Úvod
V tomto článku se budeme zabývat tím, jak různé typy indexů v tabulkách SQL Server s optimalizovanou pamětí ovlivňují výkon. Prozkoumáme příklady toho, jak mohou různé typy indexů ovlivnit výkon tabulek optimalizovaných pro paměť.
Pro usnadnění diskuse k tématu použijeme poměrně rozsáhlý příklad. Pro účely jednoduchosti bude tento příklad obsahovat různé repliky jedné tabulky, proti kterým budeme spouštět různé dotazy. Tyto repliky budou používat různé indexy nebo žádné indexy (samozřejmě kromě primárních klíčů – PK).
Všimněte si, že skutečným účelem tohoto článku není porovnávat výkon mezi tabulkami založenými na disku a tabulkami optimalizovanými pro paměť v SQL Server per se. Jeho účelem je prozkoumat, jak indexy ovlivňují výkon v tabulkách optimalizovaných pro paměť. Abychom však měli úplný obrázek o experimentech, jsou uvedeny také časování pro odpovídající dotazy na diskové tabulky a zrychlení jsou počítána s použitím nejoptimálnější konfigurace diskových tabulek jako výchozích hodnot.
Scénář
Ukázková data pro náš scénář jsou založena na jediné tabulce definované takto:
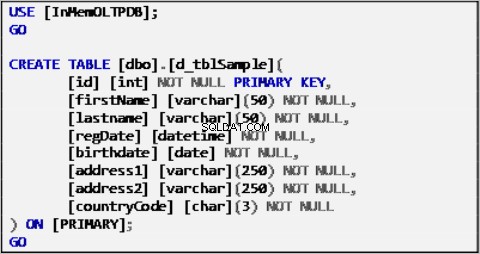
Zápis 1:Ukázková tabulka zdrojů dat.
Tabulka výše byla naplněna ukázkovými daty a bude fungovat jako zdroj dat pro ostatní tabulky.
Na základě výše uvedené tabulky tedy vytvoříme následujících 9 variant tabulky a naplníme je stejnými ukázkovými daty:
- 3 diskové tabulky:
- d_tblSample1
- Shlukovaný index ve sloupci „id“ – primární klíč (PK)
- d_tblSample2
- Shlukovaný index ve sloupci „id“ (PK)
- Neshlukovaný index ve sloupci „countryCode“
- d_tblSample3
- Shlukovaný index ve sloupci „id“ (PK)
- Neshlukované indexy ve sloupci „regDate“
- Neseskupené indexy ve sloupci „countryCode“
- d_tblSample1
- 3 tabulky optimalizované pro paměť (sada 1:Hash indexy):
- m1_tblSample1
- Neklastrovaný hash index ve sloupci „id“ – primární klíč (PK)
- m1_tblSample2
- Neshlukovaný hash index ve sloupci „id“ (PK)
- Hash index ve sloupci „countryCode“
- m1_tblSample3
- Neshlukovaný hash index ve sloupci „id“ (PK)
- Hash index ve sloupci „regDate“
- Hash index ve sloupci „countryCode“
- 3 tabulky optimalizované pro paměť (sada 2:Neklastrované indexy):
- m2_tblSample1
- Neshlukovaný index ve sloupci „id“ – primární klíč (PK)
- m2_tblSample2
- Neshlukovaný index ve sloupci „id“ (PK)
- Neshlukovaný index ve sloupci „countryCode“
- m2_tblSample3
- Neshlukovaný index ve sloupci „id“ (PK)
- Neshlukovaný index ve sloupci „regDate“
- Neshlukovaný index ve sloupci „countryCode“
- m2_tblSample1
- m1_tblSample1
V níže uvedených seznamech můžete najít definice pro výše uvedené tabulky.
Logika scénáře spočívá v tom, že provádíme různé databázové operace proti variantám stejné tabulky (ale s různými indexy) a sledujeme, jak je v každém případě ovlivněn výkon.
Definice
Tabulky založené na disku
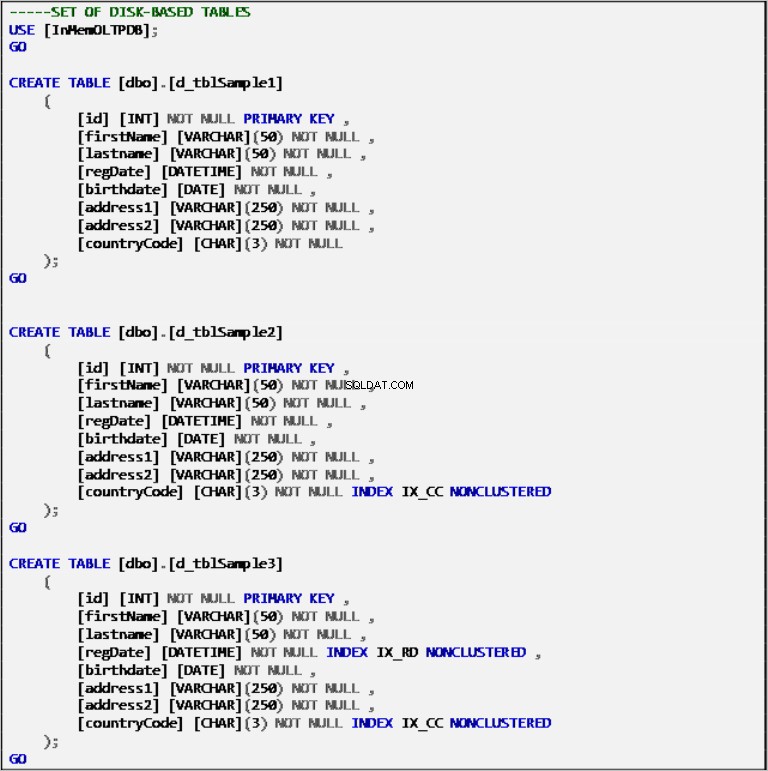
Výpis 2:Definice tabulek na disku.
Tabulky optimalizované pro paměť (sada 1:Hash indexy)

Výpis 3:Tabulky optimalizované pro paměť – sada 1 (Hash indexy).
Tabulky optimalizované pro paměť (Sada 2:Indexy bez klastrů)

Výpis 4:Tabulky optimalizované pro paměť – sada 2 (indexy bez klastrů).
Poté naplníme všechny výše uvedené tabulky stejnými ukázkovými daty, což je celkem 5 milionů záznamů v každé tabulce.
Zde je výstup příkazu count pro každou sadu tabulek:
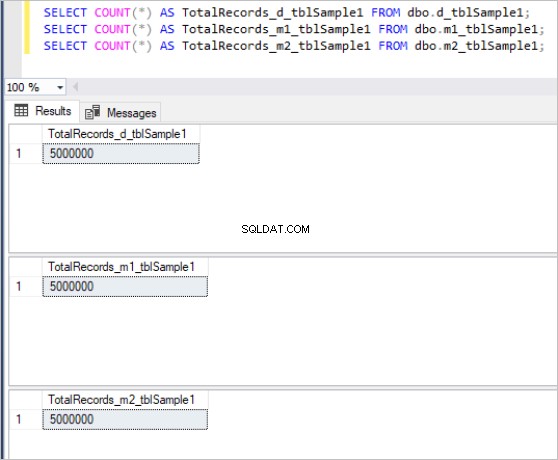
Obrázek 1:Celkový počet záznamů pro první sadu tabulek.
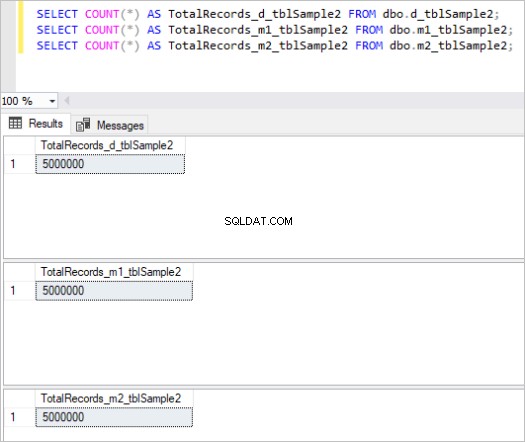
Obrázek 2:Celkový počet záznamů pro druhou sadu tabulek.
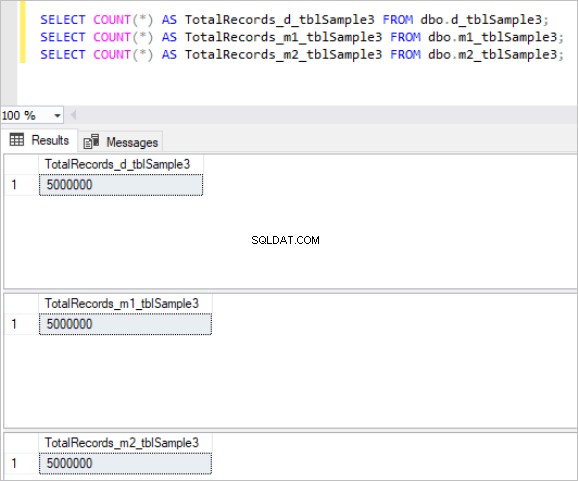
Obrázek 3:Celkový počet záznamů pro třetí sadu tabulek.
Dotazy a provádění scénářů
Nyní spustíme sadu dotazů proti výše uvedeným tabulkám a uvidíme, jak si jednotlivé tabulky vedou.
Tyto dotazy provádějí následující operace:
- Dotaz 1:Agregace (GROUP BY)
- Dotaz 2:Hledání indexu na predikátech rovnosti
- Dotaz 3:Hledání indexu na predikáty rovnosti a nerovnosti
Plán je provést dotazy podle níže:
Dotaz 1 – Provedení podle následujících tabulek:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (žádný index v cílových sloupcích)
- m2_tblSample1 (žádný index v cílových sloupcích)
Dotaz 2 – Provedení podle následujících tabulek:
- d_tblSample2
- m1_tblSample2
- m2_tblSample2
- m1_tblSample1 (žádný index v cílových sloupcích)
- m2_tblSample1 (žádný index v cílových sloupcích)
Dotaz 3 – Provedení podle následujících tabulek:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (žádný index v cílových sloupcích)
- m2_tblSample1 (žádný index v cílových sloupcích)
Poznámka :I když definice pro d_tblSample1 disková tabulka je zahrnuta ve výše uvedených definicích tabulek, není použita v dotazech uvedených v tomto článku. Důvodem je to, že v každém scénáři je použita nejoptimálnější možná konfigurace pro diskovou tabulku, protože chceme, aby naše základní linie byla co nejrychlejší, když ji porovnáme s výkonem tabulek s optimalizovanou pamětí. Za tímto účelem d_tblSample1 tabulka je uvedena pouze pro informační účely.
Níže naleznete T-SQL skripty pro tři dotazy spolu s mechanismy měření doby provádění.

Výpis 5:Dotaz 1 – Agregace (s indexy).
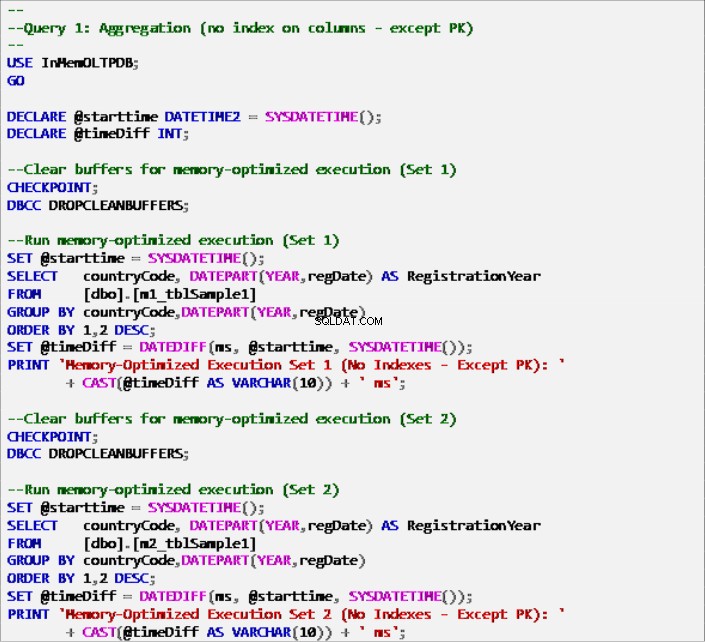
Výpis 6:Dotaz 1 – Agregace (bez indexů – kromě primárního klíče).
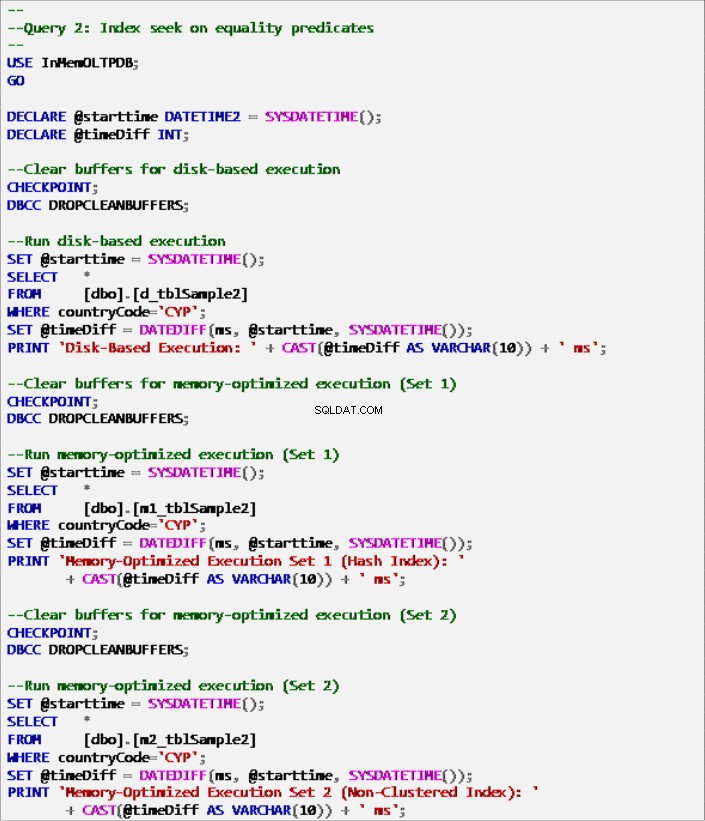
Výpis 7:Dotaz 2 – Hledání indexu na predikátech rovnosti (s indexy).

Výpis 8:Dotaz 2 – Hledání indexu na predikátech rovnosti (bez indexů – kromě primárního klíče).
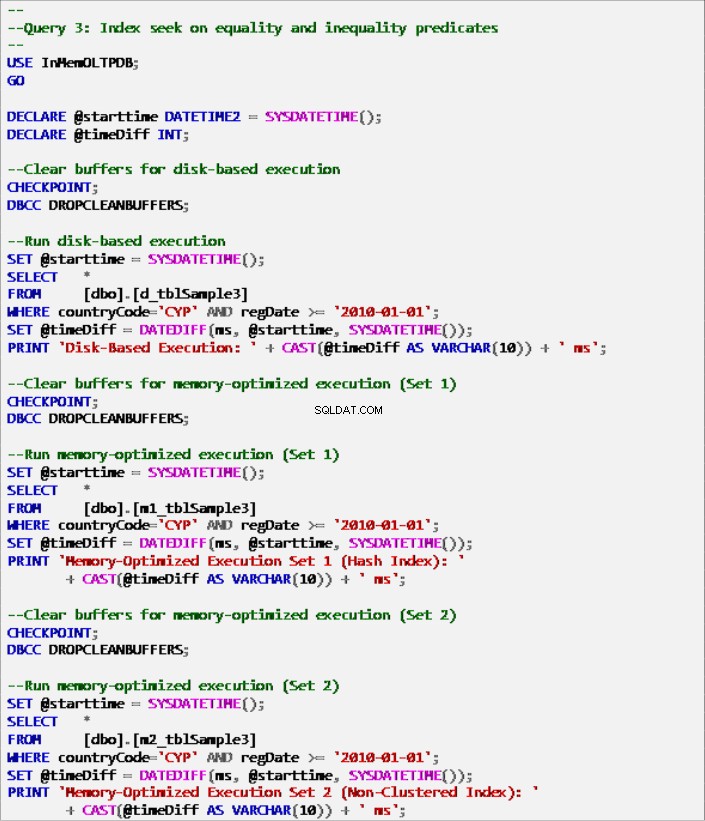
Výpis 9:Dotaz 3 – Hledání indexu na predikátech rovnosti a nerovnosti (s indexy).

Výpis 10:Dotaz 3 – Hledání indexu na predikátech rovnosti a nerovnosti (bez indexů – kromě primárního klíče).
Níže uvedené snímky obrazovky ukazují výstup každého provedení dotazu:
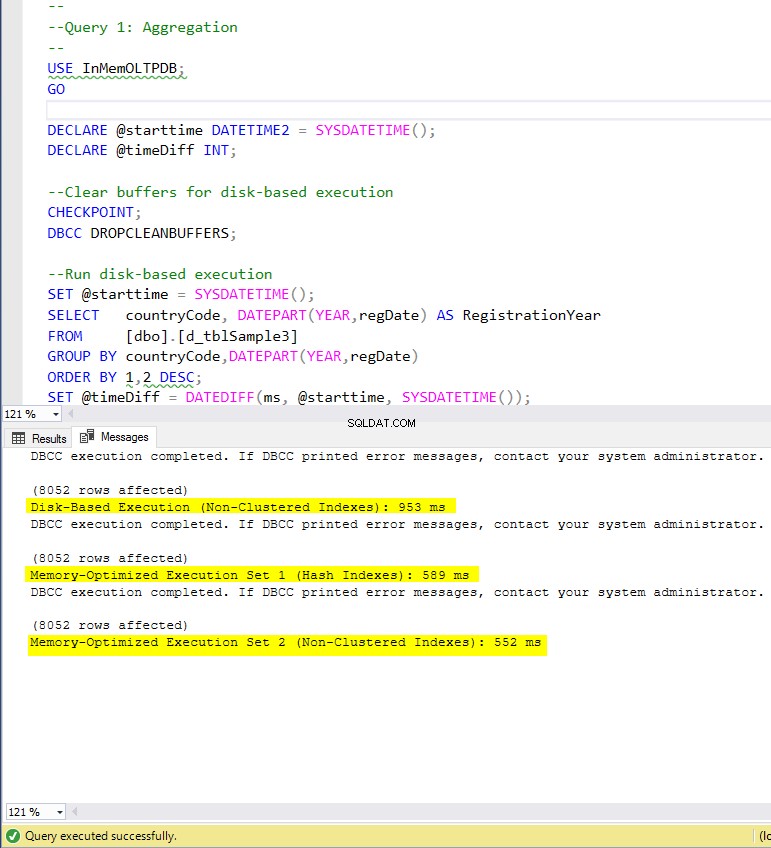
Obrázek 4:Doba provedení dotazu 1 (s indexy).
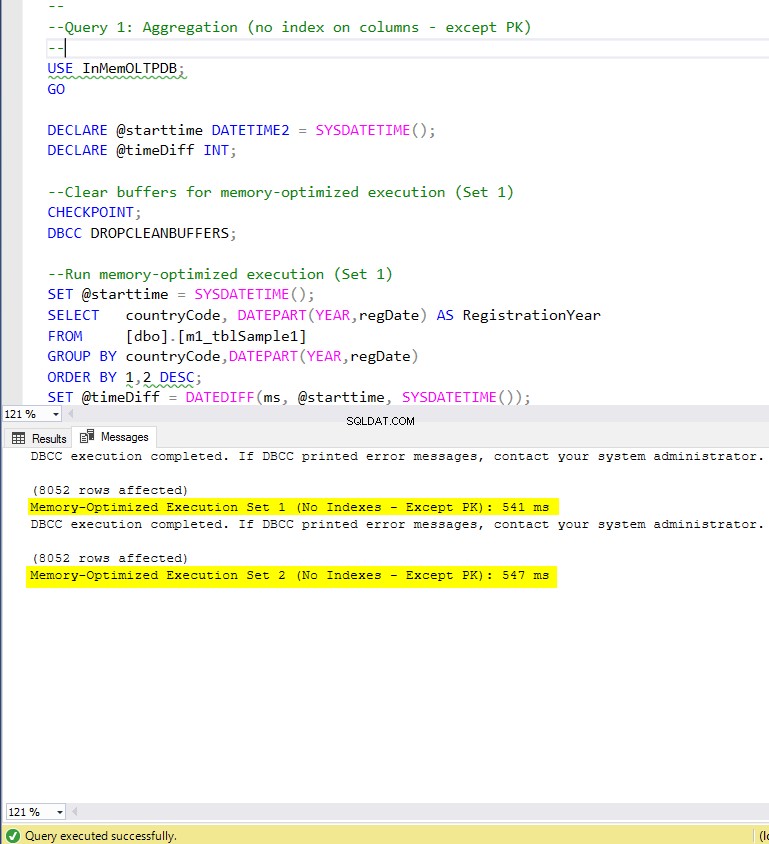
Obrázek 5:Doba provádění dotazu 1 (bez indexů – kromě PK).
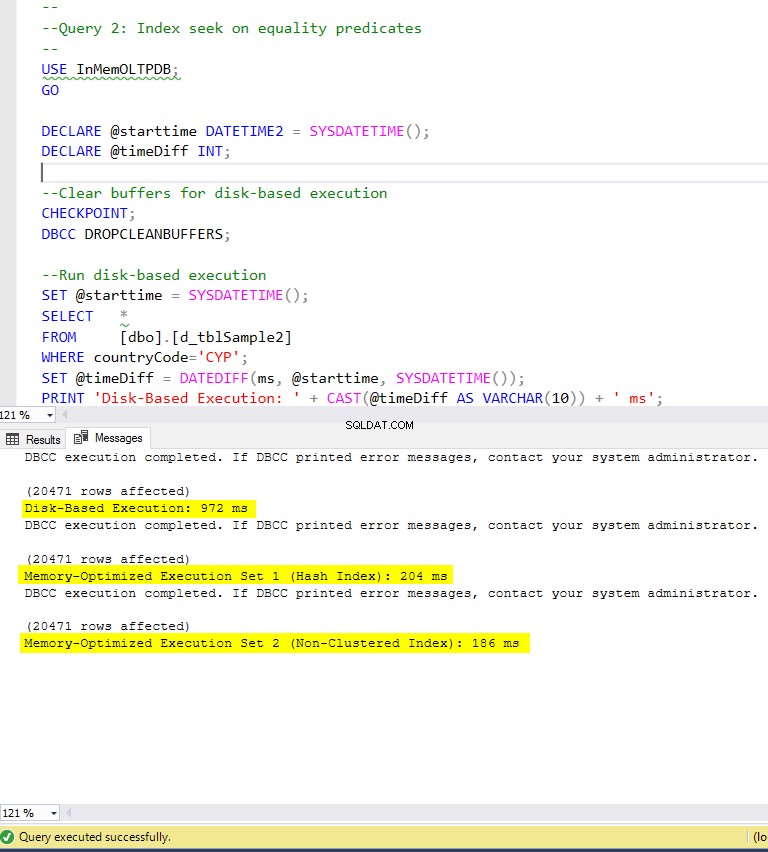
Obrázek 6:Doba provedení dotazu 2 (s indexy).
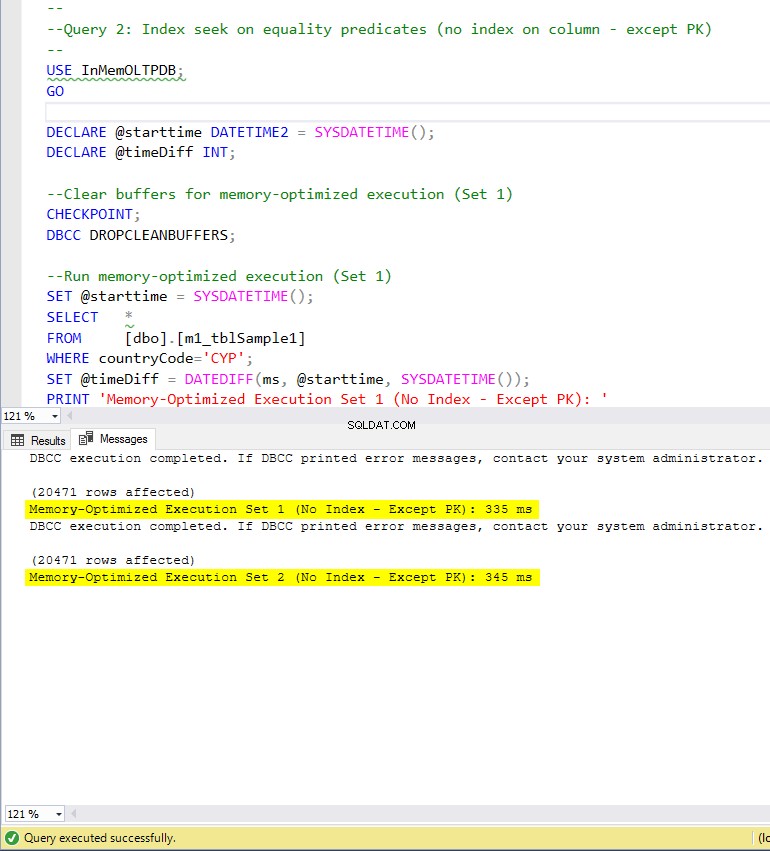
Obrázek 7:Doba provedení dotazu 2 (bez indexů – kromě PK).
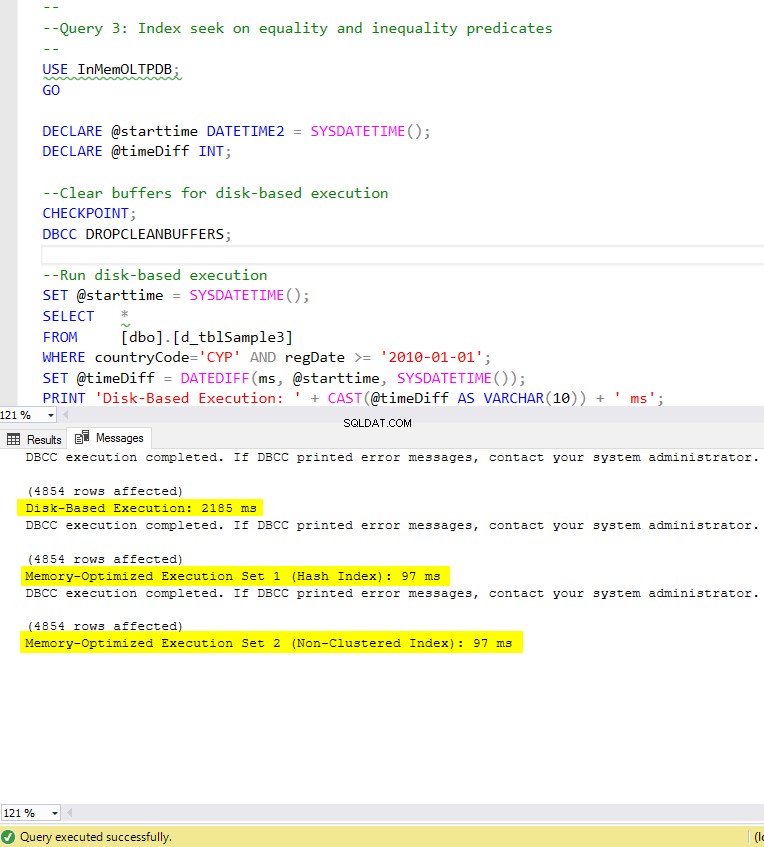
Obrázek 8:Doba provedení dotazu 3 (s indexy).
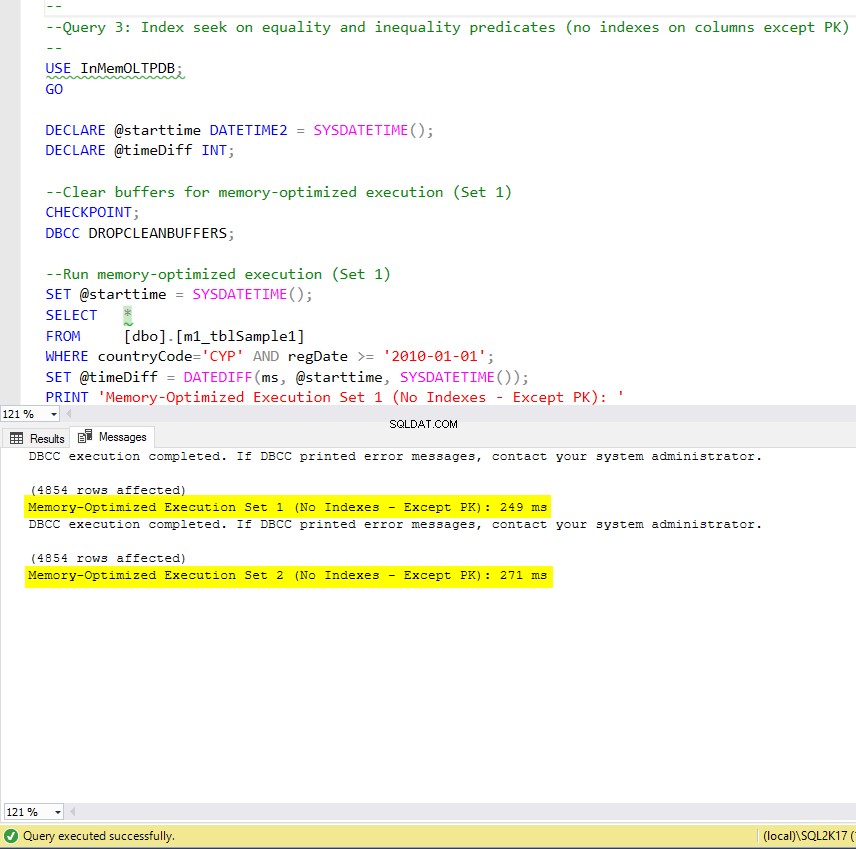
Obrázek 9:Doba provedení dotazu 3 (bez indexů – kromě PK).
Nyní shrňme výše získané výsledky. Následující tabulka zobrazuje naměřené doby provádění pro všechny výše uvedené dotazy a kombinace tabulky/indexu.
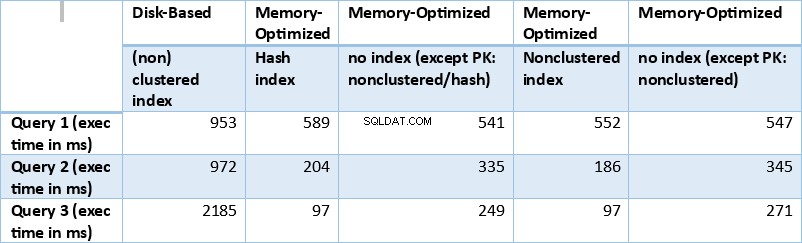
Tabulka 1:Souhrn dob provádění (ms) pro všechny dotazy.
Diskuse
Pokud prozkoumáme výsledky provedení shrnuté v tabulce výše, můžeme dospět k určitým závěrům. Vyneste každý výsledek dotazu do grafu. Níže uvedené grafy znázorňují doby provádění a také zrychlení tabulek s optimalizovanou pamětí oproti tabulkám na disku.
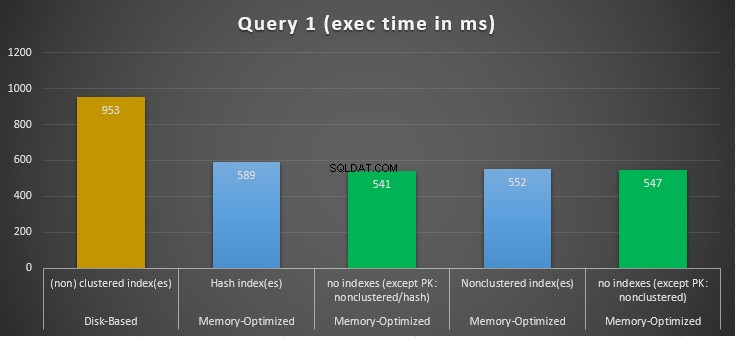
Obrázek 10:Porovnání časů provádění dotazu 1.
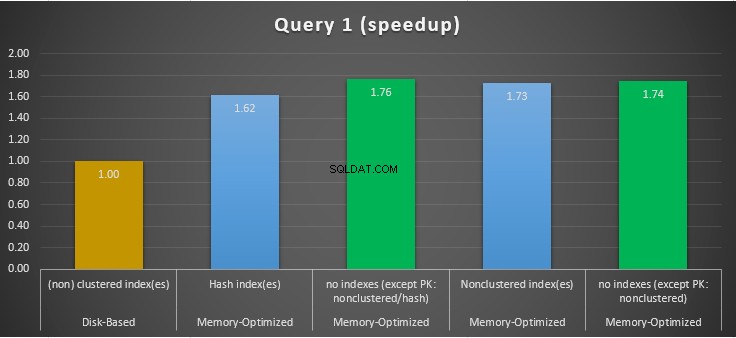
Obrázek 11:Porovnání zrychlení dotazu 1.
Pokud jde o Dotaz 1, což byla agregace GROUP BY, můžeme vidět, že obě verze (indexy vs. žádné indexy) tabulek optimalizovaných pro paměť, fungují téměř stejně, mají zrychlení oproti tabulkám na disku (povoleno pomocí indexů) mezi 1,62 a 1,76krát rychlejší.
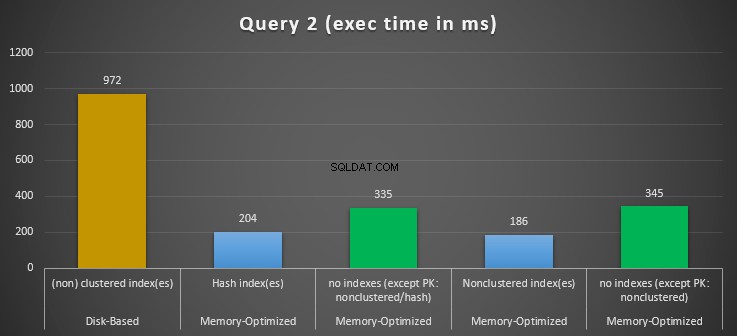
Obrázek 12:Porovnání časů provádění dotazu 2.
Obrázek 13:Porovnání zrychlení dotazu 2.
Pokud jde o Dotaz 2, který zahrnoval hledání indexu na predikátech rovnosti, můžeme vidět, že tabulky optimalizované pro paměť s indexy fungovaly mnohem lépe než tabulky optimalizované pro paměť bez indexů. Navíc jsme pozorovali, že tabulka optimalizovaná pro paměť s neshlukovaným indexem ve sloupci použitém jako predikát fungovala lépe než tabulka s hash indexem.
Pro dotaz 2 je tedy vítězem tabulka optimalizovaná pro paměť s neklastrovaným indexem s celkovým zrychlením 5,23 krát rychlejší než spouštění na disku.
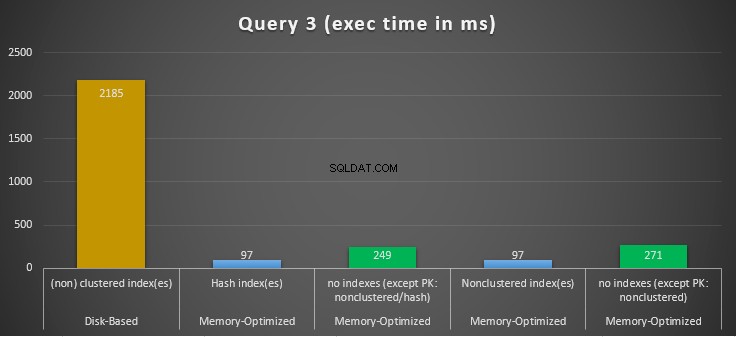
Obrázek 14:Porovnání časů provádění dotazu 3.
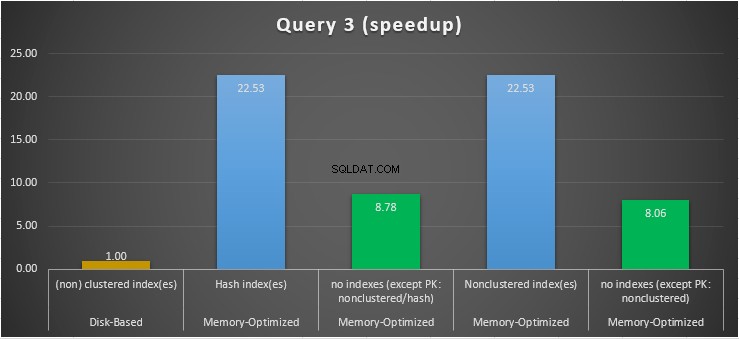
Obrázek 15:Porovnání zrychlení dotazu 3.
Pokud jde o Dotaz 3, který zahrnoval hledání indexu na predikátech rovnosti a nerovnosti v kombinaci, můžeme vidět, že tabulky optimalizované pro paměť s indexy fungovaly mnohem lépe než tabulky optimalizované pro paměť bez indexů. Navíc jsme pozorovali, že tabulka optimalizovaná pro paměť s neklastrovaným indexem ve sloupci použitém jako predikát fungovala stejně jako tabulka s hash indexem.
Za tímto účelem můžeme vidět, že obě tabulky optimalizované pro paměť, které využívají indexy ve sloupcích používaných jako predikáty, fungovaly rychleji než ty bez indexů a dosáhly zrychlení 22,53krát rychleji přes diskové spouštění.
Závěr
V tomto článku jsme zkoumali použití indexů v tabulkách optimalizovaných pro paměť na serveru SQL Server. Jako základ pro každý dotaz jsme použili nejlepší možnou konfiguraci diskové tabulky a poté jsme porovnali výkon tří dotazů s diskovými tabulkami a 4 variantami tabulek optimalizovaných pro paměť. Dvě ze čtyř tabulek optimalizovaných pro paměť používaly indexy (hash/neshlukované) a další dvě nepoužívaly žádné indexy kromě těch, které se používají pro primární klíče.
Celkový závěr je takový, že vždy musíte prozkoumat, jak indexy ovlivňují výkon, a to nejen pro tabulky optimalizované pro paměť, ale také pro tabulky založené na disku, a kdykoli zjistíte, že zlepšují výkon, použít je. Zjištění příkladů v tomto článku ukazují, že pokud použijete správné indexy v tabulkách optimalizovaných pro paměť, můžete dosáhnout mnohem lepšího výkonu pro dotazy podobné těm, které jsou použity v tomto článku, ve srovnání s pouhým použitím tabulek optimalizovaných pro paměť bez indexů. .
Odkazy a další informace:
- Dokumenty Microsoft:Tabulky optimalizované pro paměť
- Dokumenty Microsoft:Pokyny pro používání indexů v tabulkách s optimalizovanou pamětí
- Dokumenty Microsoft:Indexy v tabulkách optimalizovaných pro paměť
Užitečný nástroj:
dbForge Index Manager – praktický doplněk SSMS pro analýzu stavu indexů SQL a řešení problémů s fragmentací indexů.