@rob_farley vaše nedávné řešení stackoverflow k řazení podle hodnoty, poté pole génius! Chtěl jsem vám osobně poděkovat.
— Joel Sacco (@Jsac90) 11. srpna 2016
Viděl jsem, jak tento tweet prošel…
A donutilo mě to podívat se, na co se to vztahuje, protože jsem na StackOverflow nenapsal nic „nedávno“ o objednávání dat. Ukázalo se, že to byla tuto odpověď, kterou jsem napsal , která ačkoli nebyla přijata, nasbírala přes sto hlasů.
Osoba, která položila otázku, měla velmi jednoduchý problém – chtěl, aby se určité řádky objevily jako první. A moje řešení bylo jednoduché:
ORDER BY CASE WHEN city = 'New York' THEN 1 ELSE 2 END, City;
Zdá se, že to byla populární odpověď, včetně odpovědi pro Joela Sacca (podle výše uvedeného tweetu).
Smyslem je vytvořit výraz a podle toho uspořádat. ORDER BY nezajímá, zda se jedná o skutečný sloupec nebo ne. Totéž byste mohli udělat pomocí APPLY, pokud opravdu dáváte přednost použití 'sloupec' v klauzuli ORDER BY.
SELECT Users.* FROM Users CROSS APPLY ( SELECT CASE WHEN City = 'New York' THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, City;
Pokud použiji nějaké dotazy proti WideWorldImporters, mohu vám ukázat, proč jsou tyto dva dotazy skutečně úplně stejné. Budu se dotazovat na tabulku Sales.Orders a požádám, aby se jako první zobrazily objednávky pro prodejce 7. Také vytvořím vhodný index pokrytí:
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID) INCLUDE (OrderDate);
Plány pro tyto dva dotazy vypadají identicky. Provádějí identicky – stejná čtení, stejné výrazy, ve skutečnosti jsou to stejné dotazy. Pokud existuje nepatrný rozdíl ve skutečném CPU nebo délce trvání, je to náhoda kvůli jiným faktorům.
SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders ORDER BY CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END, SalespersonPersonID; SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders CROSS APPLY ( SELECT CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, SalespersonPersonID;
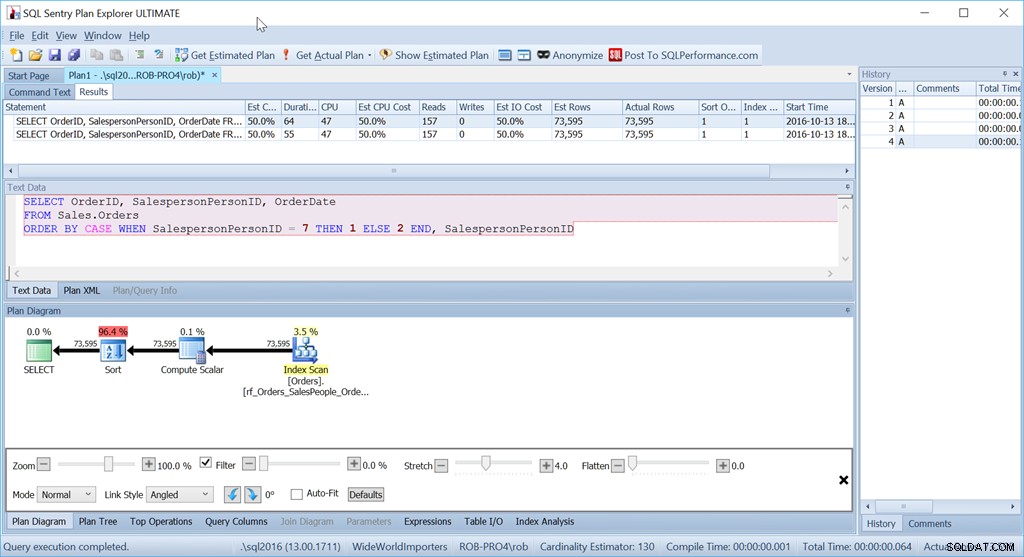
A přesto to není dotaz, který bych v této situaci skutečně použil. Ne, kdyby pro mě byl důležitý výkon. (Obvykle je, ale ne vždy se vyplatí psát dotaz zdlouhavě, pokud je množství dat malé.)
Co mi vadí je ten operátor řazení. Je to 96,4 % nákladů!
Zvažte, zda chceme pouze objednávat podle SalespersonPersonID:
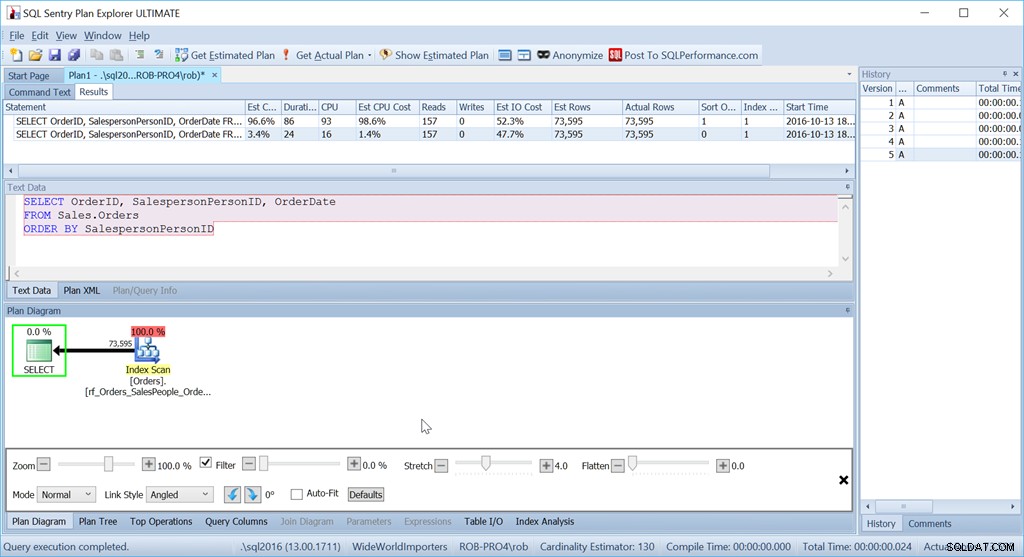
Vidíme, že odhadovaná cena CPU tohoto jednoduššího dotazu je 1,4 % dávky, zatímco u verze s vlastním řazením je to 98,6 %. To je Sedmdesátkrát horší. Čtení jsou však stejná – to je dobře. Trvání je mnohem horší a CPU také.
Nemám rád Sorts. Mohou být oškliví.
Jednou z možností, kterou zde mám, je přidat vypočítaný sloupec do své tabulky a indexovat to, ale to bude mít dopad na cokoli, co hledá všechny sloupce v tabulce, jako jsou ORM, Power BI nebo cokoli, co dělá SELECT * . Takže to není tak skvělé (ačkoli kdybychom někdy přidali skryté vypočítané sloupce, byla by to opravdu pěkná možnost).
Další možností, která je rozvláčnější (někteří by mohli naznačovat, že by mi vyhovovala – a pokud jste si mysleli, že:Oi! Nebuďte tak hrubý!) a používá více čtení, je zvážit, co bychom dělali v reálném životě, kdybych museli jsme to udělat.
Pokud bych měl hromadu 73 595 objednávek seřazených podle objednávky prodejce a potřeboval bych je nejprve vrátit s konkrétním prodejcem, neignoroval bych pořadí, ve kterém byly, a jednoduše je všechny seřadil, začal bych tím, že se ponořím a najít ty pro prodejce 7 – udržet je v pořadí, v jakém byly. Pak bych našel ty, které nebyly ty, které nebyly pro prodejce 7 – dal je jako další a znovu je ponechal v pořadí, v jakém už byly v.
V T-SQL se to dělá takto:
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID; Tím získáte dvě sady dat a zřetězíte je. Ale Optimalizátor dotazů vidí, že potřebuje udržovat objednávku SalespersonPersonID, jakmile jsou dvě sady zřetězeny, takže provede speciální druh zřetězení, který toto pořadí zachová. Je to spojení Merge Join (Concatenation) a plán vypadá takto:
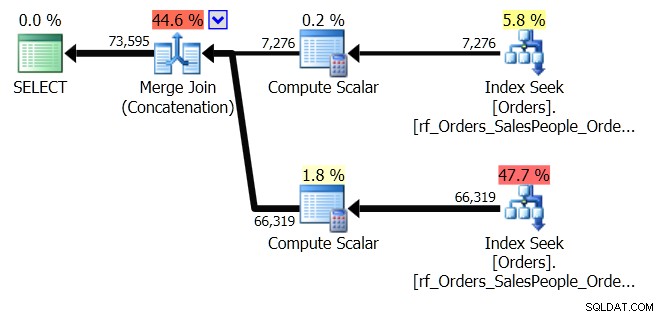
Vidíte, že je to mnohem složitější. Ale doufejme, že si také všimnete, že neexistuje operátor řazení. Merge Join (Concatenation) stahuje data z každé větve a vytváří datovou sadu, která je ve správném pořadí. V tomto případě nejprve vytáhne všech 7 276 řádků pro prodejce 7 a poté vytáhne dalších 66 319, protože to je požadovaná objednávka. V rámci každé sady jsou data v objednávce SalespersonPersonID, která je udržována, když data procházejí.
Již jsem zmínil, že používá více čtení a také to dělá. Pokud ukážu výstup SET STATISTICS IO při porovnání těchto dvou dotazů, vidím toto:
Tabulka 'Pracovní stůl'. Počet skenů 0, logické čtení 0, fyzické čtení 0, čtení napřed 0, logické čtení 0 lob, fyzické čtení 0, lob čtení napřed čte 0.Tabulka 'Objednávky'. Počet skenů 1, logické čtení 157, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka 'Objednávky '. Počet skenů 3, logické čtení 163, fyzické čtení 0, čtení napřed čtení 0, logické čtení lob 0, fyzické čtení 0 lob, napřed čtení 0.
Při použití verze "Custom Sort" jde pouze o jedno skenování indexu s použitím 157 čtení. Při použití metody „Union All“ jsou to tři skenování – jedno pro SalespersonPersonID =7, jedno pro SalespersonPersonID <7 a jedno pro SalespersonPersonID> 7. Poslední dva můžeme vidět, když se podíváme na vlastnosti druhého hledání indexu:
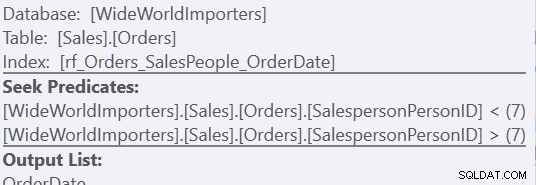
Pro mě však výhoda spočívá v absenci pracovního stolu.
Podívejte se na odhadované náklady na CPU:

Není to tak malé jako našich 1,4 %, když se třídění úplně vyhýbáme, ale stále je to obrovské zlepšení oproti naší metodě vlastního třídění.
Ale slovo varování…
Předpokládejme, že jsem tento index vytvořil jinak a měl OrderDate jako klíčový sloupec, nikoli jako zahrnutý sloupec.
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID, OrderDate);
Nyní moje metoda "Union All" vůbec nefunguje tak, jak bylo zamýšleno.
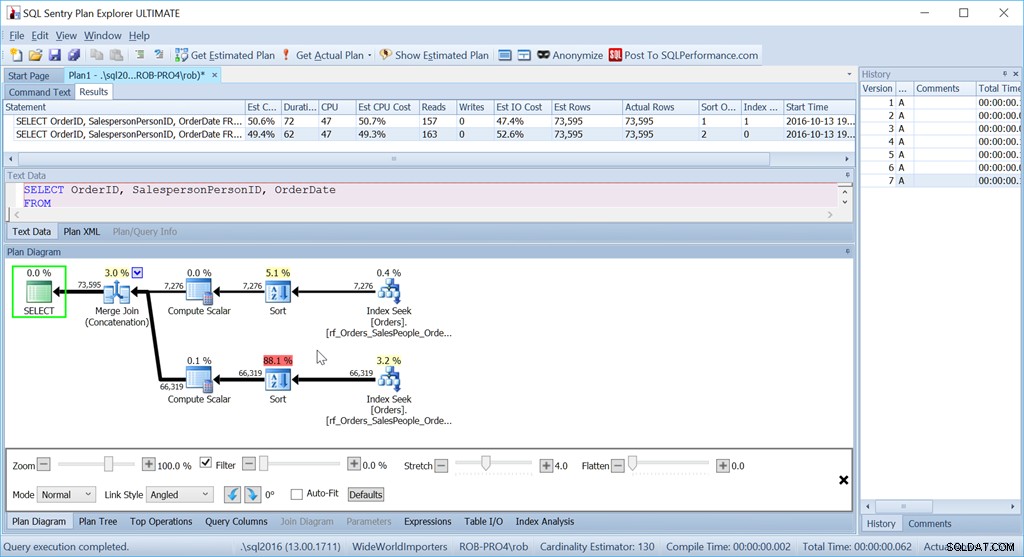
Navzdory tomu, že používám přesně stejné dotazy jako dříve, můj pěkný plán má nyní dva operátory řazení a funguje téměř stejně špatně jako moje původní verze Scan + Sort.
Důvodem je podivnost operátoru Merge Join (Concatenation) a vodítko je v operátoru Sort.

Je to řazení podle SalespersonPersonID následované OrderID – což je seskupený indexový klíč tabulky. Vybere si toto, protože je známo, že je to jedinečné, a je to menší sada sloupců, podle kterých se má třídit, než SalespersonPersonID následované OrderDate následovaným OrderID, což je pořadí datové sady vytvořené třemi skeny rozsahu indexu. Jeden z těch případů, kdy si Optimalizátor dotazů nevšimne lepší možnosti, která je právě tady.
S tímto indexem bychom k vytvoření našeho preferovaného plánu potřebovali také naši datovou sadu uspořádanou podle OrderDate.
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID, OrderDate;
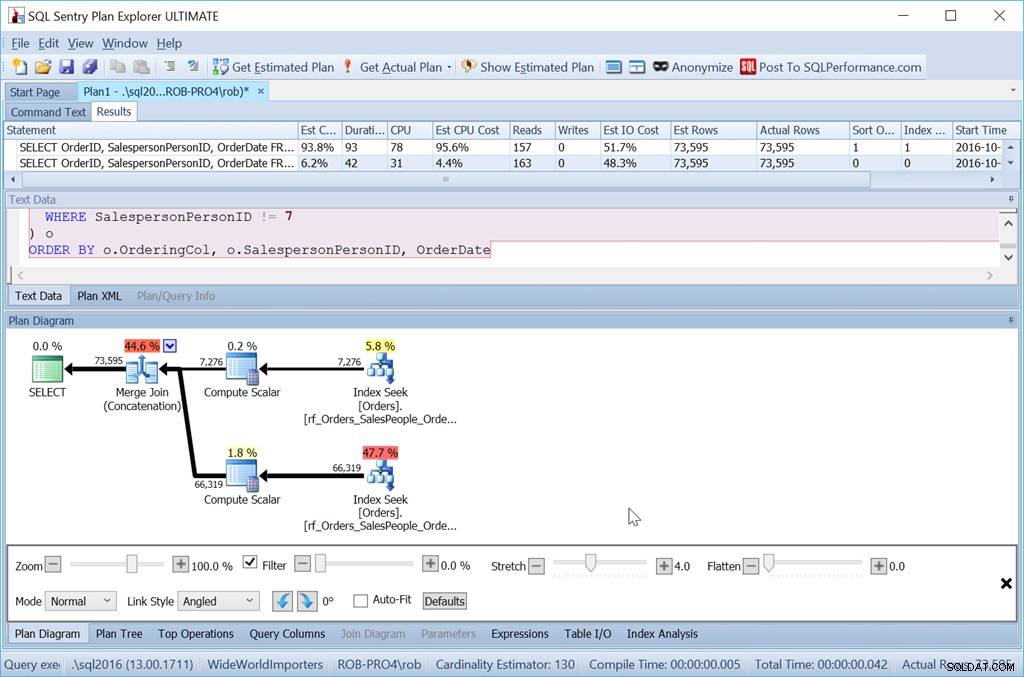
Takže je to určitě větší námaha. Dotaz je pro mě delší na psaní, je to více čtení a musím mít index bez dalších klíčových sloupců. Ale je to určitě rychlejší. S ještě větším počtem řádků je dopad ještě větší a také nemusím riskovat, že se řazení přelije do databáze tempdb.
Pro malé sady je moje odpověď StackOverflow stále dobrá. Ale když mě operátor Sort stojí výkon, použiji metodu Union All / Merge Join (Concatenation).