Se zavedením Azure SQL Database a přidáním dalších funkcí ve verzi 12 začínají správci databází vidět, že jejich organizace se více zajímají o přesun databází na tuto platformu.
Nedávno jsem se začal více ponořit do Azure SQL Database, abych zjistil, co je drasticky odlišné od podpory krabicové verze v datových centrech po celém světě a Azure SQL Database. Ve svém předchozím článku „Tuning:A Good Place to Start“ jsem popsal svůj přístup k zahájení ladění SQL Serveru. Rozhodl jsem se to zkontrolovat v porovnání s Azure SQL Database, abych objevil hlavní rozdíly.
Ve svém původním článku jsem začal běžnými nastaveními na úrovni instance, která jsou ignorována nebo ponechána jako výchozí, a také položkami údržby. Patří mezi ně paměť, maxdop, prahová hodnota nákladů pro paralelismus, umožnění optimalizace pro zátěže ad hoc a konfigurace databáze tempdb. S Azure SQL Database nejste odpovědní za instanci a nemůžete tato nastavení upravovat. Azure SQL Database je platforma jako služba (PaaS), což znamená, že Microsoft spravuje instanci za vás; jste jednoduše nájemcem své databáze nebo databází.
Jste však zodpovědní za údržbu, takže musíte aktualizovat statistiky a zacházet s fragmentací indexu jako u krabicového produktu. U těchto úloh jsem zjistil, že většina klientů spravuje tyto procesy pomocí vyhrazeného virtuálního počítače Azure se systémem SQL Server a pomocí SQL Server Agent s naplánovanými úlohami.
Po krocích z mého článku se další oblasti, kterými se začnu zabývat, jsou statistiky souborů a čekání a vysokonákladové dotazy. Pokud vás zajímá, zda se tento aspekt vaší práce jako produkčního dba s místními databázemi změní při práci s Azure SQL Database, odpověď zní ve skutečnosti ne . Statistiky souborů a čekání stále existují, ale musíme se k nim dostat trochu jiným způsobem. Pokud jste zvyklí používat skripty Paula Randala pro statistiky souborů a statistiky čekání (nebo dotazy na statistiky souborů po určitou dobu a statistiky čekání po určitou dobu), budete muset provést nějaké změny, aby tyto skripty pro práci s Azure SQL Database.
Když jsem poprvé vyzkoušel Pavlův skript pro statistiky souborů, selhal, protože Azure SQL Database nepodporuje sys.master_files :
Neplatný název objektu 'sys.master_files'.
Podařilo se mi upravit skript tak, aby používal sys.databases ve spojení, abyste získali název databáze a odeberte část skriptu, abyste získali názvy jednotlivých souborů, protože se budeme zabývat pouze jedním souborem dat a protokolu. Změny, které jsem musel provést, můžete vidět na následujícím obrázku:
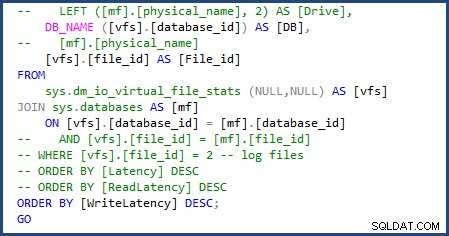
Když jsem poté spustil skript file-stats-over-a-period-of-time, provedl jsem stejnou změnu v sys.databases a odstranění odkazů na file_id ve spojení se nezdařilo, protože Azure SQL Database v12 nepodporuje globální ##temp tabulky.
Jakmile jsem změnil všechny globální ##temp tabulky na lokální, měl jsem další problém se skriptem, který nedokázal zrušit existující dočasné tabulky, které byly použity, protože na lokální #temp tabulky nelze odkazovat přímo jménem tak, jak to mohou globální ##temp tabulky, ale to bylo snadné překonat změnou těchto kontrol na OBJECT_ID('tempdb..#SQLskillsStats1') . Provedl jsem stejnou změnu pro druhou dočasnou tabulku a aktualizoval jsem blok kódu na začátku a na konci skriptu.
Musel jsem provést ještě jednu změnu a odstranit [mf].[type_desc] a LEFT ([mf].[physical_name], 2) AS [Drive] protože ty jsou závislé na sys.master_files . Skript byl poté dokončen a připraven k použití s Azure SQL Database.
Při řešení problémů s výkonem pravidelně používám soubor-stats-over-a-period-of-time. Kumulativní data mají svůj účel, ale více mě zajímají konkrétní časové úseky, kdy jsou spuštěny uživatelské zátěže.
U statistik souborů se zabýváme naší latencí na databázový soubor a tím, jak můžeme vyladit, abychom pomohli snížit celkové I/O. Přístup je stejný jako u SQL Serveru, kde potřebujete správně vyladit své dotazy a mít správné indexy. Pokud je pracovní zátěž příliš velká, musíte přejít na databázovou vrstvu DTU s rychlejším výkonem. Pro mě je to skvělé:prostě na to hodíte hardware; ale ve skutečnosti to není hardware v tradičním slova smyslu. S Azure SQL Database můžete začít s levnější vrstvou a škálovat, protože vaše podnikání a požadavky na vstup/výstup rostou – v podstatě pouhým přepnutím přepínače.
Pokus o nalezení nejlepší metody pro získání statistik čekání byl jednodušší. Standardní skript, který mnoho z nás používá, stále funguje, ale stahuje statistiky čekání pro kontejner, ve kterém běží vaše databáze. Tato čekání se stále vztahují na váš systém, ale mohou zahrnovat čekání vzniklá jinými databázemi ve stejném kontejneru. Azure SQL Database obsahuje nový DMV, sys.dm_db_wait_stats , který filtruje do aktuální databáze. Pokud jste jako já a primárně používáte Paulův skript statistiky čekání, který vynechává všechna benigní čekání, stačí změnit sys.dm_os_wait_stats na sys.dm_db_wait_stats . Stejná změna funguje i u skriptu čekání na časové období, ale musíte také provést změnu z globálních proměnných na místní.
Pokud jde o hledání vysokonákladových dotazů, jeden z mých oblíbených skriptů najde nejpoužívanější prováděcí plány. Podle mých zkušeností je vyladění dotazu, který se volá 100 000krát za den, obvykle větší výhrou než vyladění dotazu, který má nejvyšší IO, ale spouští se pouze jednou týdně. K vyhledání nejpoužívanějších plánů používám následující dotaz:
SELECT usecounts , cacheobjtype , objtype , [text]FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_sql_text(plan_handle)WHERE usecounts> 1 AND objtype IN ( N'Adhoc', N'DESCOFF use';Při použití tohoto dotazu v ukázkách vždy vyprázdním mezipaměť plánu, abych resetoval hodnoty. Když jsem se pokusil spustit
DBCC FREEPROCCACHEv Azure SQL Database se mi zobrazila následující chyba:Ukázalo se, že
SQL Azure aktuálně nepodporuje DBCC FREEPROCCACHE (Transact-SQL), takže nemůžete ručně odebrat plán provádění z mezipaměti. Pokud však provedete změny v tabulce nebo pohledu, na který dotaz odkazuje (ALTER TABLE a ALTER VIEW), plán bude odstraněn z mezipaměti.DBCC FREEPROCCACHEnení podporována v Azure SQL Database. To mě znepokojovalo, co když jsem ve výrobě a mám nějaké špatné plány a chci vymazat mezipaměť procedur, jako mohu s krabicovou verzí. Malý průzkum Google/Bing mě přivedl k tomu, že jsem našel článek Microsoftu „Porozumění mezipaměti procedur v SQL Azure“, kde se uvádí:Když o tom diskutujeme s Kimberly Tripp poté, co neviděla popsané chování, nevyprázdní plán z mezipaměti, ale zneplatní plán (a plán bude nakonec z vyrovnávací paměti zastaralý). I když je to v určitých situacích užitečné, nebylo to to, co jsem potřeboval. Pro své demo jsem chtěl resetovat čítače v sys.dm_exec_cached_plans. Vygenerování nového plánu by mi nepřineslo požadované výsledky. Oslovil jsem svůj tým a Glenn Berry mi řekl, abych zkusil následující skript:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;Tento příkaz fungoval; Podařilo se mi vymazat mezipaměť procedur pro konkrétní databázi. Konfigurace rozsahu databáze je nová funkce přidaná do SQL Server 2016 RC0; Glenn o tom napsal blog zde:Použití ALTER DATABASE SCOPED CONFIGURATION v SQL Server 2016.
Jsem nadšený, že mohu přesunout několik svých vlastních databází do Azure SQL Database a že se budu nadále učit o nových funkcích a možnostech škálovatelnosti. Také se těším na spolupráci se SentryOne DB Sentry, nedávným přírůstkem do platformy SentryOne. Nejvíce mě zajímá experimentování s řídicím panelem DTU Usage, který Mike Wood popsal ve svém nedávném příspěvku.