
Tento příspěvek je součástí tutoriálu Oracle SQL a budeme diskutovat o analytických funkcích v oracle (přes oddíl) s příklady a podrobným vysvětlením.
Už jsme studovali funkci Oracle Aggregate jako avg, sum, count. Vezměme si příklad
Nejprve vytvoříme ukázková data
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
SQL> desc emp
Name Null? Type
---- ---- -----
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
SQL> desc dept
Name Null? Type
---- ----- ----
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
commit;
insert into emp values( 7839, 'Allen', 'MANAGER', 7839, to_date('17-11-1981','dd-mm-yyyy'), 20, null, 10 );
insert into emp values( 7782, 'CLARK', 'MANAGER', 7839, to_date('9-06-1981','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7934, 'MILLER', 'MANAGER', 7839, to_date('23-01-1982','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7788, 'SMITH', 'ANALYST', 7788, to_date('17-12-1980','dd-mm-yyyy'), 800, null, 20 );
insert into emp values( 7902, 'ADAM, 'ANALYST', 7832, to_date('23-05-1987','dd-mm-yyyy'), 1100, null, 20 );
insert into emp values( 7876, 'FORD', 'ANALYST', 7566, to_date('3-12-1981','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7369, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7698, 'JAMES', 'ANALYST', 7788, to_date('03-12-1981','dd-mm-yyyy'), 950, null, 30 );
insert into emp values( 7499, 'MARTIN', 'ANALYST', 7698, to_date('28-09-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7844, 'WARD', 'ANALYST', 7698, to_date('22-02-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7654, 'TURNER', 'ANALYST', 7698, to_date('08-09-1981','dd-mm-yyyy'), 1500, null, 30 );
insert into emp values( 7521, 'ALLEN', 'ANALYST', 7698, to_date('20-02-1981','dd-mm-yyyy'), 1600, null, 30 );
insert into emp values( 7900, 'BLAKE', 'ANALYST', 77698, to_date('01-05-1981','dd-mm-yyyy'), 2850, null, 30 );
commit;
Nyní bude uveden příklad agregačních funkcí, jak je uvedeno níže
select count(*) from EMP; --------- 13 select sum (bytes) from dba_segments where tablespace_name='TOOLS'; ----- 100 SQL> select deptno ,count(*) from emp group by deptno; DEPTNO COUNT(*) ---------- ---------- 30 6 20 4 10 3
Zde vidíme, že snižuje počet řádků v každém z dotazů. Nyní přichází otázka, co dělat, pokud potřebujeme vrátit všechny řádky s count(*) také
Pro toto orákulum poskytlo sadu analytických funkcí. Abychom vyřešili poslední problém , můžeme napsat jako
select empno ,deptno , count(*) over (partition by deptno) from emp group by deptno;
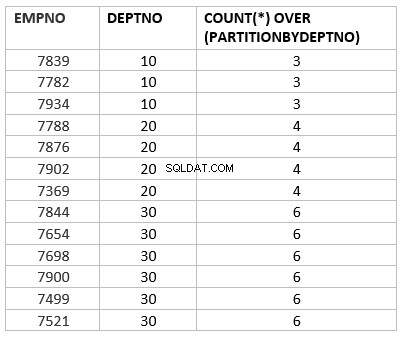
Zde count(*) over (partition by dept_no) je analytická verze funkce count agregace. Hlavní klíčová práce, která se liší agregační funkcí, je přes rozdělení podle
Analytické funkce počítají agregovanou hodnotu na základě skupiny řádků. Od agregačních funkcí se liší tím, že vracejí více řádků pro každou skupinu. Skupina řádků se nazývá okno a je definována klauzulí analytic_clause.
Zde je obecná syntaxe
analytic_function([ arguments ]) OVER ([ query_partition_clause ] [ order_by_clause [ windowing_clause ] ])
Příklad
count(*) over (partition by deptno) avg(Sal) over (partition by deptno)
Pojďme si projít každou část
klauzule_dotazu
Definovala skupinu řádků. Může se to líbit níže
rozdělení podle oddělení :skupina řádků stejného oddělení
nebo
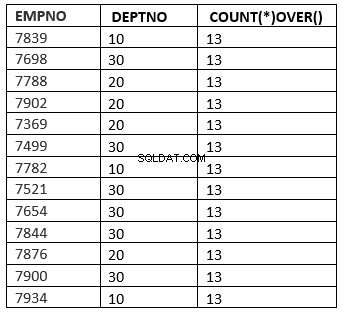
() :Všechny řádky
SQL> select empno ,deptno , count(*) over () from emp;
[ order_by_clause [ windowing_clause ] ]
Tato klauzule se používá, když chcete seřadit řádky v oddílu. To je zvláště užitečné, pokud chcete, aby analytická funkce zvážila pořadí řádků.
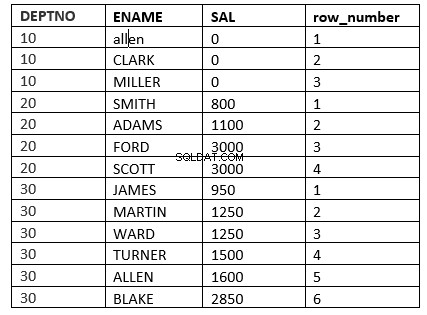
Příkladem bude funkce číslo_řádku
SQL> select deptno, ename, sal, row_number() over (partition by deptno order by sal) "row_number" from emp;
Dalším příkladem by bylo
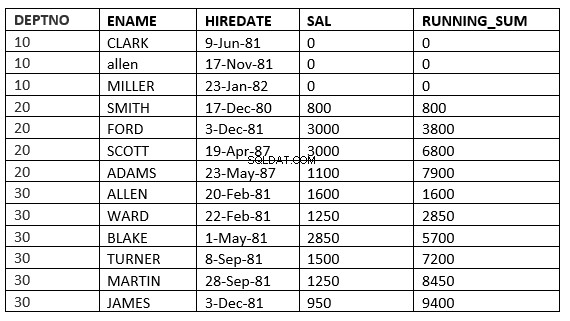
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Windowing_clause
To se vždy používá s klauzulí podle pořadí a poskytuje větší kontrolu nad sadou řádků ve skupině
S klauzulí Windowing je pro každý řádek definováno posuvné okno řádků. Okno určuje rozsah řádků použitých k provedení výpočtů pro aktuální řádek. Velikosti oken mohou být založeny buď na fyzickém počtu řádků, nebo na logickém intervalu, jako je čas.
Když použijete pořadí podle klauzule a pro windowing_clause není uvedeno nic, použije se pod výchozí hodnota windowing_clause
ROZSAH MEZI NEODPOVĚDNÝM PŘEDCHOZÍM A AKTUÁLNÍM ŘÁDKEM nebo ROZSAH NEODPOVĚDNÝ PŘEDCHOZÍM
To znamená „Aktuální a předchozí řádky v aktuálním oddíl jsou řádky, které by měly být použity při výpočtu”
Níže uvedený příklad to jasně říká. To odpovídá běžnému průměru v oddělení
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
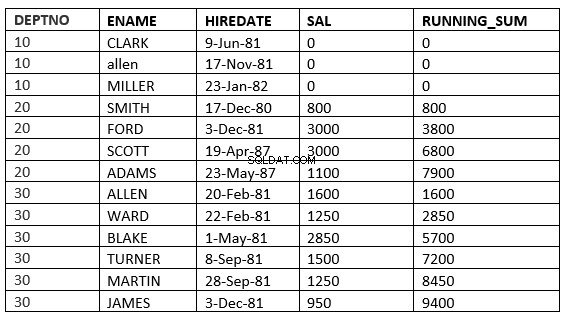
Nyní lze windowing_clause definovat několika způsoby
Nejprve pochopíme terminologii
ŘÁDKY určuje okno ve fyzických jednotkách (řádcích).
RANGE určuje okno jako logický offset. klauzuli okna RANGE lze použít pouze s klauzulemi ORDER BY obsahujícími sloupce nebo výrazy číselných nebo datových typů dat
PŘEDCHOZÍ – získat řádky před aktuálním.
NÁSLEDUJÍCÍ – získat řádky za aktuálním.
NEBOUZENO – při použití s PRECEDING nebo FOLLOWING se vrátí vše před nebo za. AKTUÁLNÍ ŘÁDEK
Obecně se tedy definuje jako
PŘEDCHÁZEJÍCÍ ŘÁDY BEZ OMEZENÍ :Aktuální a předchozí řádky v aktuálním oddílu jsou řádky, které by měly být použity při výpočtu
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS UNBOUNDED PRECEDING) running_sum from emp;
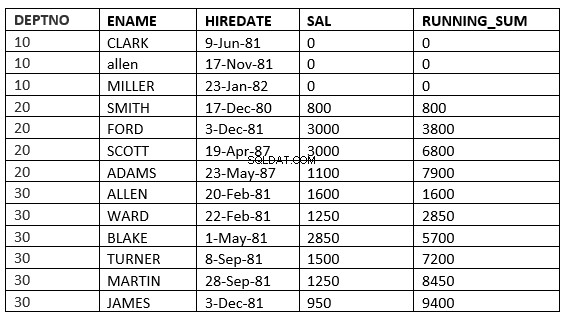
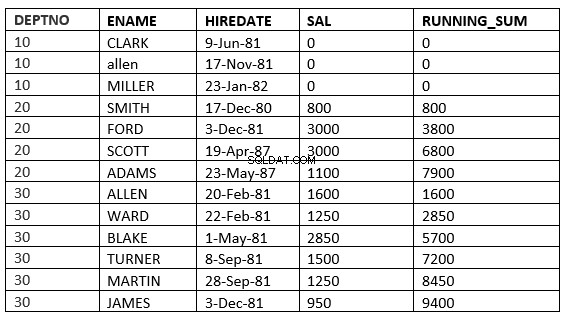
PŘEDCHOZÍ NEOMEZENÝ ROZSAH :Aktuální a předchozí řádky v aktuálním oddílu jsou řádky, které by měly být použity při výpočtu. Vzhledem k tomu, že je zadán rozsah, vše nabývá hodnot, které se rovnají aktuálním řádkům.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE UNBOUNDED PRECEDING) running_sum from emp;
Rozdíl mezi rozsahem a řádky možná neuvidíte, protože datum_nájmu se u všech liší. Rozdíl bude jasnější, když použijeme sal jako objednávku po klauzuli
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal RANGE UNBOUNDED PRECEDING) running_sum from emp;
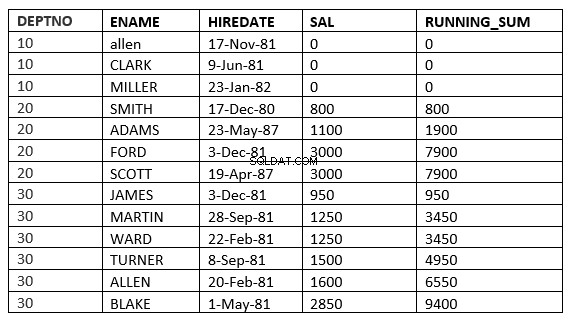
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal ROWS UNBOUNDED PRECEDING) running_sum from emp;
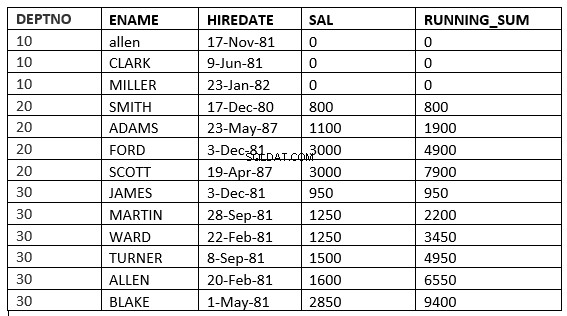
Rozdíl najdete na řádku 6
RANGE value_expr PŘEDCHOZÍ :Okno začíná řádkem, jehož hodnota ORDER BY je řádky číselného výrazu menší než nebo předcházející aktuálnímu řádku, a končí aktuálním zpracovávaným řádkem.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE 365 PRECEDING) running_sum from emp;
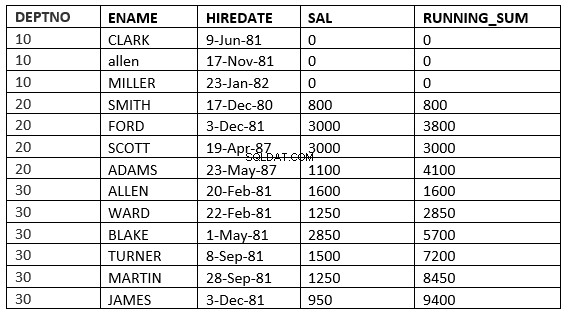
Zde se převezmou všechny řádky, ve kterých hodnota nájemného spadá do 365 dnů předcházejících hodnotě nájemného v aktuálním řádku
ROWS value_expr PŘEDCHOZÍ :Okno začíná daným řádkem a končí aktuálním zpracovávaným řádkem
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS 2 PRECEDING) running_sum from emp;
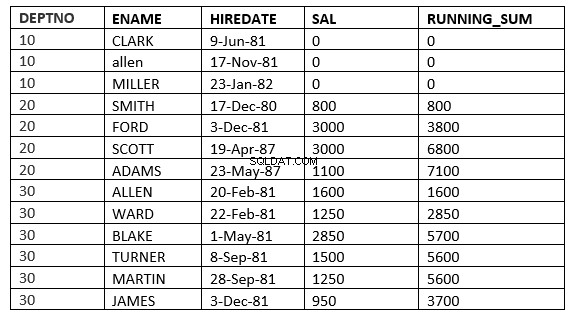
Zde okno začíná od 2 řádků předcházejících aktuálnímu řádku
NÁSLEDUJÍCÍ ROZSAH MEZI AKTUÁLNÍM ŘÁDKEM a value_expr :Okno začíná aktuálním řádkem a končí řádkem, jehož hodnota ORDER BY je řádky číselného výrazu menší než nebo následující
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
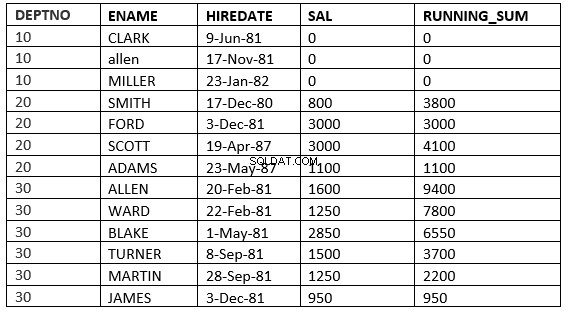
ŘÁDKY MEZI AKTUÁLNÍM ŘÁDKEM a NÁSLEDUJÍCÍ value_expr :Okno začíná aktuálním řádkem a končí řádky po aktuálním řádku
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
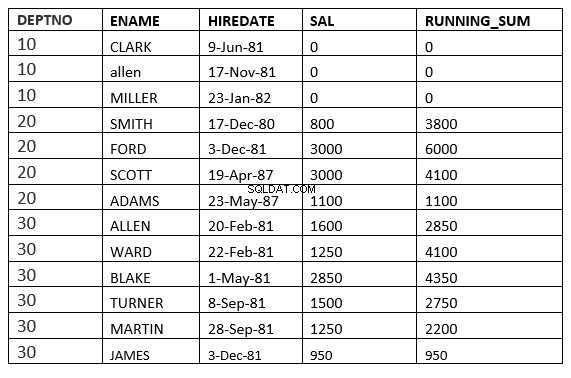
ROZSAH MEZI NEOMEZENÝM PŘEDCHOZÍM A NEOMEZENÝM NÁSLEDUJÍCÍM
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) running_sum from emp;
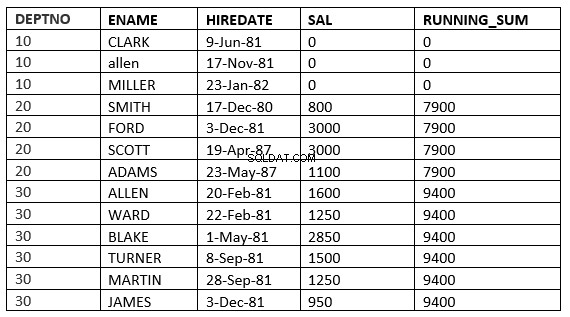
ROZSAH MEZI value_expr PŘEDCHOZÍM a value_expr NÁSLEDUJÍCÍ
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN 365 PRECEDING and 365 FOLLOWING ) running_sum from emp; 2 DEPTNO ENAME HIREDATE SAL RUNNING_SUM ---------- ---------- --------------- ---------- ----------- 10 CLARK 09-JUN-81 0 0 10 ALLEN 17-NOV-81 0 0 10 MILLER 23-JAN-82 0 0 20 SMITH 17-DEC-80 800 3800 20 FORD 03-DEC-81 3000 3800 20 SCOTT 19-APR-87 3000 4100 20 ADAMS 23-MAY-87 1100 4100 30 ALLEN 20-FEB-81 1600 9400 30 WARD 22-FEB-81 1250 9400 30 BLAKE 01-MAY-81 2850 9400 30 TURNER 08-SEP-81 1500 9400 30 MARTIN 28-SEP-81 1250 9400 30 JAMES 03-DEC-81 950 9400 13 rows selected.
Některé důležité poznámky
(1)Analytické funkce jsou poslední sadou operací prováděných v dotazu s výjimkou závěrečné klauzule ORDER BY. Všechna spojení a všechny klauzule WHERE, GROUP BY a HAVING jsou dokončeny před zpracováním analytických funkcí. Proto se analytické funkce mohou objevit pouze ve výběrovém seznamu nebo v klauzuli ORDER BY.
(2)Analytické funkce se běžně používají k výpočtu kumulativních, pohyblivých, centrovaných a vykazovacích agregátů.
Doufám, že se vám líbí toto podrobné vysvětlení analytických funkcí v oracle (over by Partition Clause)
Související články
Funkce LEAD v Oracle
Funkce DENSE v Oracle
Funkce Oracle LISTAGG
Agregace dat pomocí skupinových funkcí
https://docs.oracle.com/cd/E11882_01/ server.112/e41084/functions004.htm