Úvod
V tomto článku budeme hovořit o použití nvarchar datový typ. Prozkoumáme, jak SQL Server ukládá tento datový typ na disk a jak je zpracováván v paměti RAM. Také prozkoumáme, jak může velikost nvarchar ovlivnit výkon.
Skutečná velikost dat:nchar vs nvarchar
Používáme nvarchar kdy se velikost datových položek sloupců pravděpodobně bude značně lišit. Velikost úložiště (v bajtech) je dvakrát větší než skutečná délka zadávaných dat + 2 bajty. To nám umožňuje ušetřit místo na disku ve srovnání s použitím nchar datový typ. Uvažujme o následujícím příkladu. Vytváříme dvě tabulky. Jedna tabulka obsahuje sloupec nvarchar, další tabulka obsahuje sloupce nchar. Velikost sloupce je 2000 znaků (4000 bajtů).
CREATE TABLE dbo.testnvarchar (
col1 NVARCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnvarchar (col1)
SELECT
REPLICATE('&', 10)
GO
CREATE TABLE dbo.testnchar (
col1 NCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnchar (col1)
SELECT
REPLICATE('&', 10)
GO
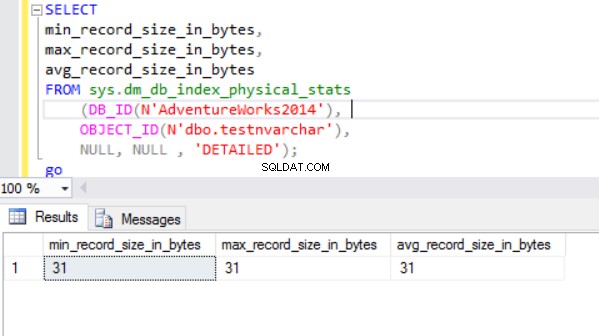
Skutečná velikost řádku je:
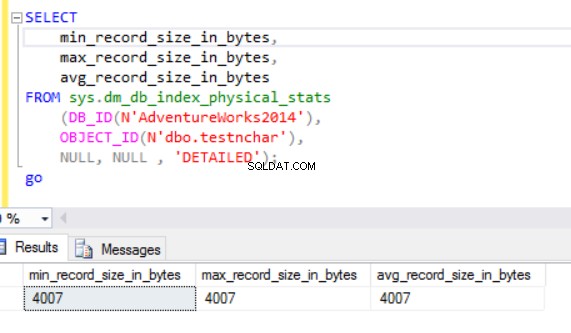
Jak vidíme, skutečná velikost řádku datového typu nvarchar je mnohem menší než datového typu nchar. V případě datového typu nchar používáme ~4000 bajtů k uložení 10 znaků znakového řetězce. Používáme ~20 bajtů k uložení stejného znakového řetězce v případě datového typu nvarchar.
Modul SQL Server zpracovává data do paměti RAM (fondu vyrovnávacích pamětí). A co velikost řádku v paměti?
Skutečná velikost dat:HDD vs RAM
Proveďme následující dotaz:
SELECT col1 FROM dbo.testnchar;

V případě řetězce znaků s pevnou délkou není žádný rozdíl mezi využitím disku a RAM.
SELECT col1 FROM dbo.testnvarchar;

Vidíme, že SQL Server Engine požadoval paměť pouze pro polovinu deklarované velikosti řádku (2000 bajtů místo skutečných 20 bajtů) a několik bajtů pro dodatečné informace. Na jednu stranu snížíme využití místa na disku, ale na druhou stranu můžeme nafouknout požadovanou RAM. To je vedlejší efekt používání různých datových typů znaků. Tento vedlejší efekt může v některých případech vážně ovlivnit zdroje.
FORMAT():Požadovaná RAM vs. využitá RAM
Používáme funkci FORMAT, která vrací naformátovanou hodnotu se zadaným formátem a volitelnou kulturou. Vrácená hodnota je nvarchar nebo null. Délka návratové hodnoty je určena formátem . FORMAT(getdate(), ‚yyyyMMdd‘,‘en-US‘) bude mít za následek ‚20170412‘. K uložení tohoto výsledku do sloupce na disku potřebujeme 16 bajtů (výsledkem bude nvarchar(8)). Jaká je velikost dat v paměti RAM pro konkrétní data?
Proveďme následující dotaz. Používáme následující prostředí:
- AdventureWorks2014
- Vývojová edice MS SQL 2016
- dbo.Customer (19 820 000 záznamů) obsahuje data z Sales.Customer (19 820 záznamů bylo nahráno 1000krát)):
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,FORMAT([modifieddate], 'yyyyMMdd', 'en-US') AS md
,' ' AS code INTO #tmp
FROM rs
Plán provádění dotazu je poměrně jednoduchý:

První operací je „Clustered index scan“ v tabulce dbo.Customer. Bylo přečteno ~19 000 000 záznamů. Odhadovaná velikost dat je 435 Mb.
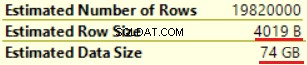
Další operací je „Compute Scalar“ (výpočet funkce FORMAT()). Výsledek je zcela neočekávaný, protože formátujeme 16bajtový znakový řetězec. Velikost řádku se dramaticky zvýšila z 23 bajtů na 4019 bajtů. Totéž s odhadovanou velikostí dat — od 435 MB do 74 GB. Vidíme, že FORMAT() vrací NVARCHAR(4000).
MS SQL Server 2016 má skvělou schopnost ukázat nadměrné přidělení paměti. Varování můžeme vidět v poslední operaci (T-SQL SELECT INTO):
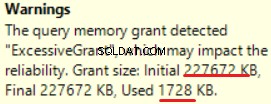
Toto je „nadměrně uděleno“ paměti:více než 90 % přidělené paměti není využito.
Statistiky doby dotazu jsou:
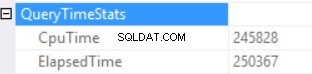
Dlouhá doba provádění závisí na neefektivním provádění skalární funkce a zpětném vedlejším efektu udělení nadměrné paměti – hash Match (pravé vnější spojení). Máme kumulativní účinek dvou různých příčin:vícenásobné provádění skalárních funkcí a nadměrné přidělení paměti.
Stroj SQL Server může udělit více než 25 % povolené paměti na dotaz. Tuto částku můžeme změnit v podnikové edici MS SQL Server pomocí správce prostředků. Udělená paměť se skládá ze dvou částí:povinné a dodatečné. Potřebná paměť je využívána pro interní potřeby – pro operace řazení a hash join. Další paměť je založena na odhadované velikosti dat. Pokud požadovaná i další paměť překročí limit 25 %, stroj SQL Server udělí dalších 25 % dostupné paměti. Podrobnosti naleznete v příspěvku o přidělení paměti serveru SQL Server.
Proveďme stejný dotaz bez funkce FORMAT().
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,' ' AS code INTO #tmp
FROM rs
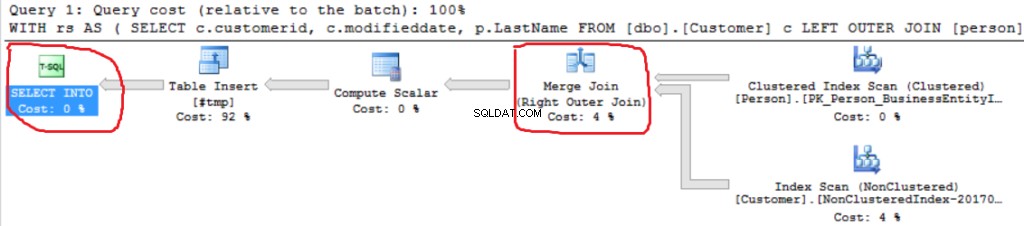
Můžeme vidět další implementaci Right Outer Join (Merge Join namísto Hash Join).
Informace o přidělení paměti jsou (pokud žádné řazení a Hash Join SQL Server nemůže udělit žádnou paměť):
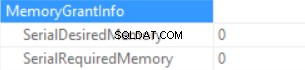
Čas dotazu Statistiky jsou (čas se předvídatelně zkrátí:žádná skalární funkce, odhadovaná velikost dat je menší než v předchozím vzorku):

Nafukujeme tedy „přidělenou paměť“ až na 222 MB (a využíváme z ní méně než 2 MB) pomocí funkce FORMAT(). Objem dat v příkladu je malý.
Dlouhé provádění dotazu
Zvažte skutečný SQL dotaz z produkčního prostředí. Tento dotaz byl proveden během procesu dávkového načítání (nikoli klasický transakční scénář). Používáme MS SQL Server spuštěný na Amazon Web Services (AWS, Amazon Relational Database Service). Charakteristiky instance DB jsou 160 GB RAM (na jeden dotaz nelze přidělit více než ~30 GB RAM) a 40 vCPU. SQL dotaz byl téměř stejný jako výše uvedený příklad (rozdíl je v počtu tabulek a velikosti dat):CTE zahrnovalo spojení mezi 6 tabulkami. "Hlavní tabulka" (tabulka v klauzuli FROM) obsahuje ~175'000'000 záznamů a velikost dat je 20 GB. Vyhledávací tabulky (pravá tabulka v klauzuli JOIN) jsou malé (ve srovnání s hlavní tabulkou). SQL dotaz obsahuje dvě volání funkce FORMAT() (parametrem této funkce jsou dva sloupce z tabulky „master table“).
Produkční dotaz vypadá takto:
;WITH rs AS ( SELECT <in column list>, c.modifieddate, c.createddate FROM [Master table] c LEFT OUTER JOIN [table1 ] p1 ON … LEFT OUTER JOIN [table2 ] p2 ON … LEFT OUTER JOIN [table3 ] p3 ON … LEFT OUTER JOIN [table4 ] p4 ON … LEFT OUTER JOIN [table5 ] p5 ON … ) SELECT DISTINT <out column list>, FORMAT([modifieddate], 'yyyyMMdd','en-US') AS md, FORMAT([createddate], 'yyyyMMdd','en-US') AS cd INTO #tmp FROM rs
„Obrázek“ prováděcího plánu je níže (plán provádění je jednoduchý:sekvenční spojení a řazení (ODLIŠNÁ klíčová slova) nahoře):

Pojďme si tyto informace podrobně prozkoumat.
První operací je „Skenování tabulky“ (vše je v pořádku, žádná překvapení):

Operace „Scalar compute“ dramaticky zvyšuje odhadovanou velikost řádku i odhadovanou velikost řádku (z 19 GB až na 1,3 TB). Dvě volání funkce FORMAT() přidala asi 8000 bajtů k odhadované velikosti řádku (ale skutečná velikost dat je menší).

Jedna z operací JOIN (Hash Match, Right Outer Join) používá nejedinečné sloupce z pravé tabulky. V případě pár záznamů to nevadí. To není náš případ. V důsledku toho se odhadovaná velikost dat zvyšuje až na ~2,4 TB.

Je zde také varování (není dostatek paměti RAM ke zpracování této operace):
SQL dotaz obsahuje nahoře operaci „Distinct Sort“, která vypadá jako třešnička na dortu. Můžeme tam vidět stejné varování.
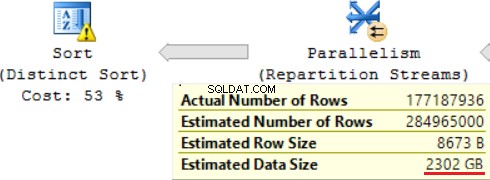
Výsledkem použití skalární funkce je dlouhá doba pro provedení dotazu:24 hodin. Jednou z příčin tohoto problému je nesprávný odhad požadované velikosti dat na základě „Odhadované velikosti dat“. Bez použití funkce FORMAT() provede MS SQL Server tento dotaz za 2 hodiny.
Závěr
Vývojáři by měli být opatrní při používání datových typů nvarchar a varchar. Výběr redundantních datových typů pro sloupce může vést k nafouknutí požadované paměti. V důsledku toho dojde k plýtvání RAM a snížení výkonu databáze.