Autor hosta :Michael J Swart (@MJSwart)
Trávím velké množství času převáděním softwarových požadavků do schématu a dotazů. Tyto požadavky lze někdy snadno implementovat, ale často jsou obtížné. Chci mluvit o možnostech návrhu uživatelského rozhraní, které vedou ke vzorům přístupu k datům, které je obtížné implementovat pomocí SQL Server.
Řadit podle sloupce
Sort-By-Column je tak známý vzorec, že jej můžeme považovat za samozřejmost. Pokaždé, když pracujeme se softwarem, který zobrazuje tabulku, můžeme očekávat, že sloupce budou seřadit takto:
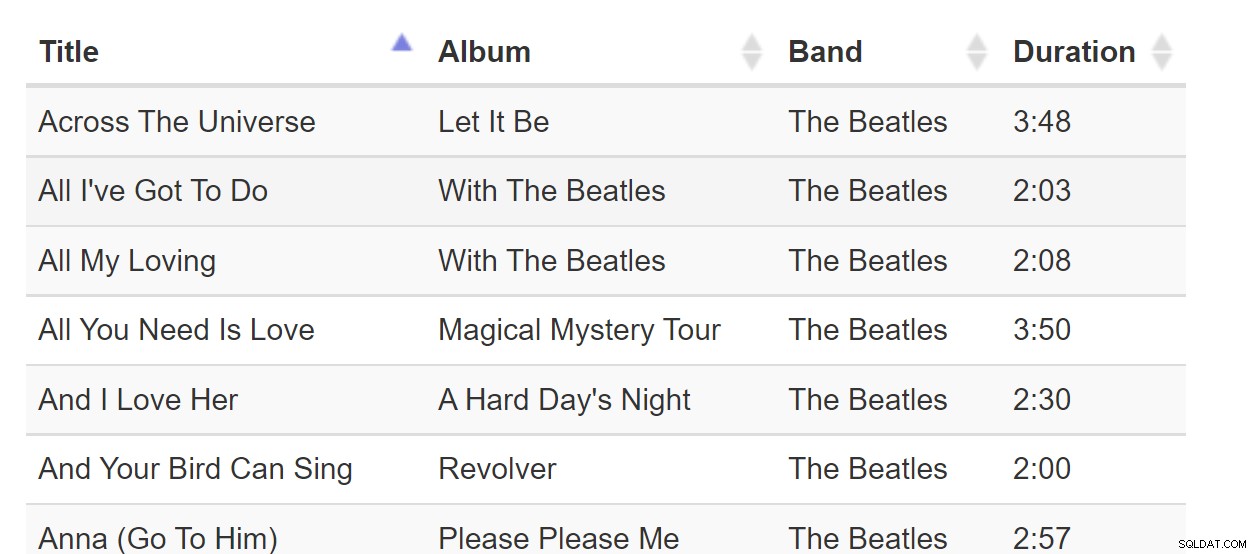
Sort-By-Colunn je skvělý vzor, když se všechna data vejdou do prohlížeče. Pokud je však datová sada velká na miliardy řádků, může to být nepříjemné, i když webová stránka vyžaduje pouze jednu stránku dat. Zvažte tuto tabulku skladeb:
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band); A zvažte tyto čtyři dotazy seřazené podle jednotlivých sloupců:
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
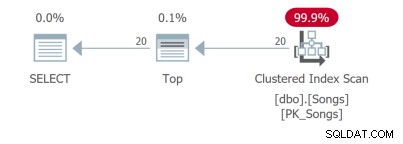
I pro takto jednoduchý dotaz existují různé plány dotazů. První dva dotazy používají krycí indexy:
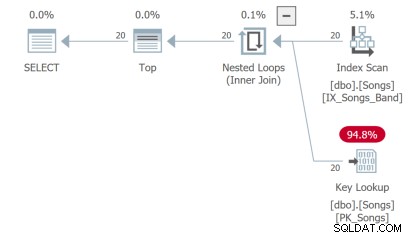
Třetí dotaz musí provést vyhledávání klíčů, což není ideální:
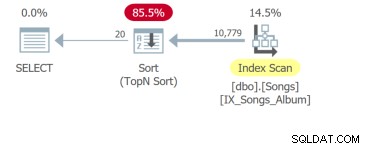
Ale nejhorší je čtvrtý dotaz, který potřebuje prohledat celou tabulku a seřadit, aby vrátil prvních 20 řádků:
Jde o to, že i když jediným rozdílem je klauzule ORDER BY, tyto dotazy je třeba analyzovat samostatně. Základní jednotkou ladění SQL je dotaz. Pokud mi tedy ukážete požadavky na uživatelské rozhraní s deseti seřaditelnými sloupci, ukážu vám deset dotazů k analýze.
Kdy to může být nepříjemné?
Funkce Sort-By-Column je skvělý vzor uživatelského rozhraní, ale může být nepohodlný, pokud data pocházejí z obrovské rostoucí tabulky s mnoha a mnoha sloupci. Může být lákavé vytvořit krycí indexy na každém sloupci, ale to má další kompromisy. Indexy Columnstore mohou za určitých okolností pomoci, ale to představuje další úroveň nešikovnosti. Ne vždy existuje snadná alternativa.
Stránkované výsledky
Použití stránkovaných výsledků je dobrý způsob, jak nezahltit uživatele příliš velkým množstvím informací najednou. Je to také dobrý způsob, jak nezahltit databázové servery... obvykle.
Zvažte tento design:

Data za tímto příkladem vyžadují počítání a zpracování celé datové sady, aby bylo možné uvést počet výsledků. Dotaz pro tento příklad může používat následující syntaxi:
... ORDER BY LastModifiedTime OFFSET @N ROWS FETCH NEXT 25 ROWS ONLY;
Je to pohodlná syntaxe a dotaz vytváří pouze 25 řádků. Ale to, že je výsledná sada malá, nemusí nutně znamenat, že je levná. Stejně jako jsme viděli u vzoru Sort-By-Column, TOP operátor je levný pouze tehdy, když nepotřebuje nejprve třídit velké množství dat.
Asynchronní požadavky na stránky
Když uživatel přechází z jedné stránky výsledků na další, mohou být příslušné webové požadavky odděleny sekundami nebo minutami. To vede k problémům, které vypadají hodně jako úskalí, která se vyskytují při používání NOLOCK. Například:
SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY; -- wait a little bit SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 25 ROWS FETCH NEXT 25 ROWS ONLY;
Když je mezi dva požadavky přidán řádek, uživatel může vidět stejný řádek dvakrát. A pokud je řádek odstraněn, uživatel může při procházení stránek řádek vynechat. Tento vzor stránkovaných výsledků je ekvivalentní „Dej mi řádky 26–50“. Když by skutečná otázka měla znít „Dej mi dalších 25 řádků“. Rozdíl je nepatrný.
Lepší vzory
Se stránkovanými výsledky může „OFFSET @N ROWS“ trvat déle a déle, jak @N roste. Místo toho zvažte tlačítka Load-More nebo Infinite-Scrolling. Díky stránkování Load-More existuje alespoň šance na efektivní využití indexu. Dotaz by vypadal nějak takto:
SELECT [Some Columns] FROM [Some Table] WHERE [Sort Value] > @Bookmark ORDER BY [Sort Value] FETCH NEXT 25 ROWS ONLY;
Stále trpí některými úskalími asynchronních požadavků na stránky, ale kvůli záložce bude uživatel pokračovat tam, kde skončil.
Hledání textu pro podřetězec
Hledání je všude na internetu. Ale jaké řešení by se mělo použít na zadní straně? Chci varovat před hledáním podřetězce pomocí filtru LIKE serveru SQL Server se zástupnými znaky, jako je tento:
SELECT Title, Category FROM MyContent WHERE Title LIKE '%' + @SearchTerm + '%';
Může to vést k nepříjemným výsledkům, jako je tento:
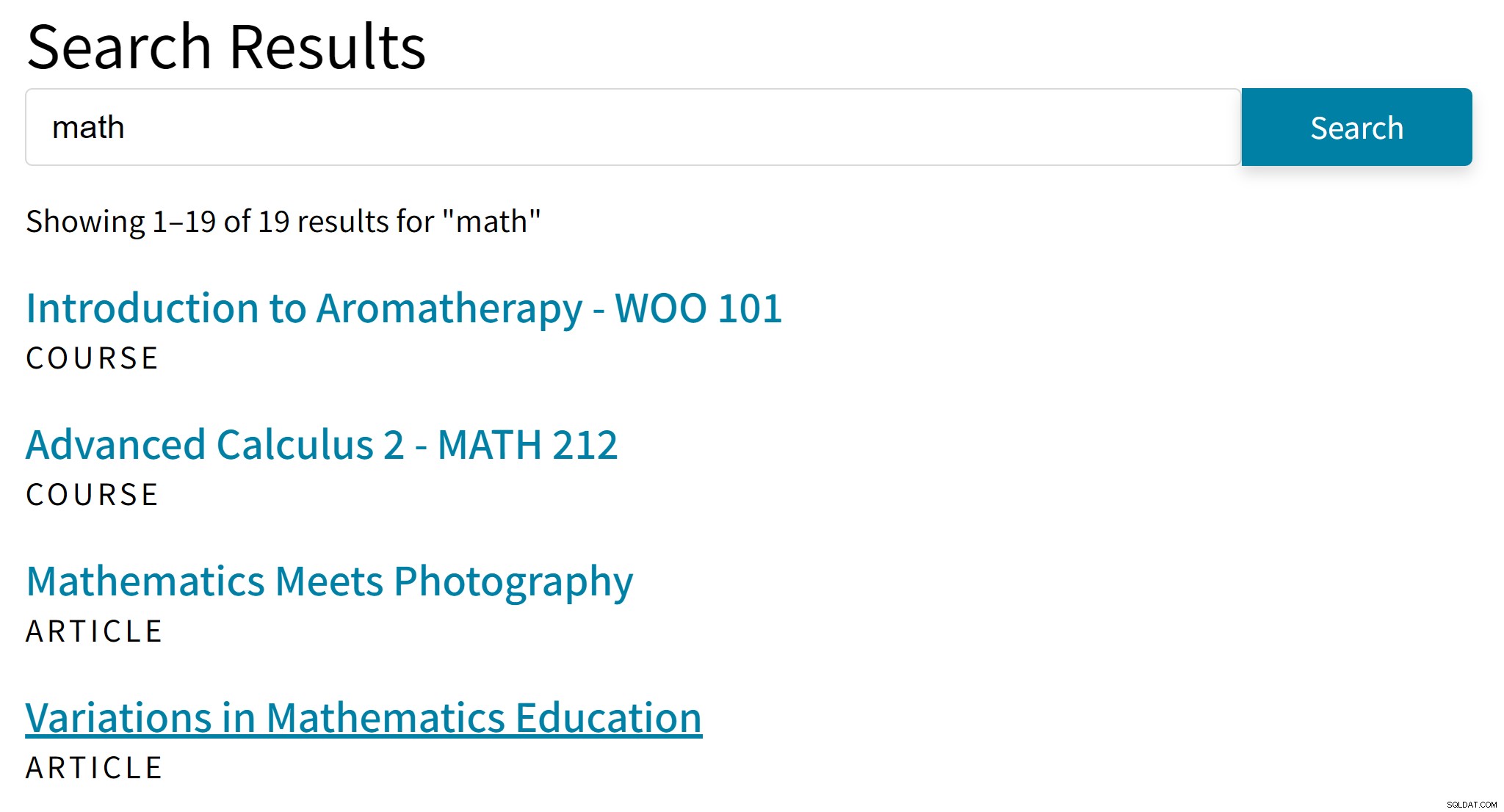
„Aromaterapie“ pravděpodobně není dobrým hitem pro hledaný výraz „matematika“. Mezitím ve výsledcích vyhledávání chybí články, které zmiňují pouze algebru nebo trigonometrii.
Může být také velmi obtížné efektivně pracovat s SQL Serverem. Neexistuje žádný přímý index, který by podporoval tento druh vyhledávání. Paul White poskytl jedno složité řešení s Trigram Wildcard String Search na SQL Server. Existují také potíže, které mohou nastat s porovnáváním a Unicode. Může se stát drahým řešením pro nepříliš dobrou uživatelskou zkušenost.
Co použít místo toho
Zdá se, že fulltextové vyhledávání SQL Serveru by mohlo pomoci, ale osobně jsem ho nikdy nepoužil. V praxi jsem zaznamenal úspěch pouze v řešeních mimo SQL Server (např. Elasticsearch).
Závěr
Ze své zkušenosti jsem zjistil, že návrháři softwaru jsou často velmi vnímaví ke zpětné vazbě, že implementace jejich návrhů bude někdy nepohodlná. Když nejsou, zjistil jsem, že je užitečné upozornit na úskalí, náklady a dobu dodání. Tento druh zpětné vazby je nezbytný pro vytváření udržitelných a škálovatelných řešení.
O autorovi
 Michael J Swart je vášnivý databázový profesionál a blogger, který se zaměřuje na vývoj databází a softwarovou architekturu. Rád mluví o čemkoli, co souvisí s daty, přispívá do komunitních projektů. Michael bloguje jako „Database Whisperer“ na michaeljswart.com.
Michael J Swart je vášnivý databázový profesionál a blogger, který se zaměřuje na vývoj databází a softwarovou architekturu. Rád mluví o čemkoli, co souvisí s daty, přispívá do komunitních projektů. Michael bloguje jako „Database Whisperer“ na michaeljswart.com.