního projektu generuje čísla řádků a horní omezuje výstup plánu na deset milionů řádků:

Compute Scalar definuje výraz, který aplikuje funkci modulo, a přidá jeden k výsledku:

Jak spolu souvisí popisky výrazů Sekvenční projekt a Výpočet skalárního výrazu, můžeme vidět na kartě Výrazy v Průzkumníkovi plánu:

To nám dává ucelenější představu o průběhu tohoto plánu:Sequence Project čísluje řádky a označí výraz Expr1050; Compute Scalar označí výsledek výpočtu modulo a plus-one jako Expr1052 . Všimněte si také implicitní konverze ve výrazu Compute Scalar. Sloupec cílové tabulky je typu integer, zatímco ROW_NUMBER funkce vytváří bigint, takže je nutný zužující převod.
Dalším operátorem v plánu je řazení. Podle odhadů nákladů optimalizátoru dotazů se očekává, že to bude nejdražší operace (88,1 % odhad ):

Nemusí být hned zřejmé, proč tento plán obsahuje řazení, protože v dotazu není žádný explicitní požadavek na řazení. Třídění je přidáno do plánu, aby se zajistilo, že řádky dorazí k operátoru vložení seskupeného indexu v pořadí seskupeného indexu. To podporuje sekvenční zápisy, zabraňuje dělení stránek a je jedním z předpokladů pro minimálně protokolované INSERT operace.
To vše jsou potenciálně dobré věci, ale samotné řazení je poměrně drahé. Kontrola plánu provádění po spuštění ("skutečného") skutečně odhalí, že třídění také došla paměť v době provádění a muselo se přenést do fyzického tempdb disk:

K rozlití řazení dochází navzdory tomu, že odhadovaný počet řádků je přesně správný, a navzdory skutečnosti, že dotazu byla přidělena všechna paměť, o kterou požádal (jak je vidět ve vlastnostech plánu pro kořenový adresář INSERT uzel):

Úniky při třídění jsou také indikovány přítomností IO_COMPLETION čeká na kartě statistiky čekání Plan Explorer PRO:

Nakonec pro tuto sekci analýzy plánu si všimněte DML Request Sort vlastnost operátoru vložení seskupeného indexu je nastavena jako true:

Tento příznak označuje, že optimalizátor vyžaduje, aby podstrom pod vložkou poskytoval řádky v pořadí seřazených podle indexového klíče (proto je potřeba problematického operátora řazení).
Vyhnout se řazení
Nyní, když víme proč Objeví se Sort, můžeme vyzkoušet, co se stane, když jej odstraníme. Existují způsoby, jak můžeme přepsat dotaz tak, abychom optimalizátor „oklamali“, aby si myslel, že by bylo vloženo méně řádků (takže by se řazení nevyplatilo), ale rychlým způsobem, jak se vyhnout přímému řazení (pouze pro experimentální účely), je použít nezdokumentovaný příznak trasování 8795. Toto nastaví DML Request Sort vlastnost na hodnotu false, takže řádky již nemusí docházet k vložení seskupeného indexu v pořadí seskupených klíčů:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
OPTION (QUERYTRACEON 8795); Nový plán dotazů po provedení je následující (kliknutím na obrázek jej zvětšíte):

Operátor řazení zmizel, ale nový dotaz běží déle než 50 sekund (ve srovnání s 30 sekundami před). Existuje pro to několik důvodů. Za prvé, ztrácíme jakoukoli možnost minimálně protokolovaných vložek, protože ty vyžadují tříděná data (DML Request Sort =true). Za druhé, během vkládání dojde k velkému počtu "špatných" rozdělení stránek. V případě, že se to zdá neintuitivní, pamatujte, že ačkoli ROW_NUMBER funkce čísel řádky sekvenčně, efektem operátoru modulo je prezentovat opakující se sekvenci čísel 1…1000 do seskupeného rejstříku.
Ke stejnému zásadnímu problému dochází, pokud místo použití nepodporovaného příznaku trasování použijeme triky T-SQL ke snížení očekávaného počtu řádků, abychom se vyhnuli řazení.
Vyhýbání se třídění II
Když se podíváme na plán jako celek, zdá se jasné, že bychom chtěli generovat řádky způsobem, který se vyhýbá explicitnímu řazení, ale který stále těží z výhod minimálního protokolování a vyhýbání se špatnému rozdělení stránek. Jednoduše řečeno:chceme plán, který prezentuje řádky v seskupeném pořadí klíčů, ale bez řazení.
Vyzbrojeni tímto novým náhledem můžeme svůj dotaz vyjádřit jiným způsobem. Následující dotaz generuje každé číslo od 1 do 1000 a křížová spojení, která jsou nastavena na 10 000 řádků, aby se vytvořil požadovaný stupeň duplikace. Cílem je vygenerovat sadu vložek, která obsahuje 10 000 řádků očíslovaných „1“ a poté 10 000 očíslovaných „2“ … a tak dále.
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C; Bohužel optimalizátor stále vytváří plán s řazením:

Tady na obranu optimalizátoru není moc co říct, tohle je jen hloupý plán. Rozhodla se vygenerovat 10 000 řádků a poté křížově spojit ty s čísly od 1 do 1000. To neumožňuje zachovat přirozené pořadí čísel, takže se řazení nelze vyhnout.
Vyhnout se řazení – konečně!
Strategie, kterou optimalizátor minul, je vzít nejprve čísla 1…1000 a křížově spojte každé číslo s 10 000 řádky (vytvoříte 10 000 kopií každého čísla v sekvenci). Očekávaný plán by se vyhnul řazení pomocí křížového spojení vnořených smyček, které zachová pořadí řádků na vnějším vstupu.
Tohoto výsledku můžeme dosáhnout tak, že pomocí příkazu FORCE ORDER přinutíme optimalizátor přistupovat k odvozeným tabulkám v pořadí uvedeném v dotazu. nápověda k dotazu:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C
OPTION (FORCE ORDER); Konečně dostáváme plán, o který jsme šli:
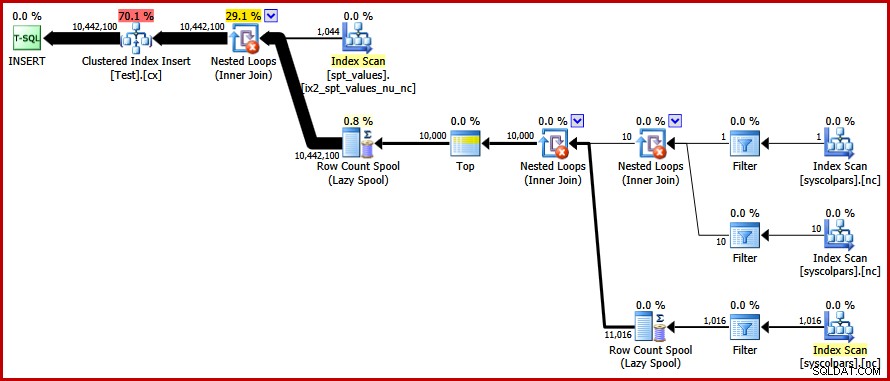
Tento plán se vyhýbá explicitnímu řazení a zároveň zabraňuje "špatnému" rozdělení stránek a umožňuje minimálně protokolované vkládání do seskupeného indexu (za předpokladu, že databáze nepoužívá FULL model obnovy). Načte všech deset milionů řádků přibližně za 9 sekund na mém notebooku (s jediným rotujícím diskem SATA 7200 ot./min.). To představuje výrazné zvýšení účinnosti během 30–50 sekund uplynulý čas před přepsáním.
Nalezení odlišných hodnot
Nyní máme vytvořená ukázková data, můžeme obrátit svou pozornost k psaní dotazu, abychom našli odlišné hodnoty v tabulce. Přirozený způsob vyjádření tohoto požadavku v T-SQL je následující:
SELECT DISTINCT data FROM dbo.Test WITH (TABLOCK) OPTION (MAXDOP 1);
Prováděcí plán je velmi jednoduchý, jak byste očekávali:

To trvá přibližně 2900 ms ke spuštění na mém počítači a vyžaduje 43 406 logické čtení:

Odebrání MAXDOP (1) dotaz nápověda vygeneruje paralelní plán:

To se dokončí přibližně za 1500 ms (ale s 8 764 ms spotřebovaného času CPU) a 43 804 logické čtení:

Pokud použijeme GROUP BY, výsledkem budou stejné plány a výkon místo DISTINCT .
Lepší algoritmus
Výše uvedené plány dotazů čtou všechny hodnoty ze základní tabulky a zpracovávají je prostřednictvím agregátu streamů. Když uvážíme úkol jako celek, zdá se neefektivní skenovat všech 10 milionů řádků, když víme, že existuje relativně málo různých hodnot.
Lepší strategií může být najít jedinou nejnižší hodnotu v tabulce, pak najít další nejvyšší a tak dále, dokud nám nedojdou hodnoty. Rozhodující je, že tento přístup se hodí spíše k vyhledávání jednotlivých položek v indexu než k prohledávání každého řádku.
Tuto myšlenku můžeme implementovat v jediném dotazu pomocí rekurzivního CTE, kde kotevní část najde nejnižší odlišnou hodnotu, pak rekurzivní část najde další odlišnou hodnotu a tak dále. První pokus o napsání tohoto dotazu je:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT data = MIN(T.data)
FROM dbo.Test AS T
UNION ALL
-- Recursive
SELECT MIN(T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
)
SELECT data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Bohužel se tato syntaxe nezkompiluje:

Dobře, takže agregační funkce nejsou povoleny. Místo použití MIN , můžeme napsat stejnou logiku pomocí TOP (1) s ORDER BY :
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
T.data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT TOP (1)
T.data
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
ORDER BY T.data
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0);

Stále žádná radost.
Ukázalo se, že tato omezení můžeme obejít přepsáním rekurzivní části tak, aby byly kandidátské řádky očíslovány v požadovaném pořadí, a poté filtrem pro řádek, který je očíslován „jedna“. Může se to zdát trochu zdlouhavé, ale logika je úplně stejná:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT R.data
FROM
(
-- Number the rows
SELECT
T.data,
rn = ROW_NUMBER() OVER (
ORDER BY T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
) AS R
WHERE
-- Only the row that sorts lowest
R.rn = 1
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Tento dotaz ano zkompilovat a vytvoří následující plán po spuštění:

Všimněte si operátoru Top v rekurzivní části plánu provádění (zvýrazněno). Nemůžeme napsat T-SQL TOP v rekurzivní části rekurzivního společného tabulkového výrazu, ale to neznamená, že optimalizátor nemůže jeden použít! Optimalizátor zavádí Top na základě úvahy o počtu řádků, které bude muset zkontrolovat, aby našel ten s číslem '1'.
Výkon tohoto (neparalelního) plánu je mnohem lepší než u přístupu Stream Aggregate. Dokončí se přibližně za 50 ms , s 3007 logická čtení proti zdrojové tabulce (a 6001 řádků načtených z pracovní tabulky řazení) ve srovnání s předchozí nejlepší hodnotou 1500 ms (8764 ms CPU čas při DOP 8) a 43 804 logické čtení:


Závěr
Zvažováním jednotlivých prvků plánu dotazů samostatně není vždy možné dosáhnout průlomu ve výkonu dotazů. Někdy potřebujeme analyzovat strategii celého prováděcího plánu a poté přemýšlet laterálně, abychom našli efektivnější algoritmus a implementaci.