Pokud používáte rozdělení tabulky na oddíly s jedním nebo více oddíly uloženými ve skupině souborů pouze pro čtení, příkazy SQL update a delete mohou selhat s chybou. Toto je samozřejmě očekávané chování, pokud by některá z úprav vyžadovala zápis do skupiny souborů pouze pro čtení; je však také možné narazit na tento chybový stav, kdy jsou změny omezeny na skupiny souborů označené jako čtení a zápis.
Ukázka databáze
Abychom problém demonstrovali, vytvoříme jednoduchou databázi s jedinou vlastní skupinou souborů, kterou později označíme jako pouze pro čtení. Všimněte si, že budete muset přidat cestu k souboru, aby vyhovovala vaší testovací instanci.
USE master;GOCREATE DATABASE Test;GO-- Tato skupina souborů bude označena jako pouze pro čtení. <...vaše cesta...>\MSSQL\DATA\Test_ReadOnly.ndf')TO FILEGROUP ReadOnlyFileGroup;
Funkce a schéma rozdělení
Nyní vytvoříme základní rozdělovací funkci a schéma, které bude směrovat řádky s daty před 1. lednem 2000 do oddílu pouze pro čtení. Pozdější data budou uložena v primární skupině souborů pro čtení a zápis:
Specifikace rozsahu vpravo znamená, že řádky s hraniční hodnotou 1. ledna 2000 budou v oddílu pro čtení a zápis.
Rozdělená tabulka a indexy
Nyní můžeme vytvořit naši testovací tabulku:
CREATE TABLE dbo.Test( dt datetime NOT NULL, c1 integer NOT NULL, c2 integer NOT NULL, CONSTRAINT PK_dbo_Test__c1_dt PRIMAR KEY CLUSTERED (dt) ON PS (dt))ON PS (dt);GOCREATE_dINDEXbo NODboLUest. Test (c1)ON PS (dt);GOCREATE NENCLUSTERED INDEX IX_dbo_Test_c2ON dbo.Test (c2)ON PS (dt);
Tabulka má seskupený primární klíč ve sloupci datetime a je také rozdělena na tento sloupec. Na dalších dvou celočíselných sloupcích jsou neshlukované indexy, které jsou rozděleny stejným způsobem (indexy jsou zarovnány se základní tabulkou).
Ukázková data
Nakonec přidáme několik řádků ukázkových dat a datový oddíl před rokem 2000 zajistíme pouze pro čtení:
INSERT dbo.Test WITH (TABLOCKX) (dt, c1, c2)VALUES ({D '1999-12-31'}, 1, 1), -- Pouze pro čtení ({D '2000-01-01' }, 2, 2); -- WritableGOALTER DATABASE TestMODIFY FILEGROUP ReadOnlyFileGroup READ_ONLY;
Následující testovací příkazy aktualizace můžete použít k potvrzení, že data v oddílu pouze pro čtení nelze upravit, zatímco data s dt hodnotu k 1. lednu 2000 nebo později lze zapsat na:
-- Selže podle očekáváníUPDATE dbo.TestSET c2 =1WHERE dt ={D '1999-12-31'}; -- Úspěšně, podle očekávání UPDATE dbo.TestSET c2 =999WHERE dt ={D '2000-01-01'}; -- Resetujte hodnotu c2UPDATE dbo.TestSET c2 =2WHERE dt ={D '2000-01-01'}; Neočekávané selhání
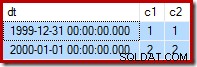
Máme dva řádky:jeden jen pro čtení (1999-12-31); a jedno čtení a zápis (2000-01-01):

Nyní zkuste následující dotaz. Identifikuje stejný zapisovatelný řádek „2000-01-01“, který jsme právě úspěšně aktualizovali, ale používá jiný predikát klauzule where:
UPDATE dbo.TestSET c2 =2WHERE c1 =2;
Odhadovaný (před provedením) plán je:

Čtyři (!) Compute Scalars nejsou pro tuto diskusi důležité. Používají se k určení, zda je nutné udržovat neshlukovaný index pro každý řádek, který dorazí k operátoru Aktualizace seskupeného indexu.
Zajímavější je, že toto prohlášení o aktualizaci selže s chybou podobnou:
Msg 652, Level 16, State 1Index "PK_dbo_Test__c1_dt" pro tabulku "dbo.Test" (RowsetId 72057594039042048) je umístěn ve skupině souborů pouze pro čtení ("ReadOnlyFileGroup."), kterou nelze upravit.
Není k odstranění oddílu
Pokud jste již s dělením pracovali, možná si říkáte, že důvodem může být „odstranění diskových oddílů“. Logika by vypadala asi takto:
V předchozích příkazech byla v klauzuli where poskytnuta doslovná hodnota pro rozdělovací sloupec, takže SQL Server by byl schopen okamžitě určit, ke kterému oddílu (oddílům) má přistupovat. Změnou klauzule where, aby již neodkazovala na rozdělovací sloupec, jsme přinutili SQL Server přistupovat ke každému oddílu pomocí Clustered Index Scan.
To vše je obecně pravda, ale není to důvod, proč se zde příkaz aktualizace nezdaří.
Očekávaným chováním je, že SQL Server by měl být schopen číst ze všech oddílů během provádění dotazu. Operace úpravy dat by měla pouze selhat pokud se prováděcí stroj skutečně pokusí upravit řádek uložený ve skupině souborů pouze pro čtení.
Pro ilustraci udělejme malou změnu v předchozím dotazu:
UPDATE dbo.TestSET c2 =2, dt =dtWHERE c1 =2;
Klauzule where je úplně stejná jako předtím. Jediný rozdíl je v tom, že nyní (záměrně) nastavujeme rozdělovací sloupec na sebe. To nezmění hodnotu uloženou v tomto sloupci, ale ovlivní výsledek. Aktualizace nyní proběhla úspěšně (i když se složitějším prováděcím plánem):

Optimalizátor zavedl nové operátory Split, Sort a Collapse a přidal strojní zařízení nezbytné pro správu každého potenciálně ovlivněného neshlukovaného indexu samostatně (pomocí široké strategie neboli strategie pro jednotlivé indexy).
Vlastnosti Clustered Index Scan ukazují, že oba oddíly tabulky byly přístupné při čtení:
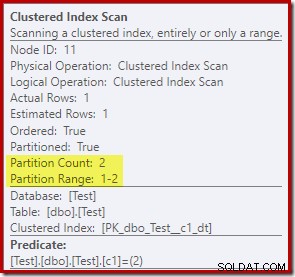
Naproti tomu aktualizace Clustered Index Update ukazuje, že pro zápis byl přístupný pouze oddíl pro čtení a zápis:
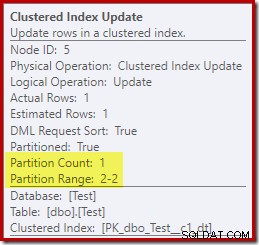
Každý z operátorů Nonclustered Index Update zobrazuje podobné informace:za běhu byl změněn pouze zapisovatelný oddíl (#2), takže nedošlo k žádné chybě.
Důvod odhalen
Nový plán uspěje ne protože neklastrované indexy jsou udržovány odděleně; ani je to (přímo) kvůli kombinaci Split-Sort-Collapse nutné k tomu, aby se zabránilo přechodným chybám duplicitních klíčů v jedinečném indexu.
Skutečným důvodem je něco, co jsem krátce zmínil ve svém předchozím článku „Optimalizace aktualizačních dotazů“ – interní optimalizace známá jako Sdílení sady řádků . Když je toto použito, Clustered Index Update sdílí stejnou základní sadu řádků úložiště jako Clustered Index Scan, Seek nebo Key Lookup na straně čtení plánu.
Pomocí optimalizace Sdílení sady řádků SQL Server kontroluje skupiny souborů offline nebo pouze pro čtení při čtení. V plánech, kde aktualizace Clustered Index Update používá samostatnou sadu řádků, se kontrola offline/pouze pro čtení provádí pouze pro každý řádek v iterátoru aktualizace (nebo odstranění).
Nezdokumentovaná zástupná řešení
Pojďme nejprve odstranit zábavné, podivínské, ale nepraktické věci.
Optimalizaci sdílené sady řádků lze použít pouze v případě, že trasa z hledání seskupeného indexu, skenování nebo vyhledávání klíčů je potrubí . Nejsou povoleny žádné blokující nebo poloblokující operátory. Jinak řečeno, každý řádek musí být schopen dostat se ze zdroje čtení do cíle zápisu, než se přečte další řádek.
Připomínáme, že zde jsou ukázková data, prohlášení a plán provedení pro neúspěšné aktualizovat znovu:
--Změňte řádek pro čtení a zápisUPDATE dbo.TestSET c2 =2WHERE c1 =2;

Halloweenská ochrana
Jedním ze způsobů, jak do plánu zavést blokujícího operátora, je vyžadovat pro tuto aktualizaci explicitní Halloweenskou ochranu (HP). Oddělení čtení od zápisu pomocí operátoru blokování zabrání použití optimalizace sdílení sady řádků (žádný kanál). Nedokumentovaný a nepodporovaný (pouze testovací systém!) příznak trasování 8692 přidává Eager Table Spool pro explicitní HP:
-- Funguje (explicitní HP) UPDATE dbo.TestSET c2 =2WHERE c1 =2OPTION (QUERYTRACEON 8692);
Skutečný plán provádění (dostupný, protože chyba již není vyvolána) je:

Kombinace Řadit v kombinaci Split-Sort-Collapse uvedená v předchozí úspěšné aktualizaci poskytuje blokování nezbytné pro zakázání sdílení sady řádků v tomto případě.
Příznak trasování sdílení Anti-Rowset
Existuje jiný příznak trasování nezdokumentovaný, který zakáže optimalizaci sdílení sady řádků. To má výhodu v tom, že nezavádí potenciálně drahý blokovací operátor. V praxi to samozřejmě nelze použít (pokud se neobrátíte na podporu Microsoftu a nedostanete písemně něco s doporučením, abyste to povolili, předpokládám). Nicméně pro zábavní účely je zde příznak sledování 8746 v akci:
-- Funguje (žádné sdílení sady řádků)UPDATE dbo.TestSET c2 =2WHERE c1 =2OPTION (QUERYTRACEON 8746);
Skutečný plán provádění tohoto příkazu je:

Nebojte se experimentovat s různými hodnotami (takovými, které ve skutečnosti mění uložené hodnoty, chcete-li), abyste se zde přesvědčili o rozdílu. Jak bylo zmíněno v mém předchozím příspěvku, můžete také použít nezdokumentovaný příznak trasování 8666 k odhalení vlastnosti sdílení sady řádků v plánu provádění.
Pokud chcete vidět chybu sdílení sady řádků s příkazem delete, jednoduše nahraďte klauzule aktualizace a nastavte klauzule delete, přičemž použijte stejnou klauzuli where.
Podporovaná zástupná řešení
Existuje libovolný počet potenciálních způsobů, jak zajistit, aby sdílení sady řádků nebylo použito v dotazech v reálném světě bez použití příznaků trasování. Nyní, když víte, že hlavní problém vyžaduje sdílený a zřetězený klastrovaný plán čtení a zápisu indexu, pravděpodobně můžete přijít s vlastním. Přesto existuje několik příkladů, které stojí za to si zde prohlédnout.
Vynucený index / krycí index
Jedním z přirozených nápadů je přinutit čtecí stranu plánu, aby místo seskupeného indexu používala index bez clusterů. Nemůžeme přidat nápovědu indexu přímo k testovacímu dotazu tak, jak je napsán, ale aliasování tabulky to umožňuje:
AKTUALIZOVAT TSET c2 =2FROM dbo.Test AS TWITH (INDEX(IX_dbo_Test_c1))WHERE c1 =2;
To by se mohlo zdát jako řešení, které by měl optimalizátor dotazů zvolit na prvním místě, protože ve sloupci c1 predikátu klauzule where máme neshlukovaný index. Plán provádění ukazuje, proč se optimalizátor rozhodl tak, jak to udělal:
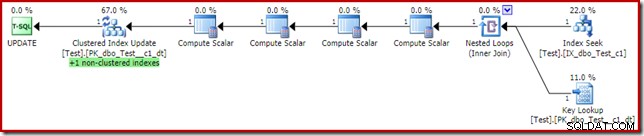
Náklady na vyhledávání klíčů jsou dostatečné k tomu, aby přesvědčil optimalizátor, aby ke čtení použil seskupený index. K načtení aktuální hodnoty sloupce c2 je potřeba vyhledání, takže výpočetní skalary mohou rozhodnout, zda je třeba zachovat neshlukovaný index.
Přidání sloupce c2 do neklastrovaného indexu (klíč nebo zahrnutí) by se problému vyhnulo. Optimalizátor by zvolil nyní pokrývající index namísto seskupeného indexu.
To znamená, že není vždy možné předvídat, které sloupce budou potřeba, nebo je zahrnout všechny, i když je známa sada. Pamatujte, že sloupec je potřeba, protože c2 je v klauzuli set aktualizačního prohlášení. Pokud jsou dotazy ad-hoc (např. odeslané uživateli nebo generované nástrojem), každý neshlukovaný index bude muset zahrnovat všechny sloupce, aby se z toho stala robustní možnost.
Jedna zajímavá věc na plánu s výše uvedeným vyhledáváním klíčů je, že nedělá vygenerovat chybu. A to navzdory vyhledávání klíčů a aktualizaci seskupeného indexu pomocí sdílené sady řádků. Důvodem je, že neshlukované hledání indexu najde řádek s c1 =2 před vyhledávání klíčů se dotkne seskupeného indexu. Kontrola sdílené sady řádků pro skupiny souborů offline / pouze pro čtení se stále provádí při vyhledávání, ale nedotýká se oddílu pouze pro čtení, takže nedojde k chybě. Posledním (souvisejícím) bodem zájmu je, že hledání indexu se dotýká obou oddílů, ale vyhledávání klíčů zasáhne pouze jeden.
Vyjma oddílu pouze pro čtení
Triviálním řešením je spolehnout se na eliminaci oddílu, takže čtecí strana plánu se nikdy nedotkne oddílu pouze pro čtení. To lze provést pomocí explicitního predikátu, například některého z těchto:
UPDATE dbo.TestSET c2 =2WHERE c1 =2AND dt>={D '2000-01-01'}; UPDATE dbo.TestSET c2 =2WHERE c1 =2AND $PARTITION.PF(dt)> 1; -- Není oddíl #1 Tam, kde je nemožné nebo nepohodlné změnit každý dotaz a přidat predikát eliminace oddílu, mohou být vhodná jiná řešení, jako je aktualizace prostřednictvím pohledu. Například:
CREATE VIEW dbo.TestWritablePartitionsWITH SCHEMABINDINGAS-- Pouze zapisovatelná část tabulkySELECT T.dt, T.c1, T.c2FROM dbo.Test AS TWHERE $PARTITION.PF(dt)> 1;GO-- SucceedsUPDATE dbo. TestWritablePartionsSET c2 =2WHERE c1 =2;
Jednou nevýhodou použití zobrazení je to, že aktualizace nebo odstranění, které cílí na část základní tabulky pouze pro čtení, bude úspěšné bez ovlivnění řádků, místo aby selhalo s chybou. Místo spouštěče na stole nebo pohledu může být v některých situacích řešením, ale může také způsobit další problémy… ale to jsem odbočil.
Jak již bylo zmíněno, existuje mnoho potenciálních podporovaných řešení. Cílem tohoto článku je ukázat, jak sdílení sady řádků způsobilo neočekávanou chybu aktualizace.