Modul pro provádění dotazů SQL Server má dva způsoby, jak implementovat logickou operaci „sjednocení všech“ pomocí fyzických operátorů Concatenation a Merge Join Concatenation. I když je logická operace stejná, mezi dvěma fyzickými operátory jsou důležité rozdíly, které mohou mít obrovský rozdíl v účinnosti vašich plánů provádění.
Optimalizátor dotazů dělá v mnoha případech rozumnou práci při výběru mezi těmito dvěma možnostmi, ale v této oblasti má k dokonalosti daleko. Tento článek popisuje možnosti ladění dotazů, které nabízí Merge Join Concatenation, a podrobně popisuje interní chování a úvahy, o kterých musíte vědět, abyste z toho měli co nejvíce.
Zřetězení

Operátor Concatenation je relativně jednoduchý:jeho výstup je výsledkem úplného čtení z každého z jeho vstupů v sekvenci. Operátor Concatenation je n-ární fyzický operátor, což znamená, že může mít vstupy '2…n'. Pro ilustraci se vraťme k příkladu založenému na AdventureWorks z mého předchozího článku „Přepisování dotazů pro zlepšení výkonu“:
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
Následující dotaz uvádí ID produktů a transakcí pro šest konkrétních produktů:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711;
Vytváří prováděcí plán s operátorem Concatenation se šesti vstupy, jak je vidět v SQL Sentry Plan Explorer:
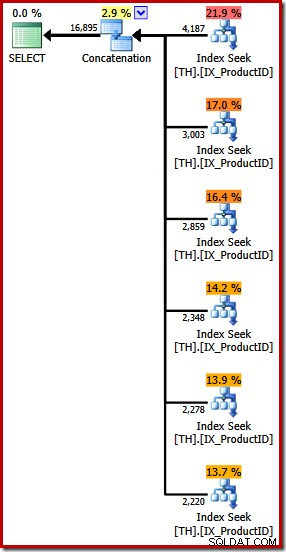
Výše uvedený plán obsahuje samostatné hledání indexu pro každé uvedené ID produktu ve stejném pořadí, jako je uvedeno v dotazu (čteno shora dolů). Nejvyšší hledání indexu je pro produkt 870, další níže je pro produkt 873, pak 921 a tak dále. Nic z toho samozřejmě není zaručené chování, je to jen něco zajímavého k pozorování.
Již jsem zmínil, že operátor Concatenation tvoří svůj výstup postupným čtením ze svých vstupů. Když je tento plán proveden, existuje velká šance, že sada výsledků zobrazí nejprve řádky pro produkt 870, poté 873, 921, 712, 707 a nakonec produkt 711. Opět to není zaručeno, protože jsme nezadali OBJEDNÁVKU BY, ale ukazuje, jak interně funguje Concatenation.
Prováděcí plán SSIS
Z důvodů, které budou za chvíli dávat smysl, zvažte, jak bychom mohli navrhnout balíček SSIS pro provedení stejného úkolu. Určitě bychom také mohli celou věc napsat jako jeden T-SQL příkaz v SSIS, ale zajímavější možností je vytvořit samostatný zdroj dat pro každý produkt a použít komponentu SSIS "Union All" místo SQL Server Concatenation. operátor:
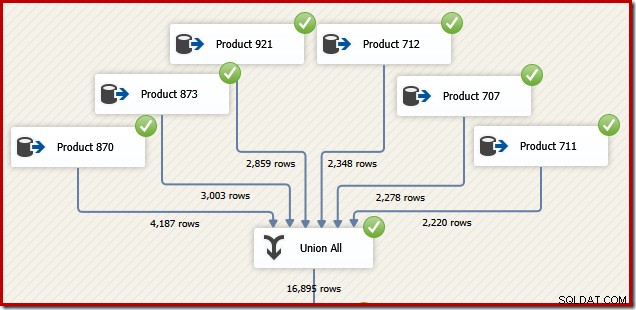
Nyní si představte, že potřebujeme konečný výstup z tohoto datového toku v pořadí Transaction ID. Jednou z možností by bylo přidat explicitní komponentu Sort za Sjednotit vše:
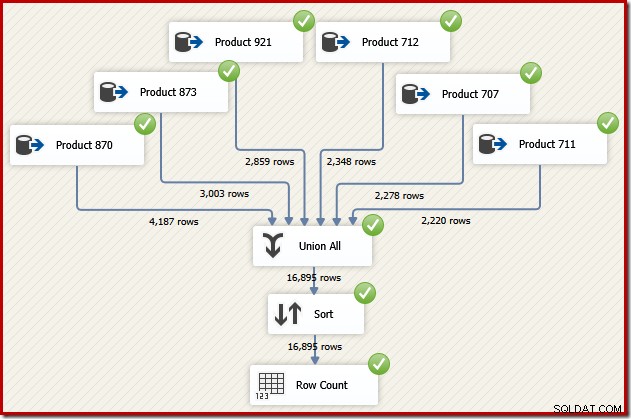
To by jistě fungovalo, ale zkušený a zkušený návrhář SSIS by si uvědomil, že existuje lepší možnost:číst zdrojová data pro každý produkt v pořadí ID transakce (s využitím indexu), poté použít operaci pro zachování objednávky ke zkombinování sad. .
V SSIS se komponenta, která kombinuje řádky ze dvou seřazených datových toků do jediného setříděného datového toku, nazývá „Sloučit“. Následuje přepracovaný tok dat SSIS, který používá sloučení k vrácení požadovaných řádků v pořadí ID transakce:
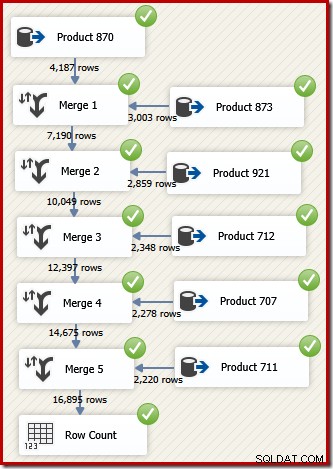
Všimněte si, že potřebujeme pět samostatných komponent Merge, protože Merge je binární komponenta, na rozdíl od komponenty SSIS "Union All", která byla n-ary . Nový tok sloučení vytváří výsledky v pořadí ID transakce, aniž by vyžadoval nákladnou (a blokující) komponentu řazení. Pokud se po konečném sloučení pokusíme přidat Sort on Transaction ID, SSIS zobrazí varování, abychom věděli, že stream je již seřazen požadovaným způsobem:
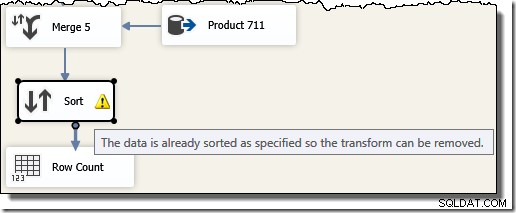
Pointa příkladu SSIS může být nyní odhalena. Podívejte se na plán provádění zvolený optimalizátorem dotazů SQL Server, když jej požádáme, aby vrátil původní výsledky dotazu T-SQL v pořadí ID transakce (přidáním klauzule ORDER BY):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
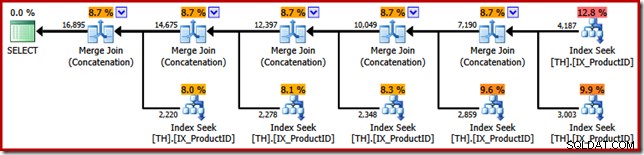
Podobnosti s balíčkem SSIS Merge jsou nápadné; dokonce až na potřebu pěti binárních operátorů "Merge". Jediným důležitým rozdílem je, že SSIS má samostatné komponenty pro „Merge Join“ a „Merge“, zatímco SQL Server používá pro obě stejný operátor jádra.
Aby bylo jasno, operátory Merge Join (Concatenation) v plánu provádění SQL Server nejsou provedení spojení; motor pouze znovu používá stejného fyzického operátora k implementaci sjednocení pro zachování pořádku.
Psaní plánů provádění na serveru SQL Server
SSIS nemá jazyk specifikace toku dat ani optimalizátor, který by takovou specifikaci proměnil ve spustitelnou úlohu toku dat. Je na návrháři balíčků SSIS, aby si uvědomil, že je možné sloučení zachovávající pořadí, vhodně nastavil vlastnosti komponent (jako jsou klíče řazení) a poté porovnal výkon. To vyžaduje více úsilí (a dovedností) ze strany návrháře, ale poskytuje to velmi jemný stupeň kontroly.
Situace v SQL Serveru je opačná:napíšeme dotaz specifikace pomocí jazyka T-SQL, pak se spolehněte na optimalizátor dotazů, který prozkoumá možnosti implementace a vybere efektivní. Nemáme možnost přímo sestavit prováděcí plán. Většinou je to velmi žádoucí:SQL Server by byl bezpochyby méně populární, kdyby každý dotaz vyžadoval, abychom napsali balíček ve stylu SSIS.
Nicméně (jak je vysvětleno v mém předchozím příspěvku), plán zvolený optimalizátorem může být citlivý na T-SQL použitý k popisu požadovaných výsledků. Opakováním příkladu z tohoto článku bychom mohli napsat původní dotaz T-SQL pomocí alternativní syntaxe:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Tento dotaz specifikuje přesně stejnou sadu výsledků jako dříve, ale optimalizátor nezohledňuje plán zachování pořadí (sloučení zřetězení) a místo toho zvolí skenování Clustered Index (mnohem méně efektivní možnost):
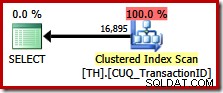
Využití zachování objednávky na serveru SQL Server
Vyhnutí se zbytečnému třídění může vést k výraznému zvýšení efektivity, ať už mluvíme o SSIS nebo SQL Server. Dosažení tohoto cíle může být na SQL Serveru složitější a obtížnější, protože nemáme tak podrobnou kontrolu nad plánem provádění, ale stále existují věci, které můžeme udělat.
Konkrétně pochopení toho, jak interně funguje operátor SQL Server Merge Join Concatenation, nám může pomoci pokračovat v psaní jasného relačního T-SQL a zároveň povzbudit optimalizátora dotazů, aby zvážil možnosti zpracování pro zachování (sloučení) zpracování tam, kde je to vhodné.
Jak funguje zřetězení Merge Join

Běžné sloučení spojení vyžaduje, aby byly oba vstupy seřazeny na klíčích spojení. Na druhou stranu spojení Merge Join Concatenation jednoduše sloučí dva již uspořádané toky do jednoho uspořádaného toku – žádné spojení jako takové neexistuje.
To vyvolává otázku:co přesně je „pořádek“, který je zachován?
V SSIS musíme nastavit vlastnosti klíče řazení na vstupech Merge, abychom definovali řazení. SQL Server k tomu nemá ekvivalent. Odpověď na otázku výše je trochu komplikovaná, takže to vezmeme krok za krokem.
Zvažte následující příklad, který vyžaduje sloučení zřetězení dvou neindexovaných tabulek haldy (nejjednodušší případ):
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (MERGE UNION);
Tyto dvě tabulky nemají žádné indexy a není zde žádná klauzule ORDER BY. Jaké pořadí „zachová“ zřetězení sloučení? Abyste o tom měli chvíli přemýšlet, podívejme se nejprve na plán provádění vytvořený pro dotaz výše ve verzích SQL Server před 2012:
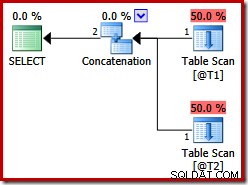
Neexistuje žádné zřetězení spojení sloučení, navzdory nápovědě k dotazu:před SQL Server 2012 tato nápověda funguje pouze s UNION, nikoli UNION ALL. Abychom získali plán s požadovaným operátorem sloučení, musíme zakázat implementaci logického UNION ALL (UNIA) pomocí fyzického operátoru Concatenation (CON). Vezměte prosím na vědomí, že následující není zdokumentováno a není podporováno pro produkční použití:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (QUERYRULEOFF UNIAtoCON);
Tento dotaz vytváří stejný plán jako SQL Server 2012 a 2014 pouze s nápovědou k dotazu MERGE UNION:
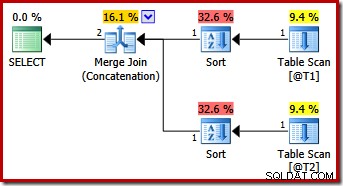
Možná neočekávaně obsahuje plán provádění explicitní řazení na obou vstupech do sloučení. Vlastnosti řazení jsou:
Dává smysl, že sloučení zachovávající pořadí vyžaduje konzistentní řazení vstupů, ale proč zvolilo (c1, c2, c3) místo řekněme (c3, c1, c2) nebo (c2, c3, c1)? Jako výchozí bod jsou vstupy zřetězení sloučení seřazeny v seznamu výstupních projekcí. Hvězdička výběru v dotazu se rozšíří na (c1, c2, c3), takže je zvolené pořadí.
Seřadit podle seznamu sloučení výstupních projekcí
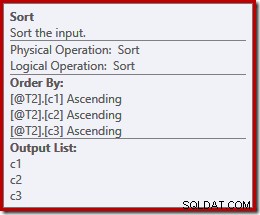
Abychom to dále ilustrovali, můžeme sami rozšířit výběrovou hvězdu (jak bychom měli!) a vybrat jiné pořadí (c3, c2, c1), když jsme u toho:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Řazení se nyní změní na shodu (c3, c2, c1):
Opět dotaz výstup pořadí (za předpokladu, že bychom do tabulek přidali nějaká data) není zaručeno, že bude seřazeno podle obrázku, protože nemáme klauzuli ORDER BY. Tyto příklady jsou určeny pouze k tomu, aby ukázaly, jak optimalizátor vybírá počáteční pořadí řazení vstupu, pokud neexistuje žádný jiný důvod pro řazení.
Konfliktní objednávky řazení
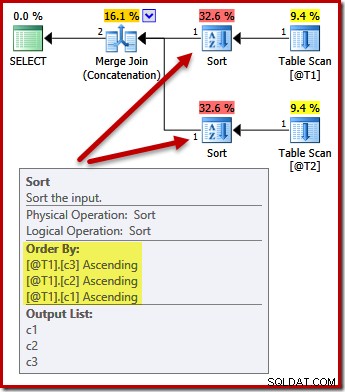
Nyní zvažte, co se stane, když ponecháme seznam projekcí jako (c3, c2, c1) a přidáme požadavek na řazení výsledků dotazu podle (c1, c2, c3). Budou se vstupy do sloučení stále řadit podle (c3, c2, c1) s řazením po sloučení na (c1, c2, c3), aby bylo splněno ORDER BY?
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 ORDER BY c1, c2, c3 OPTION (MERGE UNION);
Ne. Optimalizátor je dostatečně chytrý, aby nemusel třídit dvakrát:
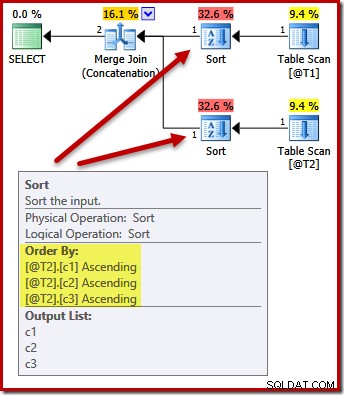
Řazení obou vstupů na (c1, c2, c3) je dokonale přijatelné pro slučovací zřetězení, takže není vyžadováno dvojité řazení.
Upozorňujeme, že tento plán dělá zaručit, že pořadí výsledků bude (c1, c2, c3). Plán vypadá stejně jako předchozí plány bez ORDER BY, ale ne všechny interní detaily jsou uvedeny v uživatelsky viditelných prováděcích plánech.
Efekt jedinečnosti
Při volbě pořadí řazení pro vstupy sloučení je optimalizátor ovlivněn také všemi existujícími zárukami jedinečnosti. Zvažte následující příklad s pěti sloupci, ale všimněte si různého pořadí sloupců v operaci UNION ALL:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Prováděcí plán zahrnuje řazení na (c5, c1, c2, c4, c3) pro tabulku @T1 a (c5, c4, c3, c2, c1) pro tabulku @T2:
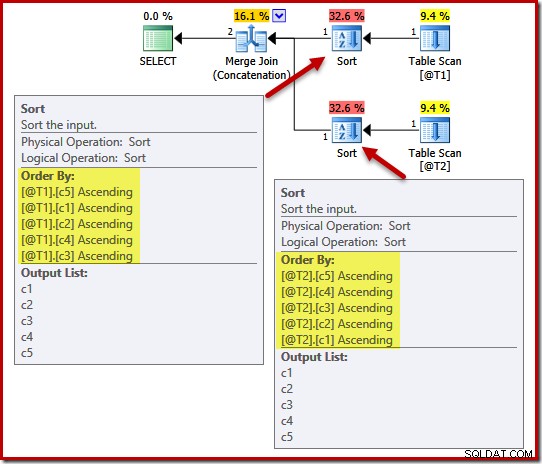
Abychom demonstrovali vliv jedinečnosti na tyto druhy, přidáme do sloupce c1 v tabulce T1 a sloupce c4 v tabulce T2 omezení UNIQUE:
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Pointou jedinečnosti je, že optimalizátor ví, že může přestat třídit, jakmile narazí na sloupec, který je zaručeně jedinečný. Řazení podle dalších sloupců po nalezení jedinečného klíče neovlivní konečné pořadí řazení, podle definice.
Se zavedenými omezeními UNIQUE může optimalizátor zjednodušit seznam řazení (c5, c1, c2, c4, c3) pro T1 až (c5, c1), protože c1 je jedinečný. Podobně je seznam řazení (c5, c4, c3, c2, c1) pro T2 zjednodušen na (c5, c4), protože c4 je klíč:
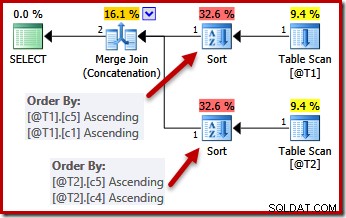
Paralelismus
Zjednodušení díky jedinečnému klíči není dokonale implementováno. V paralelním plánu jsou proudy rozděleny tak, aby všechny řádky pro stejnou instanci sloučení skončily ve stejném vláknu. Toto rozdělení datové sady je založeno na sloučených sloupcích a není zjednodušeno přítomností klíče.
Následující skript používá nepodporovaný příznak trasování 8649 ke generování paralelního plánu pro předchozí dotaz (který se jinak nemění):
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION, QUERYTRACEON 8649);
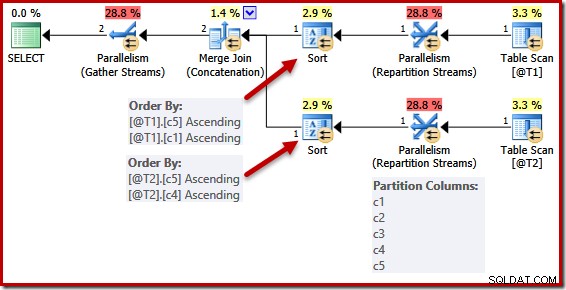
Seznamy řazení jsou zjednodušeny jako dříve, ale operátory Repartition Streams stále rozdělují všechny sloupce. Pokud by toto zjednodušení bylo implementováno důsledně, operátoři přerozdělování by také fungovali pouze na (c5, c1) a (c5, c4).
Problémy s nejedinečnými indexy
Způsob, jakým optimalizátor zdůvodňuje požadavky na řazení pro zřetězení sloučení, může vést ke zbytečným problémům s řazením, jak ukazuje následující příklad:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Podíváme-li se na dotaz a dostupné indexy, očekávali bychom plán provádění, který provádí uspořádané prohledávání seskupených indexů pomocí zřetězení slučovacích spojení, aby nebylo nutné žádné řazení. Toto očekávání je plně oprávněné, protože seskupené indexy poskytují řazení specifikované v klauzuli ORDER BY. Bohužel plán, který ve skutečnosti dostáváme, zahrnuje dva druhy:
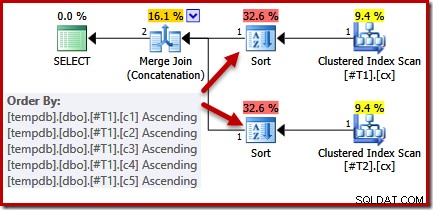
Pro tyto druhy neexistuje žádný dobrý důvod, objevují se pouze proto, že logika optimalizátoru dotazů je nedokonalá. Seznam výstupních sloupců sloučení (c1, c2, c3, c4, c5) je nadmnožinou ORDER BY, ale neexistuje žádný jedinečný klíč pro zjednodušení tohoto seznamu. V důsledku této mezery v uvažování optimalizátoru dochází k závěru, že sloučení vyžaduje jeho vstup seřazený podle (c1, c2, c3, c4, c5).
Tuto analýzu můžeme ověřit úpravou skriptu tak, aby byl jeden z seskupených indexů jedinečný:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Prováděcí plán má nyní pouze řazení nad tabulkou s nejedinečným indexem:
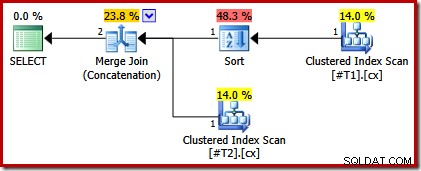
Pokud nyní uděláme obě seskupené indexy jsou jedinečné, neobjeví se žádné řazení:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE UNIQUE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1; DROP TABLE #T1, #T2;
Vzhledem k tomu, že oba indexy jsou jedinečné, lze počáteční seznamy řazení vstupu sloučení zjednodušit na samotný sloupec c1. Zjednodušený seznam pak přesně odpovídá klauzuli ORDER BY, takže v konečném plánu není potřeba žádné řazení:
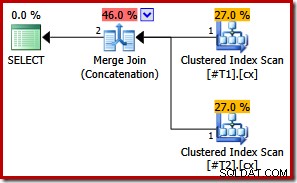
Všimněte si, že ani nepotřebujeme nápovědu k dotazu v tomto posledním příkladu, abychom získali optimální plán provádění.
Poslední myšlenky
Eliminovat druhy v prováděcím plánu může být složité. V některých případech to může být tak jednoduché jako úprava existujícího indexu (nebo poskytnutí nového), aby se řádky doručovaly v požadovaném pořadí. Optimalizátor dotazů odvede celkově rozumnou práci, když jsou k dispozici vhodné indexy.
V (mnoha) jiných případech však vyhýbání se řazení může vyžadovat mnohem hlubší pochopení prováděcího stroje, optimalizátoru dotazů a samotných operátorů plánu. Vyhýbání se třídění je nepochybně pokročilé téma ladění dotazů, ale také neuvěřitelně obohacující téma, když je vše v pořádku.