Minulý měsíc jsem zveřejnil výzvu k vytvoření efektivního generátoru číselných řad. Odezvy byly ohromující. Bylo tam mnoho skvělých nápadů a návrhů se spoustou aplikací daleko za hranicemi této konkrétní výzvy. Uvědomil jsem si, jak skvělé je být součástí komunity a že lze dosáhnout úžasných věcí, když spojí síly skupina chytrých lidí. Díky Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason a John Number2 za sdílení vašich nápadů a komentářů.
Původně mě napadlo napsat jen jeden článek, abych shrnul nápady, které lidé předložili, ale bylo jich příliš mnoho. Rozdělím tedy pokrytí do několika článků. Tento měsíc se zaměřím především na vylepšení dvou původních řešení, která jsem zveřejnil minulý měsíc, navrhli Charlie a Alan Burstein ve formě inline TVF s názvem dbo.GetNumsItzikBatch a dbo.GetNumsItzik. Vylepšené verze pojmenuji dbo.GetNumsAlanCharlieItzikBatch a dbo.GetNumsAlanCharlieItzik.
To je tak vzrušující!
Originální Itzikova řešení
Pro rychlé připomenutí, funkce, které jsem probral minulý měsíc, používají základní CTE, který definuje konstruktor hodnot tabulky s 16 řádky. Funkce používají řadu kaskádových CTE, z nichž každý aplikuje produkt (křížové spojení) dvou instancí svého předchozího CTE. Tímto způsobem, s pěti CTE nad rámec základního, můžete získat sadu až 4 294 967 296 řádků. CTE s názvem Nums používá funkci ROW_NUMBER k vytvoření řady čísel začínajících 1. Nakonec vnější dotaz vypočítá čísla v požadovaném rozsahu mezi vstupy @low a @high.
Funkce dbo.GetNumsItzikBatch používá k získání dávkového zpracování fiktivní spojení s tabulkou s indexem columnstore. Zde je kód pro vytvoření fiktivní tabulky:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
A zde je kód definující funkci dbo.GetNumsItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Použil jsem následující kód k otestování funkce s povoleným "Zahodit výsledky po spuštění" v SSMS:
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Zde jsou statistiky výkonu, které jsem získal pro toto provedení:
CPU time = 16985 ms, elapsed time = 18348 ms.
Funkce dbo.GetNumsItzik je podobná, jen nemá fiktivní spojení a běžně se v rámci plánu zpracovává v režimu řádků. Zde je definice funkce:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Zde je kód, který jsem použil k testování funkce:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Zde jsou statistiky výkonu, které jsem získal pro toto provedení:
CPU time = 19969 ms, elapsed time = 21229 ms.
Vylepšení Alana Bursteina a Charlieho
Alan a Charlie navrhli několik vylepšení mých funkcí, některá s mírnými dopady na výkon a některá s dramatičtějšími. Začnu Charlieho zjištěními ohledně režie kompilace a neustálého skládání. Poté se budu zabývat Alanovými návrhy, včetně sekvencí založených na 1 versus @nízce založených sekvencí (také sdílené Charliem a Jeffem Modenem), vyhýbám se zbytečnému řazení a počítám číselný rozsah v opačném pořadí.
Zjištění doby kompilace
Jak poznamenal Charlie, generátor číselných řad se často používá ke generování řad s velmi malým počtem řádků. V těchto případech se doba kompilace kódu může stát podstatnou částí celkové doby zpracování dotazu. To je zvláště důležité při používání iTVF, protože na rozdíl od uložených procedur se neoptimalizuje parametrizovaný kód dotazu, ale kód dotazu po vložení parametru. Jinými slovy, parametry jsou před optimalizací nahrazeny vstupními hodnotami a kód s konstantami se optimalizuje. Tento proces může mít negativní i pozitivní důsledky. Jedním z negativních důsledků je, že získáte více kompilací, protože funkce je volána s různými vstupními hodnotami. Z tohoto důvodu by se rozhodně měly brát v úvahu časy kompilace – zvláště při velmi častém používání funkce s malými rozsahy.
Zde jsou časy kompilace, které Charlie našel pro různé základní kardinality CTE:
2: 22ms 4: 9ms 16: 7ms 256: 35ms
Je zajímavé vidět, že mezi nimi je 16 optimální a že při přechodu na další úroveň, což je 256, dojde k velmi dramatickému skoku. Připomeňme, že funkce dbo.GetNumsItzikBacth a dbo.GetNumsItzik používají základní kardinalitu CTE 16. .
Neustálé skládání
Neustálé skládání je často pozitivním důsledkem, který lze ve správných podmínkách povolit díky procesu vkládání parametrů, který iTVF zažívá. Předpokládejme například, že vaše funkce má výraz @x + 1, kde @x je vstupní parametr funkce. Funkci vyvoláte s @x =5 jako vstup. Vložený výraz se pak změní na 5 + 1, a pokud je vhodný pro konstantní skládání (více o tom brzy), pak se stane 6. Pokud je tento výraz součástí propracovanějšího výrazu obsahujícího sloupce a je aplikován na mnoho milionů řádků, může výsledkem jsou nezanedbatelné úspory cyklů CPU.
Ošemetná část je v tom, že SQL Server je velmi vybíravý v tom, co má neustále skládat a co ne. Například SQL Server nebude konstantní skládání col1 + 5 + 1, ani to nesloží 5 + col1 + 1. Ale složí 5 + 1 + col1 na 6 + col1. Vím. Pokud tedy vaše funkce například vrátila SELECT @x + col1 + 1 AS mycol1 FROM dbo.T1, můžete povolit konstantní skládání s následující malou změnou:SELECT @x + 1 + col1 AS mycol1 FROM dbo.T1. nevěříš mi? Prozkoumejte plány pro následující tři dotazy v databázi PerformanceV5 (nebo podobné dotazy s vašimi daty) a přesvědčte se sami:
SELECT orderid + 5 + 1 AS myorderid FROM dbo.orders; SELECT 5 + orderid + 1 AS myorderid FROM dbo.orders; SELECT 5 + 1 + orderid AS myorderid FROM dbo.orders;
V operátorech Compute Scalar pro tyto tři dotazy jsem získal následující tři výrazy:
[Expr1003] = Scalar Operator([PerformanceV5].[dbo].[Orders].[orderid]+(5)+(1)) [Expr1003] = Scalar Operator((5)+[PerformanceV5].[dbo].[Orders].[orderid]+(1)) [Expr1003] = Scalar Operator((6)+[PerformanceV5].[dbo].[Orders].[orderid])
Vidíte, kam tím mířím? Ve svých funkcích jsem použil následující výraz k definování výsledného sloupce n:
@low + rownum - 1 AS n
Charlie si uvědomil, že s následující malou změnou může umožnit neustálé skládání:
@low - 1 + rownum AS n
Například plán pro dřívější dotaz, který jsem poskytl proti dbo.GetNumsItzik, s @low =1, měl původně následující výraz definovaný operátorem Compute Scalar:
[Expr1154] = Scalar Operator((1)+[Expr1153]-(1))
Po použití výše uvedené drobné změny se výraz v plánu změní na:
[Expr1154] = Scalar Operator((0)+[Expr1153])
To je skvělé!
Pokud jde o důsledky pro výkon, připomeňme, že statistiky výkonu, které jsem získal pro dotaz na dbo.GetNumsItzikBatch před změnou, byly následující:
CPU time = 16985 ms, elapsed time = 18348 ms.
Zde jsou čísla, která jsem dostal po změně:
CPU time = 16375 ms, elapsed time = 17932 ms.
Zde jsou čísla, která jsem dostal pro dotaz proti dbo.GetNumsItzik původně:
CPU time = 19969 ms, elapsed time = 21229 ms.
A zde jsou čísla po změně:
CPU time = 19266 ms, elapsed time = 20588 ms.
Výkon se zlepšil jen o pár procent. Ale počkejte, je toho víc! Pokud potřebujete zpracovat objednaná data, dopady na výkon mohou být mnohem dramatičtější, jak se k tomu dostanu později v části o objednávání.
1 versus @nízká sekvence a čísla opačných řádků
Alan, Charlie a Jeff poznamenali, že ve velké většině případů ze skutečného života, kdy potřebujete řadu čísel, potřebujete, aby začínal 1 nebo někdy 0. Potřeba jiného výchozího bodu je mnohem méně běžné. Mohlo by tedy dávat větší smysl, aby funkce vždy vracela rozsah, který začíná řekněme 1, a když potřebujete jiný počáteční bod, použijte jakékoli výpočty externě v dotazu proti funkci.
Alan vlastně přišel s elegantním nápadem, aby inline TVF vracela jak sloupec, který začíná 1 (prostě přímý výsledek funkce ROW_NUMBER) s aliasem rn, tak sloupec, který začíná @low aliasem jako n. Vzhledem k tomu, že funkce je vložena, když vnější dotaz interaguje pouze se sloupcem rn, sloupec n se ani nevyhodnotí a získáte výhodu výkonu. Když potřebujete, aby sekvence začínala @low, interagujete se sloupcem n a zaplatíte příslušné dodatečné náklady, takže není třeba přidávat žádné explicitní externí výpočty. Alan dokonce navrhl přidat sloupec nazvaný op, který počítá čísla v opačném pořadí, a interagovat s ním pouze v případě potřeby takové sekvence. Sloupec op je založen na výpočtu:@high + 1 – rownum. Tento sloupec má význam, když potřebujete zpracovat řádky v sestupném řazení podle čísel, jak ukážu později v části pro řazení.
Aplikujme tedy Charlieho a Alanova vylepšení na mé funkce.
U verze v dávkovém režimu se ujistěte, že nejprve vytvoříte fiktivní tabulku s indexem columnstore, pokud již není přítomen:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Poté použijte pro funkci dbo.GetNumsAlanCharlieItzikBatch následující definici:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Zde je příklad použití funkce:
SELECT * FROM dbo.GetNumsAlanCharlieItzikBatch(-2, 3) AS F ORDER BY rn;
Tento kód generuje následující výstup:
rn op n --- --- --- 1 3 -2 2 2 -1 3 1 0 4 0 1 5 -1 2 6 -2 3
Dále otestujte výkon funkce se 100 miliony řádků, nejprve vraťte sloupec n:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Zde jsou statistiky výkonu, které jsem získal pro toto provedení:
CPU time = 16375 ms, elapsed time = 17932 ms.
Jak můžete vidět, oproti dbo.GetNumsItzikBatch došlo k malému zlepšení jak v CPU, tak v uplynulém čase díky neustálému skládání, ke kterému zde docházelo.
Otestujte funkci, ale tentokrát vrátí sloupec rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Zde jsou statistiky výkonu, které jsem získal pro toto provedení:
CPU time = 15890 ms, elapsed time = 18561 ms.
Čas CPU se dále snížil, i když se zdá, že uplynulý čas se při tomto provádění o něco zvýšil ve srovnání s dotazem na sloupec n.
Obrázek 1 obsahuje plány pro oba dotazy.
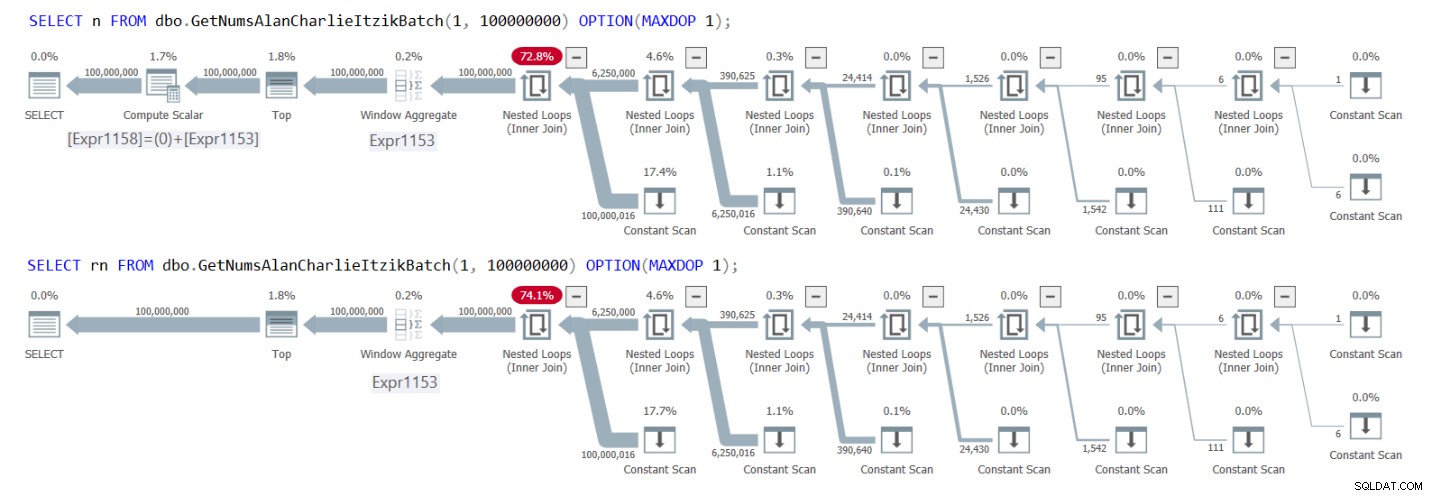 Obrázek 1:Plány pro GetNumsAlanCharlieItzikBatch s návratem n versus rn
Obrázek 1:Plány pro GetNumsAlanCharlieItzikBatch s návratem n versus rn
V plánech můžete jasně vidět, že při interakci se sloupcem rn není potřeba další operátor Compute Scalar. V prvním plánu si také všimněte výsledku neustálého skládání, které jsem popsal dříve, kde @low – 1 + rownum bylo vloženo do 1 – 1 + rownum a poté složeno do 0 + rownum.
Zde je definice verze funkce v režimu řádků s názvem dbo.GetNumsAlanCharlieItzik:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzik(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum; K otestování funkce použijte následující kód, nejprve se dotazujte na sloupec n:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Zde jsou statistiky výkonu, které jsem získal:
CPU time = 19047 ms, elapsed time = 20121 ms.
Jak můžete vidět, je to o něco rychlejší než dbo.GetNumsItzik.
Dále zadejte dotaz na sloupec rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Čísla výkonu se dále zlepšují jak na CPU, tak na frontách uplynulého času:
CPU time = 17656 ms, elapsed time = 18990 ms.
Úvahy o objednávce
Výše zmíněná vylepšení jsou jistě zajímavá a dopad na výkon je nezanedbatelný, ale nepříliš významný. Mnohem dramatičtější a hlubší dopad na výkon lze pozorovat, když potřebujete zpracovat data uspořádaná podle číselného sloupce. To by mohlo být stejně jednoduché jako potřeba vrátit objednané řádky, ale je to stejně důležité pro jakékoli zpracování založené na objednávce, např. operátor Stream Aggregate pro seskupování a agregaci, algoritmus Merge Join pro spojení a tak dále.
Při dotazu na dbo.GetNumsItzikBatch nebo dbo.GetNumsItzik a řazení podle n si optimalizátor neuvědomuje, že základní výraz řazení @low + rownum – 1 zachovává pořadí s ohledem na rownum. Důsledek je trochu podobný výrazu filtrování bez SARGable, pouze s výrazem řazení to má za následek explicitní operátor řazení v plánu. Další řazení ovlivňuje dobu odezvy. Ovlivňuje také změnu měřítka, která se obvykle stává n log n namísto n.
Chcete-li to demonstrovat, dotazujte se dbo.GetNumsItzikBatch a požádejte o sloupec n, seřazený podle n:
SELECT n FROM dbo.GetNumsItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Mám následující statistiky výkonu:
CPU time = 34125 ms, elapsed time = 39656 ms.
Doba běhu je více než dvojnásobná ve srovnání s testem bez klauzule ORDER BY.
Otestujte funkci dbo.GetNumsItzik podobným způsobem:
SELECT n FROM dbo.GetNumsItzik(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Pro tento test jsem dostal následující čísla:
CPU time = 52391 ms, elapsed time = 55175 ms.
Také zde je doba běhu více než dvojnásobná ve srovnání s testem bez klauzule ORDER BY.
Obrázek 2 obsahuje plány pro oba dotazy.
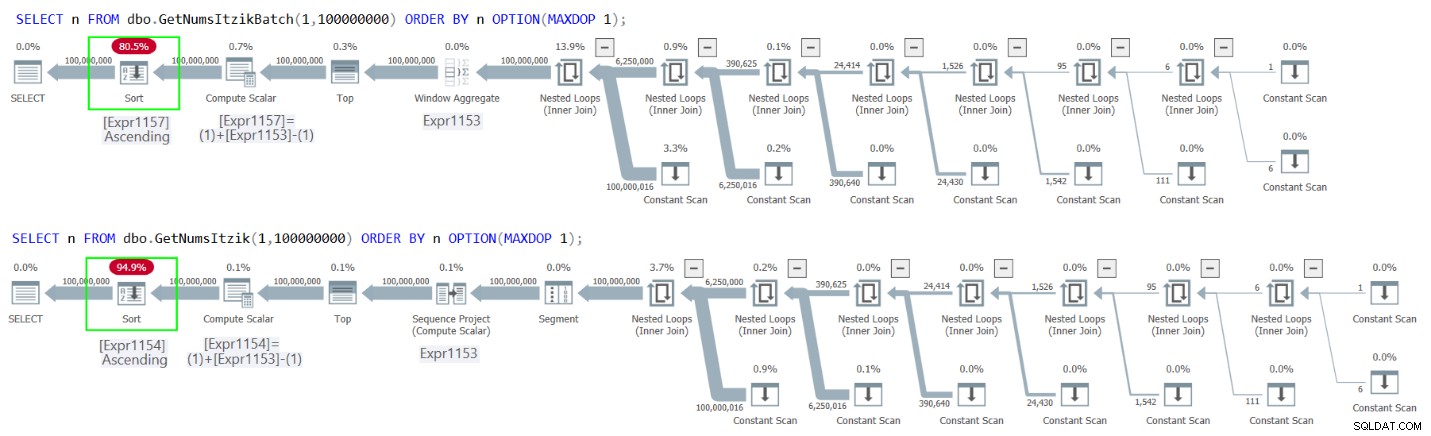 Obrázek 2:Plány pro objednávky GetNumsItzikBatch a GetNumsItzik podle n
Obrázek 2:Plány pro objednávky GetNumsItzikBatch a GetNumsItzik podle n
V obou případech můžete v plánech vidět explicitní operátor řazení.
Při dotazování na dbo.GetNumsAlanCharlieItzikBatch nebo dbo.GetNumsAlanCharlieItzik a objednávání podle rn nemusí optimalizátor do plánu přidávat operátor řazení. Mohli byste tedy vrátit n, ale seřadit podle rn, a tímto způsobem se vyhnout řazení. Co je však trochu šokující – a myslím to v dobrém slova smyslu – je to, že revidovaná verze n, která zažívá neustálé skládání, zachovává pořádek! Pro optimalizátora je snadné si uvědomit, že 0 + rownum je výraz zachovávající pořadí s ohledem na rownum, a vyhnout se tak řazení.
Zkus to. Dotaz dbo.GetNumsAlanCharlieItzikBatch, vrácení n a řazení podle n nebo rn, například takto:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Dostal jsem následující čísla výkonu:
CPU time = 16500 ms, elapsed time = 17684 ms.
To je samozřejmě díky tomu, že v plánu nebyl potřeba operátor Sort.
Spusťte podobný test proti dbo.GetNumsAlanCharlieItzik:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Mám následující čísla:
CPU time = 19546 ms, elapsed time = 20803 ms.
Obrázek 3 obsahuje plány pro oba dotazy:
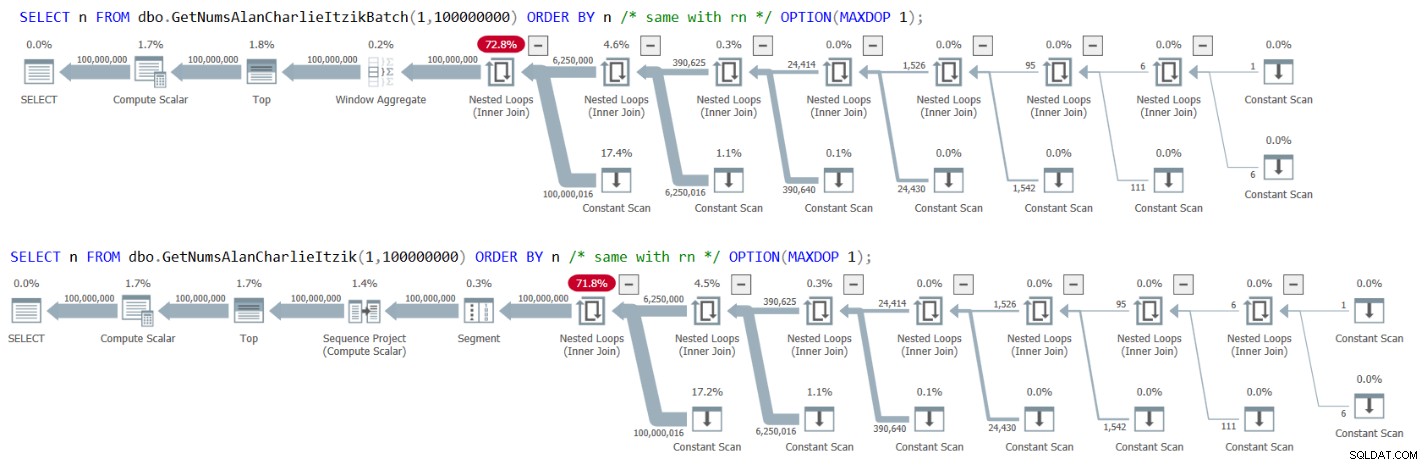
Obrázek 3:Plány pro GetNumsAlanCharlieItzikBatch a GetNumsAlanCharlie
Všimněte si, že v plánech není žádný operátor řazení.
Nutí vás zpívat…
All you need is constant folding All you need is constant folding All you need is constant folding, constant folding Constant folding is all you need
Děkuji Charlie!
Co když ale potřebujete čísla vrátit nebo zpracovat v sestupném pořadí? Zjevným pokusem je použít ORDER BY n DESC nebo ORDER BY rn DESC, podobně:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n DESC OPTION(MAXDOP 1); SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY rn DESC OPTION(MAXDOP 1);
Bohužel však oba případy vedou k explicitnímu řazení v plánech, jak ukazuje obrázek 4.
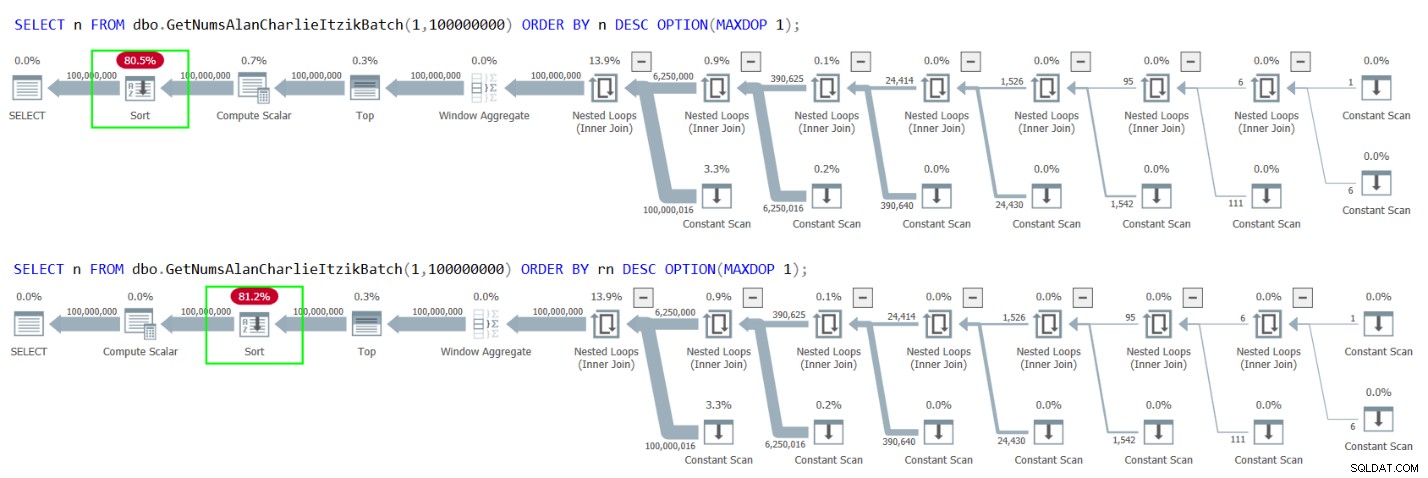 Obrázek 4:Plány pro GetNumsAlanCharlieItzikBatch řazení podle n nebo rn sestupně
Obrázek 4:Plány pro GetNumsAlanCharlieItzikBatch řazení podle n nebo rn sestupně
Tady se Alanův chytrý trik se sloupovou operací stává zachráncem. Vraťte sloupec op při řazení buď o n nebo rn, například takto:
SELECT op FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Plán pro tento dotaz je znázorněn na obrázku 5.
 Obrázek 5:Plán pro GetNumsAlanCharlieItzikBatch vracení operace a objednávání ukončením n nebo rn vzestupně em>
Obrázek 5:Plán pro GetNumsAlanCharlieItzikBatch vracení operace a objednávání ukončením n nebo rn vzestupně em>
Data získáte zpět seřazená podle n sestupně a v plánu není potřeba žádné řazení.
Děkuji Alane!
Přehled výkonu
Co jsme se tedy z toho všeho naučili?
Čas kompilace může být faktorem, zejména při častém používání funkce s malými rozsahy. Na logaritmické stupnici se základem 2 se sladkých 16 zdá být pěkné magické číslo.
Pochopte zvláštnosti neustálého skládání a využijte je ve svůj prospěch. Pokud má iTVF výrazy, které zahrnují parametry, konstanty a sloupce, umístěte parametry a konstanty do úvodní části výrazu. To zvýší pravděpodobnost skládání, sníží režii CPU a zvýší pravděpodobnost zachování objednávky.
Je v pořádku mít v iTVF více sloupců, které se používají pro různé účely, a dotazovat se na ty relevantní v každém případě, aniž byste se museli obávat, že zaplatíte za ty, na které se neodkazuje.
Pokud potřebujete vrátit číselnou řadu v opačném pořadí, použijte původní sloupec n nebo rn v klauzuli ORDER BY se vzestupným pořadím a vraťte sloupec op, který vypočítá čísla v obráceném pořadí.
Obrázek 6 shrnuje výkonová čísla, která jsem získal v různých testech.
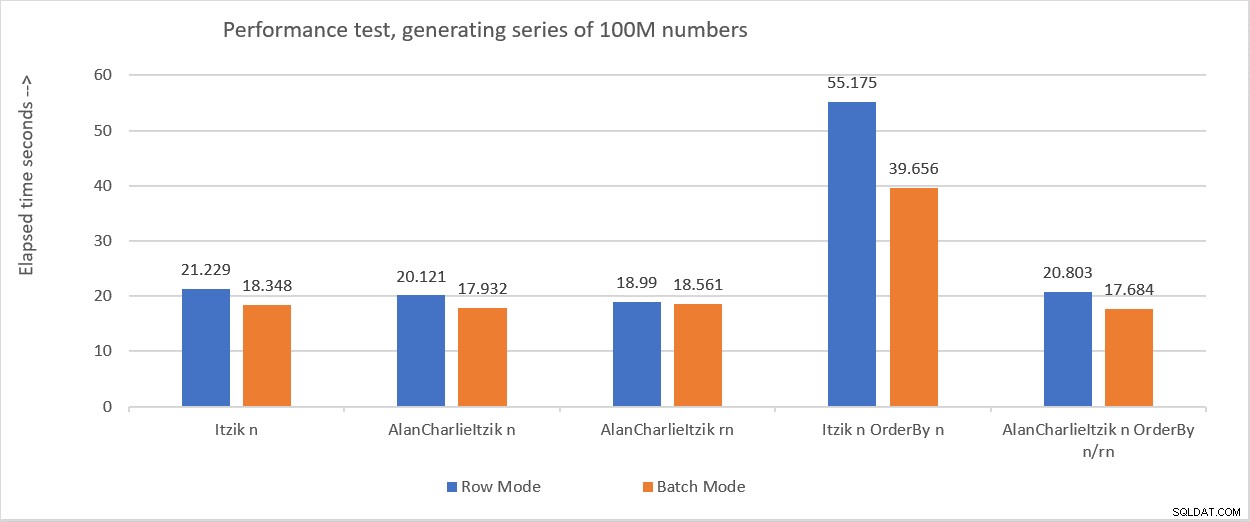 Obrázek 6:Přehled výkonu
Obrázek 6:Přehled výkonu
Příští měsíc budu pokračovat ve zkoumání dalších nápadů, postřehů a řešení výzvy generátoru číselných řad.