Podle Wikipedie "Hromadné vkládání je proces nebo metoda poskytovaná systémem správy databází k načtení více řádků dat do databázové tabulky." Pokud toto vysvětlení upravíme v souladu s příkazem BULK INSERT, hromadné vložení umožňuje import externích datových souborů do SQL Serveru. Předpokládejme, že naše organizace má soubor CSV s 1 500 000 řádky a chceme tento soubor importovat do konkrétní tabulky na serveru SQL Server, takže na serveru SQL Server můžeme snadno použít příkaz BULK INSERT. Jistě, můžeme najít několik metod importu pro zpracování tohoto procesu importu souboru CSV, např. můžeme použít bcp (b ulk c opište p rogram), Průvodce importem a exportem SQL Server nebo balíček SQL Server Integration Service. Příkaz BULK INSERT je však mnohem rychlejší a robustnější než použití jiných metodologií. Další výhodou příkazu hromadného vkládání je, že nabízí několik parametrů, které pomáhají určit nastavení procesu hromadného vkládání.
Nejprve začneme velmi základním příkladem a poté projdeme různými sofistikovanými scénáři.
Příprava
Před spuštěním ukázek potřebujeme ukázkový soubor CSV. Stáhneme si proto ukázkový CSV soubor z webu E for Excel, kde najdete různé ukázkové CSV soubory s jiným číslem řádku. Odkaz najdete na konci článku. V našich scénářích použijeme 1 500 000 záznamů o prodeji. Stáhněte si soubor zip, rozbalte soubor CSV a umístěte jej na místní disk.

Importujte soubor CSV do tabulky serveru SQL Server
Scénář 1:Cíl a soubor CSV mají stejný počet sloupců
V tomto prvním scénáři importujeme soubor CSV do cílové tabulky v nejjednodušší podobě. Umístil jsem svůj ukázkový soubor CSV na disk C:a nyní vytvoříme tabulku, do které budeme importovat data ze souboru CSV.
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
Následující příkaz BULK INSERT importuje soubor CSV do tabulky Prodej.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
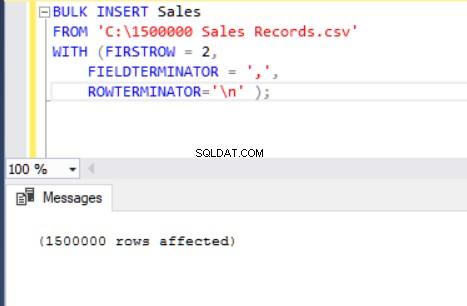
Nyní vysvětlíme parametry výše uvedeného příkazu hromadného vložení.
Parametr FIRSTROW určuje počáteční bod příkazu insert. V níže uvedeném příkladu chceme přeskočit záhlaví sloupců, takže tento parametr nastavíme na 2.

FIELDTERMINATOR definuje znak, který odděluje pole od sebe. SQL Server detekuje každé pole takovým způsobem. ROWTERMINATOR se příliš neliší od FIELDTERMINATOR. Definuje separační charakter řádků. V ukázkovém CSV souboru je fieldterminator velmi jasný a je to čárka (,). Ale jak můžeme detekovat fieldterminator? Otevřete soubor CSV v programu Poznámkový blok++ a poté přejděte na Zobrazit->Zobrazit symbol->Zobrazit všechny charty a poté zjistěte znaky CRLF na konci každého pole.
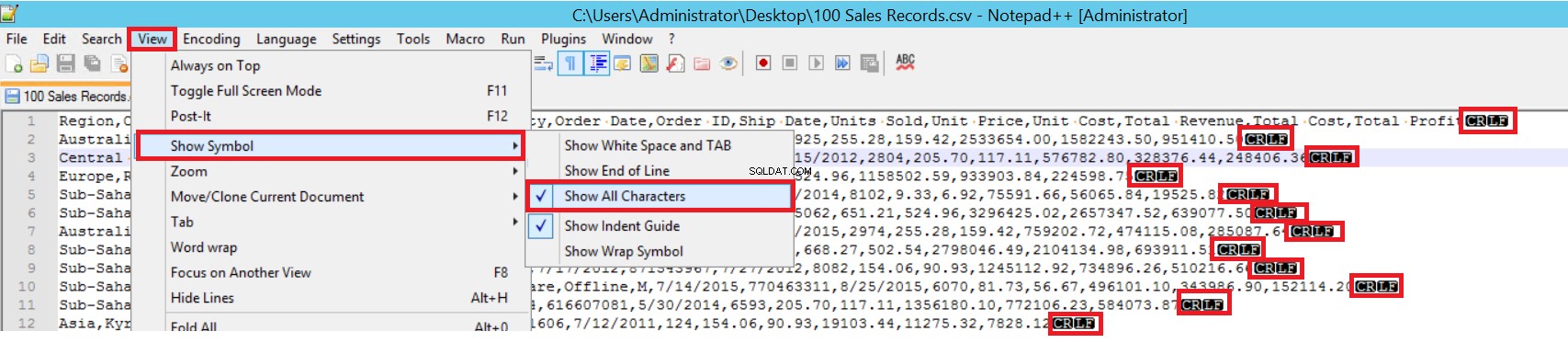
CR =Carriage Return a LF =Line Feed. Používají se k označení konce řádku v textovém souboru a je označen znakem „\n“ v příkazu hromadného vložení.
Další metodou importu CSV souboru do tabulky pomocí hromadného vkládání je použití parametru FORMAT. Pamatujte, že parametr FORMAT je dostupný pouze v SQL Server 2017 a novějších verzích.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
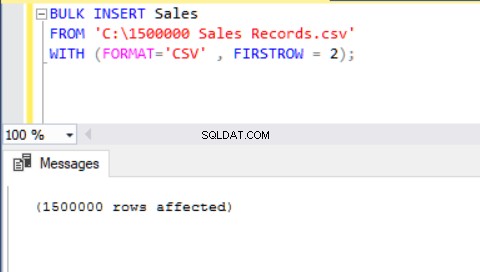
Nyní budeme analyzovat jiný scénář.
Scénář 2:Cílová tabulka má více sloupců než soubor CSV
V tomto scénáři přidáme primární klíč do tabulky Prodej a tento případ naruší mapování sloupců rovnosti. Nyní vytvoříme tabulku Prodej s primárním klíčem, pokusíme se importovat soubor CSV pomocí příkazu hromadného vložení a poté se zobrazí chyba.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
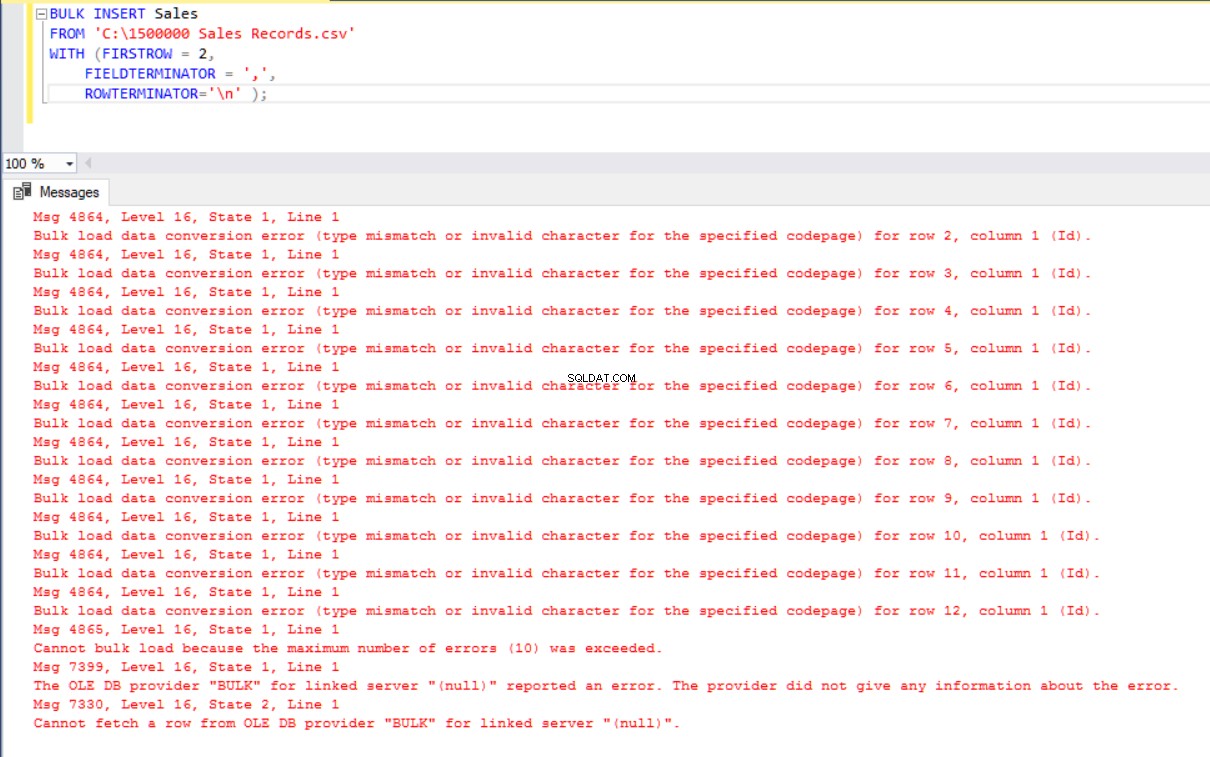
Abychom tuto chybu odstranili, vytvoříme pohled na tabulku Prodej s mapováním sloupců do souboru CSV a importujeme data CSV přes toto zobrazení do tabulky Prodej.
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Scénář 3:Jak oddělit a načíst soubor CSV do malé dávky?
SQL Server získá zámek cílové tabulky během operace hromadného vložení. Ve výchozím nastavení, pokud nenastavíte parametr BATCHSIZE, SQL Server otevře transakci a vloží do této transakce celá data CSV. Pokud však nastavíte parametr BATCHSIZE, SQL Server rozdělí data CSV podle této hodnoty parametru. V následujícím příkladu rozdělíme celá data CSV do několika sad po 300 000 řádcích. Data budou tedy importována 5krát.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 );
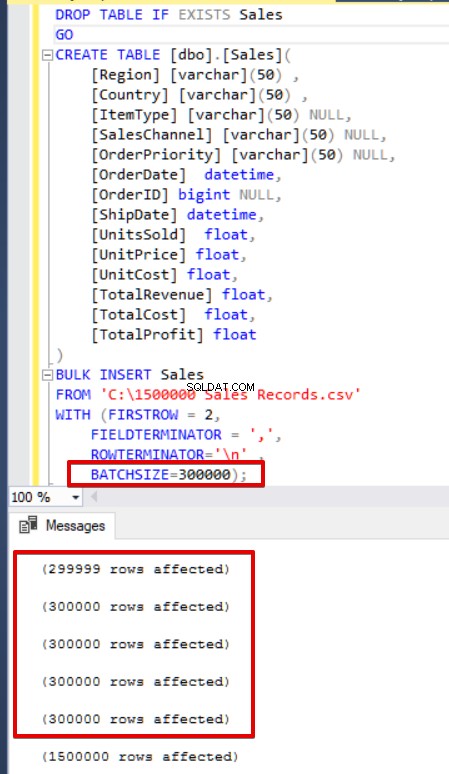
Pokud váš příkaz hromadného vložení nezahrnuje parametr velikost dávky (BATCHSIZE), dojde k chybě a SQL Server vrátí zpět celý proces hromadného vložení. Na druhou stranu, pokud nastavíte parametr velikosti dávky na příkaz hromadného vložení, SQL Server vrátí zpět pouze tuto rozdělenou část, kde došlo k chybě. Pro tento parametr neexistuje optimální ani nejlepší hodnota, protože hodnotu tohoto parametru lze změnit podle požadavků vašeho databázového systému.
Scénář 4:Jak zrušit proces importu, když se zobrazí chyba?
Pokud v některých scénářích hromadného kopírování dojde k chybě, můžeme chtít buď proces hromadného kopírování zrušit, nebo jej ponechat v chodu. Parametr MAXERRORS nám umožňuje určit maximální počet chyb. Pokud proces hromadného vkládání dosáhne této maximální chybové hodnoty, operace hromadného importu bude zrušena a vrácena zpět. Výchozí hodnota tohoto parametru je 10.
V následujícím příkladu záměrně poškodíme datový typ ve 3 řádcích souboru CSV a nastavíme parametr MAXERRORS na 2. V důsledku toho bude celá operace hromadného vkládání zrušena, protože číslo chyby překračuje parametr max error.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2);
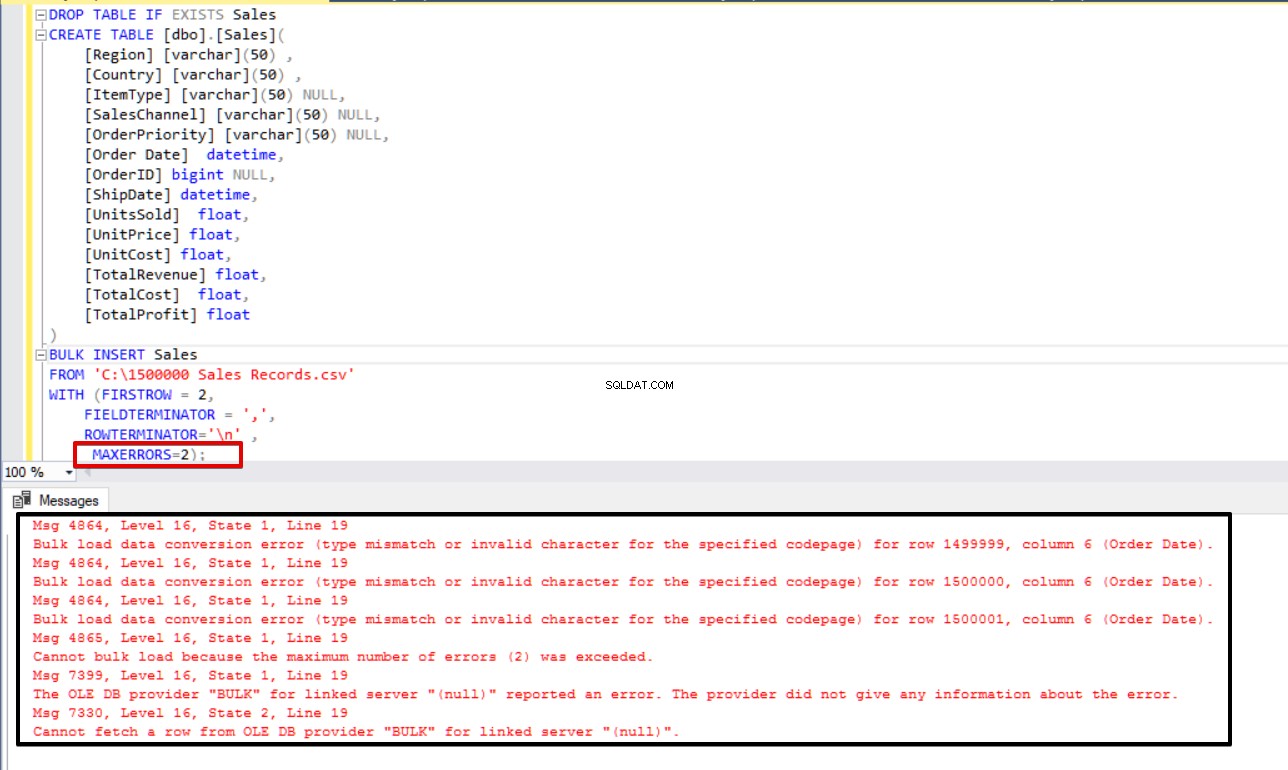
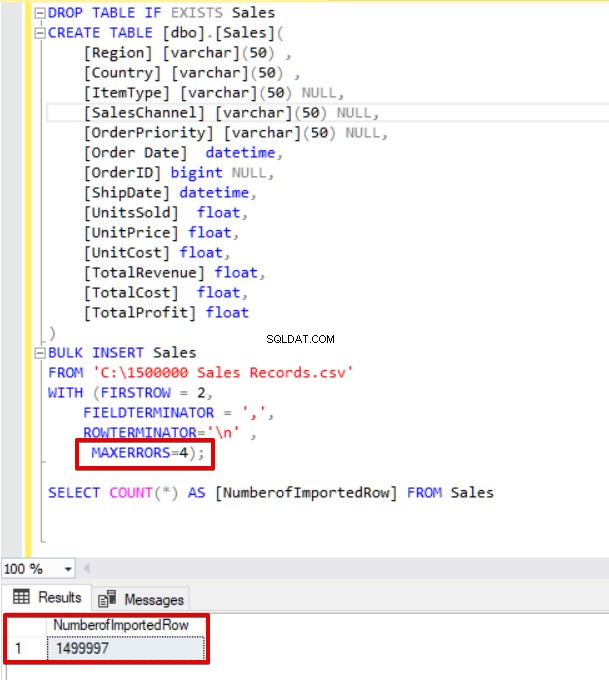
Nyní změníme parametr max error na 4. V důsledku toho příkaz hromadného vložení tyto řádky přeskočí a vloží řádky se správnou strukturou dat a dokončí proces hromadného vložení.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
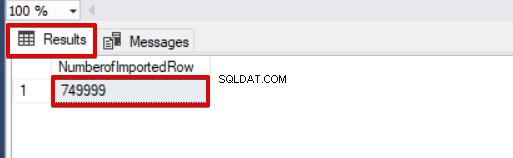
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
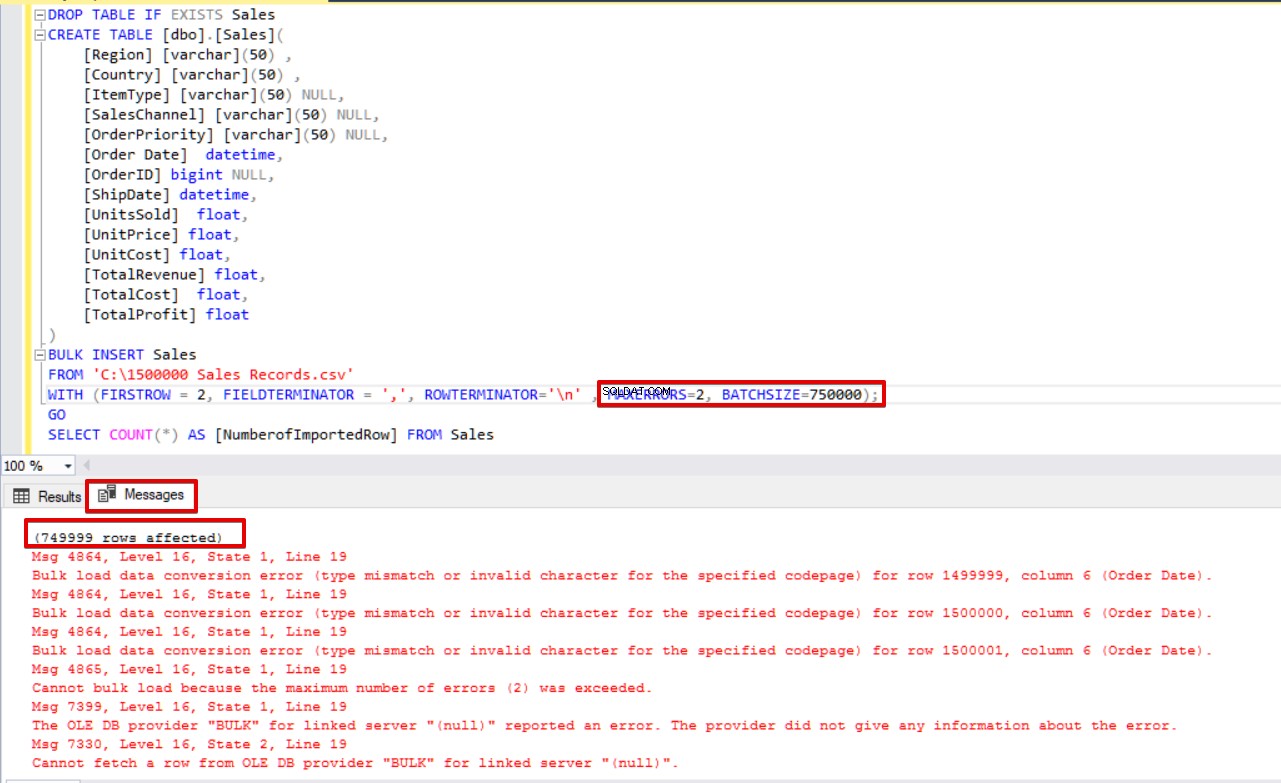
Pokud navíc použijeme oba parametry, velikost dávky a maximální chybu současně, proces hromadného kopírování nezruší celou operaci vložení, pouze zruší rozdělenou část.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
V této první části této série článků jsme diskutovali o základech používání operace hromadného vkládání na SQL Server a analyzovali jsme několik scénářů, které se blíží skutečným problémům.
Hromadné vložení serveru SQL – část 2
Užitečné odkazy:
Hromadná vložka
E pro Excel – Ukázkové soubory CSV / soubory dat pro testování (až 1,5 milionu záznamů)
Notepad++ ke stažení
Užitečný nástroj:
dbForge Data Pump – doplněk SSMS pro plnění databází SQL externími zdrojovými daty a migraci dat mezi systémy.