 Jakmile jsem viděl funkci SQL 2016 AT TIME ZONE, o které jsem psal zde na sqlperformance.com a před několika měsíci jsem si vzpomněl na zprávu, která tuto funkci potřebovala. Tento příspěvek tvoří případovou studii o tom, jak jsem viděl, že to funguje, která zapadá do úterý T-SQL tohoto měsíce pořádaného Mattem Gordonem (@sqlatspeed). (Je 87. úterý T-SQL a já opravdu potřebuji napsat více blogových příspěvků, zejména o věcech, které úterky T-SQL nevyžadují.)
Jakmile jsem viděl funkci SQL 2016 AT TIME ZONE, o které jsem psal zde na sqlperformance.com a před několika měsíci jsem si vzpomněl na zprávu, která tuto funkci potřebovala. Tento příspěvek tvoří případovou studii o tom, jak jsem viděl, že to funguje, která zapadá do úterý T-SQL tohoto měsíce pořádaného Mattem Gordonem (@sqlatspeed). (Je 87. úterý T-SQL a já opravdu potřebuji napsat více blogových příspěvků, zejména o věcech, které úterky T-SQL nevyžadují.)
Situace byla taková a může vám to znít povědomě, pokud si přečtete ten můj předchozí příspěvek.
Dlouho předtím, než existovala řešení LobsterPot, jsem potřeboval vytvořit zprávu o incidentech, ke kterým došlo, a zejména ukázat, kolikrát byly v rámci SLA učiněny odpovědi a kolikrát SLA chyběla. Například incident Sev2, ke kterému došlo v 16:30 ve všední den, by musel mít odpověď do 1 hodiny, zatímco incident Sev2, ke kterému došlo v 17:30 ve všední den, by musel mít odpověď do 3 hodin. Nebo tak nějak – zapomněl jsem na ta čísla, ale pamatuji si, že zaměstnanci helpdesku si oddechli, když se točila 17:00, protože by nemuseli reagovat na věci tak rychle. 15minutové výstrahy Sev1 by se náhle protáhly na hodinu a naléhavost by zmizela.
Problém by ale nastal vždy, když začal nebo skončil letní čas.
Jsem si jistý, že pokud máte co do činění s databázemi, víte, jaká je bolest letního času. S nápadem prý přišel Ben Franklin – a za to by ho měl udeřit blesk nebo tak něco. Západní Austrálie to nedávno zkusila na pár let a rozumně to opustila. A obecný konsenzus je ukládat data/čas data v UTC.
Pokud neukládáte data v UTC, riskujete, že událost začne ve 2:45 a skončí ve 2:15 poté, co se hodiny vrátí. Nebo mít incident SLA, který začíná v 1:59 těsně předtím, než hodiny půjdou dopředu. Nyní jsou tyto časy v pořádku, pokud uložíte časové pásmo, ve kterém se nacházejí, ale čas UTC funguje podle očekávání.
...kromě hlášení.
Protože jak mám vědět, zda konkrétní datum bylo před zahájením letního času nebo po něm? Mohl bych vědět, že k incidentu došlo v 6:30 v UTC, ale je to 16:30 v Melbourne nebo 17:30? Samozřejmě mohu zvážit, ve kterém měsíci to je, protože vím, že Melbourne dodržuje letní čas od první neděle v říjnu do první neděle v dubnu, ale pokud jsou zákazníci v Brisbane, Aucklandu, Los Angeles a Phoenixu, a na různých místech v Indianě jsou věci mnohem komplikovanější.
Abychom to obešli, existovalo jen velmi málo časových pásem, ve kterých bylo možné pro danou společnost definovat SLA. Bylo to prostě považováno za příliš těžké na to, aby se postaralo o víc než to. Zpráva by pak mohla být upravena tak, aby říkala „Uvažujte, že se v určité datum časové pásmo změnilo z X na Y“. Připadalo mi to špinavé, ale fungovalo to. Nebylo potřeba nic hledat v registru Windows a v podstatě to fungovalo.
Ale v dnešní době bych to udělal jinak.
Nyní bych použil AT TIME ZONE.
Vidíte, teď bych mohl uložit informace o časovém pásmu zákazníka jako vlastnost zákazníka. Poté jsem mohl uložit čas každého incidentu v UTC, což mi umožnilo provést nezbytné výpočty kolem počtu minut na odpověď, vyřešení atd., a zároveň jsem mohl hlásit pomocí místního času zákazníka. Za předpokladu, že můj IncidentTime byl skutečně uložen pomocí datetime, spíše než datetimeoffset, šlo by jednoduše o použití kódu jako:
i.IncidentTime AT TIME ZONE 'UTC' AT TIME ZONE c.tz
…který nejprve vloží časovou zónu i.IncidentTime do UTC a poté jej převede na časové pásmo zákazníka. A toto časové pásmo může být „AUS východní standardní čas“ nebo „Mauricijský standardní čas“ nebo cokoliv jiného. A SQL Engine musí přijít na to, jaký offset k tomu použít.
V tomto okamžiku mohu velmi snadno vytvořit zprávu, která uvádí každý incident za určité časové období a zobrazí jej v místním časovém pásmu zákazníka. Mohu převést hodnotu na typ časových dat a poté hlásit, kolik incidentů bylo během pracovní doby nebo ne.
A to vše je velmi užitečné, ale co indexování, aby to zvládlo pěkně? Koneckonců, AT TIME ZONE je funkce. Ale změna časového pásma nemění pořadí, ve kterém k incidentům skutečně došlo, takže by to mělo být v pořádku.
Abych to otestoval, vytvořil jsem tabulku nazvanou dbo.Incidents a indexoval sloupec IncidentTime. Potom jsem provedl tento dotaz a potvrdil, že bylo použito hledání indexu.
select i.IncidentTime, itz.LocalTime from dbo.Incidents i cross apply (select i.IncidentTime AT TIME ZONE 'UTC' AT TIME ZONE 'Cen. Australia Standard Time') itz (LocalTime) where i.IncidentTime >= '20170201' and i.IncidentTime < '20170301';
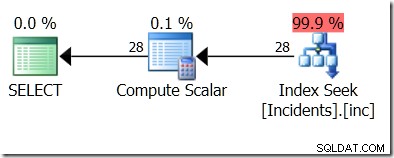
Ale chci filtrovat podle itz.LocalTime…
select i.IncidentTime, itz.LocalTime from dbo.Incidents i cross apply (select i.IncidentTime AT TIME ZONE 'UTC' AT TIME ZONE 'Cen. Australia Standard Time') itz (LocalTime) where itz.LocalTime >= '20170201' and itz.LocalTime < '20170301';
Žádné štěstí. Index se nelíbil.
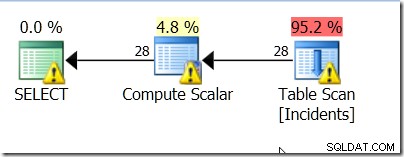
Varování jsou proto, že je třeba procházet mnohem více než jen data, která mě zajímají.
Dokonce jsem zkusil použít tabulku s polem datetimeoffset. Koneckonců, AT TIME ZONE může změnit pořadí při přechodu z datetime na datetimeoffset, i když se pořadí při přechodu z datetimeoffset na jiný datetimeoffset nezmění. Dokonce jsem se snažil ujistit, že věc, se kterou jsem to srovnával, byla v časovém pásmu.
select i.IncidentTime, itz.LocalTime
from dbo.IncidentsOffset i
cross apply (select i.IncidentTime AT TIME ZONE 'Cen. Australia Standard Time') itz (LocalTime)
where itz.LocalTime >= cast('20170201' as datetimeoffset)
AT TIME ZONE 'Cen. Australia Standard Time'
and itz.LocalTime < cast('20170301' as datetimeoffset)
AT TIME ZONE 'Cen. Australia Standard Time';
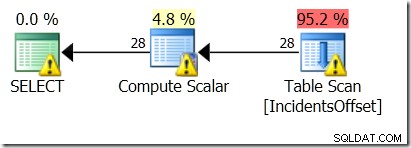
Stále žádné štěstí!
Takže teď jsem měl dvě možnosti. Jedním z nich bylo uložit převedenou verzi vedle verze UTC a indexovat ji. Myslím, že je to bolest. Určitě je to mnohem větší změna databáze, než bych si přál.
Druhou možností bylo použít to, čemu říkám pomocné predikáty. To jsou věci, které vidíte, když použijete LIKE. Jsou to predikáty, které lze použít jako predikáty hledání, ale ne přesně to, o co žádáte.
Myslím, že bez ohledu na to, jaké časové pásmo mě zajímá, časy incidentů, na kterých mi záleží, jsou ve velmi specifickém rozsahu. Tento rozsah není na žádné straně o více než jeden den větší než můj preferovaný rozsah.
Takže přidám dva další predikáty.
select i.IncidentTime, itz.LocalTime
from dbo.IncidentsOffset i
cross apply (select i.IncidentTime
AT TIME ZONE 'Cen. Australia Standard Time') itz (LocalTime)
where itz.LocalTime >= cast('20170201' as datetimeoffset)
AT TIME ZONE 'Cen. Australia Standard Time'
and itz.LocalTime < cast('20170301' as datetimeoffset)
AT TIME ZONE 'Cen. Australia Standard Time
and i.IncidentTime >= dateadd(day,-1,'20170201')
and i.IncidentTime < dateadd(day, 1,'20170301');
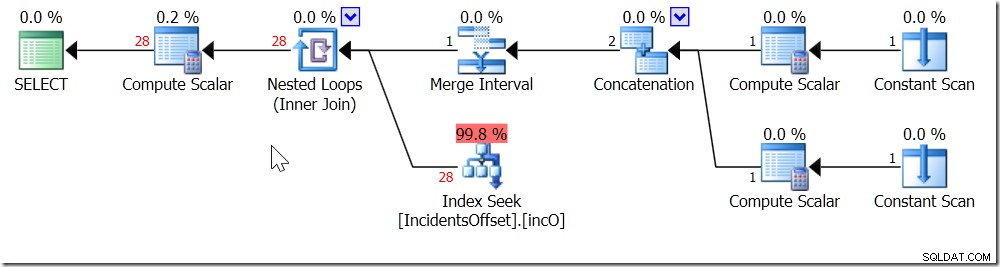
Nyní lze použít můj index. Musí se podívat přes 30 řádků, než to přefiltruje na 28, na kterých mu záleží – ale to je mnohem lepší než skenování celé.
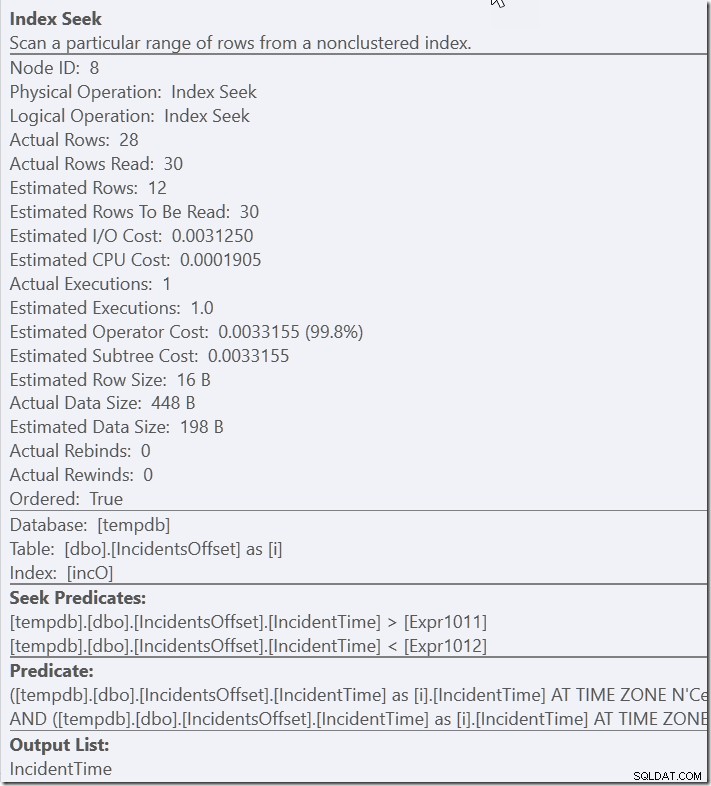
A víte – toto je druh chování, které vidím neustále z běžných dotazů, jako když udělám CAST(myDateTimeColumns AS DATE) =@SomeDate nebo použiji LIKE.
Jsem s tím v pohodě. AT TIME ZONE je skvělé, protože mi umožňuje zpracovávat konverze podle časových pásem, a když zvážím, co se děje s mými dotazy, nemusím obětovat ani výkon.
@rob_farley